第八次作业 分布式计算mapreduce




在Ubuntu中实现运行。
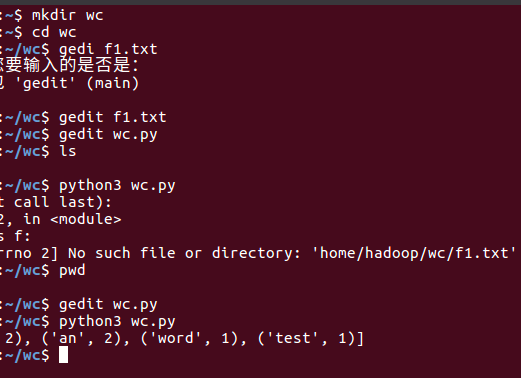
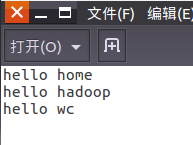
- 准备txt文件
![]()
![]()
- 编写py文件
![]()
- python3运行py文件分析txt文件。
![]()



2.用MapReduce实现词频统计
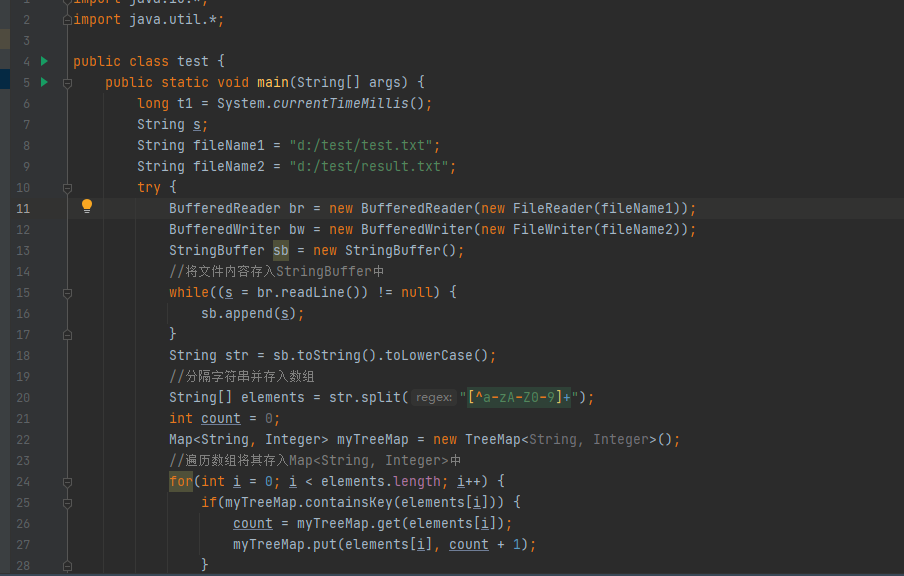
2.1编写Map函数
- 编写mapper.py
![]()
![]()
- 授予可运行权限
![]()
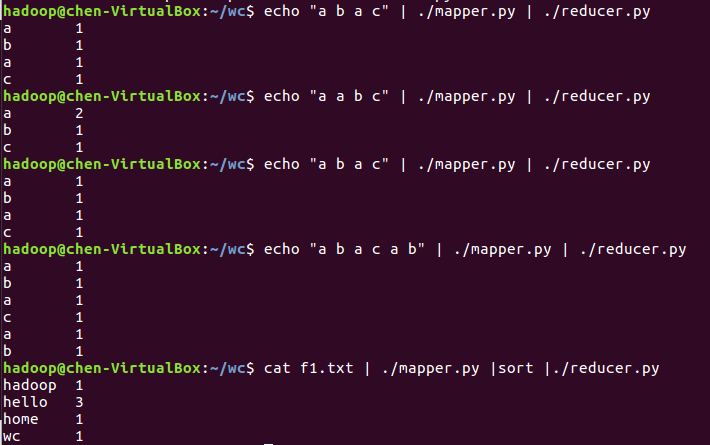
- 本地测试mapper.py
![]()




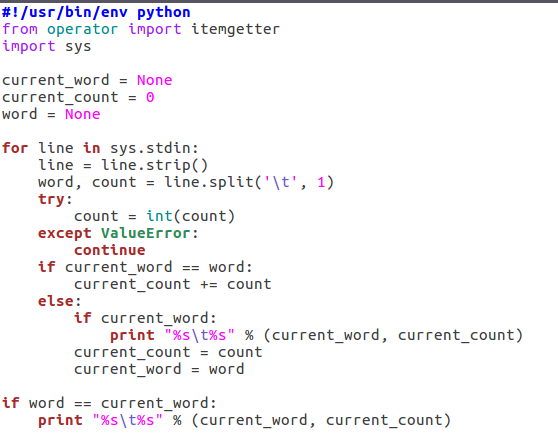
2.2编写Reduce函数
- 编写reducer.py
![]()
- 授予可运行权限
![]()
- 本地测试reducer.py
![]()
2.3分布式运行自带词频统计示例
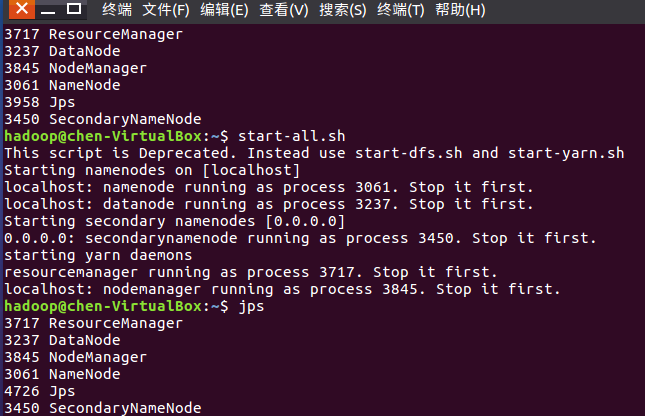
- 启动HDFS与YARN
![]()
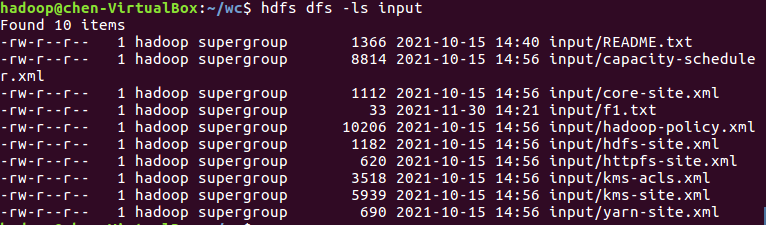
- 准备待处理文件,上传到HDFS上
![]()
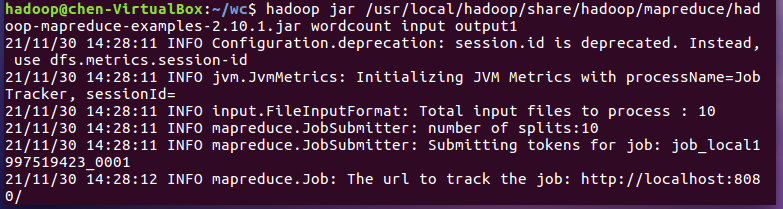
- 运行实例hadoop-mapreduce-examples-2.10.1.jar
-
![]()
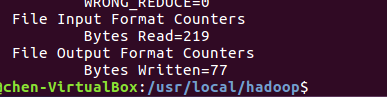
- 查看结果
![]()

2.4 分布式运行自写的词频统计
- 用Streaming提交MapReduce任务:
- 查看hadoop-streaming的jar文件位置:/usr/local/hadoop/share/hadoop/tools/lib/
![]()
![]()
![]()
- 配置stream环境变量
![]()
![]()
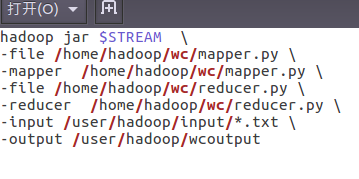
- 编写运行文件run.sh
![]()
- 运行run.sh运行
![]()
- 查看运行结果
![]()
- 停止HDFS与YARN
![]()







 浙公网安备 33010602011771号
浙公网安备 33010602011771号