搜索评价指标(一)
评价指标(一)
Metrix Based on Binary Judgement
-
两个动机
- 哪一个搜索集合更好
- 哪一种排序方式更好
![]()
-
查准率和查全率/ Precision / Recall
- 查准率值指的是在检索出来的文档中, 真正的相关的文档在查询出来的文档中的比例
- 查全率值得是在所有相关的文档中,有多少文档是被正确查询出来的
![]()
- 在第一个比较的集合中,S1的precision和recall都是好于S2的,所以我们可以初步断言S1>S2
- 但是在第二个比较的集合中,S3的precison较高,但是recall较低,不好判断哪个好,这时候用到调和平均数F1,整体上, 我们认为F1高的集合查询效果更好一些
- 但是如果两个查询结果的precison和recall都一样,也就是说F1一样的话,我们怎么判断那个返回结果好呢?
![]()
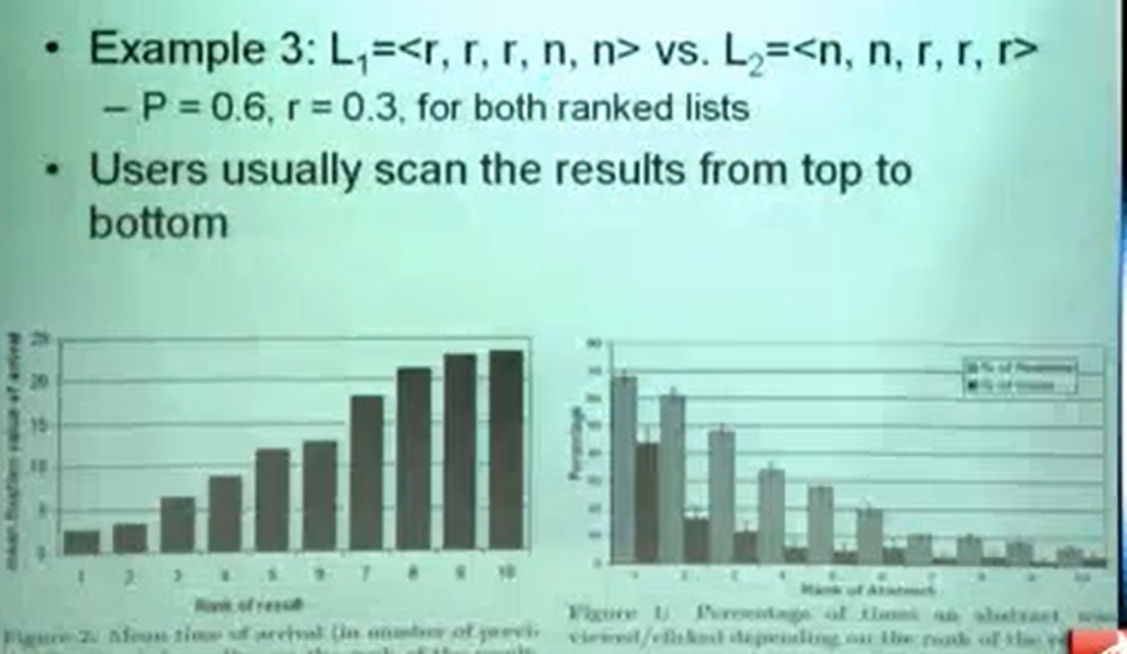
- 下面两张图表示用户查询到某个页面的点击次数,直观来说,人们通常都是从上往下来搜索想要的结果的,所以,按照这种逻辑,其实L1更好一点
-
如果去量化L1和L2的查询效果,我们可以用AP来衡量效果
![]()
- P@K:指的是前K个返回结果的Precision,针对L1和L2,我们可以用不同的前K个结果的Precision值取衡量效果
- PR Curve:比如我们P@K,K取5,那么K=1,...5, 对每一个K时候的precision和recall我们记录下这个点,那么L1就有5个点,同样的L2也能画出5个点,如果L1的点都分布在L2点的上方,那么我们认为L1的结果要更好
- AP公式中,R是所有相关文档的个数,n是所有查询到的文档总数,rel(di)指的是在所有查询结果中,和query相关或不相关,可取0,1,P@i K取i的时候precision
-
MAP指标
- 其实就是用户给了若干个query后的平均AP,Q就代表用户查询次数
-
R-Recall 和 RR
![]()
- R-Recall :比如说在一次查询中,有10个文档是相关的,我们取top-k个去计算recall和precision,其实就是子集的概念
- RR: 含义:应该被排在第一的相关文档实际上被排在了第几名,计算结果取倒数
- 比如查询,中国人民大学,我们想要在第一位就查到他,但是在第4个结果才出现,那么RR = 1/4
-
以上便是基于Binary 的Judgement




Metrics Based on Graded Relevance(分级)在实际中被广泛使用
-
含义:在Binary Judgement中,我们对于每一个返回的结果,要么是判断为相关,要么是不想关,这样其实是不好的,类似于对一个知识点的掌握,用掌握了和没掌握来表示其实并不合适,而Graded Relevance就是一个对返回结果分级打分策略,分为:相关,不相关,非常相关或。。
-
![]()
-
NDCG(Normalized disconted cumulated gain)
- 两个假设:
- high relevent 是要比relevent要好的,relevent是要比irrelevant要好的
- 相关性越高,越应该被排在前面,其实相关性的定义不是绝对的
- CG 累计的Gain:理解成每个文档能给用户带来的好处,此处用0,1,2来打分,即Gi是认为定义的
![]()
- DCG(打折的CG)
- 在上面的例子中,计算出来的CG是一样的,但能说两个一样好吗,其实不是,CG只满足了NDCG的第一条假设,即越相关分越高,但是还没考虑位置信息,所以要对不同的位置打折,和attention机制类似
![]()
- b表示从b往后,文档的Gain就要Discount
- NDCG(标准化的CG)
![]()
- 假设有一个最好的ranking结果,计算出它的DCG作为idealDCG,标准化就是每个结果除以它,让每个结果落在0-1之间
- 在实际中,NDCG有很多变种,上图中的DCG-k是比较常用的
- GAP (Graded Average precision):其实就是对打分策略做了改进
- 两个假设:
-
bpref
- 这个指标主要是解决对返回的list中,不知道是否相关的页面该如何处理的问题。、
![]()
- 其中n是在前R个排序结果中混进来的不相关的文档个数






 浙公网安备 33010602011771号
浙公网安备 33010602011771号