
BLIP3-o: A Family of Fully Open Unified Multimodal Models

BLIP3-o 是一套完全开源(权重,预训练数据集,微调数据集)、统一图像理解与生成的大模型家族,采用自回归 + diffusion 架构,并在多项图文任务中取得最优表现.
Q1:为何要用 CLIP 表征图像?
A:CLIP 特征是“语义丰富”的高层次表征,适合图文对齐,也方便统一理解与生成。
Q2:为什么 Flow Matching 比 MSE 更好?
A:MSE 只拟合平均值,结果单一;Flow Matching 模拟完整分布,支持多样化采样,生成更丰富。
Q3:BLIP3-o 跟 GPT-4o 生成图像有何区别?
A:BLIP3-o 是完全开源的统一模型,结构上与 GPT-4o 相似(自回归 + diffusion),但关键设计如 CLIP + Flow Matching 与训练策略更透明且开放。
Q4:指令微调的 60K 数据集解决了什么?
A:解决模型对人类动作、地标、文字等细粒度场景的生成能力不足问题,大幅提升“对齐”与“美感”。
引言
近年来,图像理解(Image Understanding)和图像生成(Image Generation)正逐步融合,但如何构建同时擅长这两类任务的“统一多模态模型”仍是未解之题。BLIP3-o 聚焦关键设计维度——表示方式、训练目标与训练策略——并首次系统性评估不同组合,最终提出高效统一架构,全面开放源码及数据。
动机与设计策略
为什么图文统一模型很重要?
- 多模态 AGI 的基石:理解+生成是通用智能的重要能力;
- 统一语义空间:理解和生成共享 CLIP 特征,使模型在图文空间中无缝过渡;
- 支持 In-context 多轮图文推理:比如图像编辑、视觉对话等无需切换模式。
方法详解
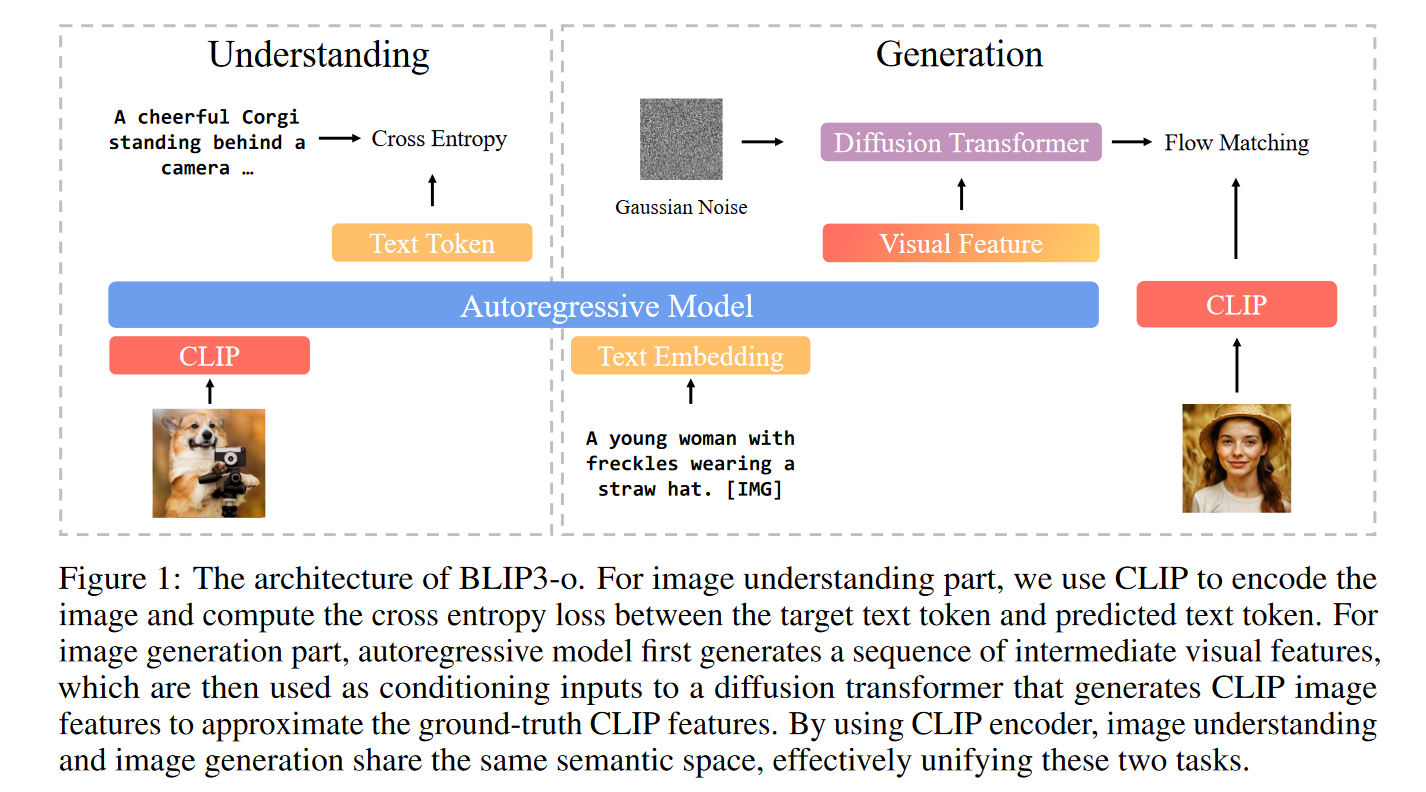
核心架构:Autoregressive + Diffusion + CLIP
BLIP3-o 使用如下三层架构:
- 自回归模块:根据文本生成中间视觉特征;
- Diffusion Transformer:将这些特征转化为 CLIP 图像特征;
- 解码器(SDXL 等):从 CLIP 表征重建真实图像。
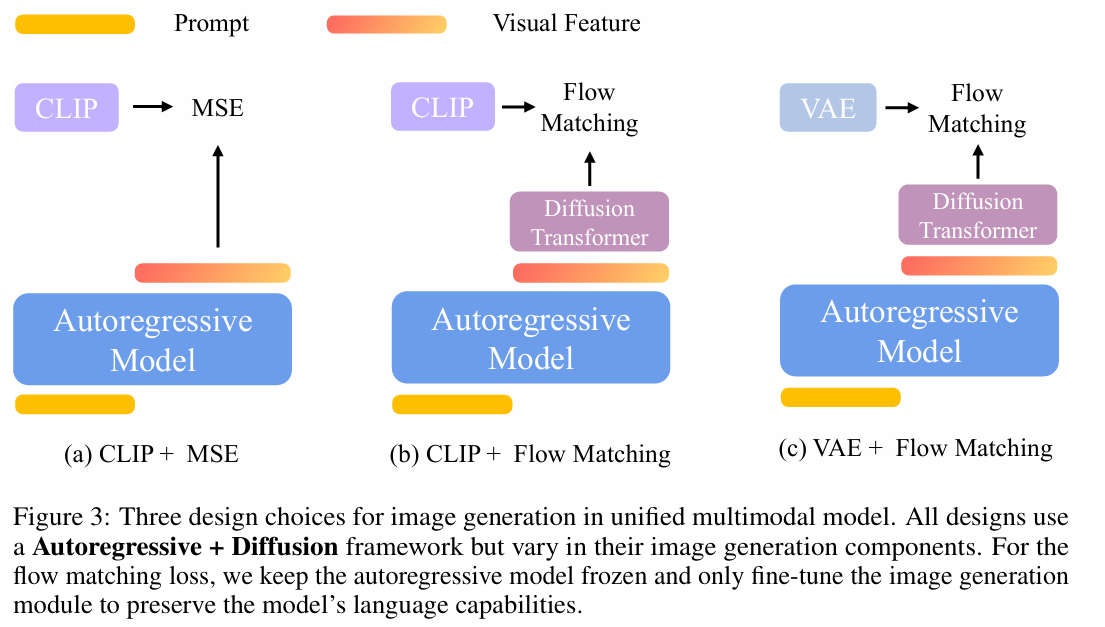
方法选择对比:编码器 × 损失函数
| 编码器类型 | 训练目标 | 优点 | 缺点 |
|---|---|---|---|
| CLIP | MSE | 简单快速,结果稳定 | 缺乏多样性,输出趋于单一 |
| CLIP | Flow Matching | 支持随机性,生成多样性高 | 模型复杂度更高 |
| VAE | Flow Matching | 重建质量高 | 表征语义弱,序列长 |
结论:CLIP + Flow Matching 是最优组合,兼顾效率与质量。
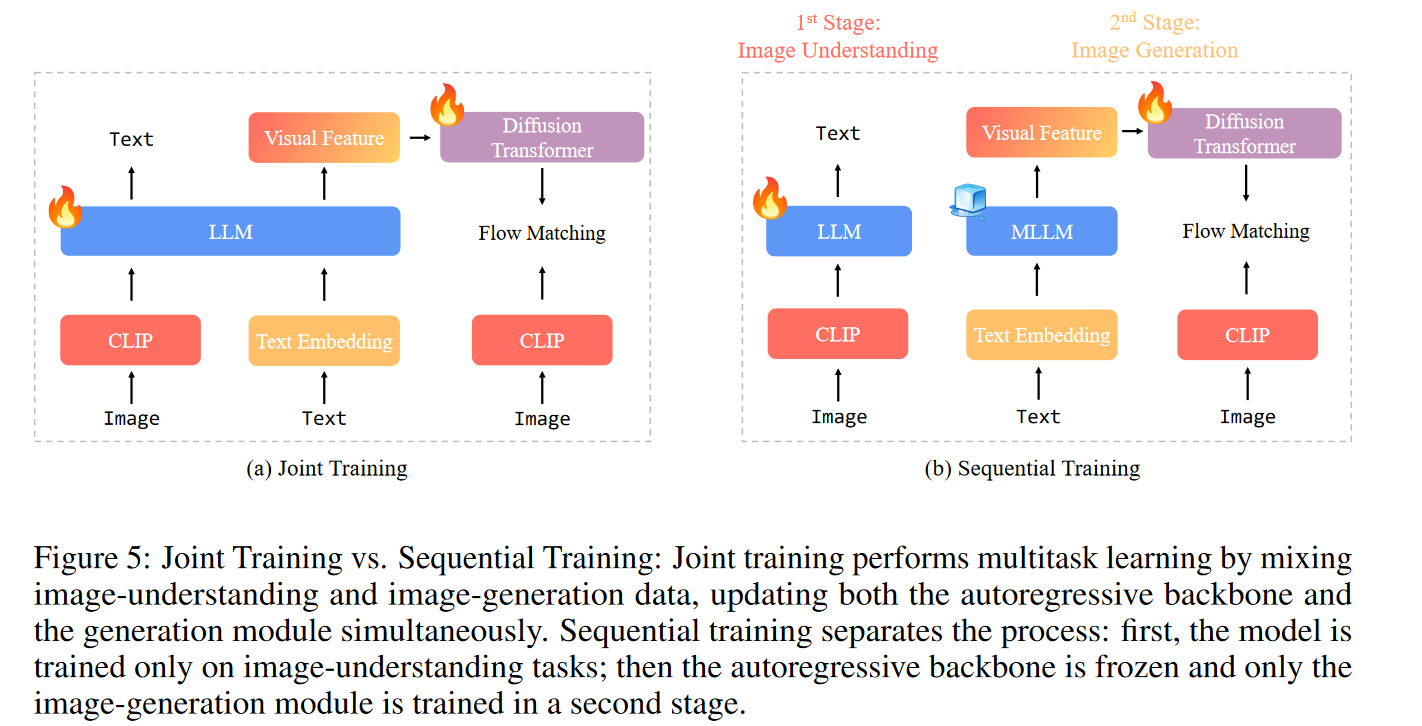
训练策略:联合 vs 顺序
- 联合训练(Joint):同时优化理解与生成模块;
- 顺序训练(Sequential):先训练理解,再冻结语言模块,仅训练生成器。
BLIP3-o 采用后者,避免干扰,提升训练效率。
模型实现与训练数据
- 使用 Qwen2.5-VL-7B 为主干,自回归部分冻结,仅训练 1.4B 的 Diffusion 模块;
- 预训练阶段覆盖 5500 万图文对,指令微调引入 GPT-4o 生成的 6 万高质量样本,强化在人、物、景、字等维度上的表现;
- 开放所有数据,包括图文对和指令调优集。
实验结果
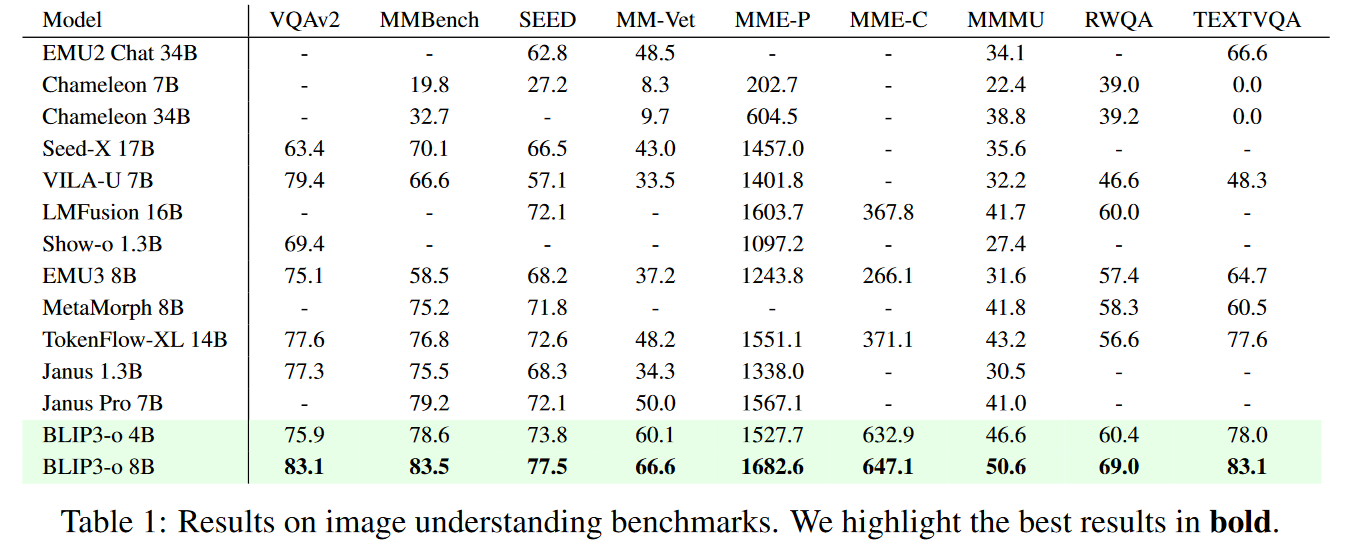
图像理解任务
在 9 个主流 benchmark 上(VQAv2、MMBench、MM-Vet 等),BLIP3-o 8B 多项排名第一。
图像生成任务
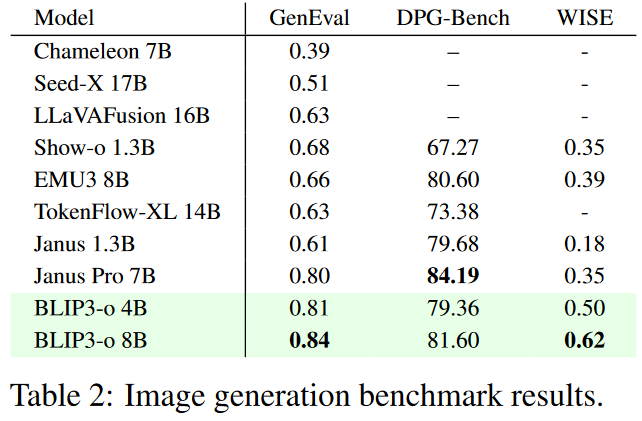
- GenEval:得分 0.84(SOTA);
- DPG-Bench(人类评分):在视觉质量和文本对齐上均优于 Janus Pro;
- WISE:展示出良好的世界知识推理能力(0.62 分)。
总结与展望
BLIP3-o 是一个开创性的工作,不仅首次系统分析了统一图文模型的设计,还在多个任务中取得领先性能,并将所有代码与数据完全开放。接下来,作者计划将其扩展到图像编辑、视觉对话与视觉推理等更复杂任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号