集合
一、集合的框架
|-------Collection接口:单列集合,用来存储一个一个的对象
|-------List接口:存储有序的、可重复的数据
|----------ArrayList、LinkedList、Vector
|-------Set接口:存储无序的、不可重复的数据 --->高中讲的“集合”
|---------------HashSet、LinkedHashSet、TreeSet
|--------Map接口:双列集合,用来存储一对(key---value)一对的数据 --->高中函数:y = f(x)
|------HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
二、Collection接口中的常用方法
见Api中的Collection接口
1.boolean contains(Object obj) :判断当前集合中是否包含obj
这个方法底层是 obj.equals(集合中的每一个对象) ,与集合中的对象一个一个的equals。
因此,我们要求 加入集合中的对象 所在的类 需要去重写equals方法,这样在调用contains()等方法时,比较的才是内容。
2.boolean containsAll(Collection c) :判断形参 c 中的所有元素 是否都存在与当前集合中
3.boolean remove(Object obj):从当前集合中删除obj这个元素,删除成功返回true,失败返回false
4.boolean removeAll(Collection c) :从当前集合中删除 集合c中 的元素(删除交集),并且会改变当前集合
5.boolean retainAll(Collection c):获取当前集合与集合c 的交集,并且会改变当前集合
6.boolean equals(Object obj):要想返回true,需要当前集合与形参集合的元素都要相同。
与元素的顺序有没有关系 需要看这个集合是什么类型的
7.Object[ ] toArray():把当前集合转换成威 Object类型的数组 (集合------>数组)
8.(数组------->集合) 用Arrays类中的静态方法 asList()即可
Arrays.asList(把数组放进来) ,返回List类型
特别注意:Arrays.asList(new int[ ]{123, 456}),返回的集合只有一个元素,这个元素是 int[ ]类型的 。
因为它把 new int[ ]{123, 456} 当成一个引用类型的元素了。
若想变成两个元素(123,456),则需要 Arrays.asList(new Integer[ ]{123, 456})或者 Arrays.asList(123, 456)
三、Iterator迭代器接口
Collection coll = new ArrayList();
coll.add("AA");
coll.add("BB");
coll.add("CC");
//怎么去遍历这个coll集合呢?
方式一:
Iterator iterator = coll.iterator();//先获取Iterator迭代器的对象
//hasNext():判断是否还有下一个元素
while(iterator.hasNext()){
//next():①指针下移 ②将下移以后集合位置上的元素返回
System.out.println(iterator.next());
}
方式二:增强for循环
//for(集合元素的类型 局部变量 :集合对象)
//内部仍然调用了迭代器
for(Object obj : coll){
sout(obj);
}
四丶Collection子接口之一:List接口
1.结构
|-------Collection接口:单列集合,用来存储一个一个的对象
|-------List接口:存储有序的、可重复的数据 --------> 代替原来的数组
|----------ArrayList : 主要实现类、线程不安全、底层使用Object[ ] 数组存储
|---------LinkedList :底层是双向链表存储
|---------Vector :古老实现类、线程安全、底层使用Object[ ] 数组存储 、用的不多
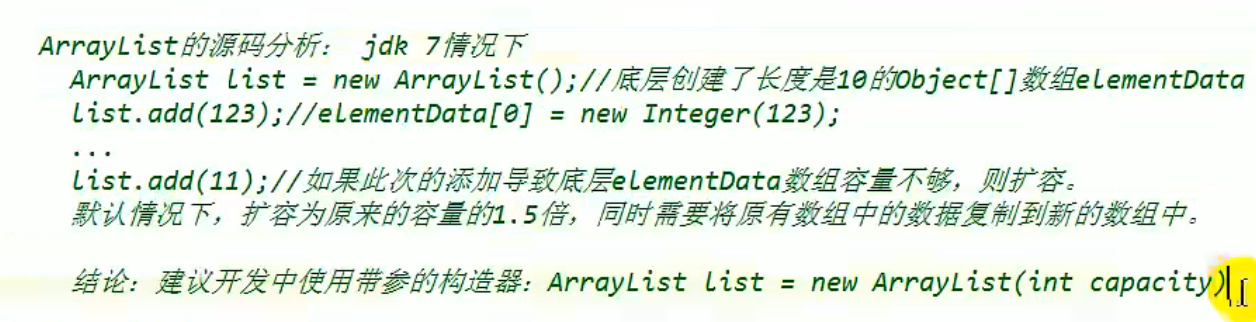
2.ArrayList的源码分析


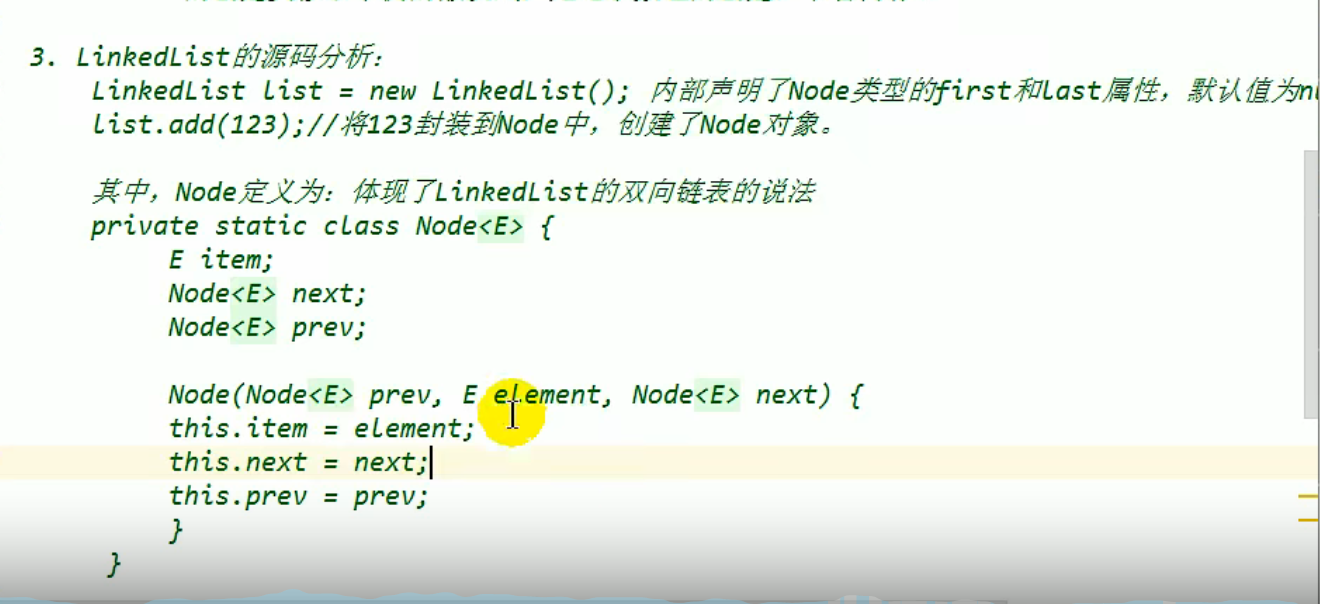
3.LinkedList的源码分析
4.List接口的常用方法

五、Collection子接口之二:Set接口
1.Set接口的框架:
|-------Collection接口:单列集合,用来存储一个一个的对象
|-------Set接口:存储无序的、不可重复的数据 --->高中讲的“集合”
|---------------HashSet:作为Set接口的主要实现类、线程不安全、可以存储null值
|---------------LinkedHashSet:HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历
|---------------TreeSet:可以按照添加对象的指定属性,进行排序
无序性:数据存放无序、数据在数组中是根据数据的哈希值来存放的,类似于哈希表
不可重复性:以HashSet为例,添加数据时,①首先计算hashcode,②根据散列函数计算数据在数组中的存放位置,③若这个位置上没有元素,就添加成功,④若这个位置上有数据,则需要比较这个位置上 链表上的元素的hashcode,若hashcode不相同,就是不同的元素,就添加成功。⑤若hashcode相同,则比较equals方法,若返回false,则是不同的元素,就添加成功
⑥如果比较equals方法时返回true,就是相同的数据,就添加失败!从而保证了不可重复性。
要求: 向HashSet添加的数据所在的类要重写equals和hashcode

2.LinkedHashSet
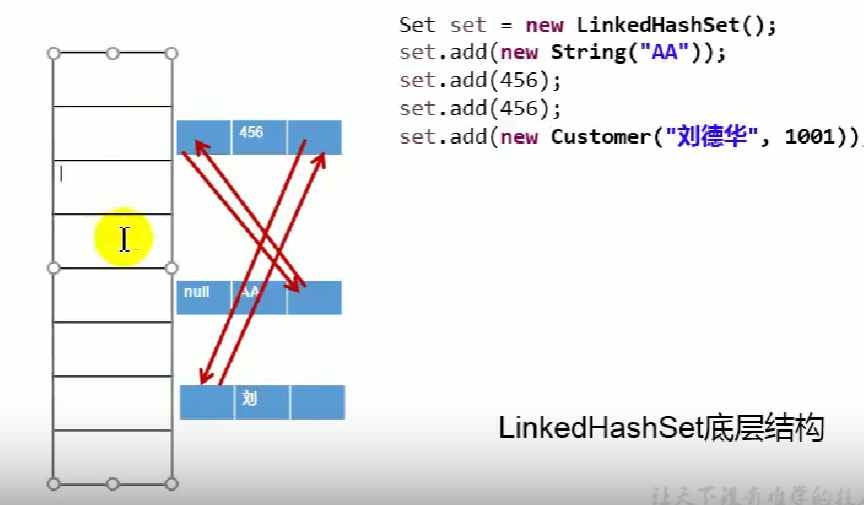
在频繁的遍历时,效率要与HashSet
3.TreeSet
向TreeSet中添加的数据,必须是同一个类的对象
两种排序方式:自然排序和定制排序
六、Map接口
1.Map接口的框架

2.Map中key-value的理解

3.jdk7及以前

4.jdk8后

5.Map接口中的常用方法

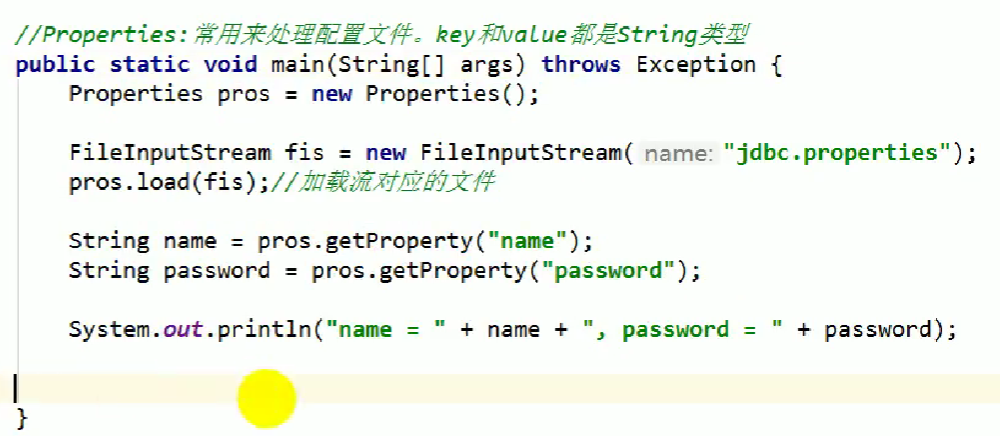
6.Properties类
七、Collections工具类的使用
看api文档



 浙公网安备 33010602011771号
浙公网安备 33010602011771号