
Python 爬虫从入门到进阶之路(十六)
.jpg) Python 爬虫从入门到进阶之路(十六)Python 用于专门爬取网站信息的框架 Scrapy 以及实现 《糗事百科》糗事爬取。
Python 爬虫从入门到进阶之路(十六)Python 用于专门爬取网站信息的框架 Scrapy 以及实现 《糗事百科》糗事爬取。
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了《糗事百科》的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy。
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图
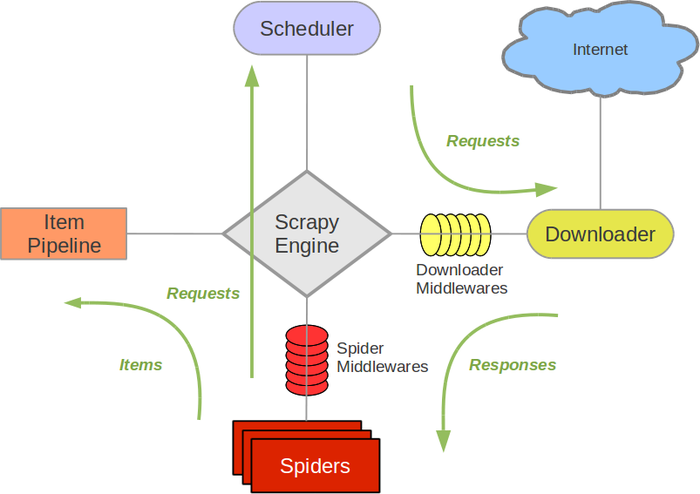
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
我们可以通过 pip install scrapy 进行 scrapy 框架的下载安装。
接下来我们就来创建一个简单的爬虫目录并对其中的目录结构进行说明。
首先我们进入我们的工作目录,然后在终端运行 scrapy startproject qiushi ,这样我们就创建了一个叫 qiushi 的基于 scrapy 框架构建的爬虫项目,目录结构如下:
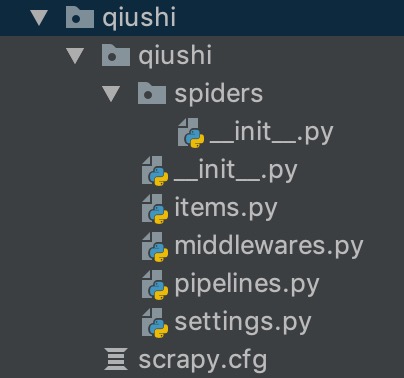
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
qiushi/ :项目的Python模块,将会从这里引用代码
qiushi/items.py :项目的目标文件
qiushi/middlewares/ :项目的中间件
qiushi/pipelines.py :项目的管道文件
qiushi/settings.py :项目的设置文件
对于目录中的 __init__.py 文件,是一个空文件,我们可以不去管理,但是也不能删除,否则项目将无法运行。
items.py 使我们要写代码逻辑的文件,相关的爬取代码在这里面写。
middlewares.py 是一个中间件文件,可以将一些自写的中间件在这里面写。
pipelines.py 是一个管道文件,我们爬取信息的处理可以在这里面写。
settings.py 是一个设置文件,里面是我们爬取信息的一些相关信息,我们可以根据需要对其进行球盖,当然也可以按照里面给定的默认设置。
接下来我们就来爬取一下之前我们爬取过的糗百的内容。
我们要爬取的网站是 https://www.qiushibaike.com/text/page/1/ 。
我们通过 Xpath Helper 的谷歌插件经过分析获取到我们想要的内容为: //div[contains(@id,"qiushi_tag")]
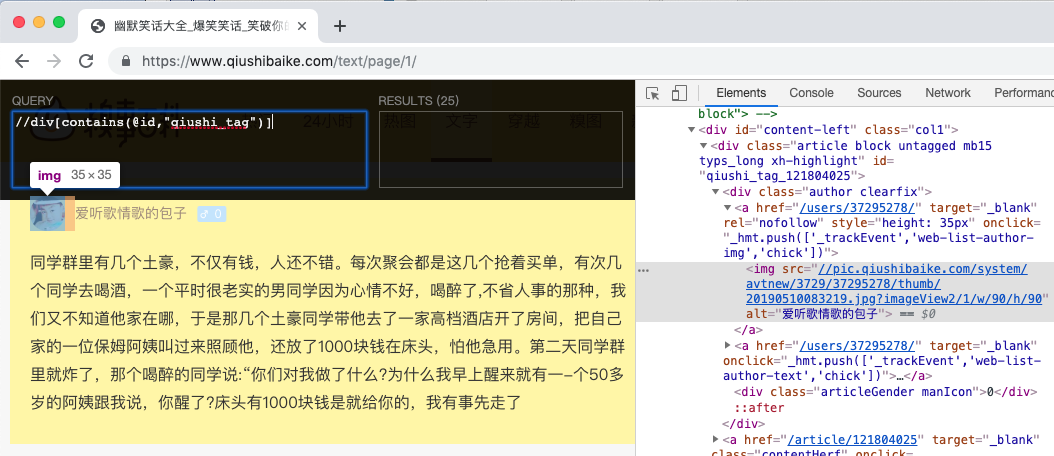
我们要爬取的是发布糗百的 作者,头像和糗事内容。
我们打开 items.py,然后将其改为如下代码:
1 import scrapy 2 3 class QiushiItem(scrapy.Item): 4 # define the fields for your item here like: 5 name = scrapy.Field() # 作者 6 imgUrl = scrapy.Field() # 头像 7 content = scrapy.Field() # 内容
然后我们在 qiushi/qiushi/spiders 文件夹下创建一个 qiushiSpider.py 的文件,代码如下:
1 import scrapy 2 from ..items import QiushiItem 3 4 5 class QiushiSpider(scrapy.Spider): 6 # 爬虫名 7 name = "qiubai1" 8 # 允许爬虫作用的范围,不能越界 9 allowd_domains = ["https://www.qiushibaike.com/"] 10 # 爬虫起始url 11 start_urls = ["https://www.qiushibaike.com/text/page/1/"] 12 13 # 我们无需再像之前利用 urllib 库那样去请求地址返回数据,在 scrapy 框架中直接利用下面的 parse 方法进行数据处理即可。 14 def parse(self, response): 15 # 通过 scrayy 自带的 xpath 匹配想要的信息 16 qiushi_list = response.xpath('//div[contains(@id,"qiushi_tag")]') 17 for site in qiushi_list: 18 # 实例化从 items.py 导入的 QiushiItem 类 19 item = QiushiItem() 20 # 根据查询发现匿名用户和非匿名用户的标签不一样 21 try: 22 # 非匿名用户 23 username = site.xpath('./div/a/img/@alt')[0].extract() # 作者 24 imgUrl = site.xpath('./div/a/img/@src')[0].extract() # 头像 25 except Exception: 26 # 匿名用户 27 username = site.xpath('./div/span/img/@alt')[0].extract() # 作者 28 imgUrl = site.xpath('./div/span/img/@src')[0].extract() # 头像 29 content = site.xpath('.//div[@class="content"]/span[1]/text()').extract() 30 item['username'] = username 31 item['imgUrl'] = "https:" + imgUrl 32 item['content'] = content 33 34 # 将获取的数据交给 pipeline 管道文件 35 yield item
接下来我们打开 settings.py,settings.py 内可以根据我们的需求自己去修改,由于内容过多,在后续的章节如果有需要用到的我们单独再说。
参考文档:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#topics-settings-ref
在该案例中我们需要做的修改如下:
1 # Crawl responsibly by identifying yourself (and your website) on the user-agent 2 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' 3 # Configure item pipelines 4 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 5 ITEM_PIPELINES = { 6 'qiushi.pipelines.QiushiPipeline': 300, 7 }
在上面的代码中,我们加入了请求报头,然后注入一个管道文件,接下来我们打开 oippelines.py 来完成这个管道文件,代码如下:
1 import json 2 3 4 class QiushiPipeline(object): 5 def __init__(self): 6 self.file = open('qiushi.json', 'a') 7 8 def process_item(self, item, spider): 9 content = json.dumps(dict(item), ensure_ascii=False) + ",\n" 10 self.file.write(content) 11 return item 12 13 def close_spider(self, spider): 14 self.file.close()
这个管道文件其实就是我们将爬取到的数据存储到本地一个叫 qiushi.json 的文件中,其中 def process_item 会接受我们的数据 item,我们就可以对其进行相关操作了。
至此我们就完成了一个简单的爬取糗百的爬虫,可以看出我们不需要再像之前那样考虑太多操作时的细节,scrapy 框架会自动为我们处理,我们只需要按照相应的流程对我们的数据做处理就行了。
在控制台输入 scrapy crawl qiubai 即可运行改程序,其中“qiubai” qiushiSpider.py 中为我们定义的 name 名,最终结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号