
Qwen2.5-Omni:一个全能多模态模型的完整进化

能看图、听声音、看视频,还能实时说话、写文字,Qwen2.5-Omni 让多模态 AI 更进一步。
摘要速览
Qwen2.5-Omni 是 Qwen 团队发布的一款真正“全能型”的多模态大模型,支持文本、图像、音频、视频的输入,并能以文本和语音的形式同步输出,且具备流式处理能力。它不仅在 OmniBench 等多模态任务上表现出色,还支持高质量的语音生成和语音指令理解。
动机与方法亮点
多模态模型为何难做?
人类能同时感知声音和画面,还能通过说话或书写表达。但对 AI 来说,要统一处理各种模态输入,并同时输出语音和文字,不仅数据结构复杂,还存在训练难度与实时性挑战。
Qwen2.5-Omni 的三大创新:
-
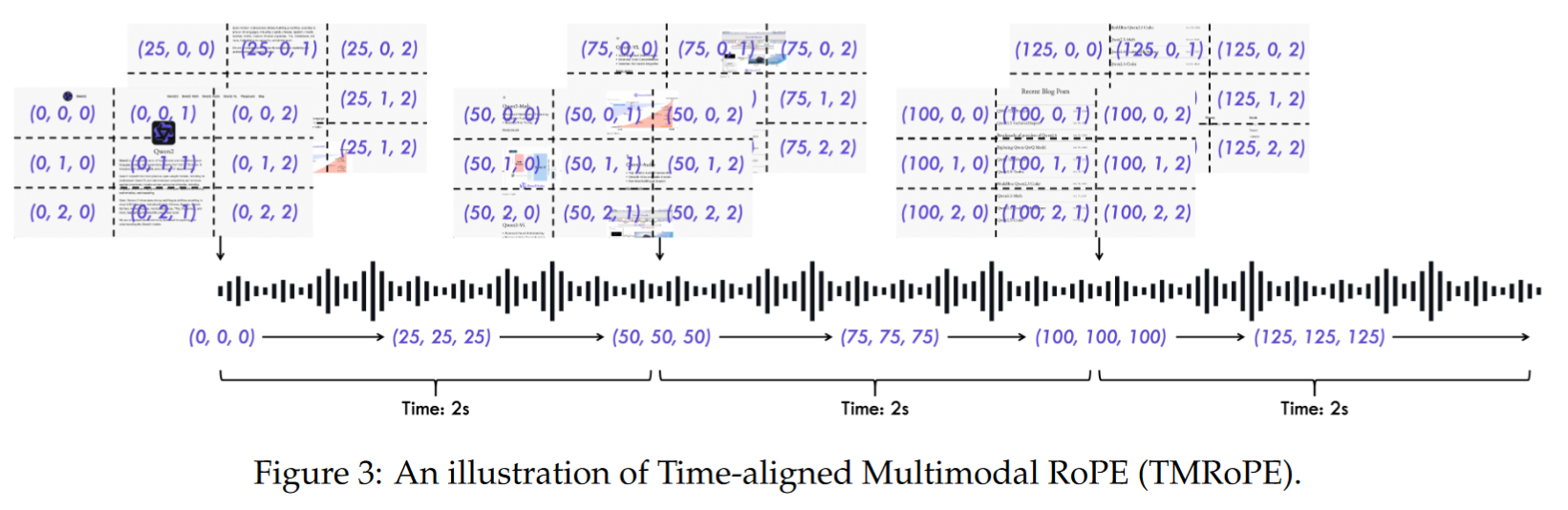
TMRoPE(时间对齐的多模态旋转位置编码):
- 解决音视频时间对齐的问题。
- 采用三维位置编码:时间、高度、宽度。
-
Thinker-Talker 架构:
- Thinker 负责文本生成;
- Talker 负责语音生成;
- 两者协同工作,实现文字与语音同步输出。
-
流式处理机制:
- 音频和视觉编码器支持按块处理;
- 使用滑动窗口注意力机制,降低语音响应延迟。
模型结构详解
架构总览
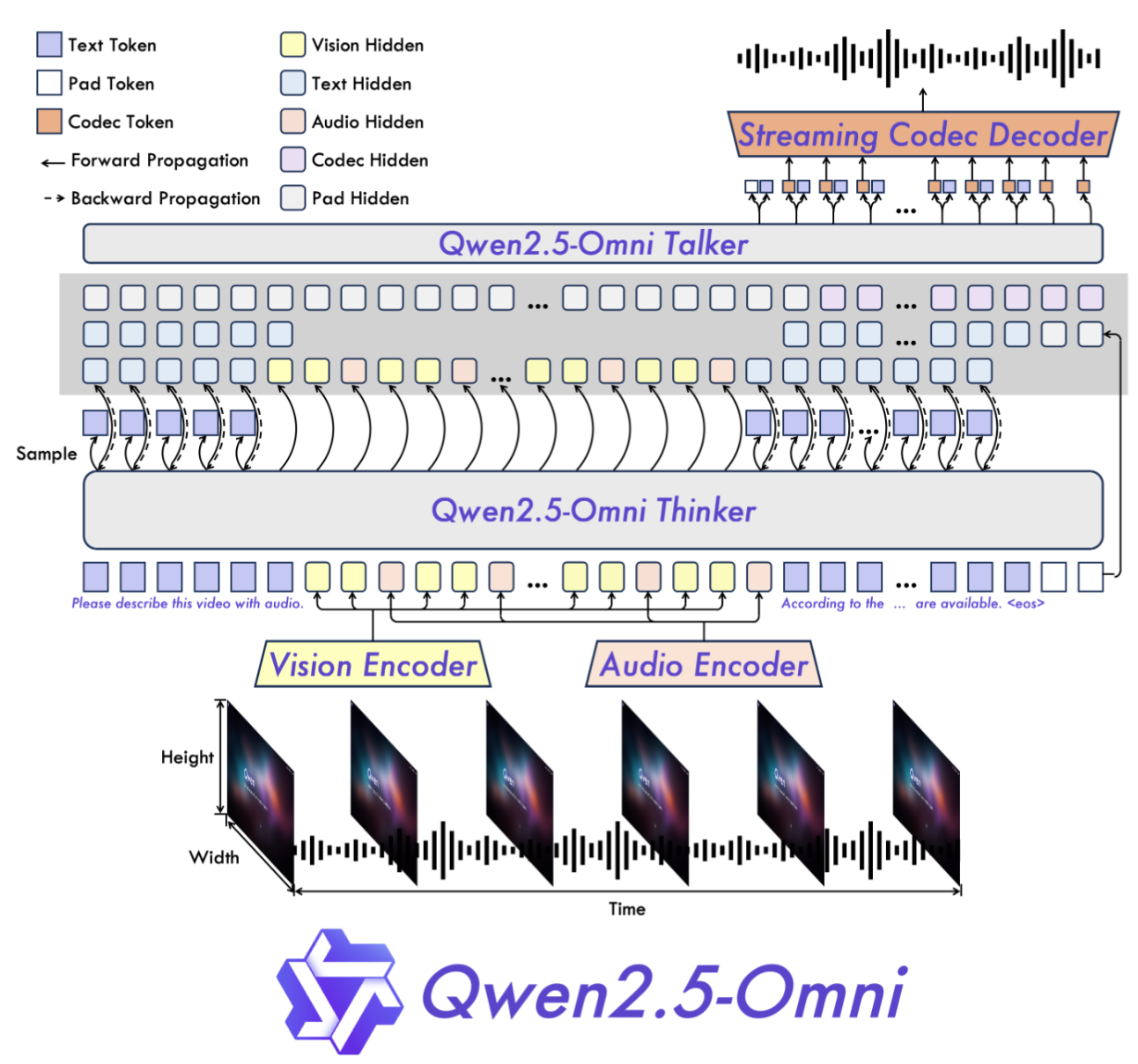
- Thinker:基于 Transformer 的解码器,处理各种输入模态并生成高层语义表示和文本。
- Talker:双通道自回归解码器,从 Thinker 获取语义信息,生成语音 token。
感知模块:TMRoPE + 多模态嵌入
- 文本:使用 Qwen 的 BPE 分词器。
- 音频:转为 Mel 频谱图(40ms/frame)。
- 图像与视频:采用 ViT 编码器,视频按动态帧率采样。
- TMRoPE:创新地编码多模态输入的时间-空间位置,支持跨模态对齐与融合。
生成模块
- 文本:标准自回归采样。
- 语音:结合高维语义和离散 token,用自研 qwen-tts-tokenizer 编码音频,Talker 流式输出语音。
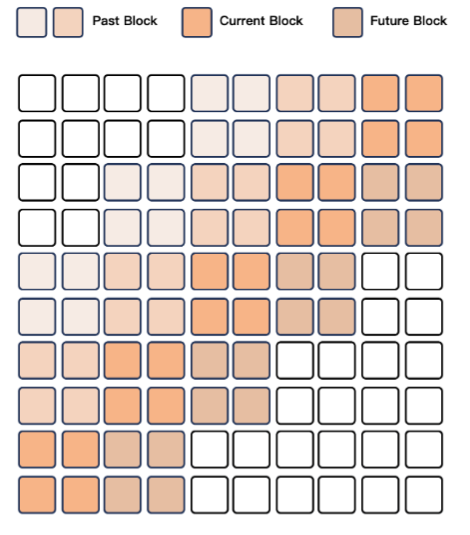
支持流式生成
- 音/视编码器按 2 秒块处理;
- DiT + BigVGAN 解码器生成连续语音;
- 使用滑窗机制减少等待时间,提升实时语音体验。
实验设计与评测结果
训练策略
- 三阶段训练:
- 冻结 LLM,仅训练音/视编码器;
- 全参数训练,多模态对齐;
- 使用最长至 32k token 的长序列预训练,增强理解能力。
多模态理解任务
- 文本任务:MMLU、GSM8K、HumanEval 等,表现一般;
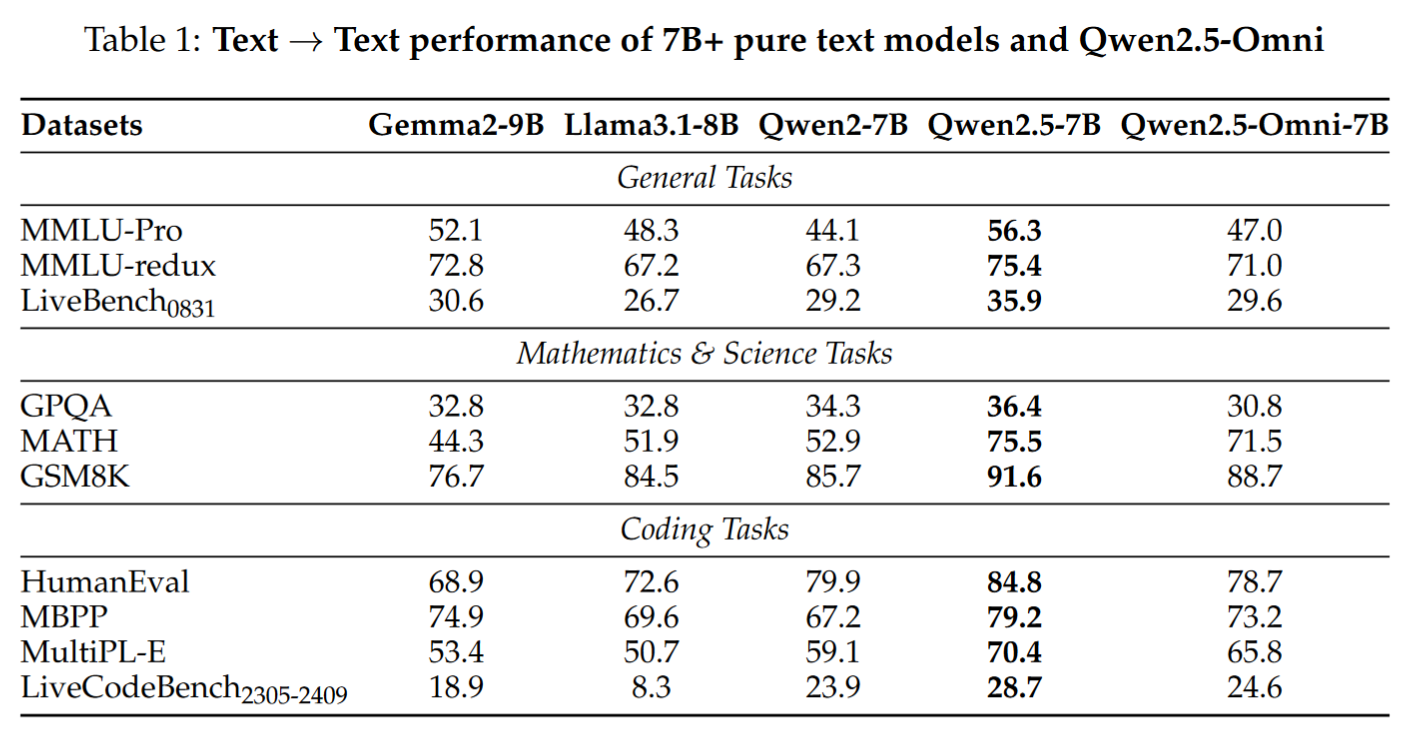
- 图像理解:在 MMBench、TextVQA、DocVQA 上超越 GPT-4o-mini,定位略胜于Qwen2.5VL-7B;
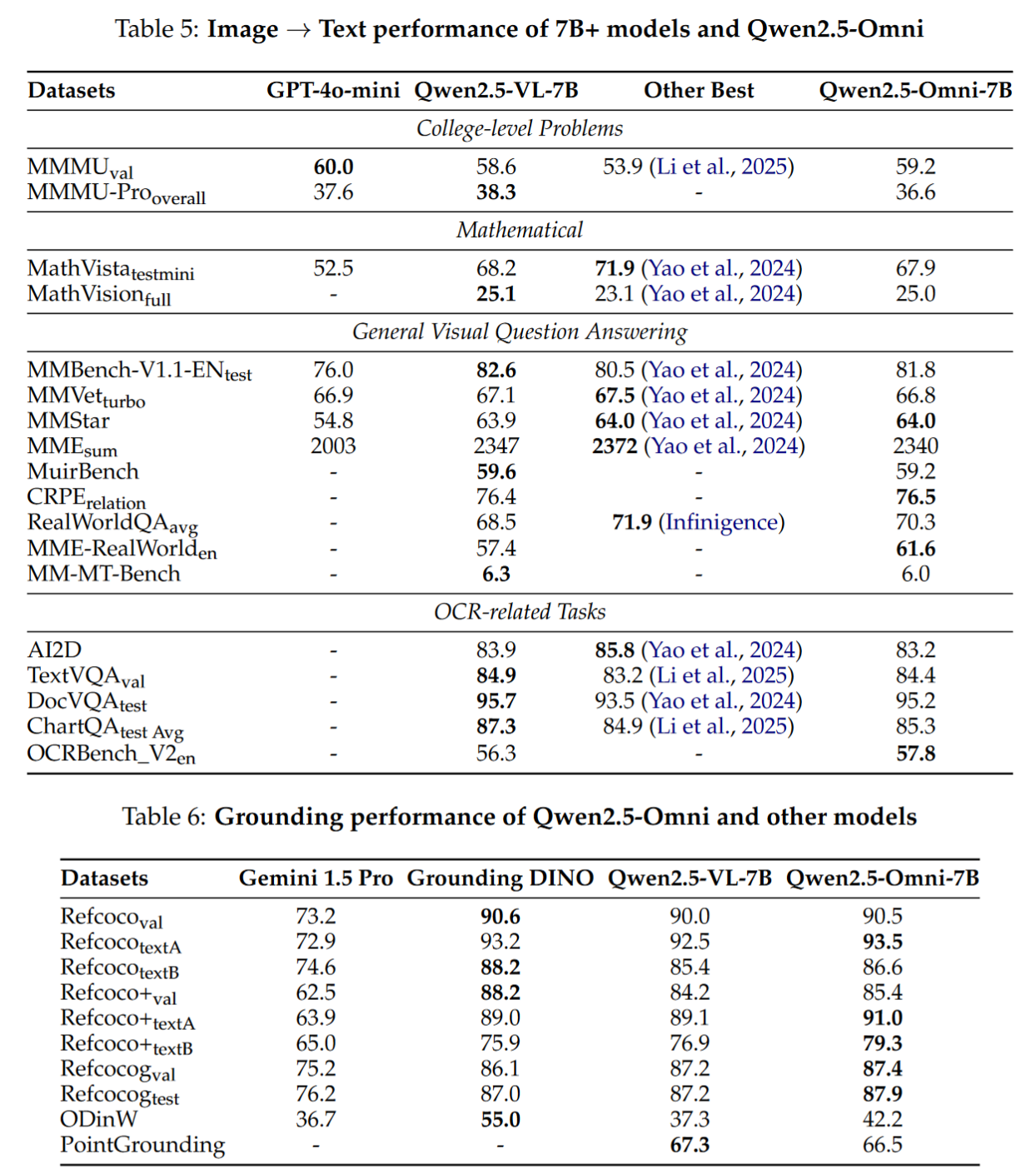
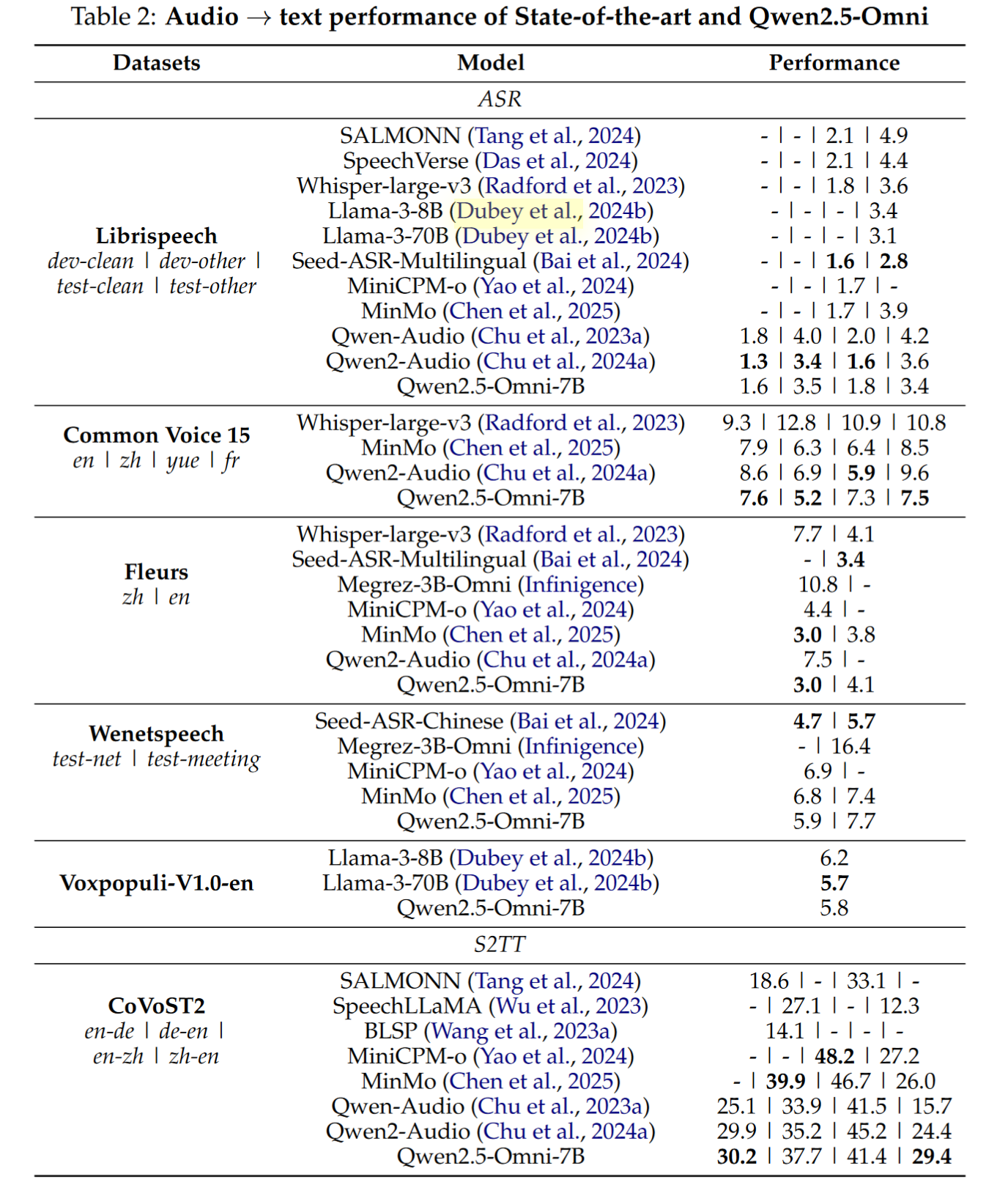
- 音频理解:在 Common Voice、Fleurs、MMAU 等数据集上优于 Whisper;
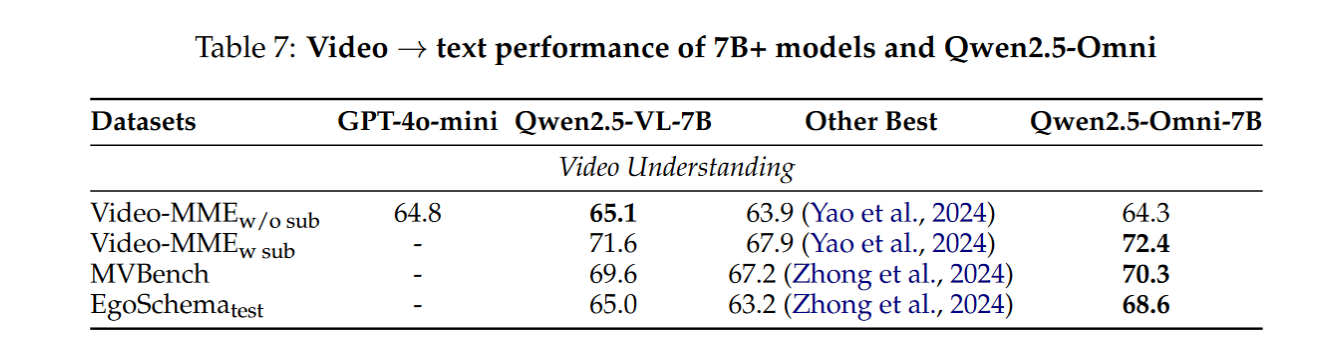
- 视频理解:在 Video-MME、MVBench 上超越同级开源模型;
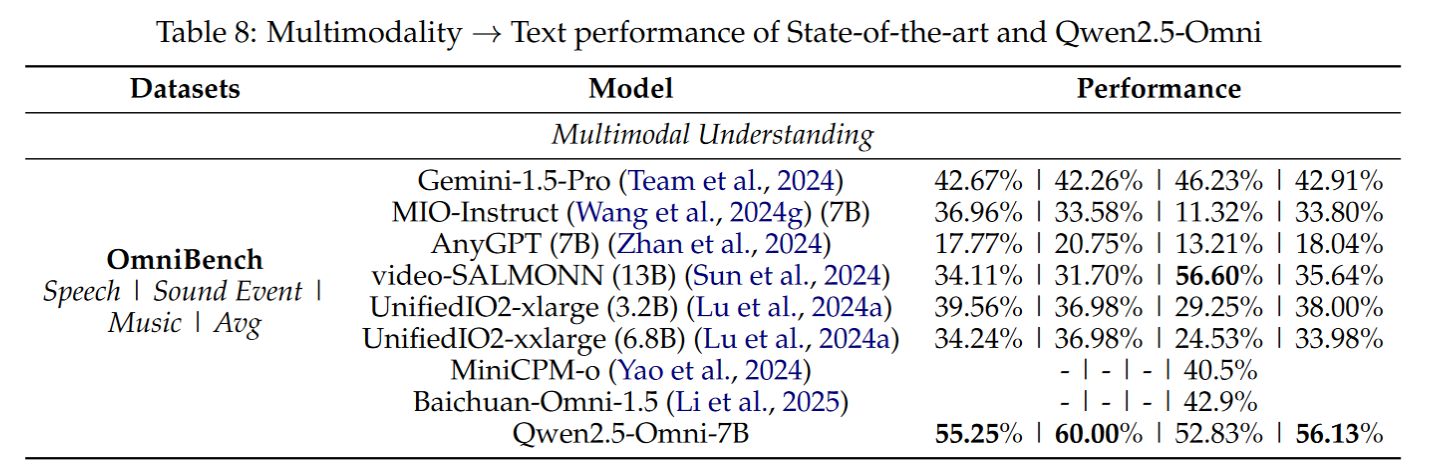
- 混合模态理解:OmniBench 上以 56.13% 平均得分夺冠。
语音生成任务
- 零样本 TTS:在 SEED 测试集上 WER 表现优于 CosyVoice 2;
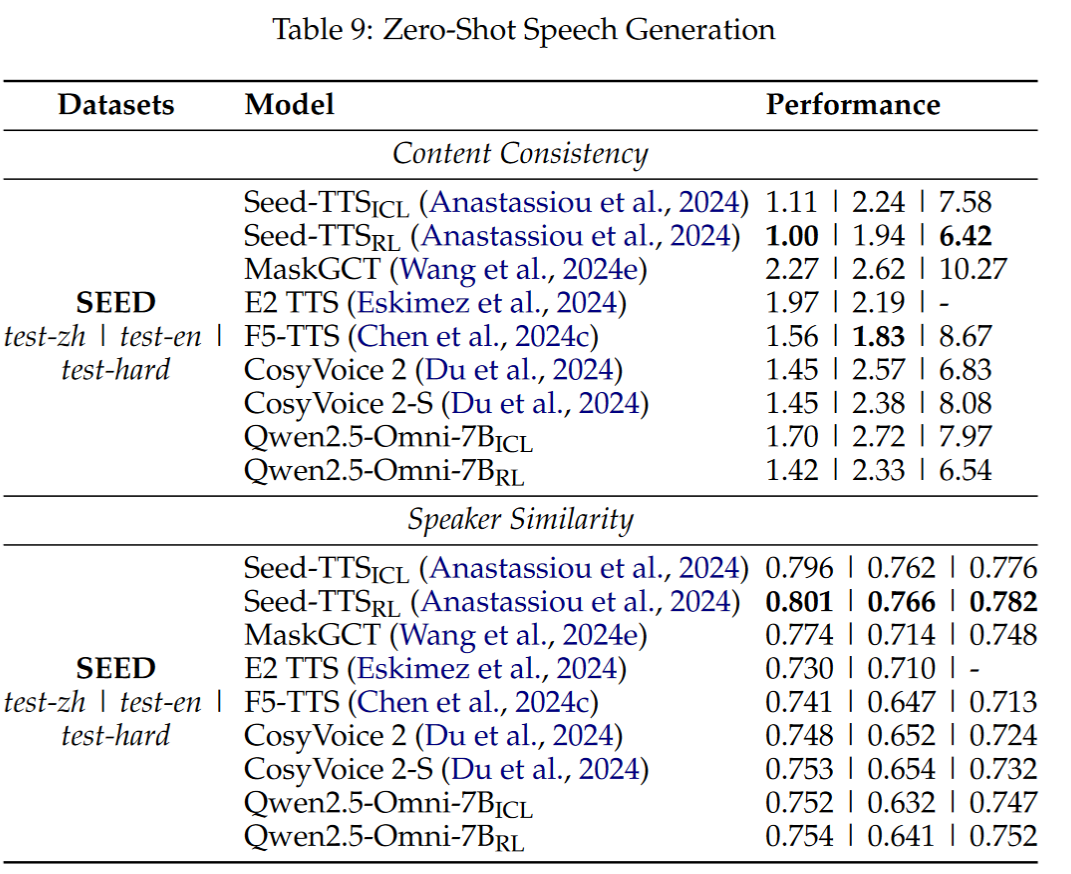
- 单说话人合成:自然度(NMOS)接近真实人声(4.5+);
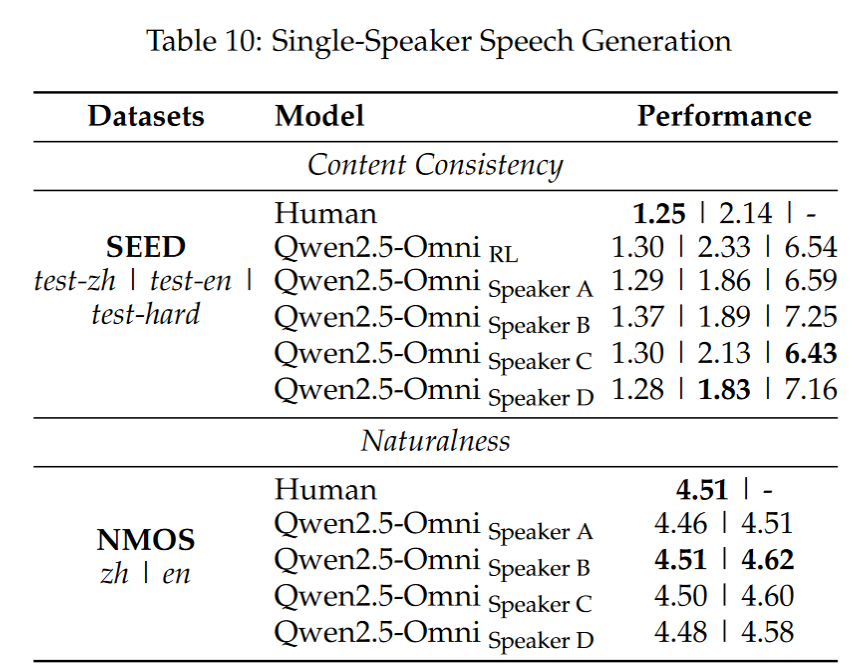
- 支持多说话人语音指令跟随与对话生成。
总结与展望
Qwen2.5-Omni 是目前开源中极具代表性的全模态大模型之一。它实现了多个关键突破:
- 真正统一的文字、图像、音频、视频输入;
- 同步输出文字与语音,具备流式响应;
- 在多模态、多任务上性能全面领先。
未来展望:
- 支持图片、视频、音乐等更丰富的输出模态;
- 更低延迟、更快响应;
- 持续扩展多模态 benchmark 和训练数据集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号