2 Elasticsearch相关软件安装及快速入门
2.1 Elasticsearch相关软件安装
2.1.1 Windows安装elasticsearch
2)下载和解压缩Elasticsearch安装包,查看目录结构
https://www.elastic.co/cn/downloads/elasticsearch
-
bin:脚本目录,包括:启动、停止等可执行脚本
-
config:配置文件目录
-
data:索引目录,存放索引文件的地方
-
logs:日志目录
-
modules:模块目录,包括了es的功能模块
-
plugins :插件目录,es支持插件机制
3)配置文件
ES的配置文件的地址根据安装形式的不同位置而不同:
-
使用zip、tar安装,配置文件的地址在安装目录的config下。
-
使用RPM安装,配置文件在/etc/elasticsearch下。
-
使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path
方式2:属性方式
path.data
常用的配置项如下
cluster.name
jvm.options
设置最小及最大的JVM堆内存大小:
在jvm.options中设置 -Xms和-Xmx:
两个值设置为相等
将Xmx 设置为不超过物理内存的一半。
log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
4)启动Elasticsearch:bin\elasticsearch.bat
es的特点就是开箱即,无需配置,启动即可
注意:es7 windows版本不支持机器学习,所以elasticsearch.yml中添加如下几个参数:
node.name
5)检查ES是否启动成功
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "E11m2bNATwSypPIFRt95Tg",
"version" : {
"number" : "7.14.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "66b55ebfa59c92c15db3f69a335d500018b3331e",
"build_date" : "2021-08-26T09:01:05.390870785Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
注释:
-
name: node名称,取自机器的hostname
-
cluster_name: 集群名称(默认的集群名称就是elasticsearch)
-
version.number: 7.14.1,es版本号
-
version.lucene_version:封装的lucene版本号
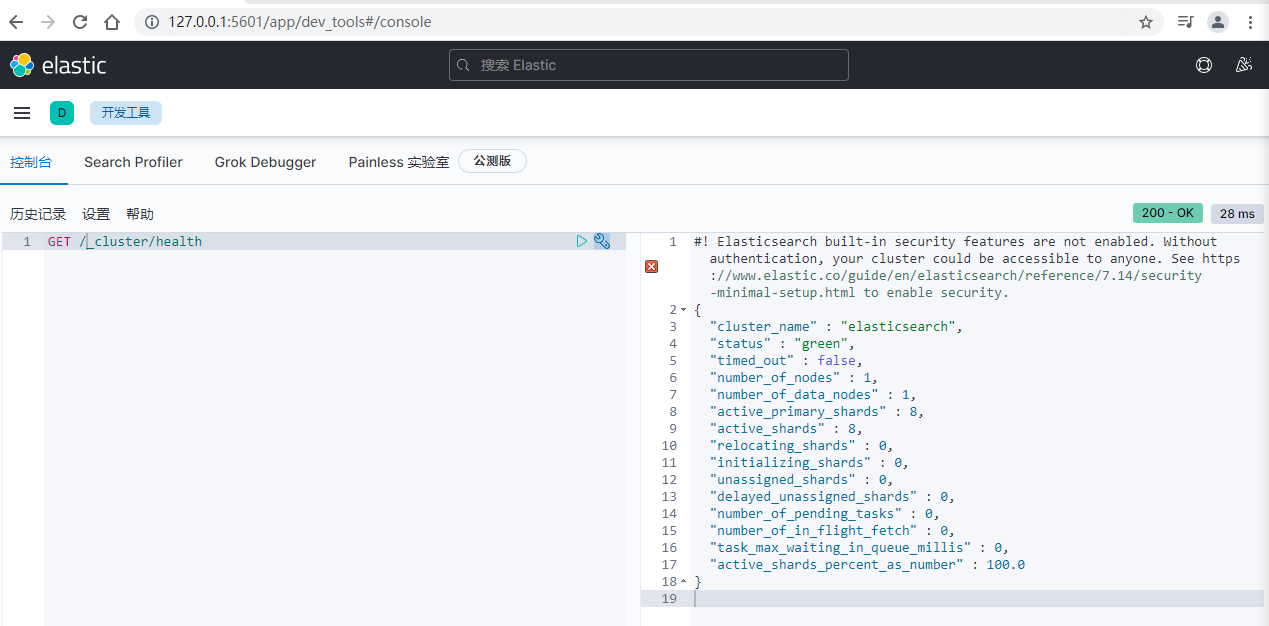
6)查询集群状态
浏览器访问 http://localhost:9200/_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 1,
"active_shards": 1,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100,0
}
注释:
-
Status:集群状态。Green 所有分片可用。Yellow所有主分片可用。Red主分片不可用,集群不可用。
2.1.2 Windows安装Kibana
kibana是es数据的前端展现,数据分析时,可以方便地看到数据。作为开发人员,可以方便访问es。
1)下载,解压kibana
https://www.elastic.co/cn/downloads/kibana
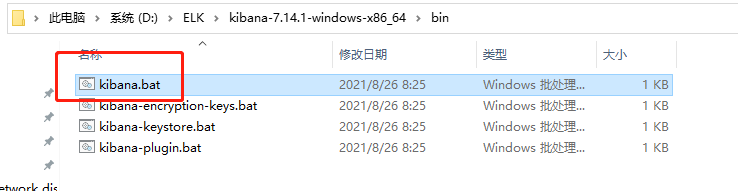
2)启动Kibana:bin\kibana.bat
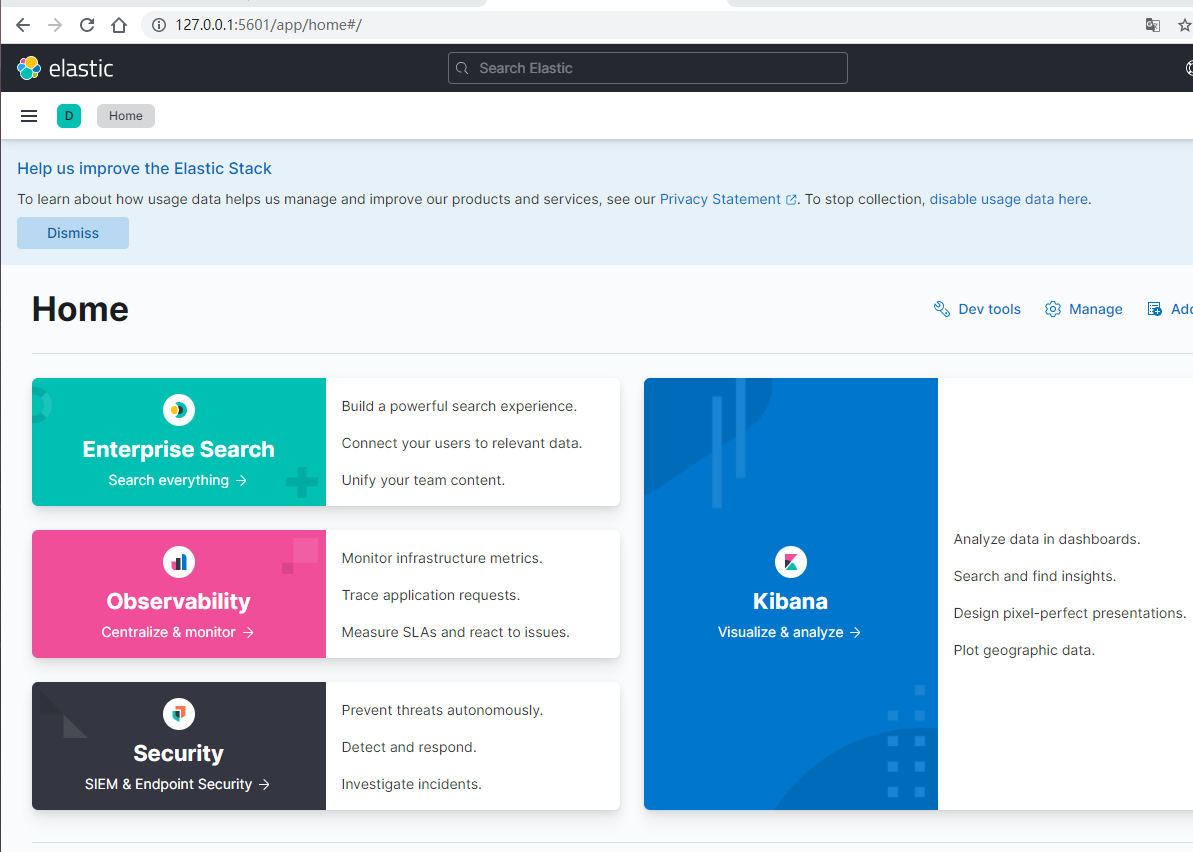
3)浏览器访问 http://localhost:5601 进入Dev Tools界面。像plsql一样支持代码提示。
4)设置Kibana为中文
编辑kibana.yml,添加该字段
i18n.locale: "zh-CN"
5)发送get请求,查看集群状态GET _cluster/health。相当于浏览器访问
Dev Tools界面
监控集群界面
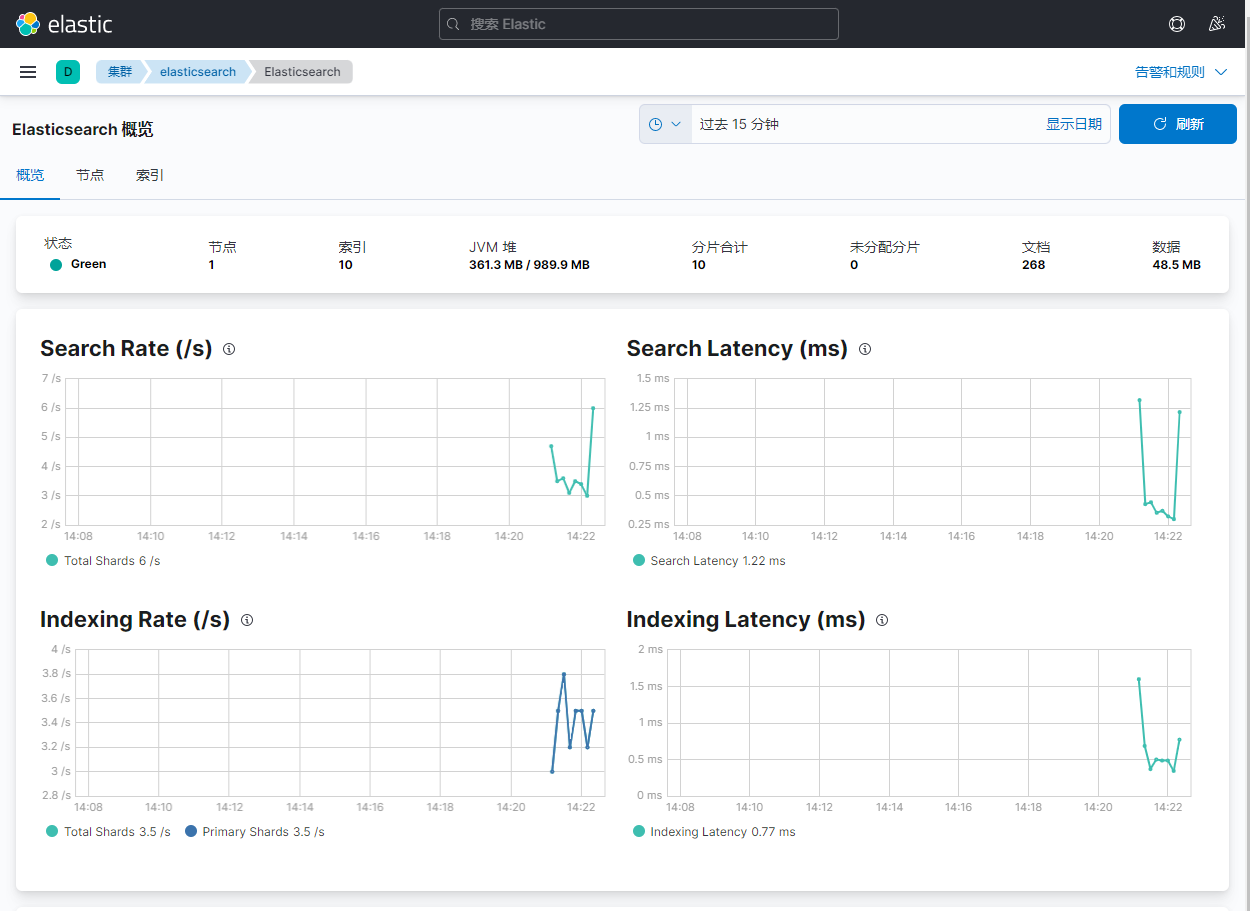
集群状态(搜索速率、索引速率等)
2.1.3 Windows安装postman
1)postman是什么
postman是一个模拟http请求的工具。能够非常细致地定制化各种http请求。如get]\post\pu\delete,携带body参数等。
2)为什么要用postman
在没有kibana时,可以使用postman调试
3)安装Postman
官网连接:
https://www.postman.com/downloads/
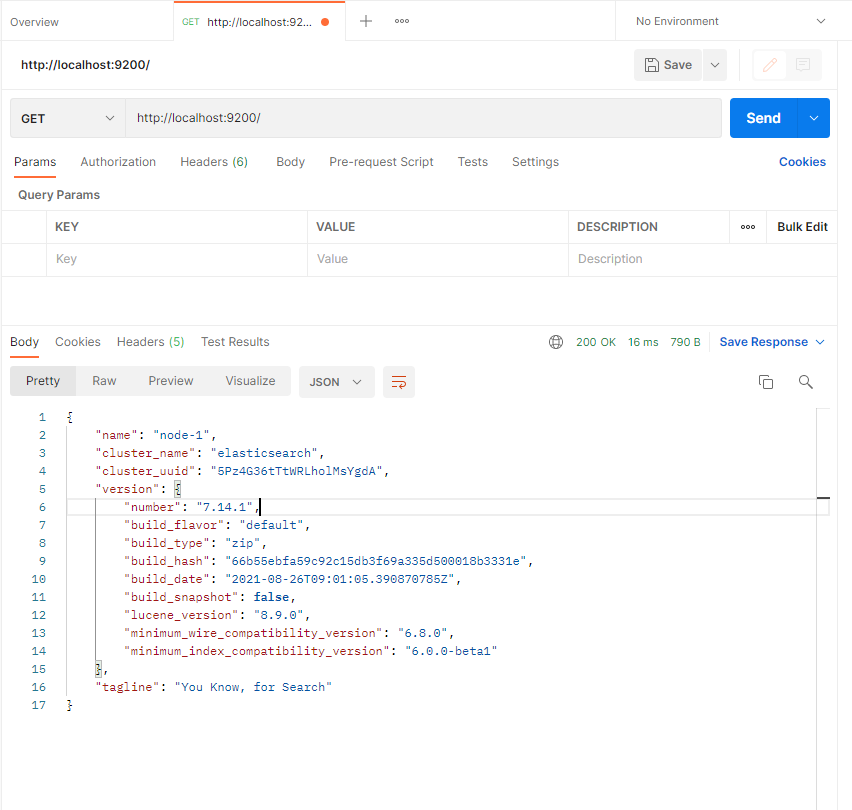
4)测试postman
get http://localhost:9200/
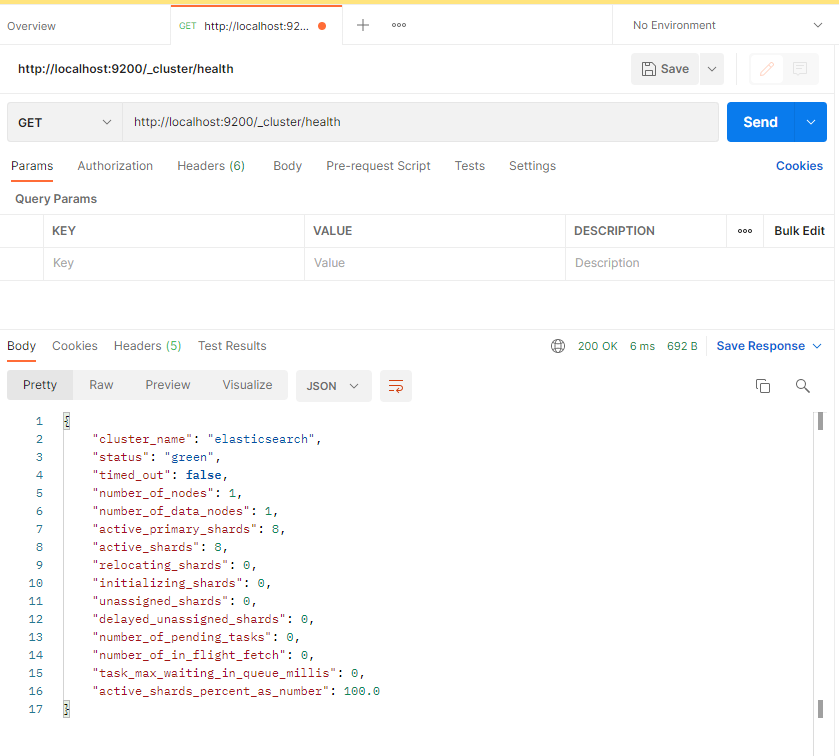
# 测试一下get方式查询集群状态
http://localhost:9200/_cluster/health
2.2 Elasticsearch快速入门
2.2.1 文档(document)的数据格式
(1)应用系统的数据结构都是面向对象的,具有复杂的数据结构
(2)对象存储到数据库,需要将关联的复杂对象属性插到另一张表,查询时再拼接起来。
(3)es面向文档,文档中存储的数据结构,与对象一致。所以一个对象可以直接存成一个文档。
(4)es的document用json数据格式来表达。
例如:班级和学生关系
public class Student {
private String id;
private String name;
private String classInfoId;
}
private class ClassInfo {
private String id;
private String className;
。。。。。
}
数据库中要设计所谓的一对多,多对一的两张表,外键等。查询出来时,还要关联,mybatis写映射文件,很繁琐。
而在es中,一个学生存成文档如下:
{
"id":"1",
"name": "张三",
"last_name": "zhang",
"classInfo": {
"id": "1",
"className": "三年二班",
}
}
2.2.2 图书网站商品管理案例:背景介绍
有一个售卖图书的网站,需要为其基于ES构建一个后台系统,提供以下功能:
-
对商品信息进行CRUD(增删改查)操作
-
执行简单的结构化查询
-
可以执行简单的全文检索,以及复杂的phrase(短语)检索
-
对于全文检索的结果,可以进行高亮显示
-
对数据进行简单的聚合分析
2.2.3 简单的集群管理
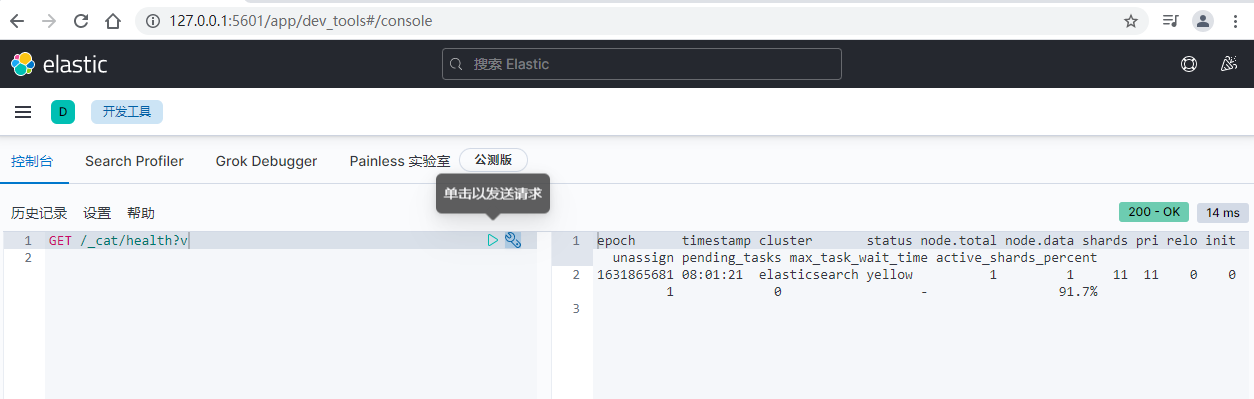
1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1631864720 07:45:20 elasticsearch green 1 1 10 10 0 0 0 0 - 100.0%
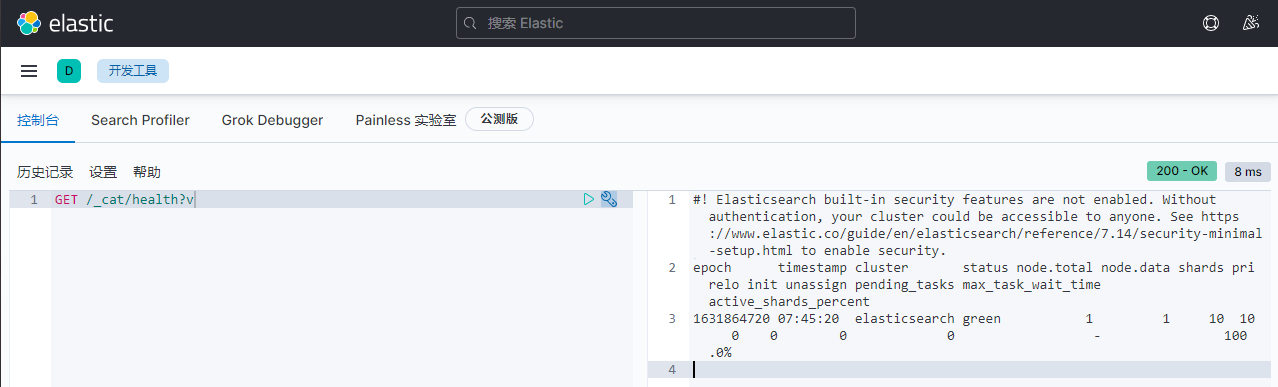
如何快速了解集群的健康状况?green、yellow、red?
-
green:每个索引的primary shard和replica shard都是active状态的
-
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
-
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
2)快速查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .geoip_databases HycFFgsJT7mSyLjnFMfQhw 1 0 42 0 40.8mb 40.8mb
green open .apm-custom-link bwStyDzdTgaPHQURWfoZhg 1 0 0 0 208b 208b
green open .kibana_task_manager_7.14.1_001 9-FWreqGRViGg1p7RUlXHg 1 0 14 5618 687kb 687kb
green open .apm-agent-configuration IMWVUqFpTUK6opQ1PcWTyw 1 0 0 0 208b 208b
green open .monitoring-kibana-7-2021.09.17 1NKgYDSTS6qJBeCcBjBwDQ 1 0 674 0 559.8kb 559.8kb
green open .kibana_7.14.1_001 00bvjGRvSymendpkUhnaBg 1 0 39 3 4.2mb 4.2mb
green open .kibana-event-log-7.14.1-000001 nMYFTOW4TV-QXhcFC-WaXQ 1 0 3 0 11.3kb 11.3kb
green open .monitoring-es-7-2021.09.17 UBKfW-38SJyhoxqHnL1VEA 1 0 4736 3350 3.4mb 3.4mb
green open .tasks GzpTfAZ6TVezMCtmxI9ltg 1 0 2 0 13.8kb 13.8kb
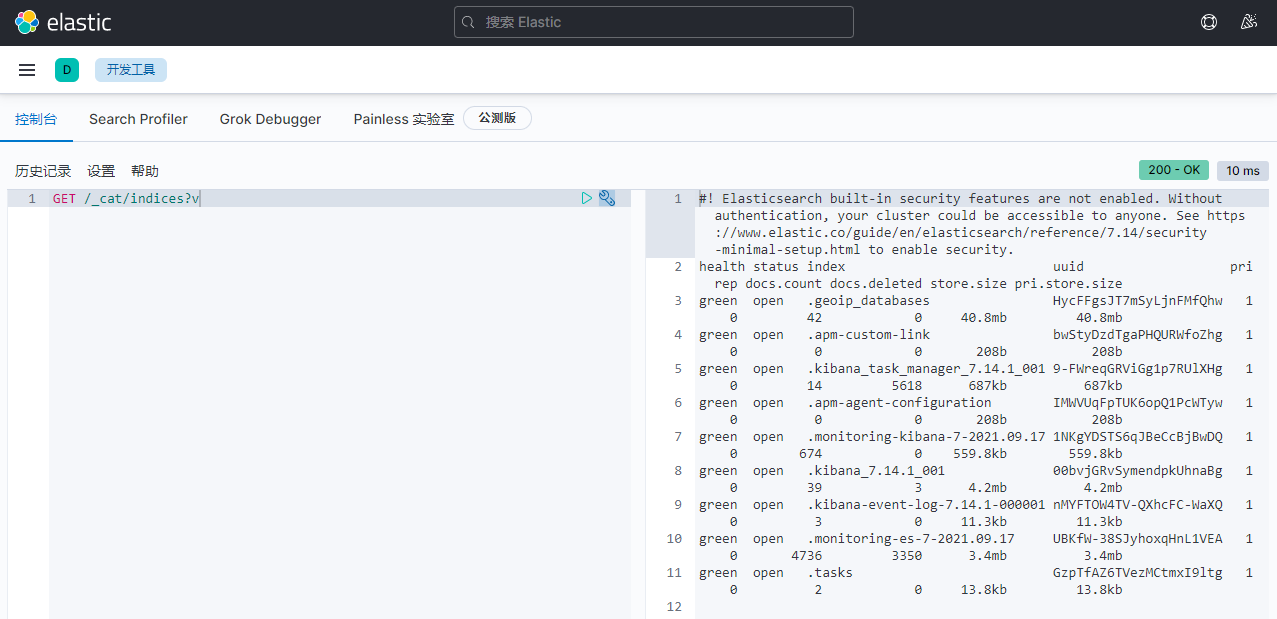
3)简单的索引操作
创建索引:PUT /demo_index?pretty
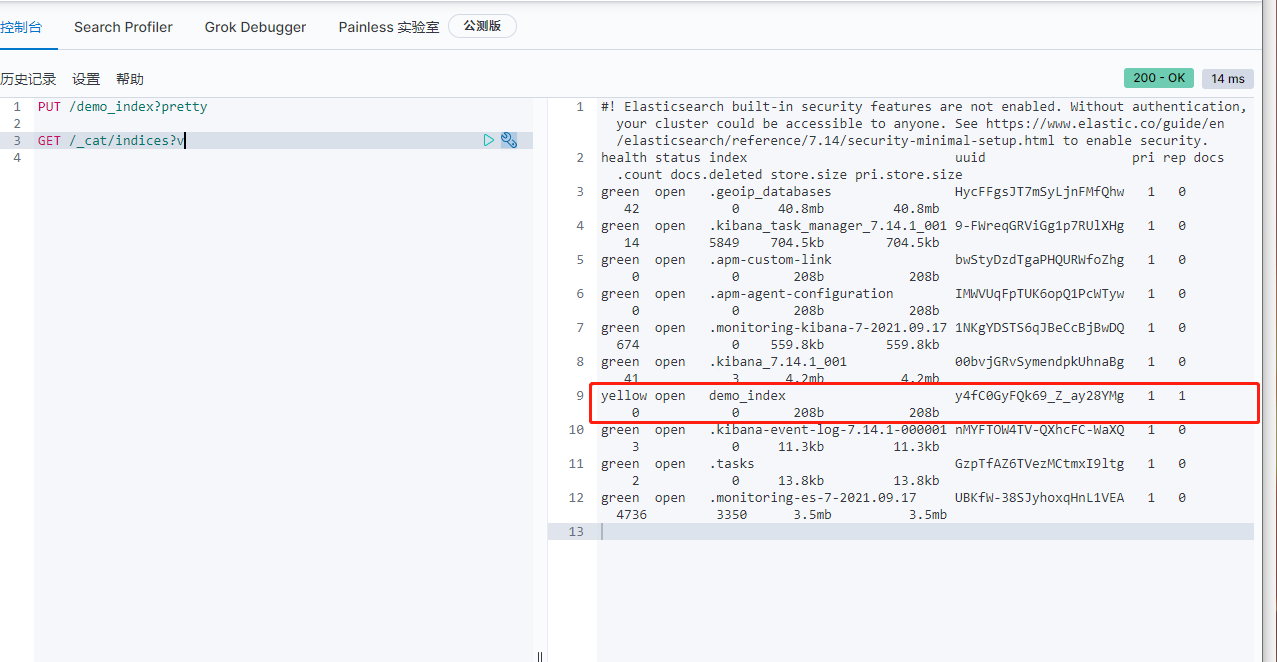
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "demo_index"
}
删除索引:DELETE /demo_index?pretty
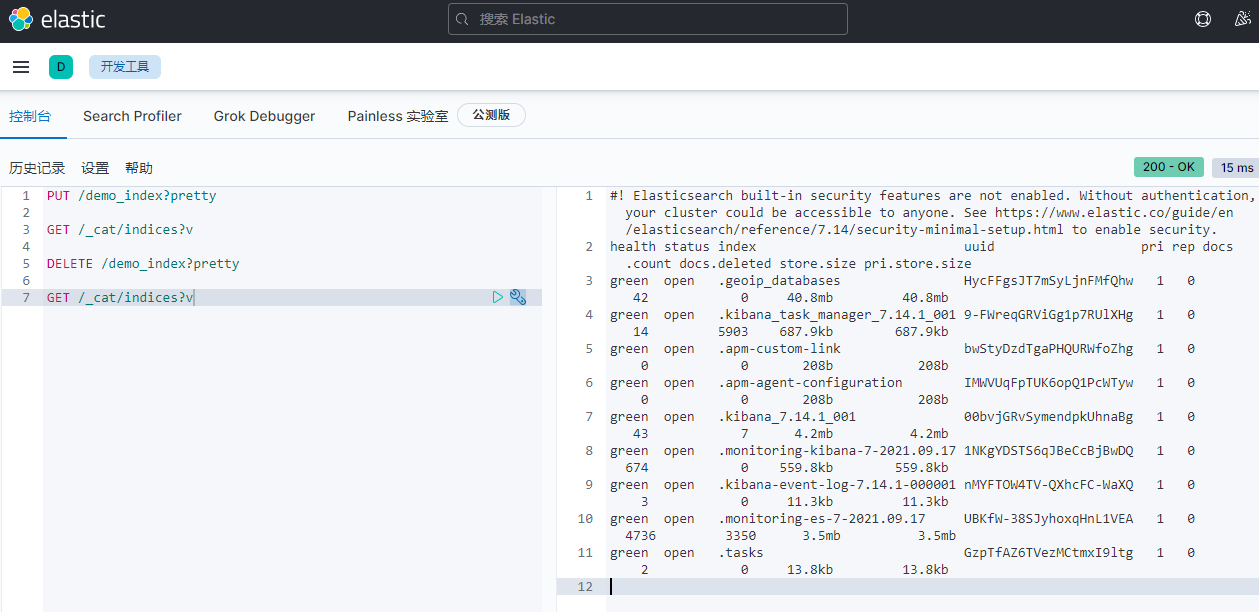
4)关闭ElasticSearch 安全功能(正式生产环境需要打开该功能)
编辑elasticsearch.yml 配置文件
xpack.security.enabled: false
2.2.4 商品的CRUD操作(document CRUD操作)
1)新建图书索引
首先建立图书索引 book
语法:put /index
PUT /book
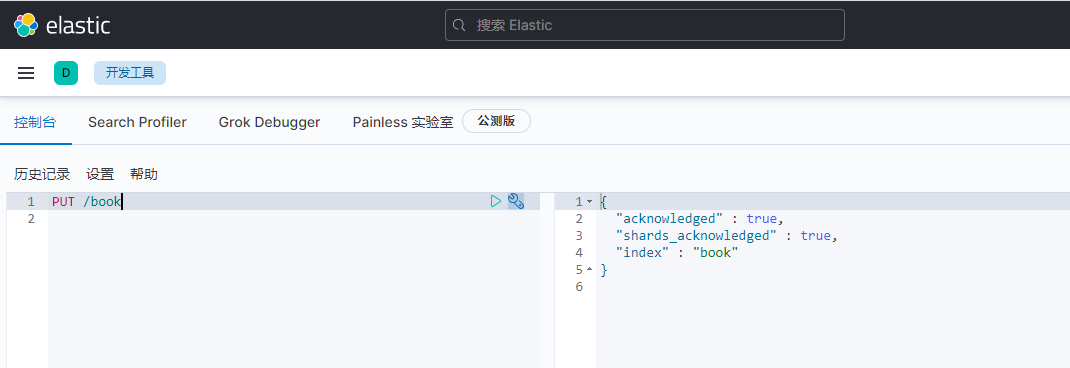
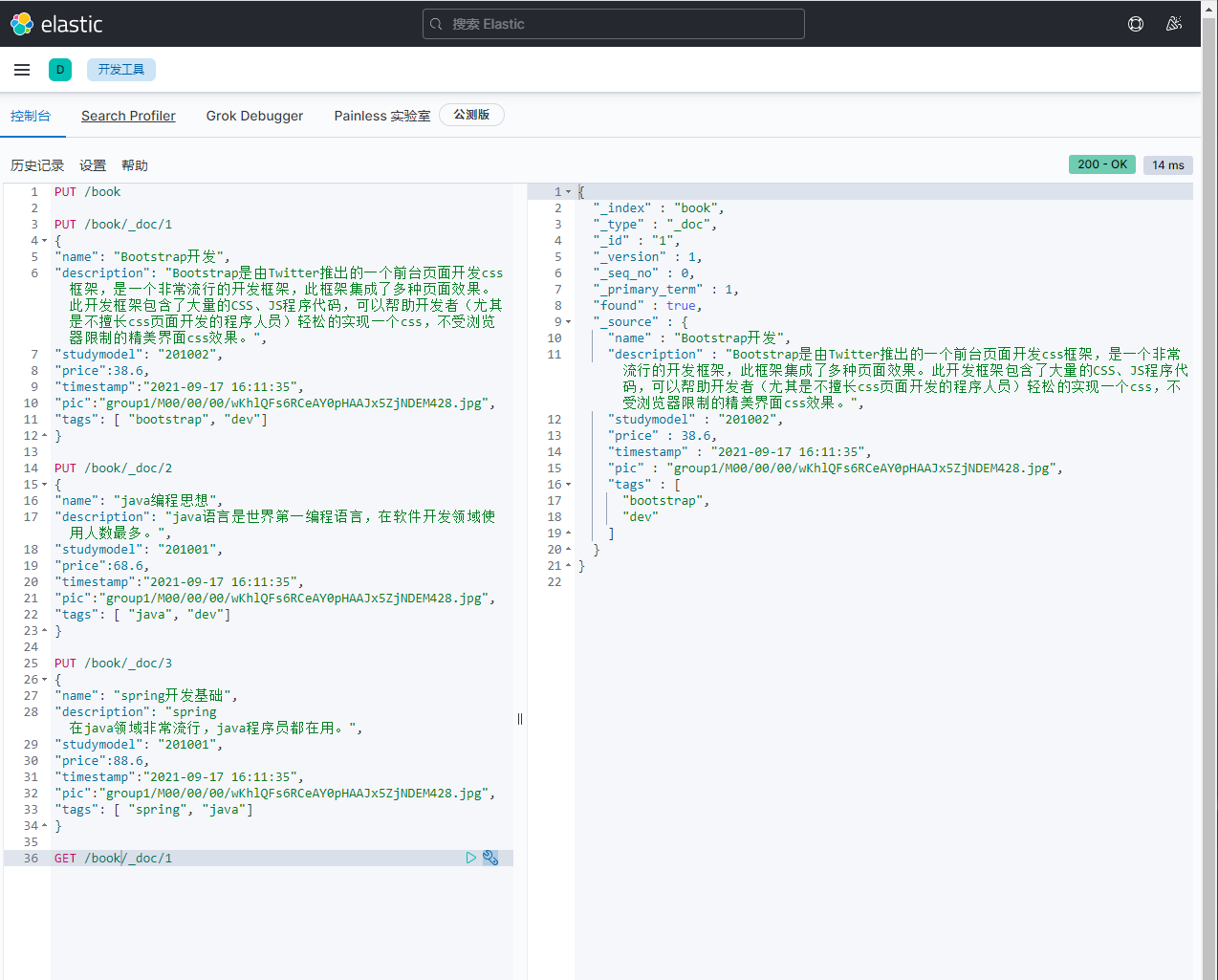
2)新增图书 :新增文档
语法:PUT /index/type/id
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2021-09-17 16:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "dev"]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"timestamp":"2021-09-17 16:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "java", "dev"]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"timestamp":"2021-09-17 16:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "spring", "java"]
}
结果
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
3)查询图书:检索文档
语法:GET /index/type/id
查看图书:GET /book/_doc/1 就可看到json形式的文档。方便程序解析。
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Bootstrap开发",
"description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel" : "201002",
"price" : 38.6,
"timestamp" : "2019-08-25 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"bootstrap",
"开发"
]
}
}
为方便查看索引中的数据,kibana可以如下操作
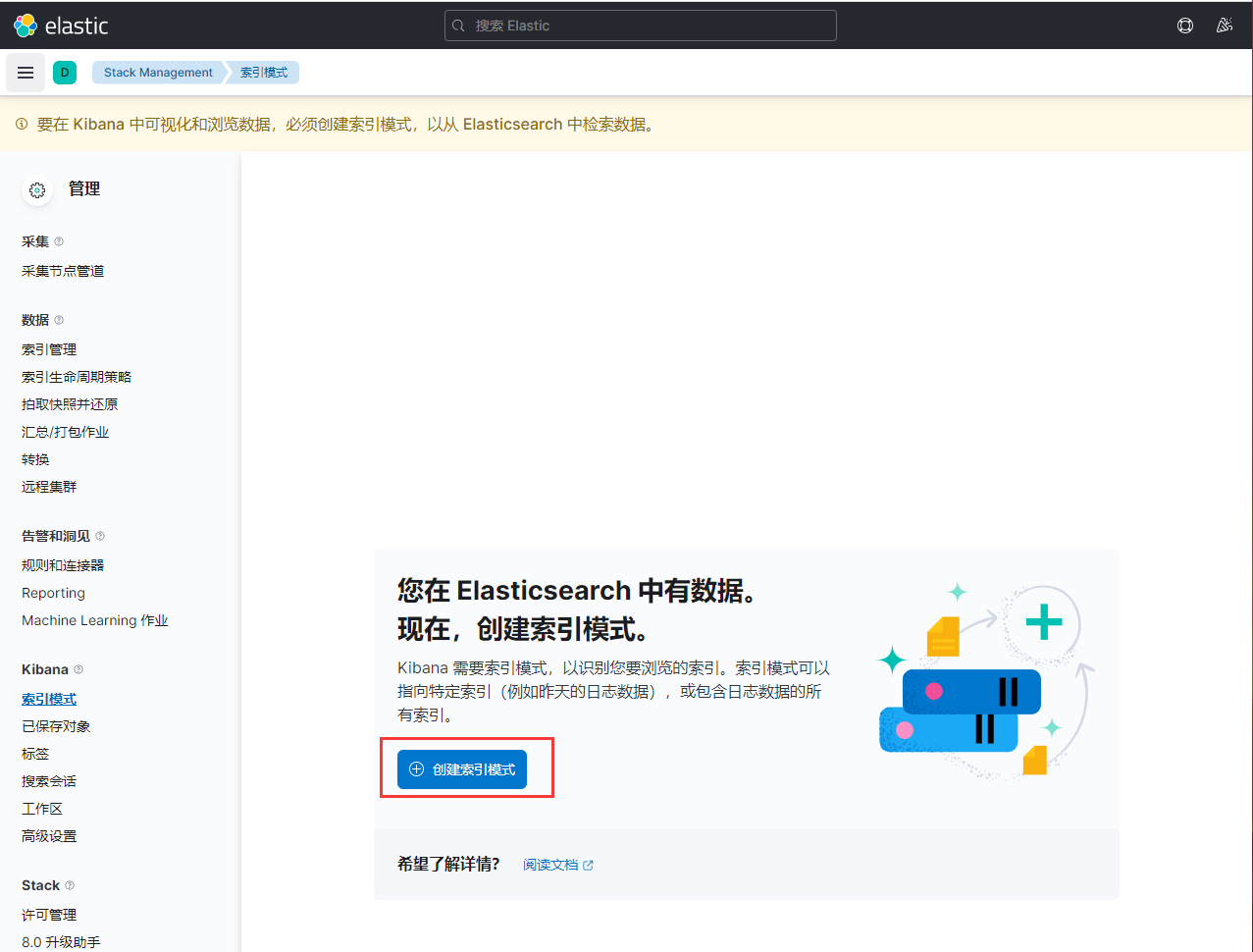
Kibana-discover- Create index pattern- Index pattern填book
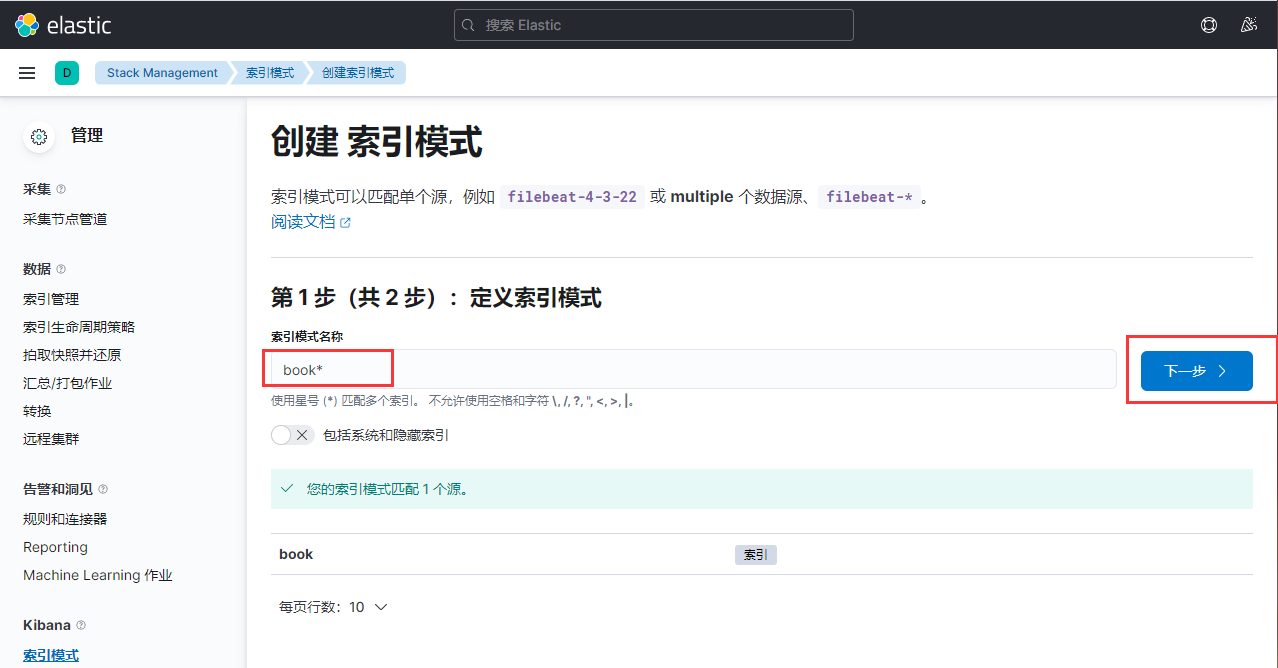
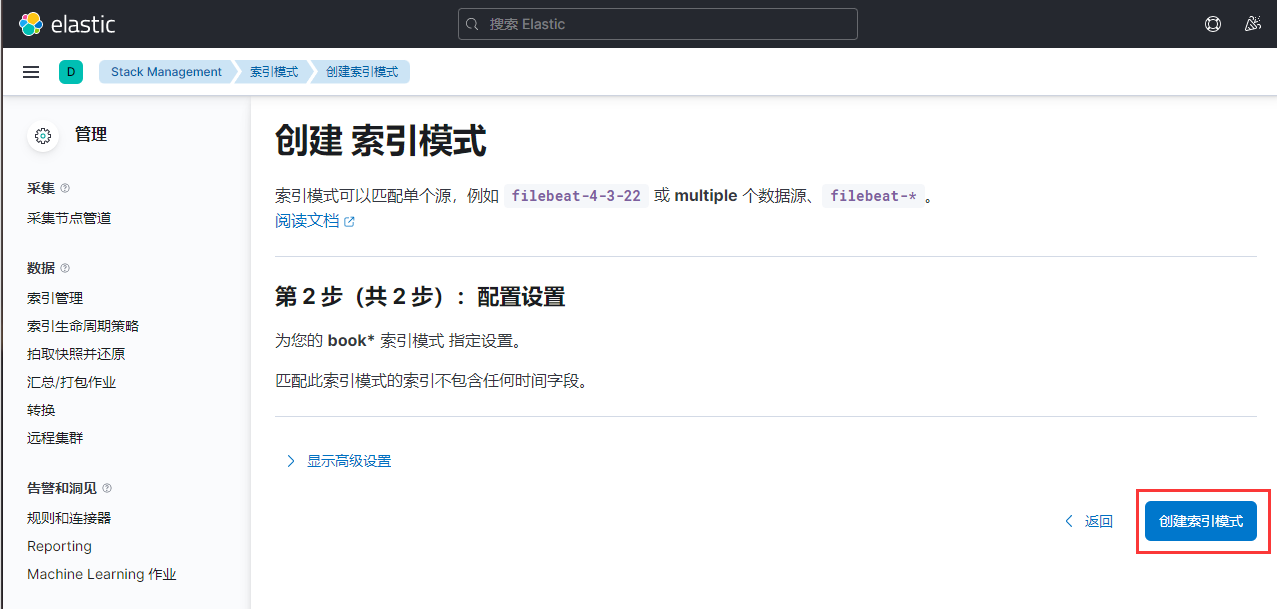
创建,再点击discover就可看到数据。
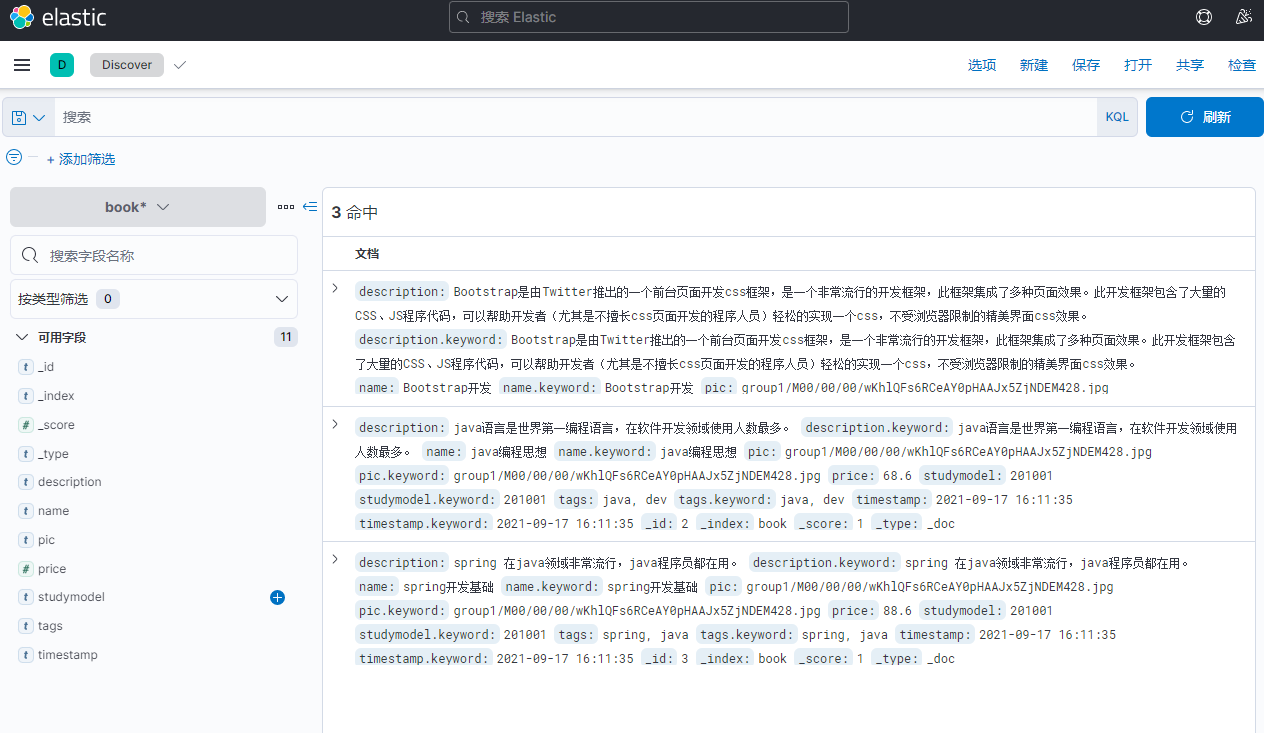
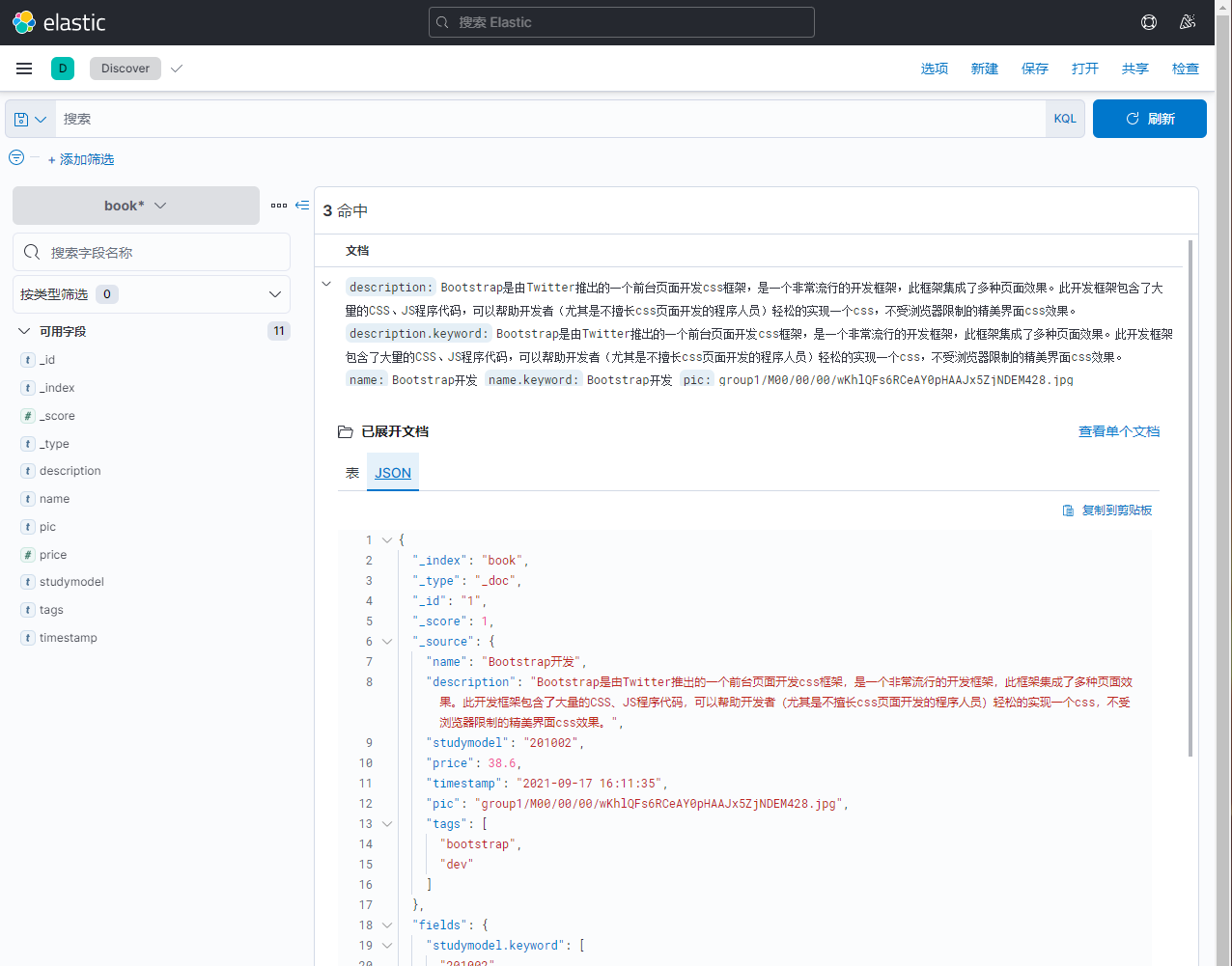
点击json还可以看到原始数据
4)修改图书:替换操作
PUT /book/_doc/1
{
"name": "Bootstrap开发教程1",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "开发"]
}
替换操作是整体覆盖,要带上所有信息。
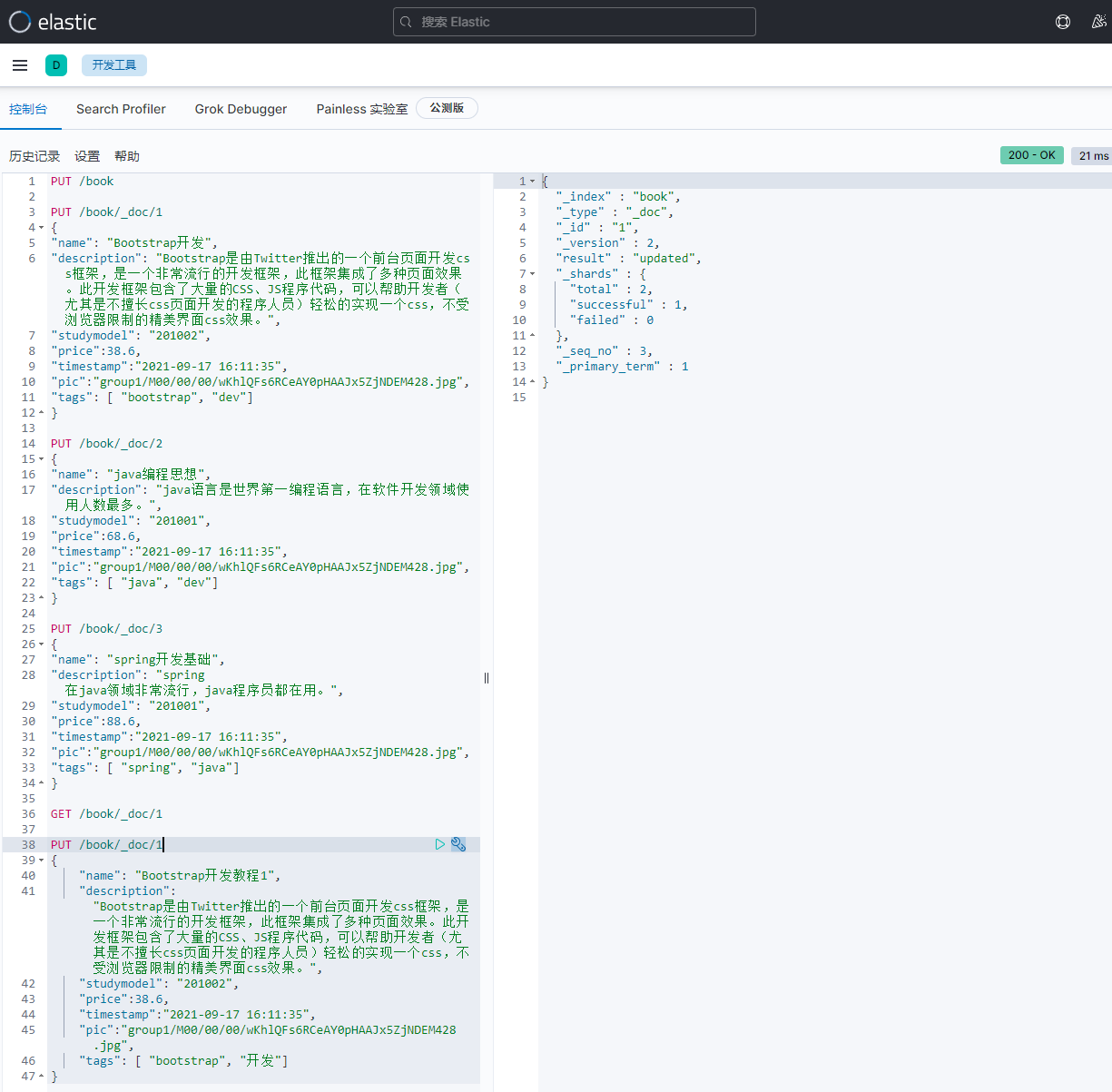
5)修改图书:更新文档
语法:
POST /{index}/_update/{id}
POST /book/_update/1/
{
"doc": {
"name": " Bootstrap开发教程高级"
}
}
返回:
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
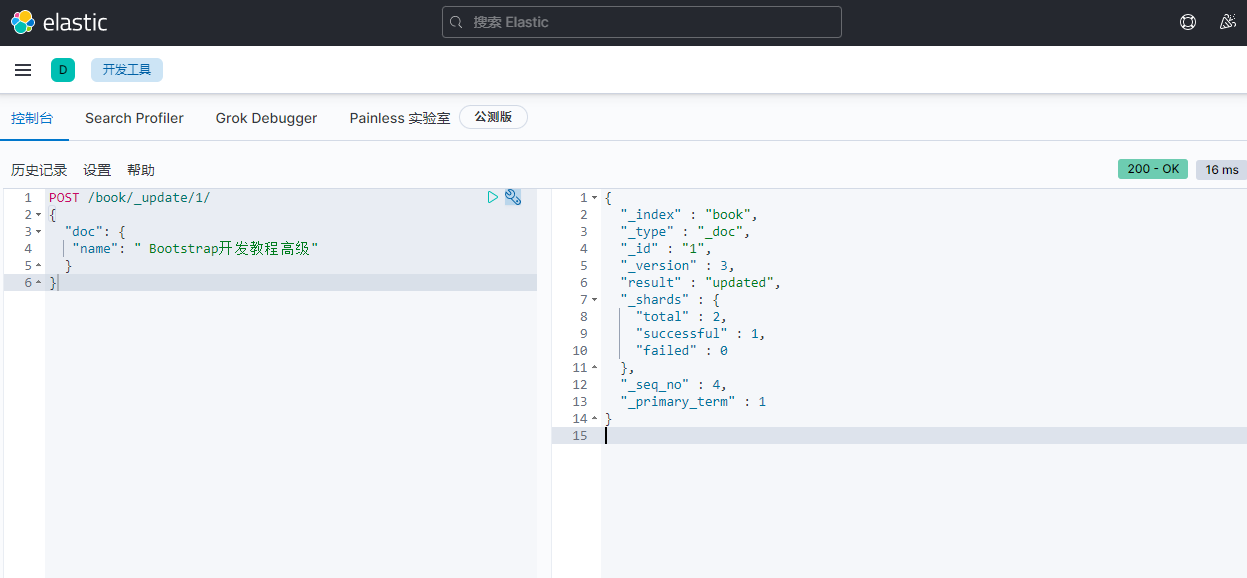
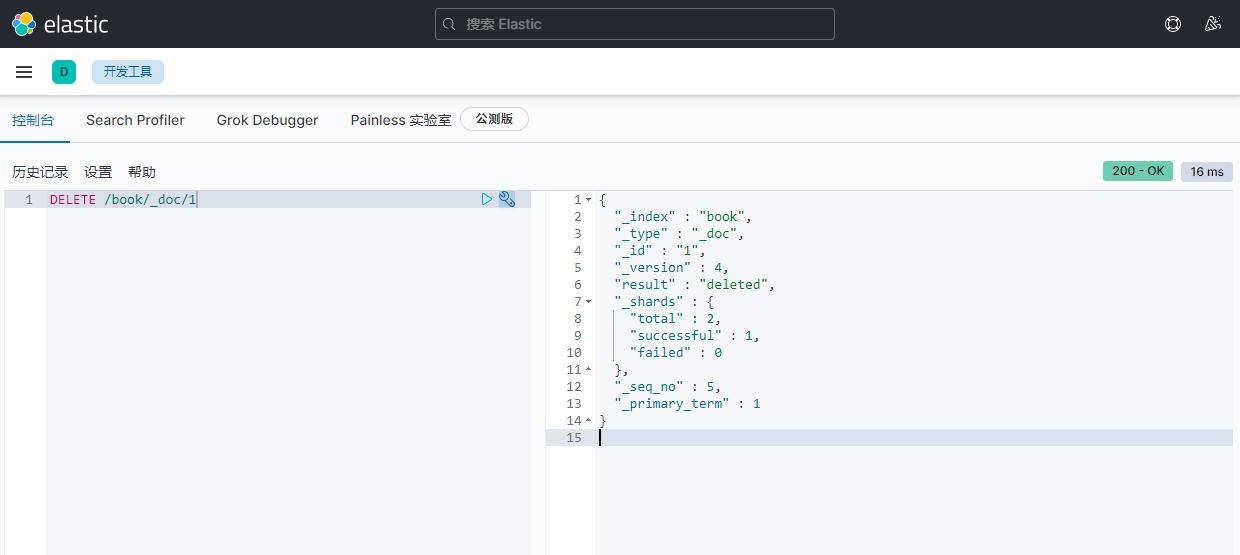
6)删除图书:删除文档
语法:
DELETE /book/_doc/1
返回:
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
2.3 文档document入门
2.3.1 默认自带字段解析
GET /book/_doc/2
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "java编程思想",
"description" : "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel" : "201001",
"price" : 68.6,
"timestamp" : "2021-09-17 16:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"java",
"dev"
]
}
}
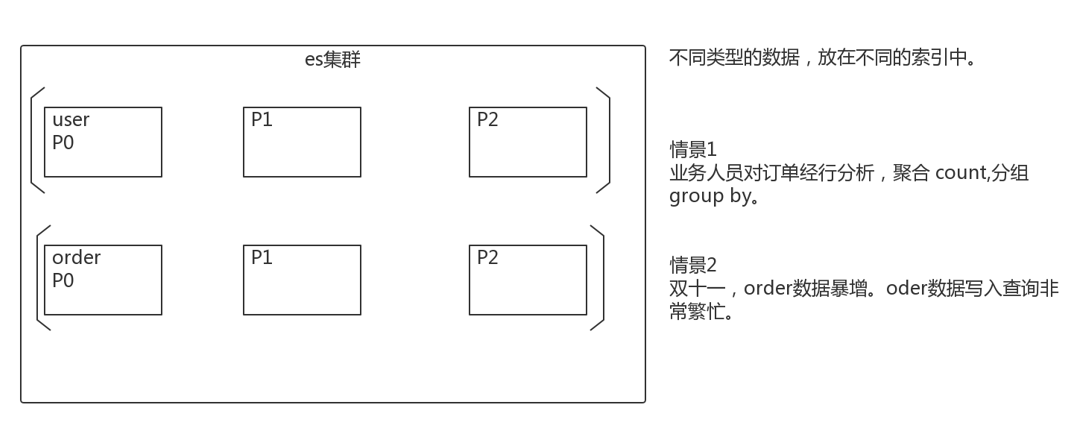
1) _index
-
含义:此文档属于哪个索引
-
原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,员工信息放在employee索引中。各个索引存储和搜索时互不影响。
-
定义规则:英文小写。尽量不要使用特殊字符。order user
2)_type
-
含义:类别。book java node
-
注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type。不需要关注。见到_type都为doc。
3)_id
含义:文档的唯一标识。就像表的id主键。结合索引可以标识和定义一个文档。
生成:手动(put /index/_doc/id)、自动
4)创建索引时,不同数据放到不同索引中
2.3.2 生成文档id
1)手动生成id
场景:数据从其他系统导入时,本身有唯一主键。如数据库中的图书、员工信息等。
用法:put /index/_doc/id
PUT /test_index/_doc/1
{
"test_field": "test"
}
2)自动生成id
用法:POST /index/_doc
POST /test_index/_doc
{
"test_field": "test1"
}
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "x29LOm0BPsY0gSJFYZAl",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
自动id特点: 长度为20个字符,URL安全,base64编码,GUID,分布式生成不冲突
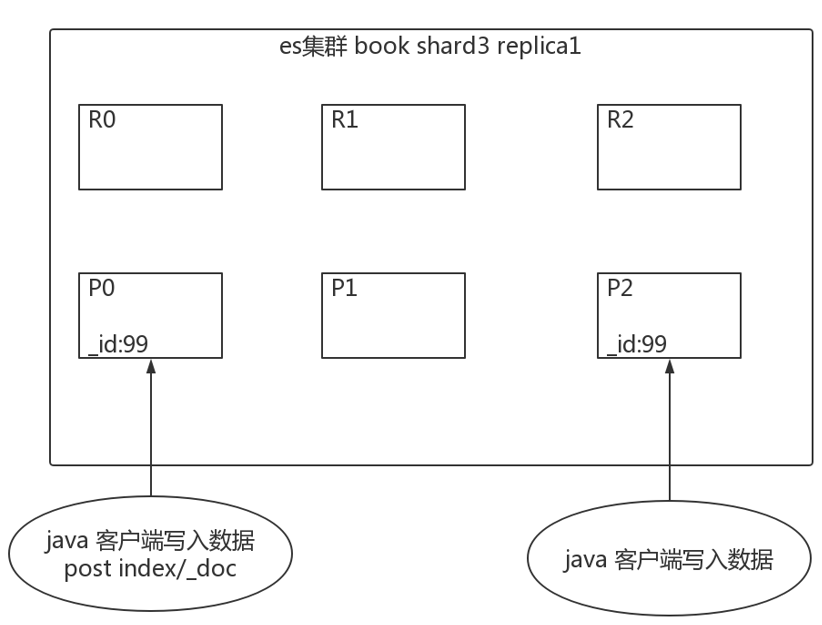
2.3.3 _source 字段
1)_source
含义:插入数据时的所有字段和值。在get获取数据时,在_source字段中原样返回。
GET /book/_doc/2
2)定制返回字段
就像sql不要select *,而要select name,price from book …一样。
GET /book/_doc/2?_source_includes=name,price
{
"_index" : "book",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"price" : 68.6,
"name" : "java编程思想"
}
}
2.3.4 文档的替换与删除
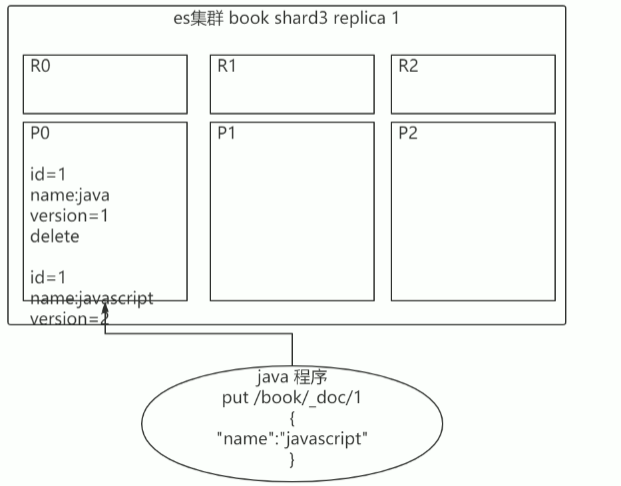
1)全量替换
执行两次,返回结果中版本号(_version)在不断上升。此过程为全量替换。
PUT /test_index/_doc/1
{
"test_field": "test"
}
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
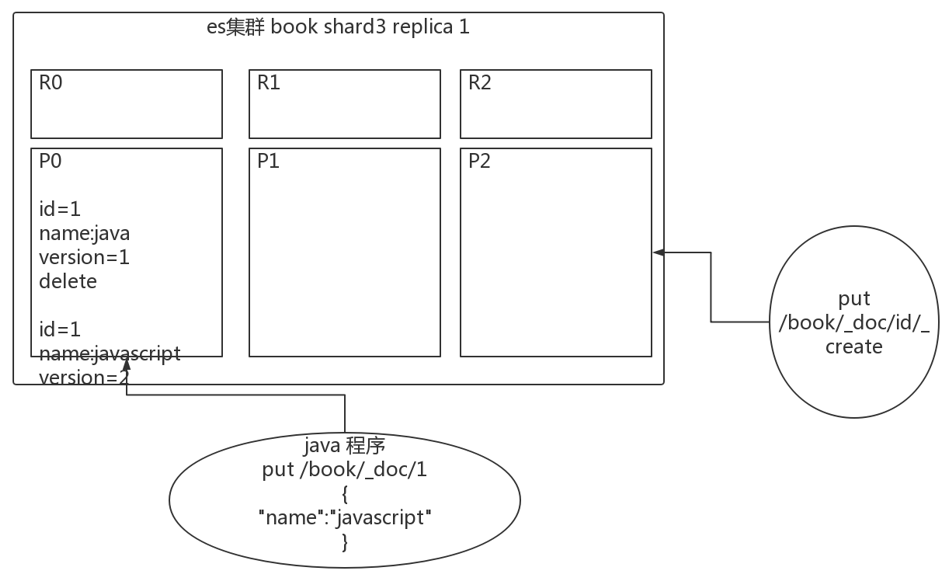
2)强制创建
为防止覆盖原有数据,我们在新增时,设置为强制创建,不会覆盖原有文档。
语法:PUT /index/ doc/id/create
PUT /test_index/_doc/1/_create
{
"test_field": "test"
}
返回
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, document already exists (current version [1])",
"index_uuid" : "d8JSbMBRTnSO-ligxIhg0Q",
"shard" : "0",
"index" : "test_index"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, document already exists (current version [1])",
"index_uuid" : "d8JSbMBRTnSO-ligxIhg0Q",
"shard" : "0",
"index" : "test_index"
},
"status" : 409
}
3)删除(lazy delete)
语法:DELETE /index/_doc/id
DELETE /test_index/_doc/1/
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
2.3.5 局部替换(partial update)
使用 PUT /index/type/id 为文档全量替换,需要将文档所有数据提交。
partial update局部替换则只修改变动字段。
用法:
post /index/type/id/_update
{
"doc": {
"field":"value"
}
}
1)图解内部原理
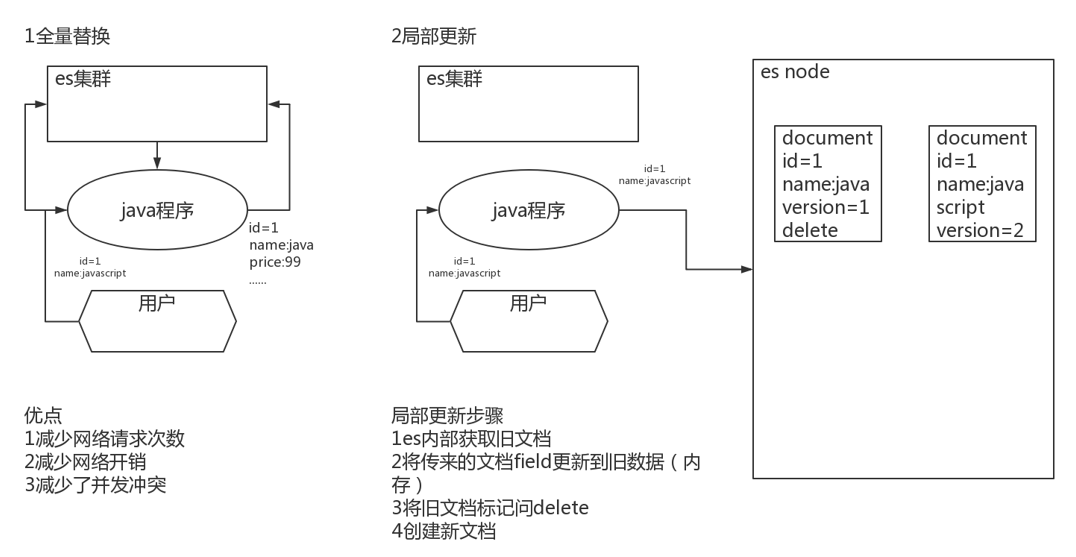
优点:
-
大大减少网络传输次数和流量,提升性能
-
减少并发冲突发生的概率。
2)演示
插入文档
PUT /test_index/_doc/5
{
"test_field1": "itcst",
"test_field2": "孤独的小人物"
}
修改字段1
POST /test_index/_update/5
{
"doc": {
"test_field2": "孤独的小人物 2"
}
}
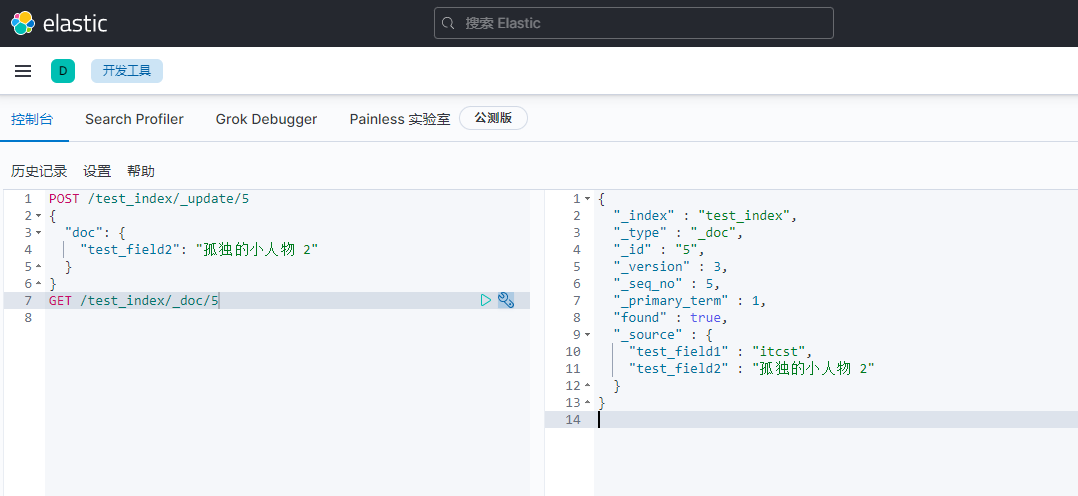
2.3.6 使用脚本更新
es可以内置脚本执行复杂操作。例如painless脚本。
注意:groovy脚本在es6以后就不支持了。原因是耗内存,不安全远程注入漏洞。
1)内置脚本
需求1:修改文档6的num字段,+1。
插入数据
PUT /test_index/_doc/6
{
"num": 0,
"tags": []
}
执行脚本操作
POST /test_index/_update/6
{
"script": "ctx._source.num+=1"
}
查询数据
GET /test_index/_doc/6
返回
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "6",
"_version" : 3,
"_seq_no" : 8,
"_primary_term" : 1,
"found" : true,
"_source" : {
"num" : 2,
"tags" : [ ]
}
}
需求2:搜索所有文档,将num字段乘以2输出
插入数据
PUT /test_index/_doc/7
{
"num": 5
}
查询
GET /test_index/_search
{
"script_fields": {
"my_doubled_field": {
"script": {
"lang": "expression",
"source": "doc['num'] * multiplier",
"params": {
"multiplier": 2
}
}
}
}
}
返回
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "7",
"_score" : 1.0,
"fields" : {
"my_doubled_field" : [
10.0
]
}
}
2)外部脚本
Painless是内置支持的。脚本内容可以通过多种途径传给 es,包括 rest 接口,或者放到 config/scripts目录等,默认开启。
注意:脚本性能低下,且容易发生注入,本教程忽略。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting-using.html
2.3.7 图解es的并发问题
如同秒杀,多线程情况下,es同样会出现并发冲突问题。
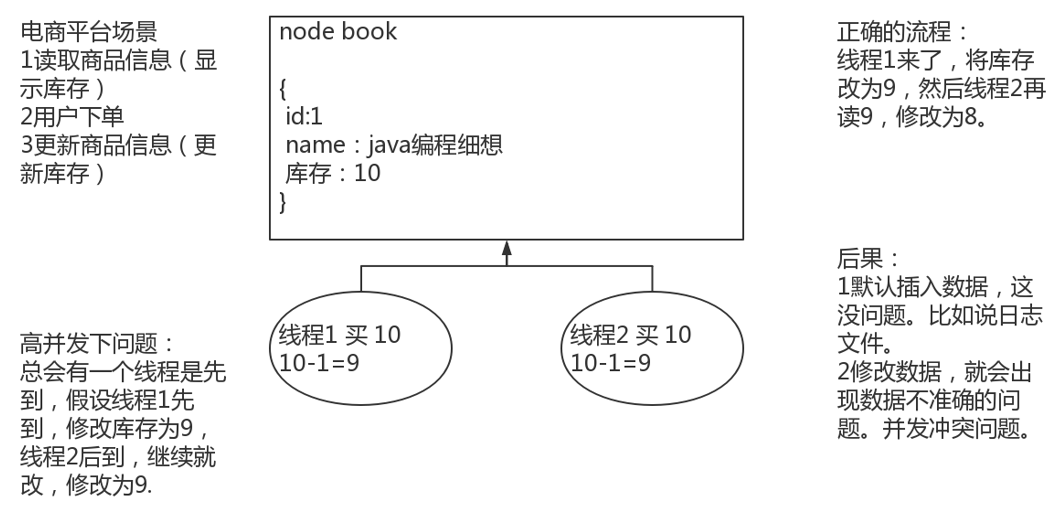
2.3.8 图解悲观锁与乐观锁机制
为控制并发问题,我们通常采用锁机制。分为悲观锁和乐观锁两种机制。
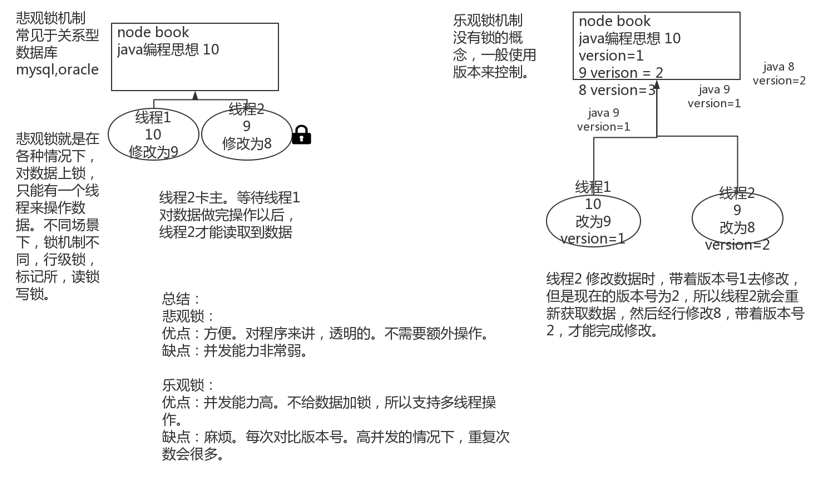
悲观锁:很悲观,所有情况都上锁。此时只有一个线程可以操作数据。具体例子为数据库中的行级锁、表级锁、读锁、写锁等。
特点:优点是方便,直接加锁,对程序透明。缺点是效率低。
乐观锁:很乐观,对数据本身不加锁。提交数据时,通过一种机制验证是否存在冲突,如es中通过版本号验证。
特点:优点是并发能力高。缺点是操作繁琐,在提交数据时,可能反复重试多次。
2.3.9 图解es内部基于_version乐观锁控制
1)实验基于_version的版本控制
es对于文档的增删改都是基于版本号。
新增多次文档:
PUT /test_index/_doc/3
{
"test_field": "test"
}
返回版本号递增
删除此文档
DELETE /test_index/_doc/3
返回
DELETE /test_index/_doc/3
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"_version" : 6,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1
}
再新增
PUT /test_index/_doc/3
{
"test_field": "test"
}
可以看到版本号依然递增,验证延迟删除策略。
如果删除一条数据立马删除的话,所有分片和副本都要立马删除,对es集群压力太大。
2)图解es内部并发控制
es内部主从同步时,是多线程异步。乐观锁机制。
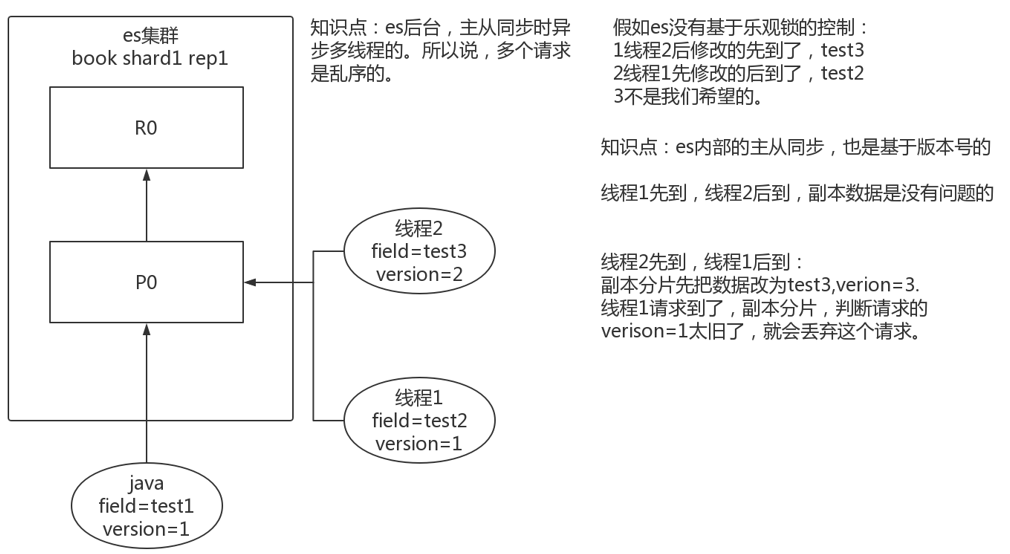
2.3.10 演示客户端程序基于_version并发操作流程
java python客户端更新的机制。
1)新建文档
PUT /test_index/_doc/5
{
"test_field": "itcast"
}
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
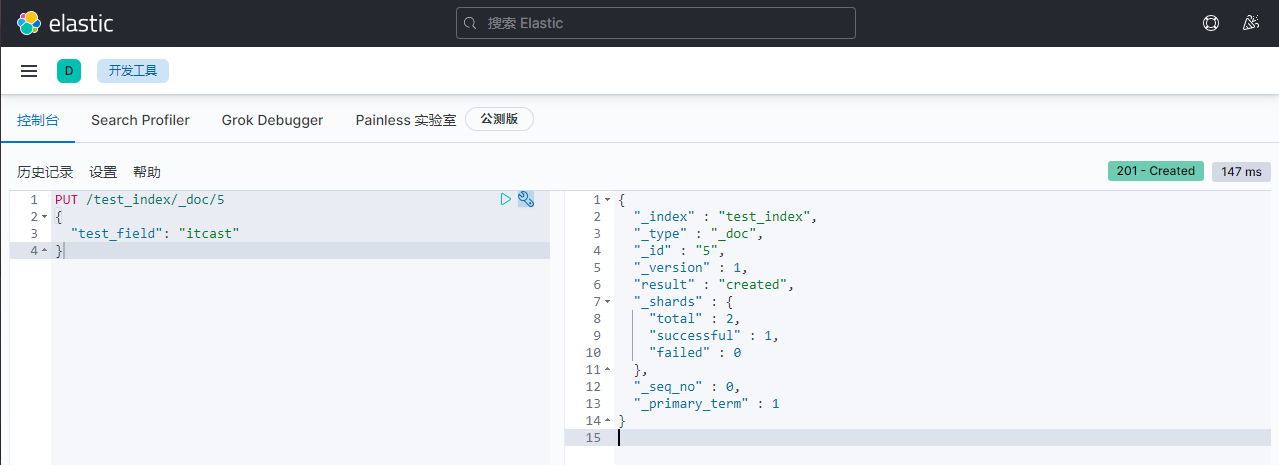
2)客户端1修改。带版本号1。
首先获取数据的当前版本号
GET /test_index/_doc/5
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "itcast"
}
}
更新文档
PUT /test_index/_doc/5?version=1
{
"test_field": "itcast1"
}
报错
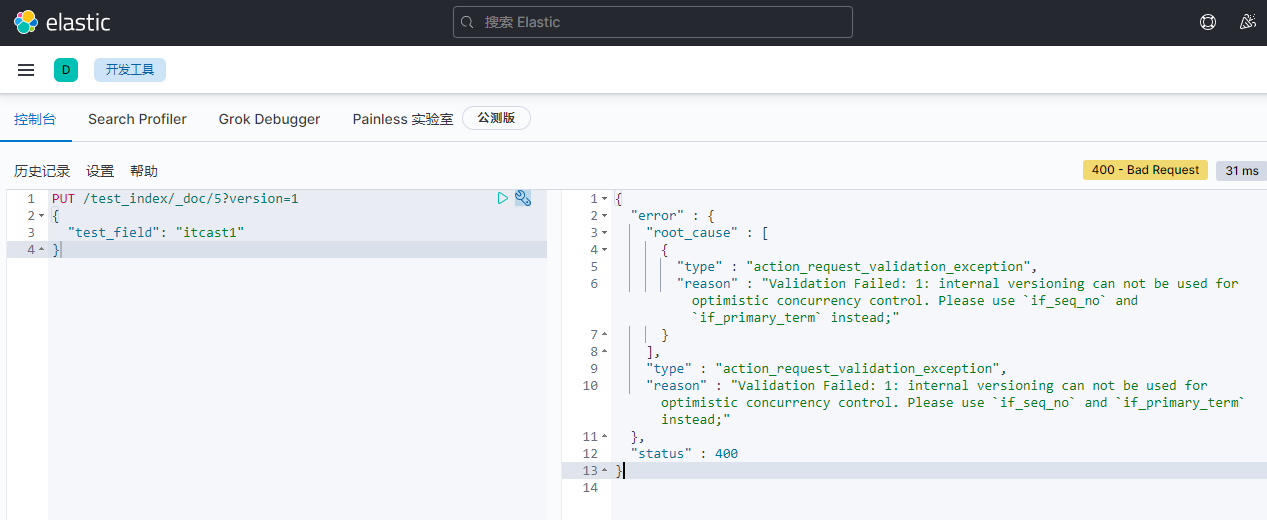
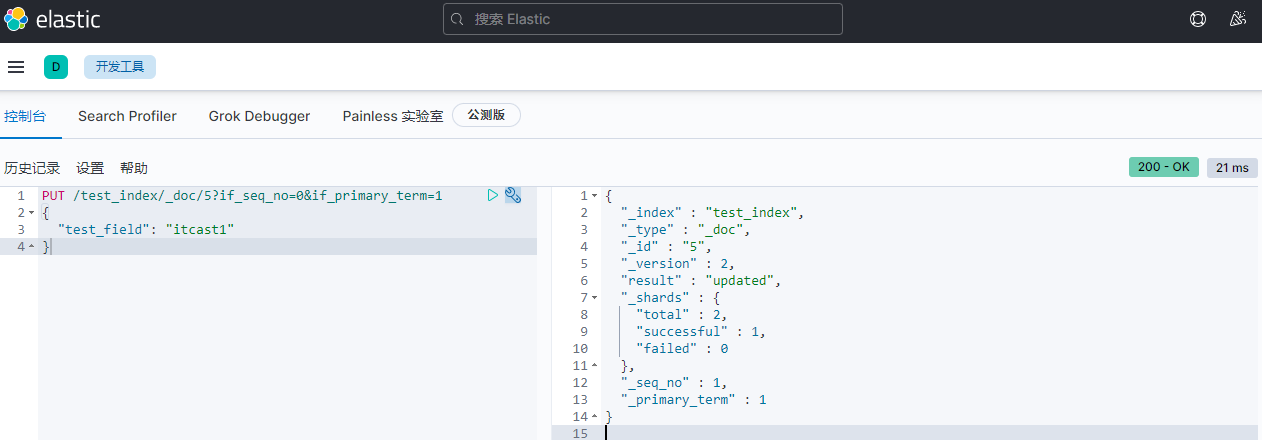
更换修改方法:
PUT /test_index/_doc/5?if_seq_no=0&if_primary_term=1
{
"test_field": "itcast1"
}
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "5",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
3)客户端2并发修改。带版本号1
更新文档:
PUT /test_index/_doc/5?version=1
{
"test_field": "itcast2"
}
报错:
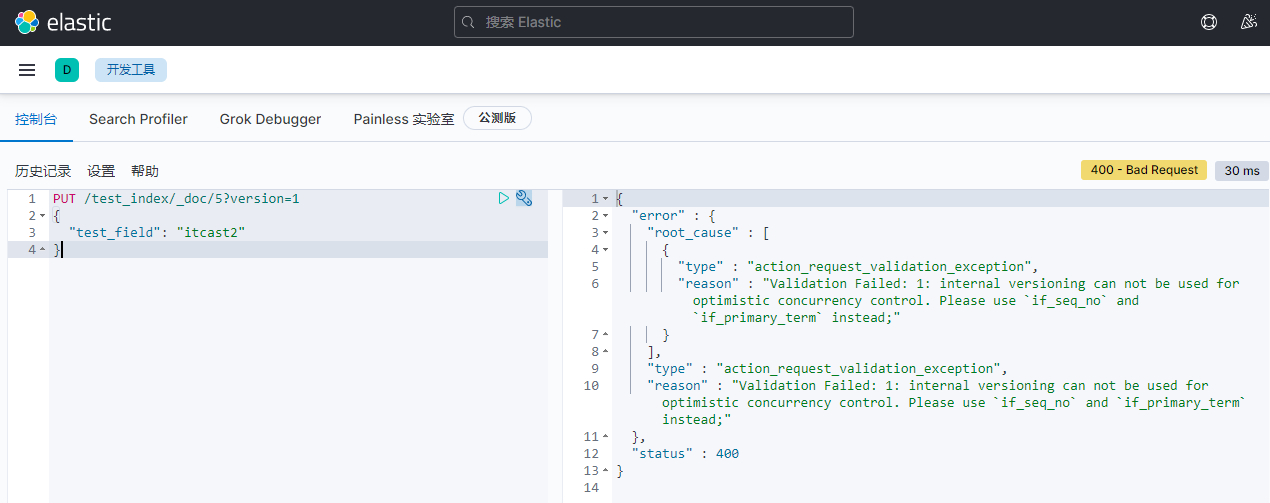
更换修改方法:
PUT /test_index/_doc/5?if_seq_no=0&if_primary_term=1
{
"test_field": "itcast1"
}
报错:
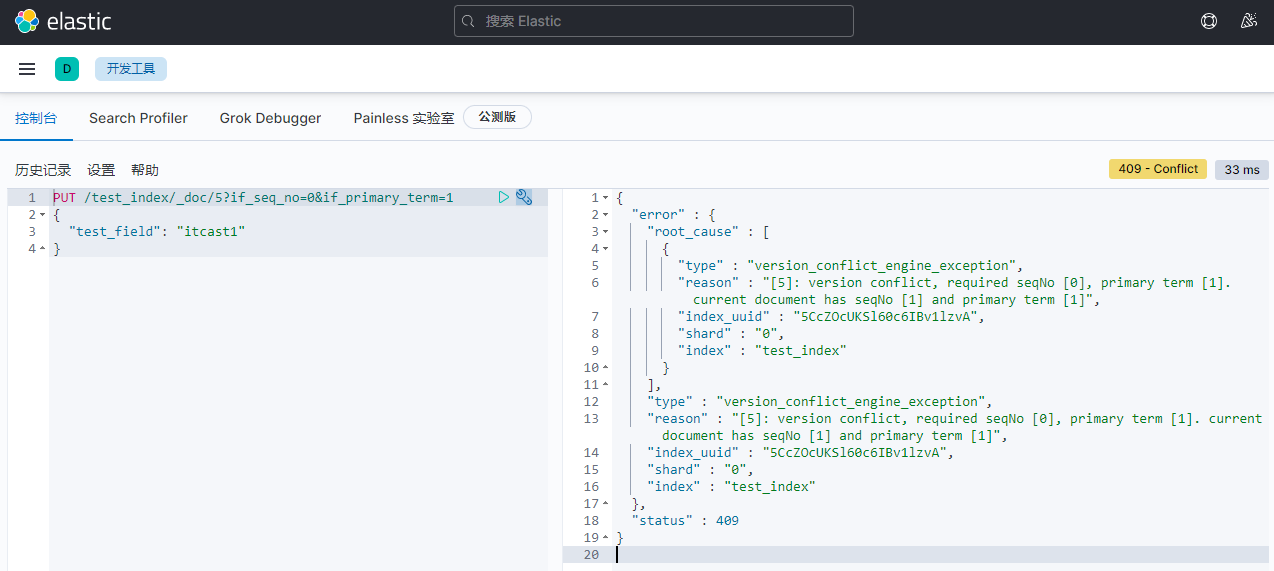
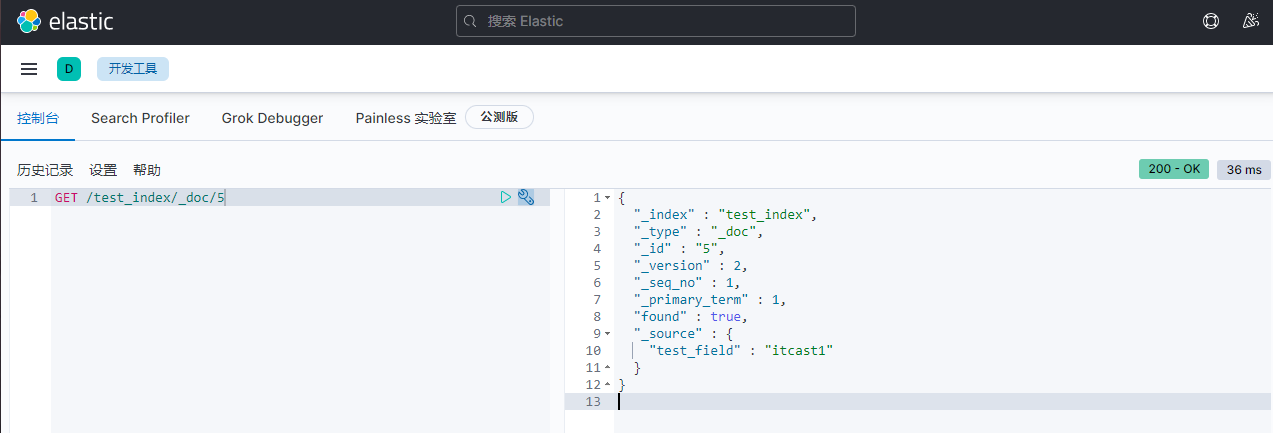
4)客户端2重新查询。得到最新版本为2。seq_no=1
GET /test_index/_doc/5
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "5",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"test_field" : "itcast1"
}
}
5)客户端2并发修改。带版本号2。
更新文档:
PUT /test_index/_doc/5?version=2
{
"test_field": "itcast2"
}
报错:
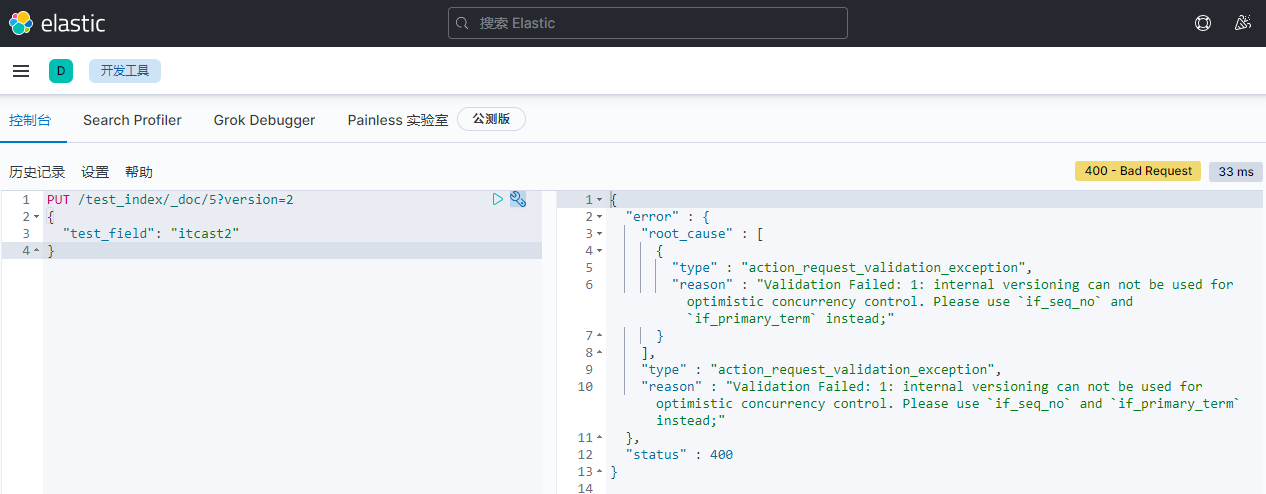
更换修改方法:
PUT /test_index/_doc/5?if_seq_no=1&if_primary_term=1
{
"test_field": "itcast2"
}
返回:
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "5",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
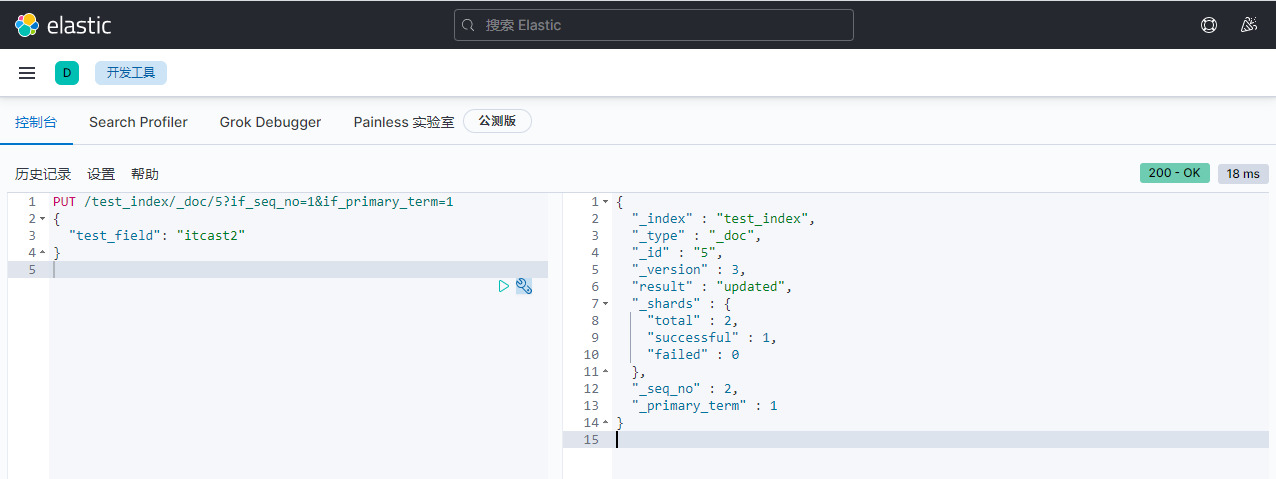
修改成功。
2.3.11 演示自己手动控制版本号 external version
背景:已有数据是在数据库中,有自己手动维护的版本号的情况下,可以使用external version控制。hbase。
要求:修改时external version要大于当前文档的_version
对比:基于_version时,修改的文档version等于当前文档的版本号。
使用?version=1&version_type=external
1)新建文档
PUT /test_index/_doc/4
{
"test_field": "itcast"
}
更新文档:
2)客户端1修改文档
PUT /test_index/_doc/4?version=2&version_type=external
{
"test_field": "itcast1"
}
3)客户端2同时修改
PUT /test_index/_doc/4?version=2&version_type=external
{
"test_field": "itcast2"
}
返回:
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[4]: version conflict, current version [2] is higher or equal to the one provided [2]",
"index_uuid" : "5CcZOcUKSl60c6IBv1lzvA",
"shard" : "0",
"index" : "test_index"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[4]: version conflict, current version [2] is higher or equal to the one provided [2]",
"index_uuid" : "5CcZOcUKSl60c6IBv1lzvA",
"shard" : "0",
"index" : "test_index"
},
"status" : 409
}
4)客户端2重新查询数据
GET /test_index/_doc/4
5)客户端2重新修改数据
PUT /test_index/_doc/4?version=3&version_type=external
{
"test_field": "itcast2"
}
2.3.12 批量查询 mget
单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大。
1)mget 批量查询:
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : 7
}
]
}
返回:
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "1",
"found" : false
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "7",
"found" : false
}
]
}
提示去掉type
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_id" : 2
},
{
"_index" : "test_index",
"_id" : 3
}
]
}
返回:
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"found" : false
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"found" : false
}
]
}
2)同一索引下批量查询:
GET /test_index/_mget
{
"docs" : [
{
"_id" : 2
},
{
"_id" : 3
}
]
}
返回:
{
"docs" : [
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "2",
"found" : false
},
{
"_index" : "test_index",
"_type" : "_doc",
"_id" : "3",
"found" : false
}
]
}
3)第三种写法:搜索写法
post /test_index/_doc/_search
{
"query": {
"ids" : {
"values" : ["1", "7"]
}
}
}
返回:
{
"took" : 143,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号