
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs

UniME 提出了一种利用多模态大语言模型(MLLM)学习通用嵌入表示的新框架,在多种跨模态任务中实现了显著性能提升
Q1:为什么传统 CLIP 表示不适合复杂跨模态任务?
A:因为 CLIP 的图文编码是分离的,它不能理解图像和语言之间复杂的上下文关系,尤其在长文本和多元素组合时容易丢失语义。
Q2:文本蒸馏对 MLLM 有什么好处?
A:它让 MLLM 的语言部分“继承”了判别型语言模型的嵌入能力,弥补了自回归模型只擅长生成而不擅长表示的问题。
Q3:为什么“难负样本”很重要?
A:因为“容易的负样本”训练效果有限,只有那些和正样本很接近的“难负样本”才能真正帮助模型学会细微差异。
Q4:UniME 的训练耗费资源吗?
A:不高。第一阶段使用文本输入,仅需 1~2 小时;第二阶段通过参数高效技术与小批次训练,在保证效果的前提下大幅降低资源开销。
背景
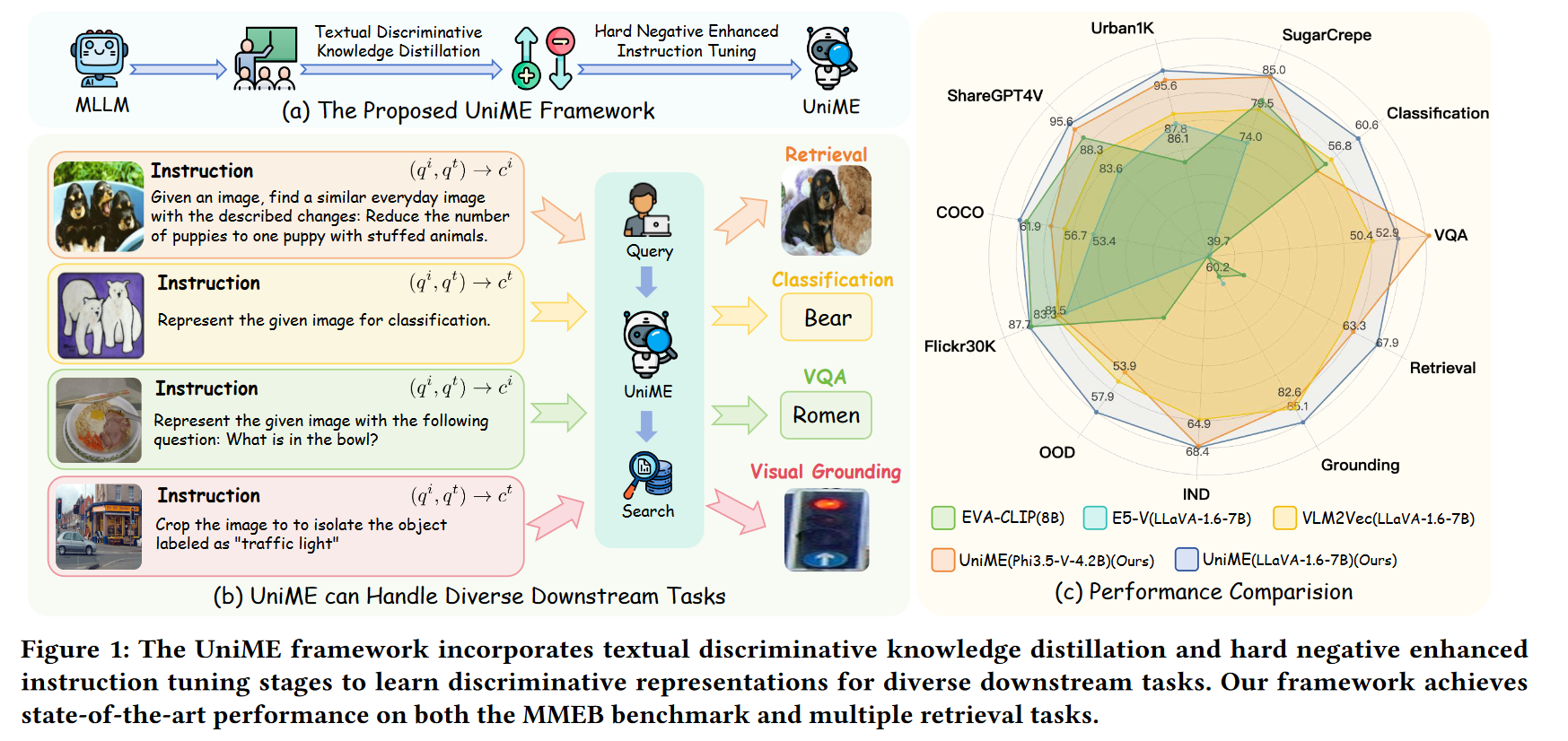
在多模态任务(如图文检索、VQA等)中,传统方法如 CLIP 虽然强大,但存在文本截断、模态隔离和组合能力差的问题。本文提出 UniME 框架,通过两阶段方法解决上述痛点,旨在充分释放多模态大模型的潜力。
动机与方法
为什么需要 UniME?
-
CLIP 的局限性:
- 文本只能处理 77 个 token;
- 图文分别编码,难以融合上下文;
- 语言建模较弱,组合表达能力差。
-
现有多模态大模型(MLLM)的问题:
- 尽管具备理解复杂指令的能力,但因自回归建模目标,缺乏强表示能力;
- 很少有方法专注于如何让 MLLM 产生具区分性的通用嵌入。
方法细节
UniME 的两阶段训练框架
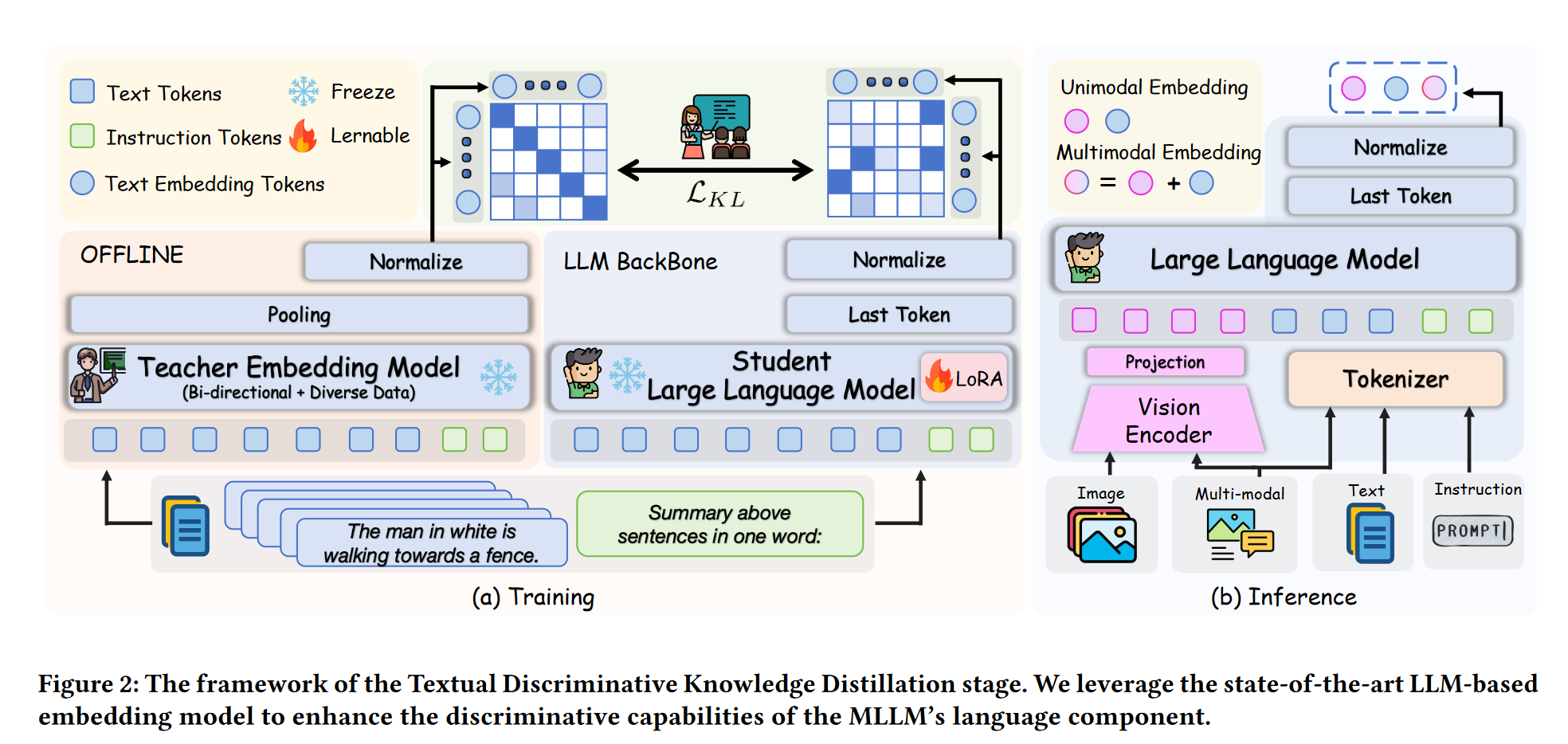
第一阶段:文本判别蒸馏(Textual Discriminative Knowledge Distillation)
- 从一个强大的 LLM 嵌入模型(NV-Embed V2)中“蒸馏”知识;
- 优化 MLLM 的语言部分,使其能生成更有判别性的文本表示;
- 使用提示词如:“Summarize the above sentences in one word”。
下图展示了蒸馏结构,通过 KL 散度最小化实现嵌入对齐。
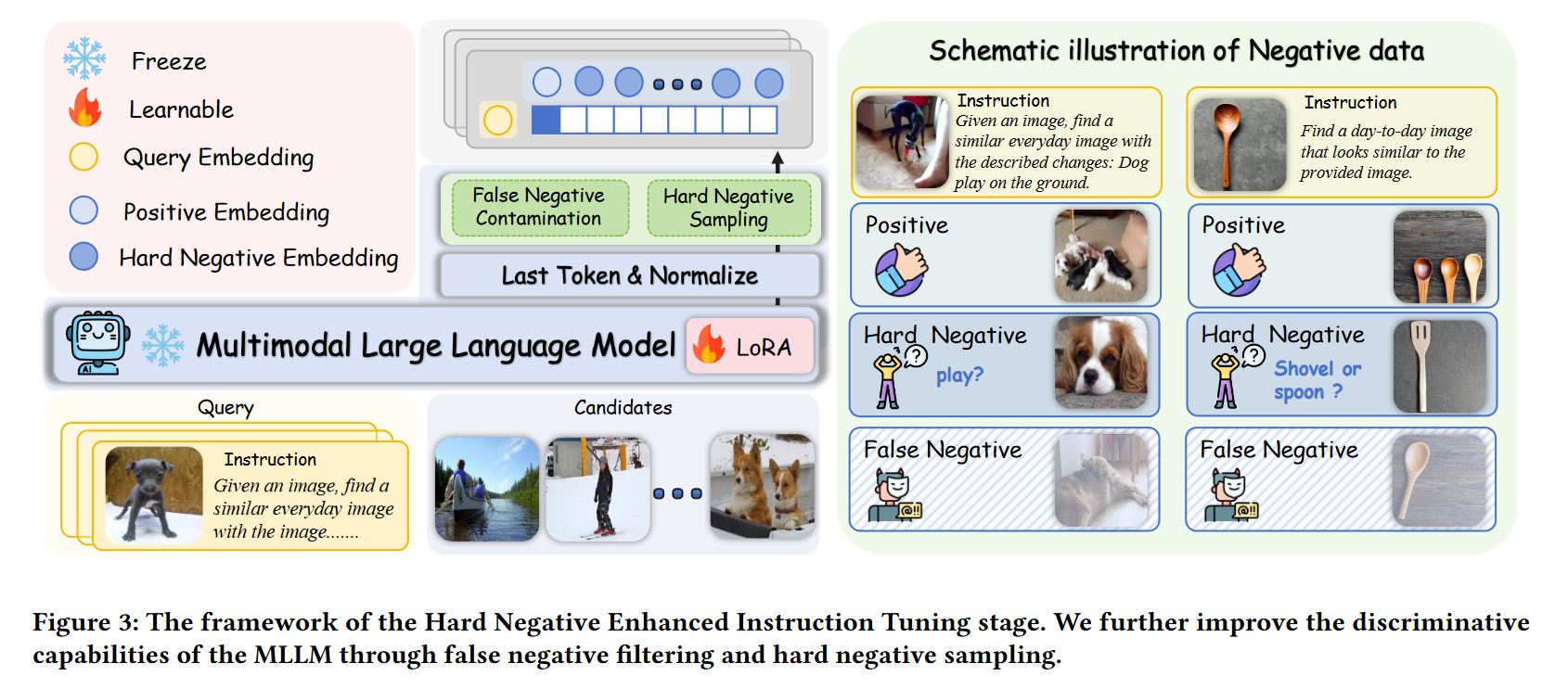
第二阶段:增强的指令调优(Hard Negative Enhanced Instruction Tuning)
- 引入“难负样本挖掘”和“误负样本过滤”策略;
- 使用任务特定提示对模型进行跨模态调优;
- 强化模型在复杂指令下的辨识与组合能力。
下图展示了难负样本训练流程,有效提高模型判别边界。
实验设计与结果
实验设置
- 训练数据:使用 NLI 文本对进行蒸馏,使用 MMEB 数据集进行调优(共 662K 对);
- 模型基础:Phi3.5-V(4.2B)与 LLaVA-1.6(7B);
- 训练时间:蒸馏阶段仅需 1-2 小时,调优阶段约 26-37 小时(8×A100 GPU)。
主要结果
MMEB Benchmark(多模态通用任务)
- 相较于 E5-V 与 VLM2Vec,UniME 在所有子任务(分类、VQA、检索、定位)中平均提升 1.3%-4.2%。
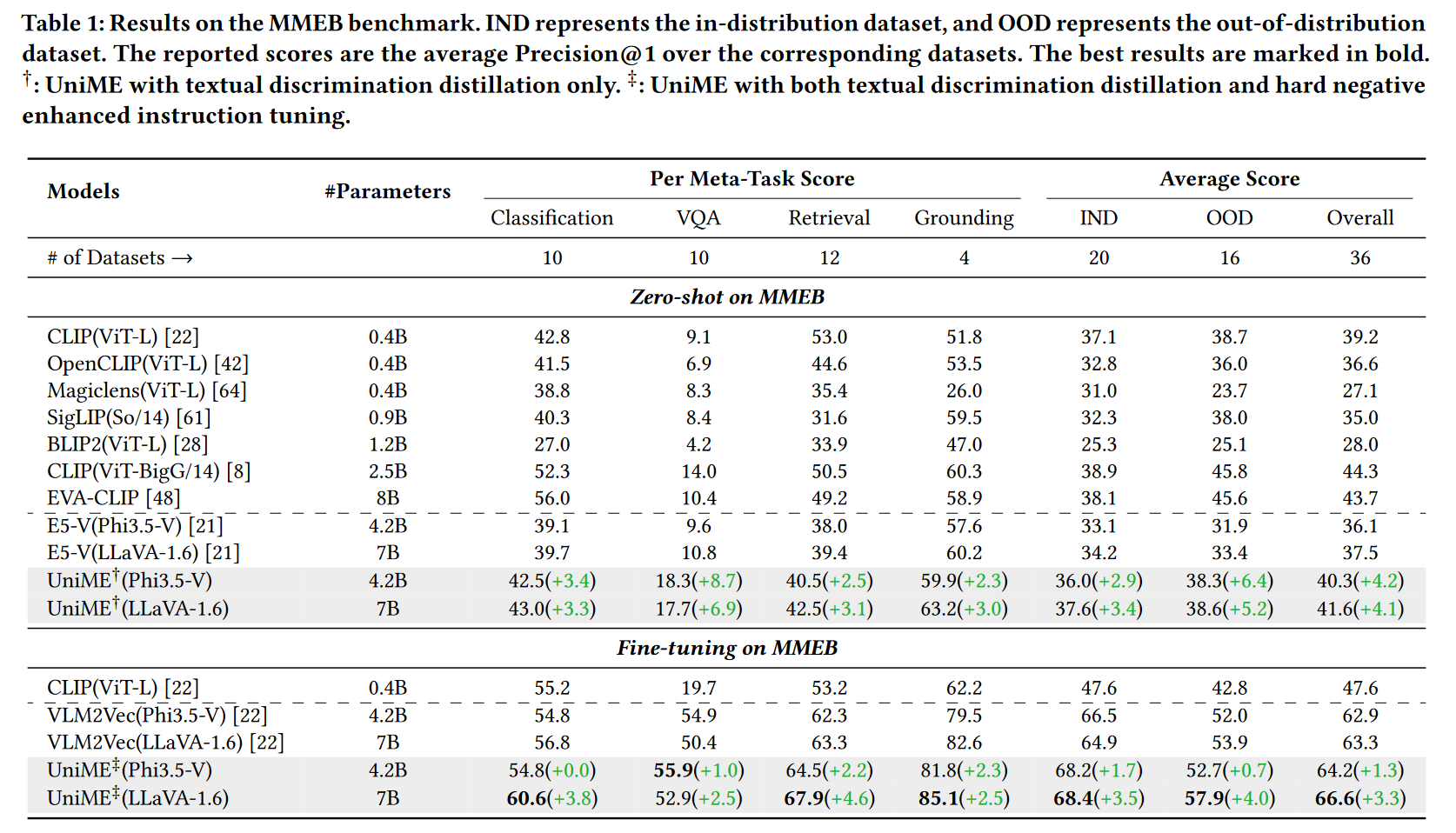
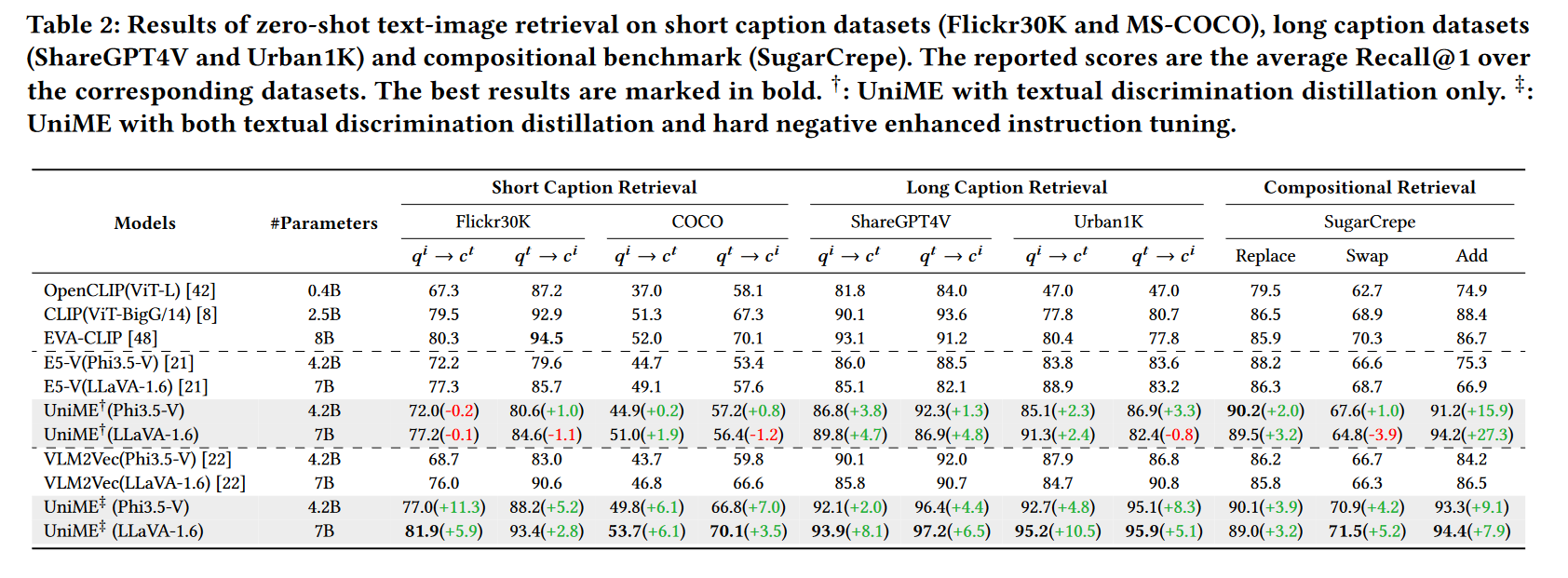
图文检索任务(短文/长文/组合)
- 长文本检索(Urban1K)上对 EVA-CLIP 提升高达 18.1%;
- SugarCrepe 组合检索任务上对 VLM2Vec 提升 9.1%。
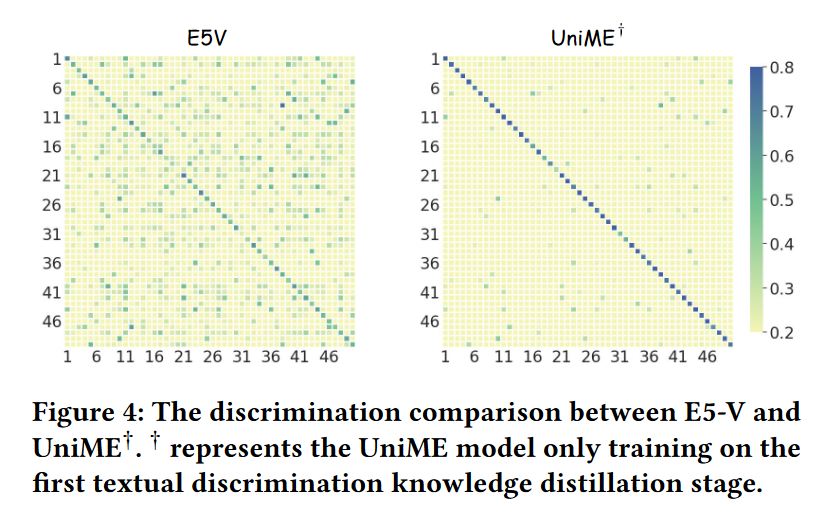
下图展示了嵌入相似度矩阵,清晰度显著提升。
总结与讨论
UniME 的关键优势在于:
- 融合式架构:利用 MLLM 本身的跨模态理解能力;
- 高效训练:基于 QLoRA 与 GradCache,实现低成本高性能;
- 泛化能力强:在多个领域任务(零样本、长文本、组合检索)中稳健表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号