
Visual-RFT: Visual Reinforcement Fine-Tuning

Visual-RFT: RFT in VLM
主要内容
- 我们引入了视觉强化微调( Visual Reinforcement Fine- Tuning,Visual-RFT ),在有限数据微调有效的视觉感知任务上扩展了可验证奖励的强化学习。
- 我们为不同的视觉任务设计了不同的可验证奖励,以可忽略的成本实现了高效、高质量的奖励计算。这使得DeepSeek R1的风格强化学习可以无缝迁移到LVLMs。
- 我们在各种视觉感知任务上进行了广泛的实验,包括细粒度图像分类、小样本目标检测、推理背景和开放词汇目标检测。在所有设置上,VisualRFT都取得了显著的性能提升,显著超越了有监督的微调基线。
- 我们在Github上完全开源了训练代码、训练数据和评估脚本,以方便进一步的研究。
动机和方法
整体动机和方法
-
OpenAI o1:基于强化微调 (Reinforcement Fine-Tuning, RFT),仅用几十到几千个样本就能有效地微调模型,出色地完成特定领域的任务 openai.com
-
SFT范式“记忆”高质量数据中提供的答案,依赖大量的训练数据。相比之下,RFT并根据模型输出是否正确进行调整,帮助其通过试错进行学习,在数据稀缺的领域尤其有用。
-
DeepSeek R1-Zero and GRPO: Deep Seek R1 - Zero算法通过使用强化学习进行训练,特别是通过GRPO框架,消除了对SFT的依赖。与PPO等强化学习算法需要一个评价模型来评估策略性能不同,GRPO直接比较候选响应组,不需要额外的评价模型。
-
可验证奖励的强化学习 (Reinforcement Learning with Verifiable Rewards, RLVR) : 奖励分数直接由预定义的规则决定,而不是额外的奖励模型
-
探索 VLM + RLVR 路线 :将DeepSeek R1的强化学习无缝迁移到LVLMs,提出 Visual-RFT
1. Preliminary
-
具有可验证奖励的强化学习:可验证奖励的强化学习( Reinforcement Learning with Verifiable Rewards,RLVR )是一种新颖的训练方法,旨在增强具有客观可验证结果的任务中的语言模型,如数学和编码。
-
DeepSeek R1-Zero and GRPO:Deep Seek R1 - Zero算法通过使用强化学习进行训练,特别是通过GRPO框架,消除了对SFT的依赖。与PPO等强化学习算法需要一个评价模型来评估策略性能不同,GRPO直接比较候选响应组,不需要额外的评价模型。
2. Visual-RFT
输入多模态数据 --> 策略模型输出一个推理过程和回答 --> 计算奖励 --> 分组计算reward,评估每个响应的质量,更新策略模型
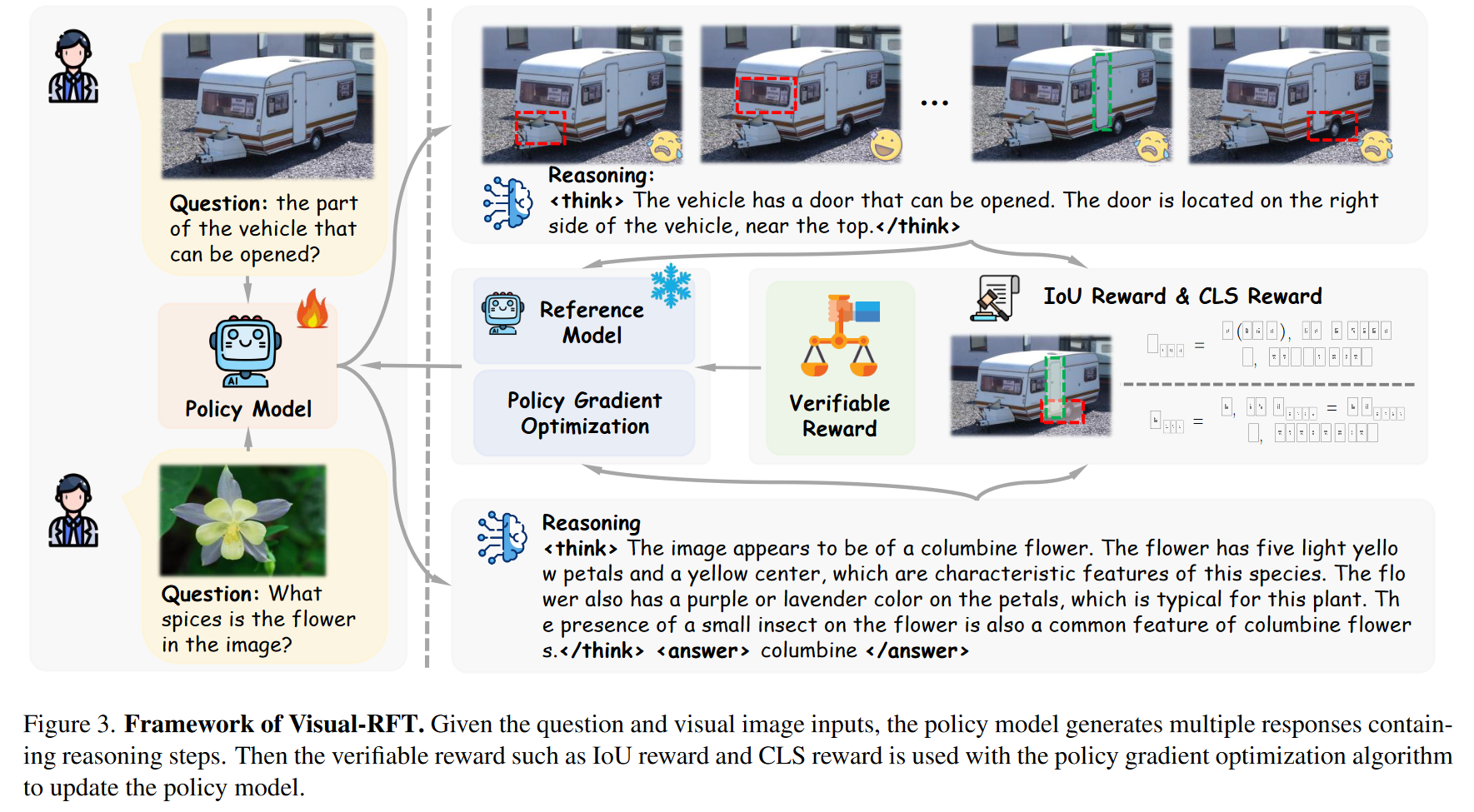
3. 视觉感知中的定量回报
奖励模型是RL中的关键
-
检测任务中的Iou奖励。对于检测任务,模型的输出由bbox和相应的置信度组成,奖励包括:IoU奖励、Confidence奖励和Format奖励(匹配是1,不匹配为0)
-
分类任务中的CLS奖励。在N个分类任务中,奖励由两部分组成:Acc奖励(分类正确是1,错误是0)和Format奖励
4. 数据组织格式
- Visual-RFT在提供最终答案之前,设计了一个提示格式来引导模型输出其推理过程。

实验分析
Visual-RFT相对于SFT的优势在于,能够对任务进行理解,而不是仅仅“记忆”训练数据
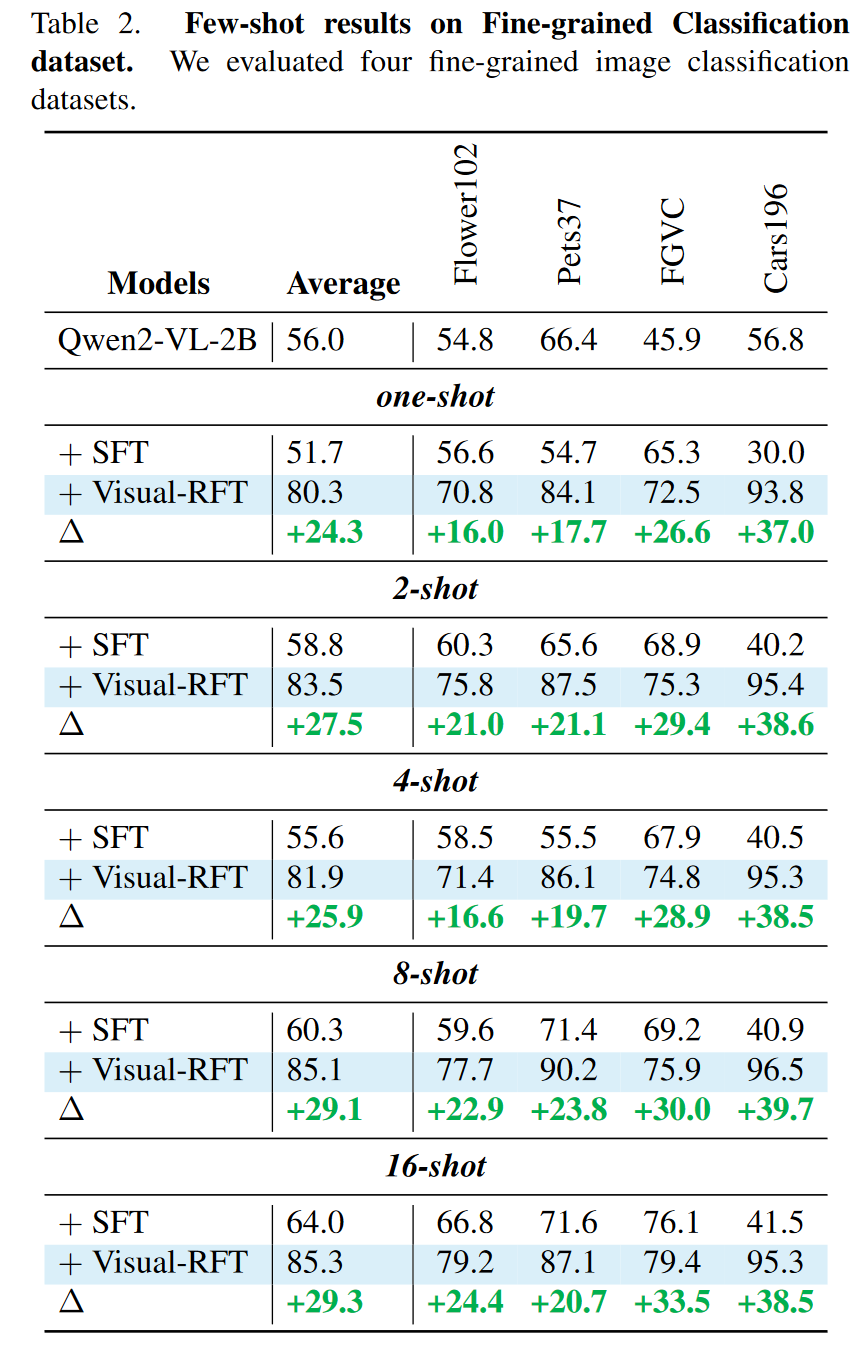
Few-Shot Classification
在4个细粒度分类数据集(Flower102,Pets37,FGVCAircraft和Car196)上实验
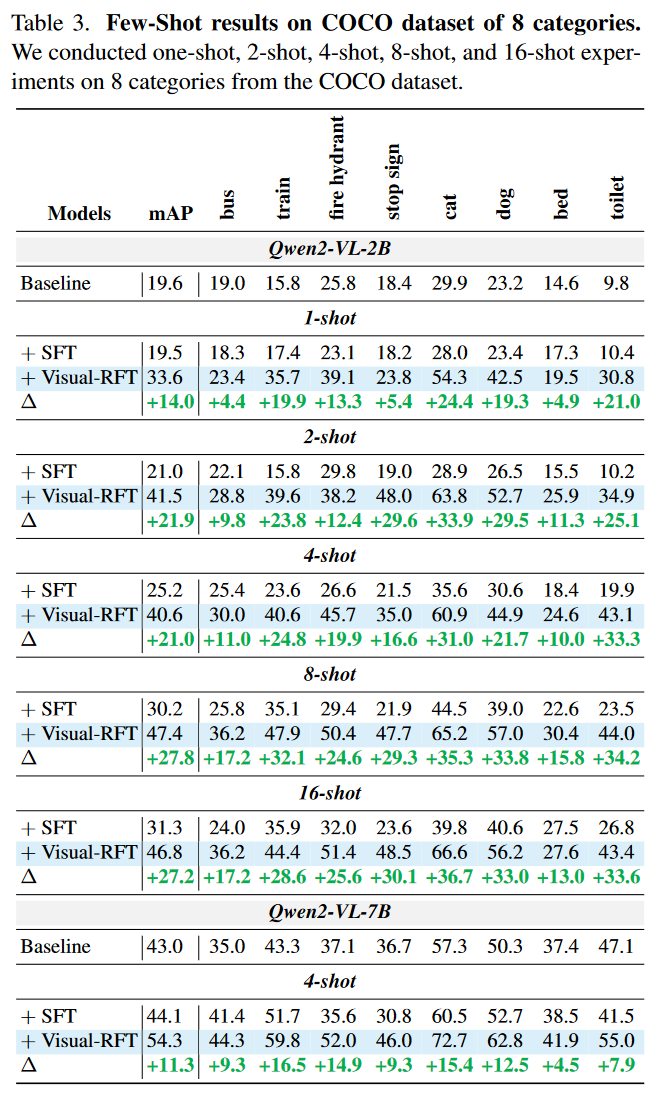
Few-Shot Object Detection
我们从COCO数据集中选取了8个类别,每个类别分别有1、2、4、8和16张图像,用有限的数据构建训练集。对于LVIS数据集,我们选取了6个稀有类别。由于这些稀有类别的训练图像非常稀疏,每个类别有1 ~ 10张图像,我们将其近似为10个shot的设置。是否模型越大?SFT和RFT差距越小?
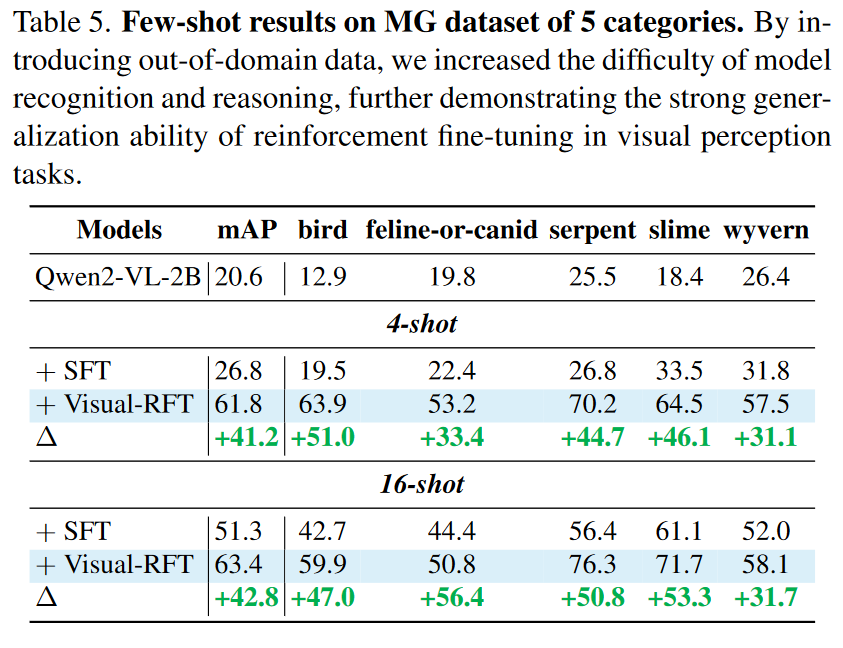
我们进一步在一些抽象的OOD数据集上进行测试。我们选取了MG数据集,该数据集包含了不同类型的动漫风格的怪兽女孩。(是否难度越大?RFT提升越高?)
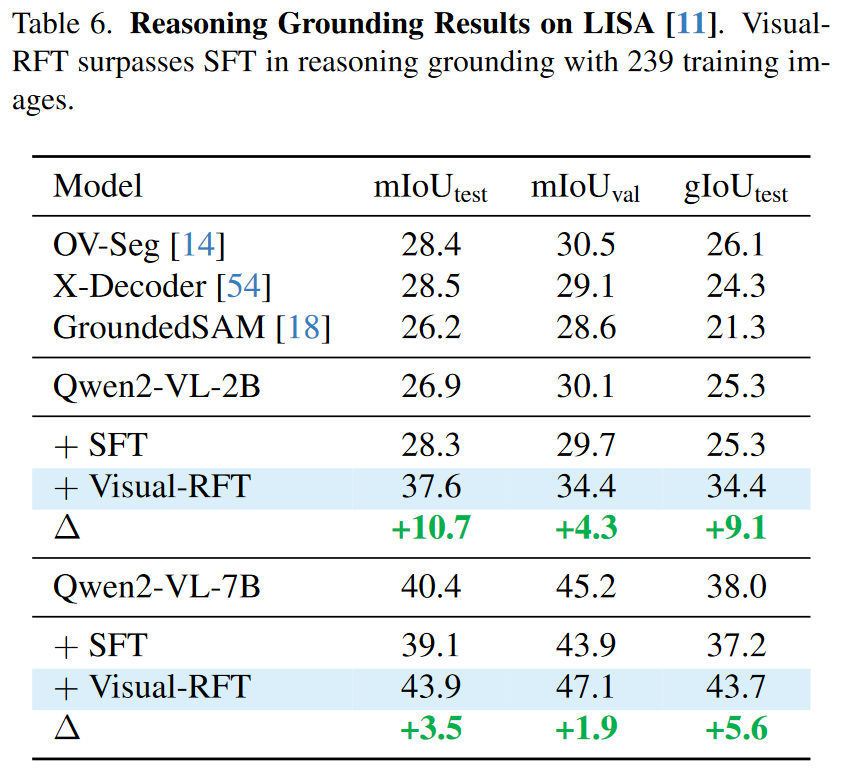
Reasoning Grounding
Reasoning Grounding是一种推理分割的任务,该任务模型需要有复杂指令的理解能力,而不简单的标签理解能力。举个例子,当我们让模型分割出“图片中含维生素C最多的水果”,模型要能分割出图像中的“橙子”,而不需要我们明确指出要分割橙子。lisa模型如图3所示。它向多模态大模型添加一个
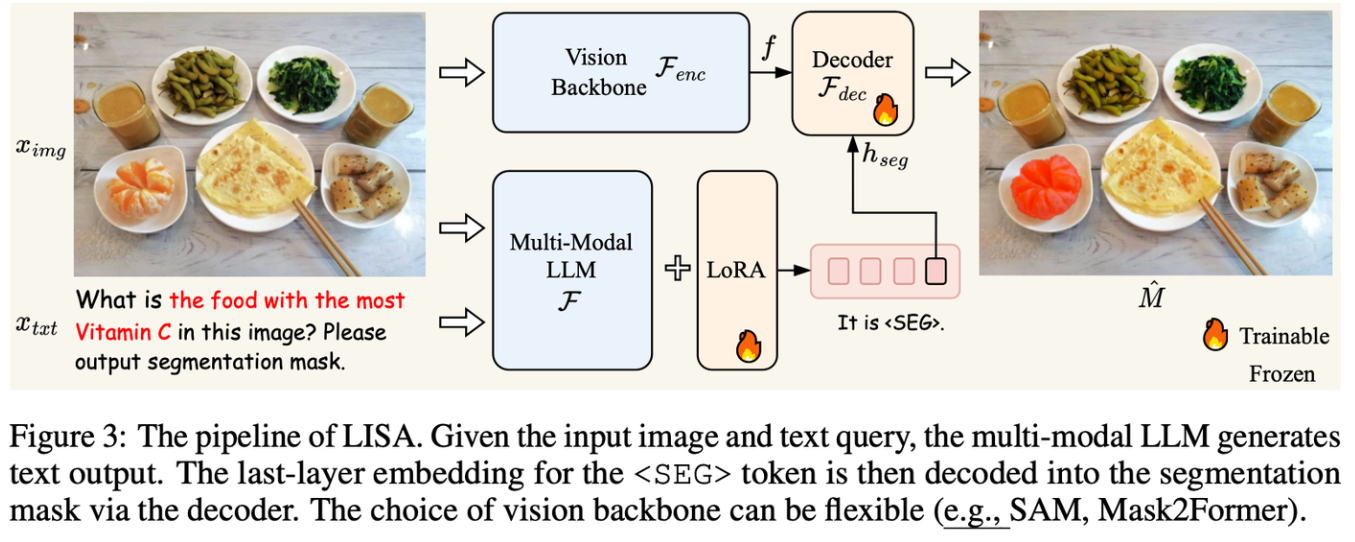
一个重要方面是根据用户需求将精确的物体grounding。以往的专业检测系统缺乏推理能力,不能完全理解用户的意图。在LISA的启发下,已经做了一些工作,使LLMs能够为其他模型输出tokens(如SAM)或通过有监督的微调直接预测边界框坐标。在我们的工作中,我们探索了Visual-RFT在这项任务中的使用,并发现强化学习(RL)比监督微调有显著的改善。
我们使用VisualRFT和SFT在LISA训练集上对Qwen2-VL 2B/7B模型进行微调,LISA训练集由239张带有推理背景物体的图像组成。我们采用与LISA相同的测试集,在500个微调步数下比较了SFT和我们方法的结果。与SFT相比,Visual-RFT在BBox IoU方面显著提高了最终结果。此外,我们用Qwen2-VL预测的边界框提示SAM来生成分割掩码(使用gIoU进行评估)。
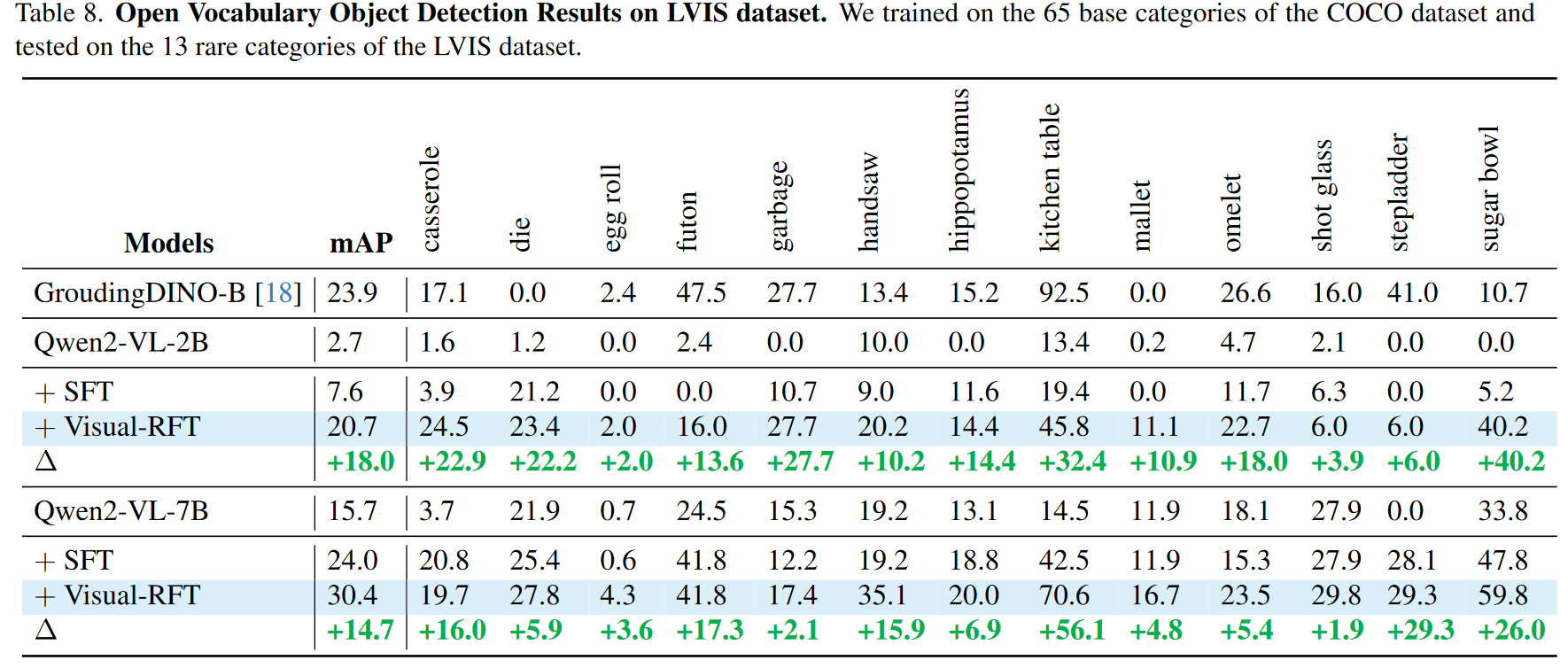
Open Vocabulary Object Detection
Visual-RFT相对于SFT的优势在于前者对任务的真正深刻理解,而不是仅仅记忆数据。我们首先从COCO数据集中随机抽取了6K个标注,其中包含65个基本类别。我们利用该数据对Qwen2-VL 2/7B模型进行了Visual - RFT和SFT,并在此前从未见过的15个新类别上对模型进行了测试。为了增加难度,我们从LVIS数据集中进一步测试了13个稀有类别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号