

Scrapy 抓取数据入门操作
一、安装python
www.python.org/ 官网下载对应自己系统的安装包
二、安装scrapy
在CMD命令提示符中输入安装命令:
pip install scrapy
安装过程中如有错误会有相应提示,按照提示补充或升级安装程序即可。
最后使用scrapy命令测试安装是否成功。
三、安装pycharm
https://www.jetbrains.com/pycharm/download/#section=windows
在官网中下载Community版本(免费使用版本)
四、创建scrapy项目
在CMD命令提示符中,切换到需要创建项目的文件夹,使用一下命令创建新项目
scrapy startproject MyScrapyPrpject

在spiders目录中使用scrapy genspider myspider my.com创建爬虫
其中myspider是爬虫名称
my.com代表爬虫的作用域,之后需要根据自己实际爬取得网页进行修改
使用pycharm 打开创建好的项目得到如下所示目录:
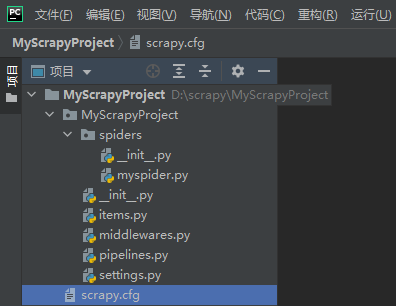
它们的作用分别是:
items.py:定义爬虫程序的数据模型
middlewares.py:定义数据模型中的中间件
pipelines.py:管道文件,负责对爬虫返回数据的处理
settings.py:爬虫程序设置,主要是一些优先级设置,优先级越高,值越小
scrapy.cfg:内容为scrapy的基础配置
值得注意的是,在学习阶段,我们要明白几点设置文件setting中的几处配置代码,它们影响着我们的爬虫的效率:
ROBOTSTXT_OBEY = True
这行代码意思是:是否遵守爬虫协议,学习阶段我们要改为False
SPIDER_MIDDLEWARES = {
'wxz.middlewares.WxzSpiderMiddleware': 800,
}
这里的数值越低,速度越快
五、爬取数据操作
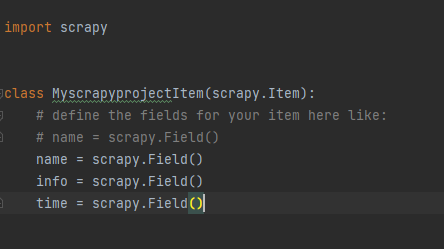
1.修改items.py文件
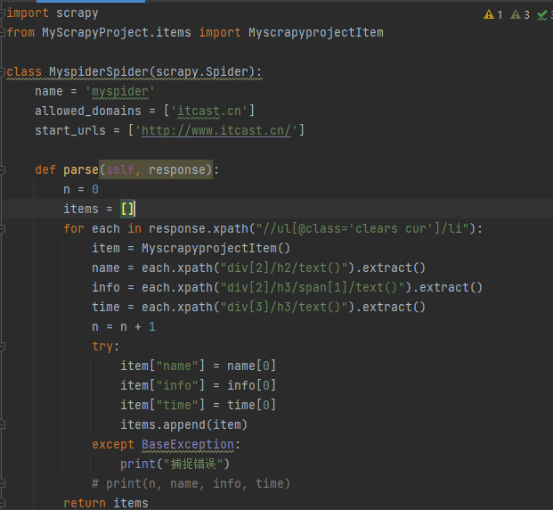
2.修改myspider.py文件
3.执行爬虫命令scrapy crawl myspider
进行相应的爬取调试
六、保存数据文件
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json
json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
xml格式
scrapy crawl itcast -o teachers.xml
保存数据出现乱码的解决方法:
保存json和txt文件,出现这种东西不是乱码,是unicode,例如:
\u96a8\u6642\u66f4\u65b0> \u25a0\u25a0\u25a
在settings.py文件中加入下面一句code,之后就是中文了。
FEED_EXPORT_ENCODING ='utf-8'
保存csv表格文件时,会出现中文乱码,这个确实是乱码,例如:
瀵掑啲瀹濈彔鎶勮鎴愬姛 鐖嗗彂浼ゅ 40涓?寮€蹇冧竴涓?
在settings.py文件中加入下面一句code,表格就是中文了
FEED_EXPORT_ENCODING = 'gb18030'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号