基础排序算法(六)希尔排序
一 希尔排序
希尔排序是一种非常独特且高效的排序算法,它通过一种“先宏观,后微观”的策略来提升效率
1.1 算法特性
希尔排序特性总结
| 特性 | 说明 |
|---|---|
| 核心思想 | 分而治之:将整个序列按一定间隔(gap)分割成若干子序列,分别进行直接插入排序。然后逐步缩小间隔,直至间隔为1,此时整个序列已基本有序,最后进行一次插入排序即可完成 |
| 时间复杂度 | 取决于增量序列的选择,通常介于 O(n log²n) 到 O(n²) 之间。使用 Hibbard 或 Knuth 增量序列时,平均复杂度可优化至约 O(n^1.3) 或 O(n^(3/2)) |
| 空间复杂度 | O(1)。是原地排序算法,只需要常数级别的额外空间 |
| 稳定性 | 不稳定。由于元素是跨间隔进行跳跃式移动,可能会改变相同元素的原始相对顺序 |
| 主要优势 | 相比简单插入排序效率显著提升;代码实现相对简单;是早期突破O(n²)时间复杂度的算法之一 |
| 主要劣势 | 性能受增量序列选择影响较大;不稳定;在最坏情况下性能可能不佳 |
1.2 算法原理
希尔排序的巧妙之处在于它通过“增量序列”将大规模无序数据转化为小规模且基本有序的数据进行排序。其过程可以清晰地分为“分组预排序”和“最终插入排序”两大阶段。下图以序列 [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]为例,展示了使用初始增量 gap=5进行分组排序,并逐步缩小增量直至为1的全过程。
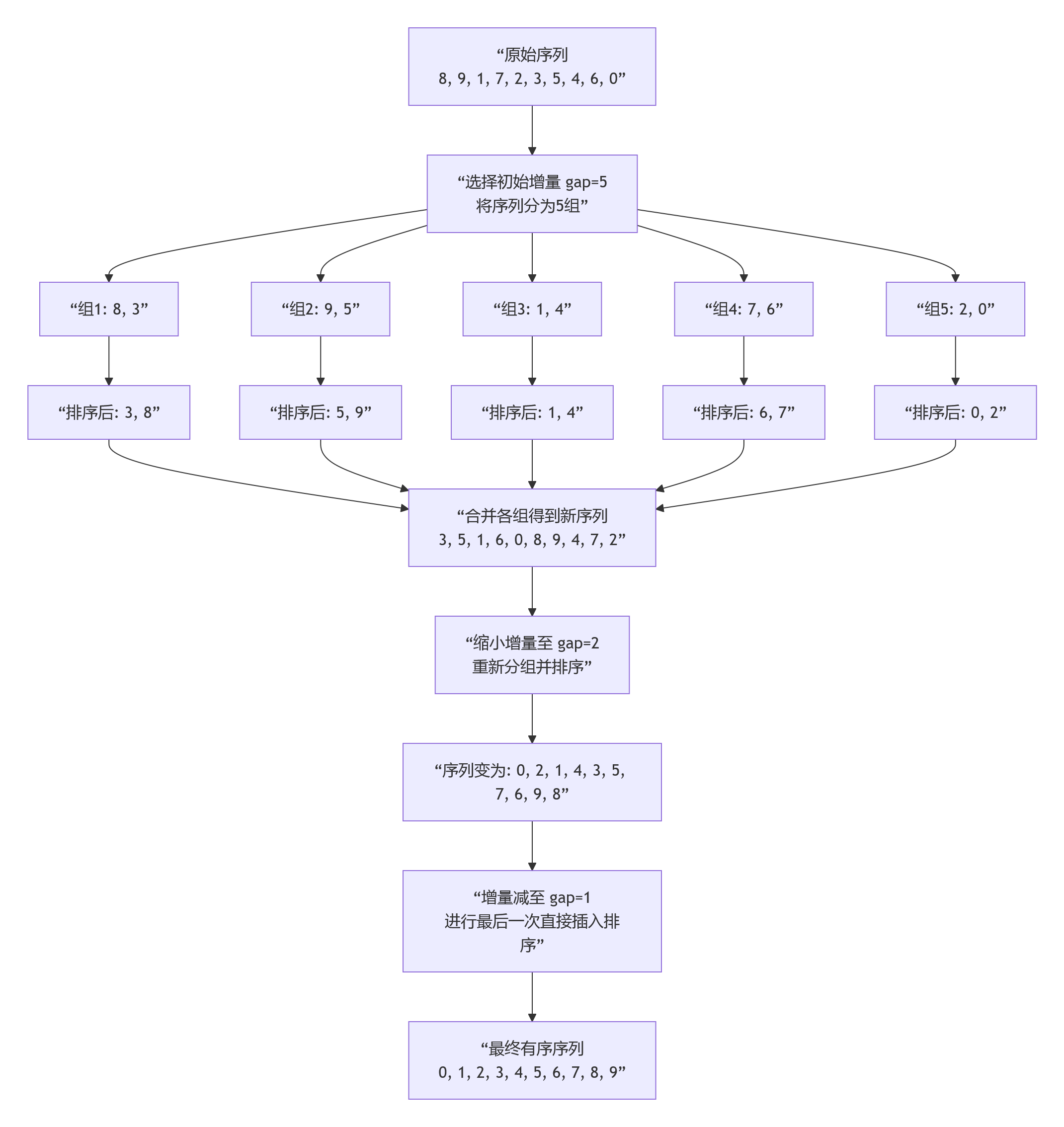
- 1 选择增量序列:这是希尔排序的“灵魂”。算法首先选择一个初始间隔(gap),通常为数组长度的一半(如n/2),然后逐步缩小这个间隔(如每次减半),直到间隔变为1。
- 2 按间隔分组并排序:
对于每个选定的间隔gap,将数组中所有相距为gap倍数的元素归为同一组。然后,分别对这些分组进行直接插入排序。这一步称为“预排序”,它使得元素能够大步地跳跃到其最终位置 附近, 从而大幅减少后续精细排序所需的工作量。 - 3 缩小间隔重复过程:完成一次分组排序后,将间隔gap缩小(例如,gap = gap / 2或使用更优的序列如 gap = gap / 3 + 1),然后重复步骤2的分组和排序过程。
- 4 最终插入排序:当间隔gap最终缩小到1时,整个数组已经被“预排序”得基本有序了。此时再对整个数组进行一次标准的直接插入排序。由于序列已基本有序,这次插入排序的效率会非常高,接近O(n)。
1.3 复杂度分析
希尔排序的性能与所选用的增量序列密切相关。
1.3.1 时间复杂度
这是一个复杂的话题,因为没有一个固定的答案。
使用最简单的增量序列(如每次减半),最坏情况时间复杂度可能达到 O(n²)。
但使用更优化的增量序列,如Hibbard增量(1, 3, 7, ..., 2ᵏ - 1)或Knuth增量(1, 4, 13, ..., (3ᵏ - 1)/2),平均时间复杂度可以优化到约 O(n^1.3) 或 O(n^(3/2)),这比简单插入排序的O(n²)要好得多。
需要注意的是,希尔排序的准确平均时间复杂度分析仍然是算法研究中的一个课题。
1.3.2 空间复杂度
由于希尔排序是原地排序,只需要少量临时变量(如用于元素交换的temp),因此空间复杂度为 O(1)。
1.4 使用场景
希尔排序在以下场景中表现出色:
- 中等规模数据排序:当数据量在数百到数万之间时,希尔排序通常能提供不错的性能,且实现比快速排序、归并排序等更简单。
- 内存受限的环境:由于它是原地排序,空间复杂度为O(1),非常适合嵌入式系统等内存紧张的场景。
- 作为更复杂算法的子过程:有时在快速排序等算法的递归过程中,当子数组规模较小时,会切换使用希尔排序来提升整体效率。
1.5 代码实现
1.5.1 C 语言代码实现
#include <stdio.h>
void shellSort(int arr[], int n) {
// 初始增量gap设为数组长度的一半,随后逐步缩小增量
for (int gap = n / 2; gap > 0; gap /= 2) {
// 从第gap个元素开始,对每个子序列进行插入排序
for (int i = gap; i < n; i++) {
int temp = arr[i]; // 待插入的元素
int j;
// 对当前子序列进行插入排序:将比temp大的元素后移
for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {
arr[j] = arr[j - gap];
}
// 将temp插入到正确位置
arr[j] = temp;
}
}
}
// 打印数组函数
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
// 主函数测试
int main() {
int arr[] = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
int n = sizeof(arr) / sizeof(arr[0]);
printf("排序前的数组: \n");
printArray(arr, n);
shellSort(arr, n);
printf("排序后的数组: \n");
printArray(arr, n);
return 0;
}
1.5.2 代码关键点解释
- 外层循环 for (int gap = n / 2; gap > 0; gap /= 2)控制增量的变化。
- 中间层循环 for (int i = gap; i < n; i++)从每个子序列的第二个元素开始遍历(因为第一个元素可视为已排序)。
- 内层循环 for (j = i; j >= gap && arr[j - gap] > temp; j -= gap)是插入排序的核心,它在当前子序列中为 temp寻找正确的插入位置,并将比它大的元素向后移动。
1.6 常用算法比较
排序算法比较
| 算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 主要特点 |
|---|---|---|---|---|---|
| 希尔排序 | 约 O(n^1.3) | O(n²) | O(1) | 不稳定 | 实现简单,中等规模数据效率高,性能受增量序列影响大 |
| 直接插入排序 | O(n²) | O(n²) | O(1) | 稳定 | 对小规模或基本有序数据效率很高;稳定;简单 |
| 快速排序 | O(n log n) | O(n²) | O(log n) | 不稳定 | 平均性能极佳,是许多标准库的实现选择,但对初始数据敏感 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | 稳定 | 性能稳定,是稳定的O(n log n)排序,但需要O(n)额外空间 |
| 堆排序 | O(n log n) | O(n log n) | O(1) | 不稳定 | 最坏情况也能保证O(n log n),但常数因子较大,缓存不友好 |
1.7 总结
希尔排序是一种巧妙且实用的排序算法,它通过“分组插入排序”和“逐步细化”的策略,显著提升了插入排序在处理无序数据时的效率。虽然其性能分析较为复杂,且它不是稳定的排序算法,但其代码简洁、空间效率高的特点,使其在特定场景下(如中等规模数据排序、内存受限环境)依然是一个非常有价值的选择。
posted on 2025-10-31 17:13 weiwei2021 阅读(34) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号