

scala实验3
1.Linux配置spark
1. spark安装包下载
下载链接https://spark.apache.org/downloads.html
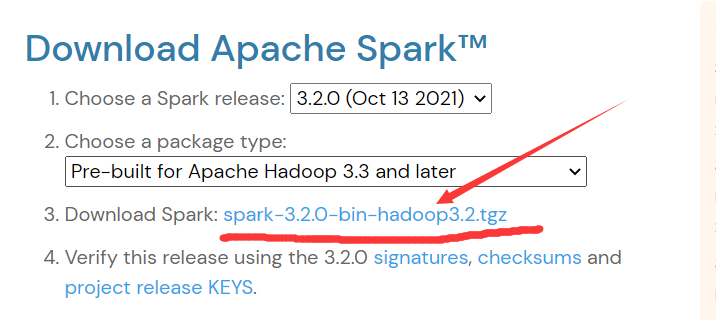

2.下载完成后,进入下载目录,解压spark
tar -zvxf spark-3.2.0-bin-hadoop3.2.tgz
3.删除安装包,移动包并修改文件名
rm -rf 安装包名
mv spark-3.2.0-bin-hadoop3.2 /usr/local/spark
4.进入spark的conf目录下
cd /usr/local/spark/conf
ll
5.修改配置文件名字
mv spark-env.sh.template spark-env.sh vim spark-env.sh
在文件末尾添加
export SCALA_HOME=/usr/local/scala scala位置
export JAVA_HOME=/usr/local/java/jdk jdk位置
export HADOOP_HOME=/usr/local/hadoop hadoop位置
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
SPARK_MASTER_IP=Master11 #这里的Master11是我的主机名
SPARK_LOCAL_DIRS=/usr/local/spark spark位置
SPARK_DRIVER_MEMORY=1G
mv workers.template slaves
vim slaves
查看主机名是否与自己的一致
6.进入spark的sbin目录启动集群
cd /usr/local/spark/sbin
./start-all.sh

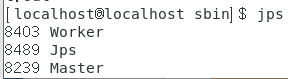
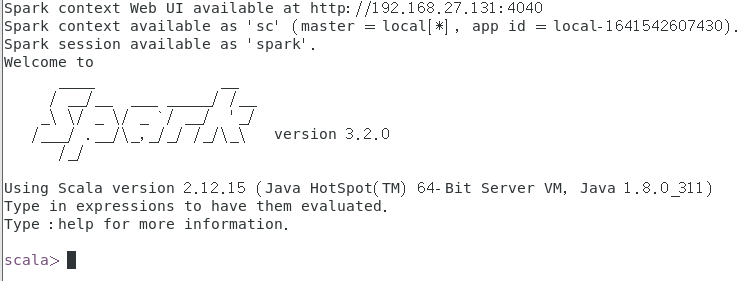
7.启动spark shell
进入spark的bin目录,启动
./spark-shell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号