
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning

VisualPRM 是首个多模态过程奖励模型(PRM),通过评估“推理过程的每一步”显著提升多模态大模型(MLLMs)的推理能力,提出了专属训练集 VisualPRM400K 与评估基准 VisualProcessBench。**
背景
多模态大模型在感知与识别方面已表现出色,但在复杂推理能力上仍落后,尤其在开源模型中。
为了解决推理能力弱、缺乏有效评价机制的问题,作者提出:
- VisualPRM:一个专门用于推理评价的多模态“过程奖励模型”(8B 参数),用于 Test-Time Scaling (TTS) 的 Best-of-N(BoN)策略。
- VisualPRM400K:400K 自动构造的过程监督数据集。
- VisualProcessBench:拥有人工标注逐步正确性的评测基准。
贡献:
- 首个多模态 PRM 数据集:VisualPRM400K
- 首个过程级别评测基准:VisualProcessBench
- 效果显著:在 7 个 benchmark 上稳定提升 MLLM 推理表现
- 文本场景也适用:在 GSM8K、MATH-500 等数据集上表现依然亮眼
动机与方法
多模态推理的挑战
- 现有 BoN 策略缺少强大的“评论员”模型(Critic):评估生成答案质量的能力不足。
- 缺乏衡量“每一步是否正确”的评测数据与基准。
核心理念
不只看“答案是否对”,更要看“每一步推理是否合理”。
方法细节
VisualPRM400K 数据集
- 每个样本包含图像 + 问题 + 步骤推理 + 每步的正确性评分(\(mc\)值)。
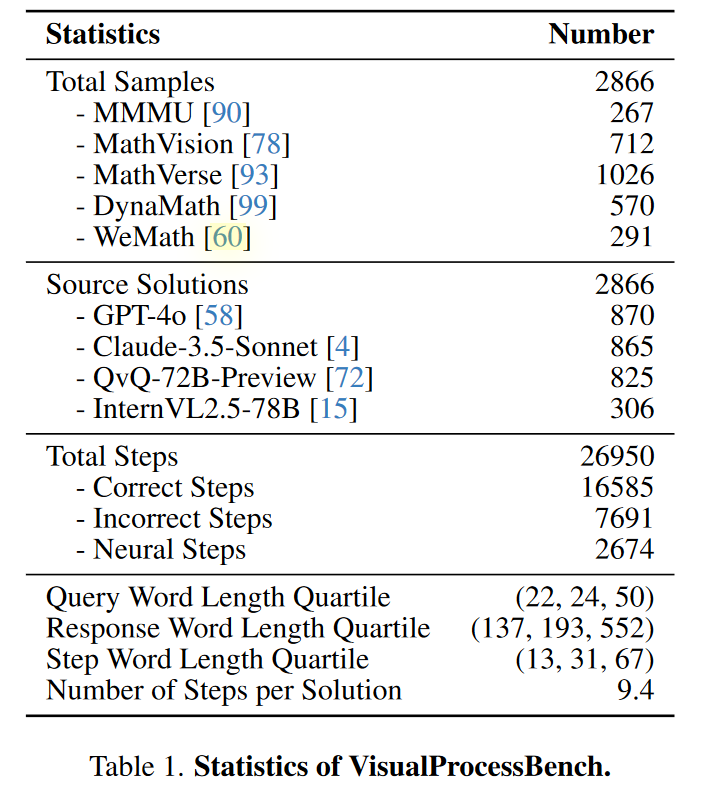
- 使用 Monte Carlo 方法生成多个推理续步,统计该步的正确性。
- 共包含约 400K 条样本,200 万步骤,平均每条回答 5.6 步。
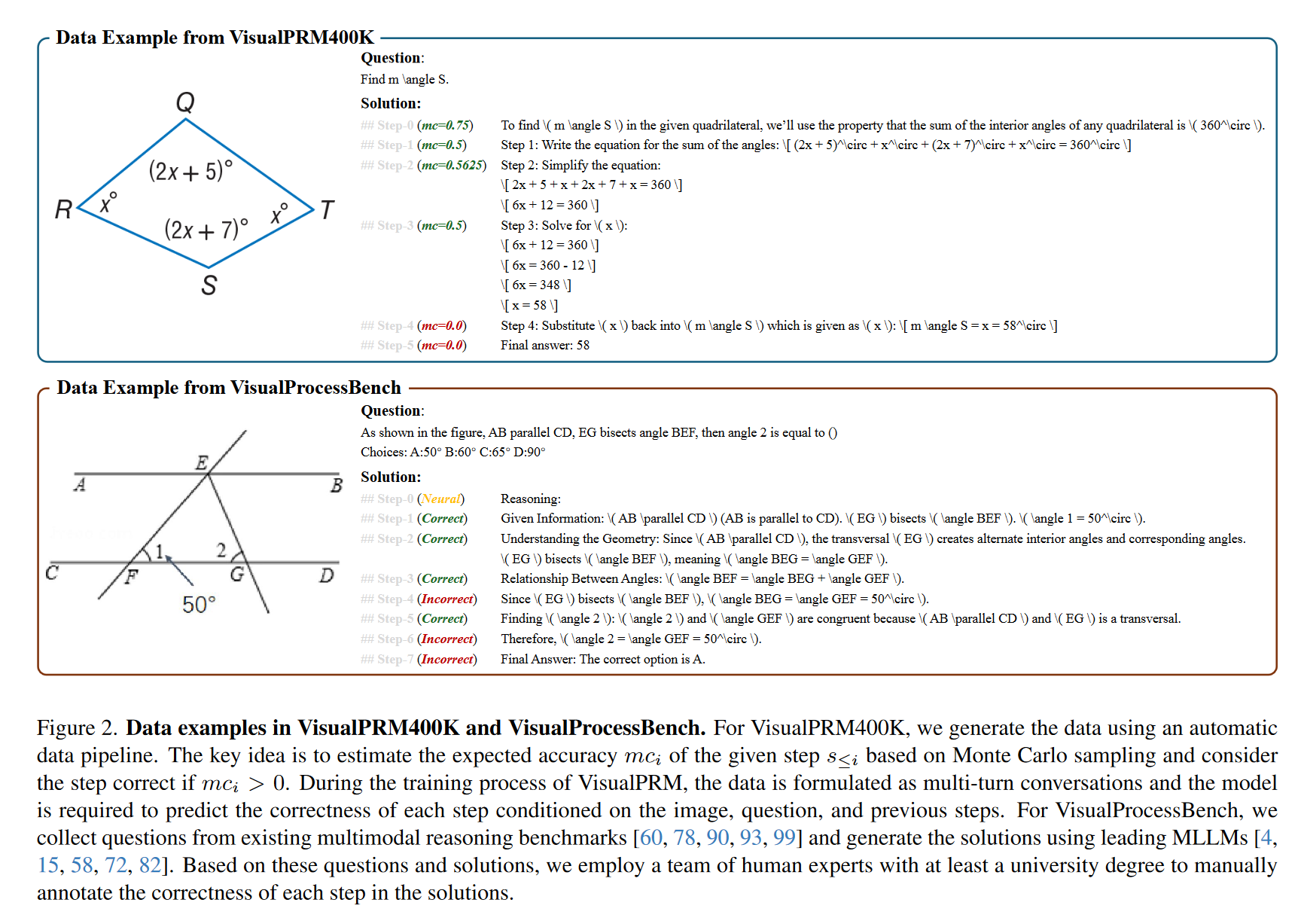
VisualPRM 模型
- 模型结构:多轮对话格式,每轮输入一个推理步骤,模型预测其质量。
- 两种评分方式:
- Value-based:判断当前步骤正确性(\(mc_i\) > 0)
- Advantage-based:看当前步骤是否优于上一步(\(mc_i - mc_{i-1}\))
- 训练策略:监督所有步骤(而不是只监督第一个错误步骤)

VisualProcessBench 评测集
- 2866 个问题,包含近 27,000 个步骤,每步有人工标注的“正/负/中性”标签。
- 来源覆盖多个数学与逻辑推理基准(如 MathVerse、WeMath、LogicVista)。
- 模型需识别所有错误步骤,而不是第一个。
实验设计与结果
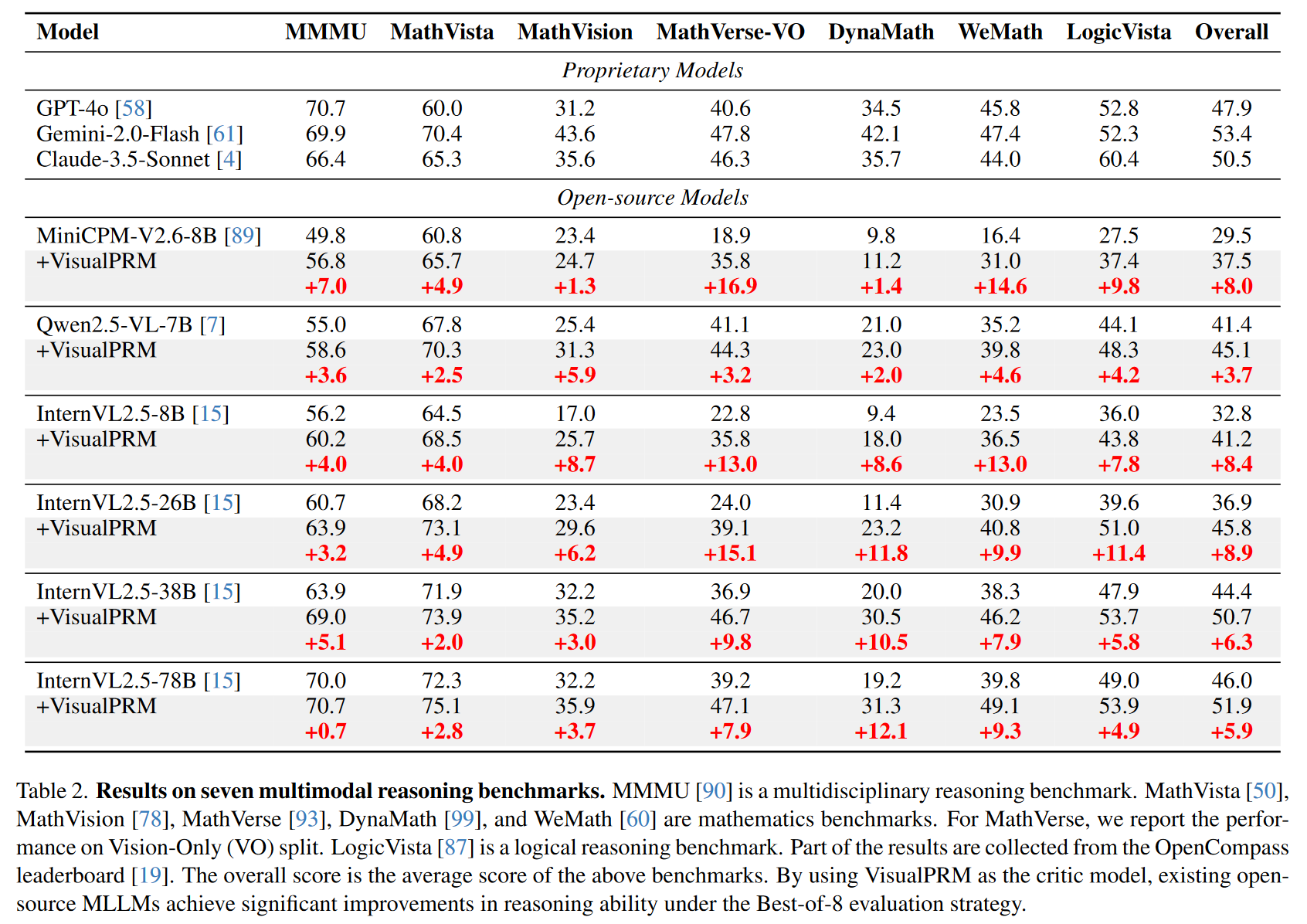
提升多模态推理表现
将 VisualPRM 应用于多种 MLLM 后,推理表现显著提升:
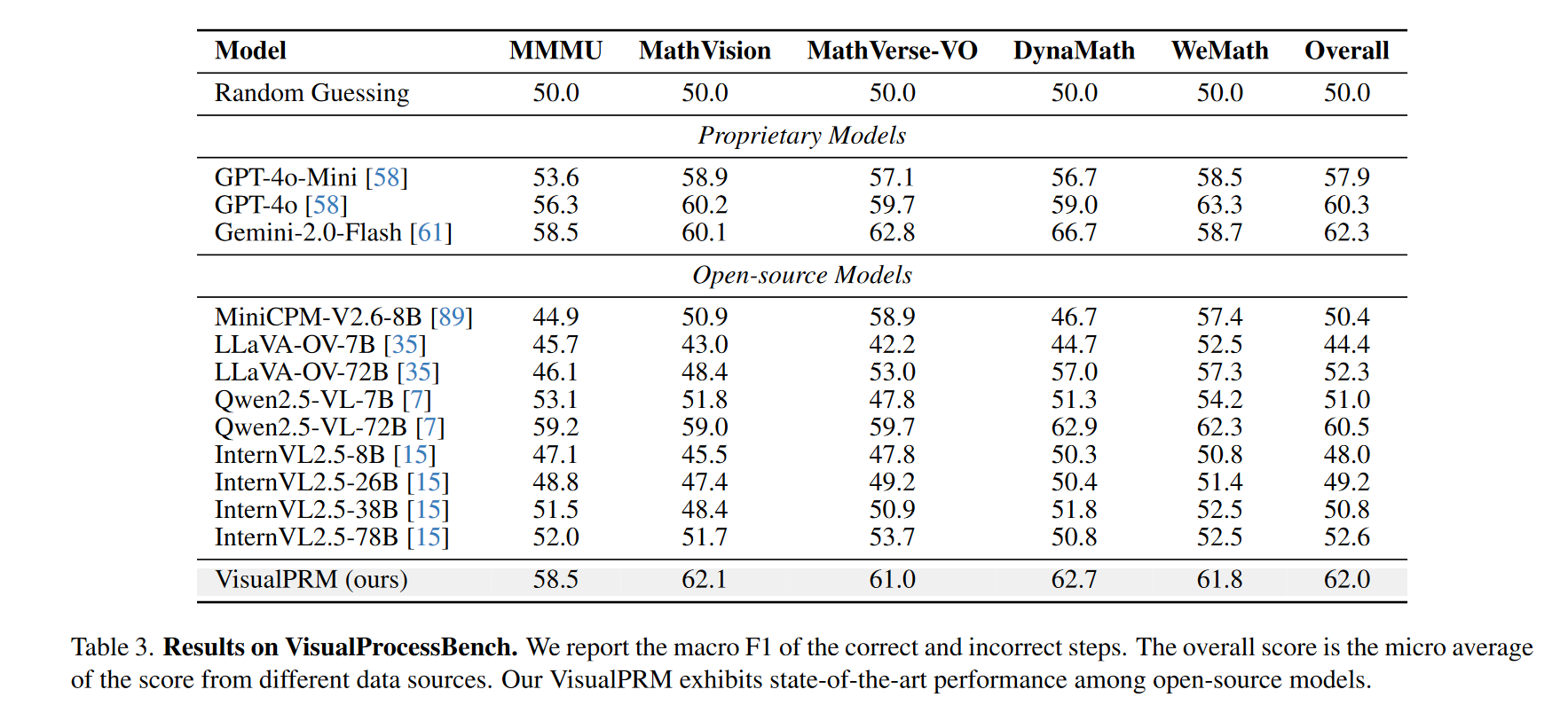
在 VisualProcessBench 的表现
VisualPRM 超过 GPT-4o 和 Gemini 等闭源模型,F1 得分达 62.0(开源最佳)。
对比分析显示:
- 现有开源模型易倾向性“判定为正确”
- PRM 能更有效识别错误步骤
总结与讨论
VisualPRM 提出了一个全新视角:将推理质量建模为一个过程而非只看最终输出,解决了 BoN 策略中“缺乏好裁判”的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号