信息检索概览
典型的信息检索架构
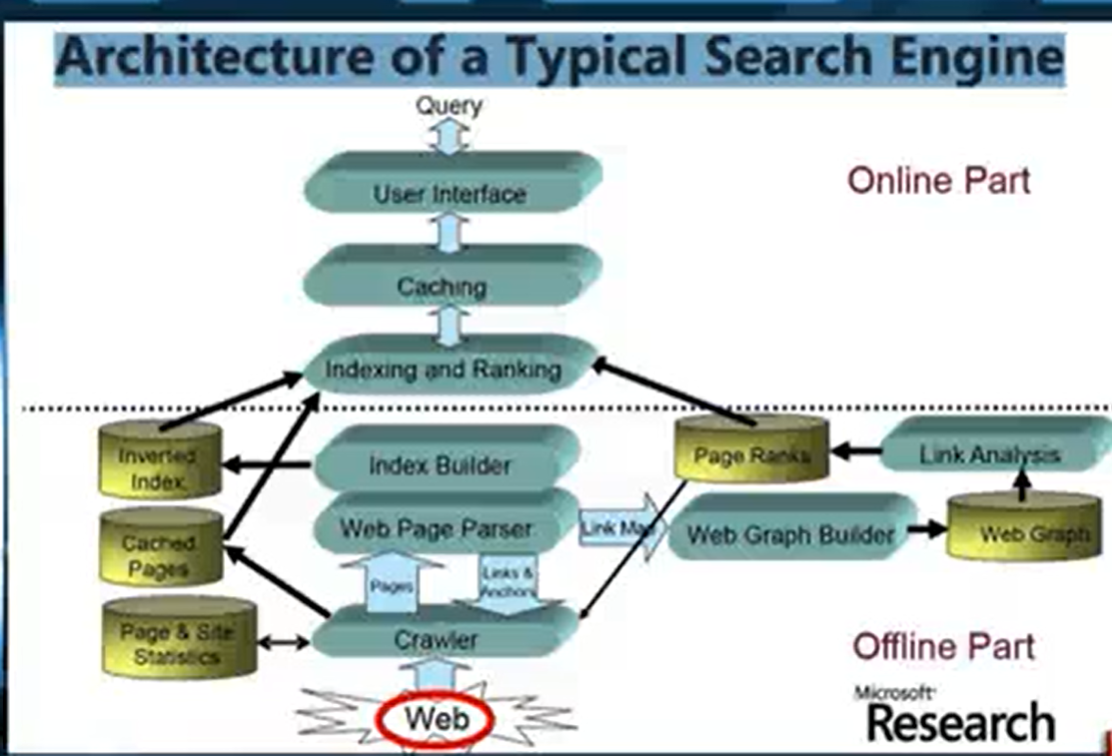
第一步
- 网站爬取:内部主要存储大量的超链接,维护消息队列,与网页解析器解析出来的新超链接交互
- crawl是需要进行不断更新的
- 和cache进行交互,cache会存储一些统计信息,比如网站有多大,更新频率等信息
第二步
- 网页解析,根据爬取的网页url,专区网页中的信息,将抓取到的URL再送回crawl的抓取队列中
- 网页解析出的URL还会放到webpageGraph中进行链接分析,如PageRank
第三步
- 建立倒排索引
第四步
- index and Ranking
- 首先根据倒排索引找到相关网页
- 对网页进行排序
第五步
- caching:存储高频网页,加快检索速度
一些假设


 浙公网安备 33010602011771号
浙公网安备 33010602011771号