企业级实战模块五:Prometheus+Grafana企业级监控系统(上)
1 Prometheus介绍
1.1 Prometheus介绍
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
1.2 Prometheus特点
1)多维度数据模型 每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定: 这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。
(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
可以对采集的metrics指标进行加法,乘法,连接等操作;
3)可以直接在本地部署,不依赖其他分布式存储;
4)通过基于HTTP的pull方式采集时序数据;
5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
7)有多种可视化图像界面,如Grafana等。
8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
1.3 Prometheus样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
-
指标(metric):指标名称和描述当前样本特征的 labelsets;
-
时间戳(timestamp):一个精确到毫秒的时间戳;
-
样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
表示方式:
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
<metric name>{<label name>=<label value>, ...}
例如,指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为:
api_http_requests_total{method="POST", handler="/messages"}
1.4 Prometheus组件介绍
1)Prometheus Server
用于收集和存储时间序列数据。
2)Client Library
客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
3)Exporters
prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
4)Alertmanager
从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。
5)Grafana
监控仪表盘,可视化监控数据
6)pushgateway
各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
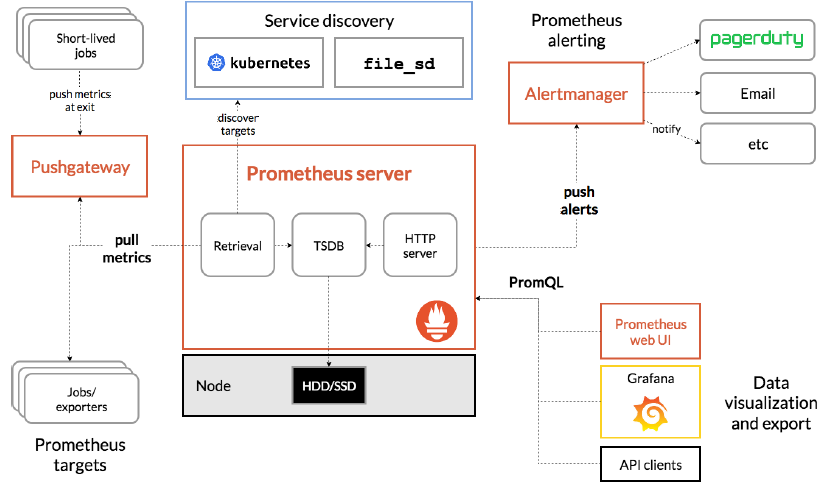
从上图可发现,Prometheus整个生态圈组成主要包括prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui界面,Prometheus server由三个部分组成,Retrieval,Storage,PromQL
-
Retrieval负责在活跃的target主机上抓取监控指标数据
-
Storage存储主要是把采集到的数据存储到磁盘中
-
PromQL是Prometheus提供的查询语言模块
1.5 Prometheus工作流程
-
Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据;
-
Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
-
Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
-
Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
-
Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
-
Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
1.6 Prometheus和zabbix对比分析
2 Prometheus部署模式和数据类型
2.1 基本高可用 模式
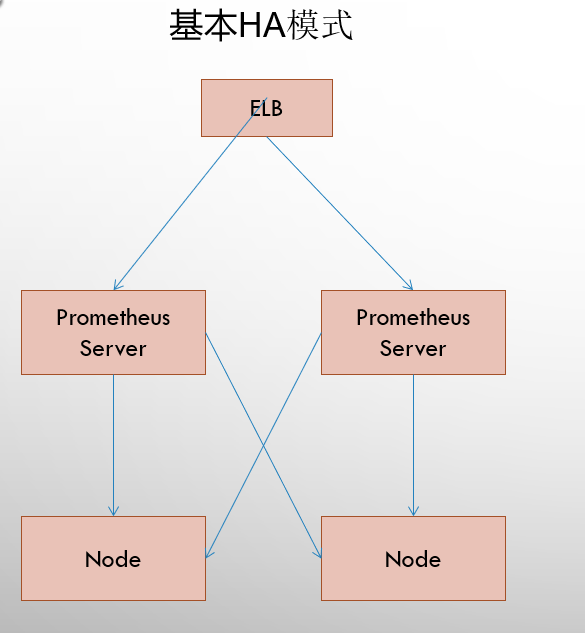
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
2.2 基本高可用远程存储
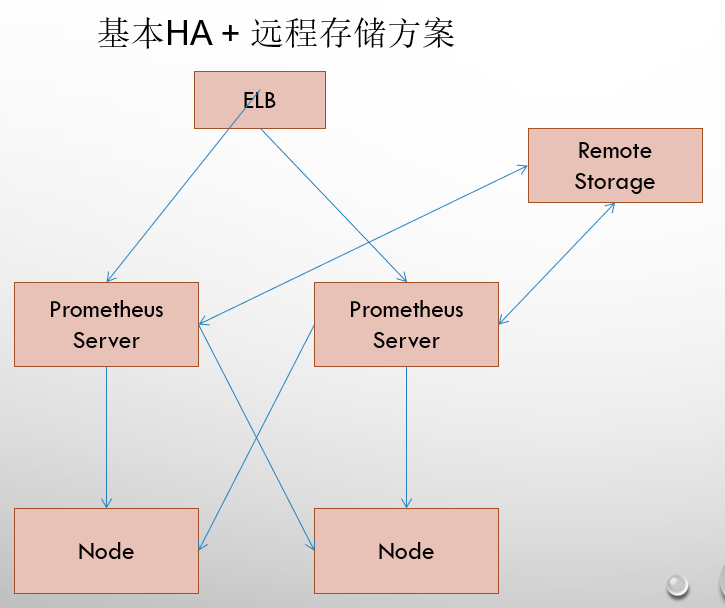
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
2.3 基本 HA + 远程存储 + 联邦集群方案
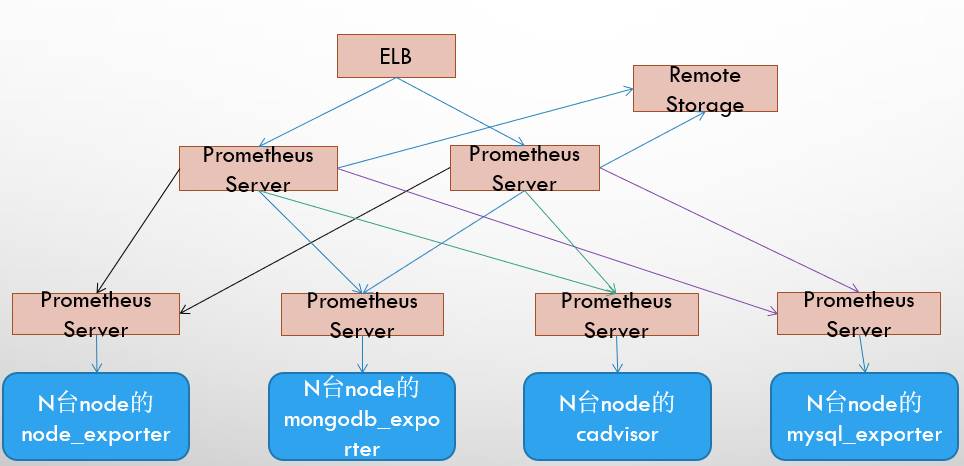
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
2.4 数据类型-Counter
Counter是计数器类型:
-
Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
-
一直增加,不会减少。
-
重启进程后,会被重置。
http_response_total{method="GET",endpoint="/api/tracks"} 100
http_response_total{method="GET",endpoint="/api/tracks"} 160
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来进行说明:
-
通过rate()函数获取HTTP请求量的增长率
rate(http_requests_total[5m])
-
查询当前系统中,访问量前10的HTTP地址
topk(10, http_requests_total)
2.5 数据类型-Gauge
Gauge是测量器类型:
-
Gauge是常规数值,例如温度变化、内存使用变化。
-
可变大,可变小。
-
重启进程后,会被重置
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
2.6 数据类型- histogram
histogram是柱状图:
-
在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
-
对每个采样点值累计和(sum)
-
对采样点的次数累计和(count)
度量指标名称: [basename]_上面三类的作用度量指标名称
[basename]_bucket{le="上边界"}, 这个值为小于等于上边界的所有采样点数量
[basename]_sum
[basename]_count
备注:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
2.7 数据类型-summary
与Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数( 通过客户端计算,然后展示出来),而不是通过区间来计算。 它也有三种作用:
-
对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于 60 分不及格的同学比例,统计低于 80 分的同学比例,统计低于 95 分的同学比例)
-
统计班上所有同学的总成绩 (sum)
-
统计班上同学的考试总人数 (count)
带有度量指标的[basename] 的 summary 在抓取时间序列数据有如命名。
-
观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为 [basename] {分位数= “[φ]"}
-
[basename]_sum 是指所有观察值的总和
-
[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为<basename>{ quantile="<Φ>"} 。
-
含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",c ode="200",quantile="0.5",} 3.052404983 -
含义:这 12 次 http 请求中有 90% 的请求响应时间是 8.003261666s
io_namespace_http_requests_latency_seconds_summary{path="/",method="GET",code="200",quantile="0.9",} 8.003261666
所有样本值的大小总和,命名为<basename>_sum
-
含义:这 12 次 http 请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sum{path="/",metho d="GET",code="200",} 51.029495508
样本总数,命名为<basename>_count 。
-
含义:当前一共发生了 12 次 http 请求
io_namespace_http_requests_latency_seconds_summary_count{path="/",method="GET",code="200",}12.0
Histogram 与 Summary 的异同:
-
它们都包含了<basename>_sum 和 <basename>_count 指标
-
Histogram需要通过 <basename>_bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server 进行 wal_fsync 操作的总次数为 216 次,耗时2.88871612700000 2s 。其中中位数( quantile=0.5 )的耗时为 0.012352463 9 分位数( quantile=0.9的耗时为 0.014458005s 。
2.8 使用柱状图原因
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标(假设指标名称为<basename>):
样本的值分布在 bucket 中的数量,命名为 <basename>_bucket{le="<上边界>"}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
1)在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0
2)在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0
3)在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0
4)在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0
io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0
5)实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001
样本总数,命名为 <basename>_count。值和 <basename>_bucket{le="+Inf"} 相同。
6)实际含义: 当前一共发生了 2 次 http 请求
io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
注意:
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。注意后面的采样点是包含前面的采样点的,假设 xxx_bucket{...,le="0.01"} 的值为 10,而 xxx_bucket{...,le="0.05"} 的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 0.01s的,其余 20 个采样点的响应时间是介于0.01s 和 0.05s之间的。
可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。分位数可能不太好理解,你可以理解为分割数据的点。我举个例子,假设样本的 9 分位数(quantile=0.9)的值为 x,即表示小于 x 的采样值的数量占总体采样值的 90%。Histogram 还可以用来计算应用性能指标值(Apdex score)。
3 Prometheus监控Kubernetes集群
3.1 Prometheus监控Kubernetes介绍
对于Kubernetes 而言,我们可以把当中所有的资源分为几类:
-
基础设施层( Node ):集群节点,为整个集群和应用提供运行时资源
-
容器基础设施( Container ):为应用提供运行时环境
-
用户应用( Pod Pod 中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能 内部服务负载均衡( Service ):在集群内,通过 Service 在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
-
外部访问入口( Ingress ):通过 Ingress 提供集群外的访问入口,从而可以使外部客户端能够访问到部署在 Kubernetes 集群内的服务
因此,如果要构建一个完整的监控体系,我们应该考虑,以下5 个方面:
-
集群节点状态监控:从集群中各节点的 kubelet 服务获取节点的基本运行状态;
-
集群节点资源用量监控:通过 Daemonset 的形式在集群中各个节点部署 Node Exporter采集节点的资源使用情况;
-
节点中运行的容器监控:通过各个节点中 kubelet 内置的 cAdvisor 中获取个节点中所有容器的运行状态和资源使用情况;
-
如果在集群中部署的应用程序本身内置了对 Prometheus 的监控支持,那么我们还应该找到相应的 Pod 实例,并从该 Pod 实例中获取其内部运行状态的监控指标。
-
对 k8s 本身的组件做监控:apiserver、scheduler、controller-manager 、kubelet、kube-proxy
3.2 安装 node-exporter
介绍:
node-exporter 可以 采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包 括 CPU, 内存,磁盘,网络,文件数等信息。
安装:
1)创建应用目录
mkdir -p /opt/k8s-cfg/prometheus/
2)创建专属名称空间
kubectl create ns monitor-sa
3)下载镜像
https://registry.hub.docker.com/r/prom/node-exporter/tags
# 所有节点拉取镜像(也可以等待K8S进行拉取)
docker pull prom/node-exporter:v1.2.2
4)编写yaml文件
cat <<EOF> /opt/k8s-cfg/prometheus/node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v1.2.2
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/node-exporter.yaml
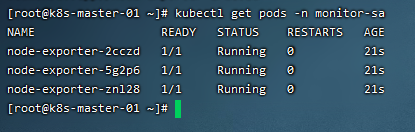
5)查看pod运行状态
kubectl get pods -n monitor-sa
6)获取监控数据
curl 192.168.5.8:9100/metrics > node-ex.log
7)过滤查询
curl 192.168.5.8:9100/metrics | grep node_cpu_seconds
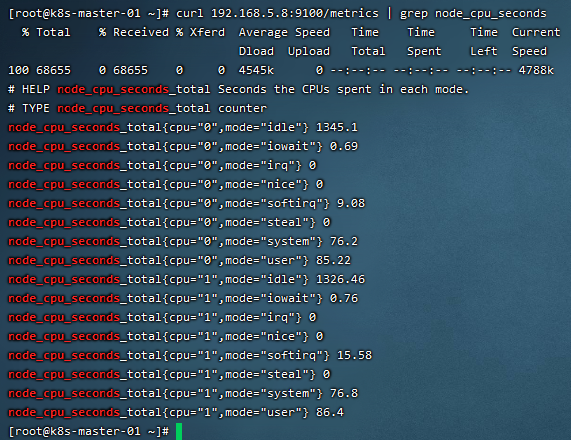
# HELP:解释当前指标的含义,上面表示在每种模式下 node 节点的 cpu 花费的时间,以 s 为单位
# TYPE:说明当前指标的数据类型,上面是 counter 类型
node_cpu_seconds_total{cpu="0",mode="idle"}
cpu0上 idle 进程占用 CPU 的总时间, CPU 占用时间是一个只增不减的度量指标,从类型中也可以看出 node_cpu 的数据类型是 counter (计数器)
counter计数器:只是采集递增的指标
curl 192.168.5.8:9100/metrics | grep node_load
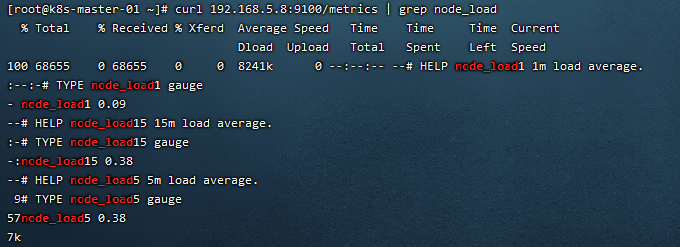
node_load1该指标反映了当前主机在最近 一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此 node_load1 反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为 gauge (标准尺寸)
gauge标准尺寸:统计的指标可增加可减少
4 Prometheus监控Kubernetes服务
4.1 创建SA账号,设置RBAC授权
# 创建账号
kubectl create serviceaccount monitor -n monitor-sa
# 绑定rolebinding
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
4.2 创建Prometheus数据存储
# 所有服务器上安装nfs服务
yum -y install nfs-utils
# 在master节点准备一个共享目录
mkdir -pv /data/nfs
# 将共享目录以读写权限暴露给192.168.5.0/24网段中的所有主机
cat <<EOF> /etc/exports
/data/nfs 192.168.5.0/24(rw,no_root_squash)
EOF
# 启动nfs服务
systemctl enable nfs && systemctl restart nfs
# 查看共享存储信息
showmount -e 192.168.5.8
4.3 创建configmap配置文件
wget -P /opt/k8s-cfg/prometheus/ https://cunqi0105-1300757323.cos.ap-shanghai.myqcloud.com/configuration-file/prometheus-configmap.yaml
kubectl apply -f /opt/k8s-cfg/prometheus/prometheus-configmap.yaml
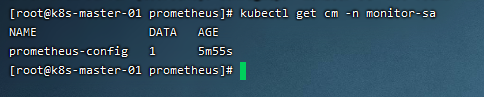
# 查看configmap文件
kubectl get cm -n monitor-sa
# 注解
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
global:
scrape_interval: 15s
# 采集目标主机监控据的时间间隔
scrape_timeout: 10s
# 数据采集超时时间默认10s
evaluation_interval: 1m
# 触发告警检测的时间,默认是1m
scrape_configs:
# scrape_configs配置数据源,称为 target ,每个target 用 job_name 命名。又分为静态配置和服务发现
# ----------------------------------------------------------------------------
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
# 使用的是 k8s 的服务发现
- role: node
# 使用 node 角色,它使用默认的 kubelet 提供的 http 端口来发现集群中每个 node 节点。
relabel_configs:
# 重新标记
- source_labels: [__address__]
# 配置的原始标签,匹配地址
regex: '(.*):10250'
# 匹配带有 10250 端口的 url
replacement: '${1}:9100'
# 把匹配到的 ip:10250 的 ip 保留
target_label: __address__
# 新生成的 url 是${1} 获取到的 ip :9100
action: replace
- action: labelmap
# 匹配到下面正则表达式的标签会被保留 如果不做 regex 正则的话, 默认只是会显示 instance 标签
regex: __meta_kubernetes_node_label_(.+)
# ----------------------------------------------------------------------------
- job_name: 'kubernetes-node-cadvisor'
# 抓取 cAdvisor 数据,是获取 kubelet上 /metrics/cadvisor 接口数据来获取容器的资源使用情况
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
# 把匹配到的标签保留
regex: __meta_kubernetes_node_label_(.+)
# 保留匹配到的具有 __meta_kubernetes_node_label 的标签
- target_label: __address__
# 获取到的地址: :__address__="192.168.5.8:
replacement: kubernetes.default.svc:443
# 把获取到的地址替换成新的地址kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
# 把原始标签中 __meta_kubernetes_node_name 值匹配到
target_label: __metrics_path__
# 获取 __metrics_ 对应的值
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
# 把 metrics 替换成新的 值 api/v1/nodes/xianchaomaster1/proxy/metrics/cadvisor
# ${1}是 __meta_kubernetes_node_name 获取到的值
# 新的URL地址就变为https://kubernetes.default.svc/api/v1/nodes/k8s-master-01/proxy/metrics/cadvisor
# ----------------------------------------------------------------------------
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
# 使用 k8s 中的 endpoint 服务发现 ,采集 apiserver 6443 端口获取到的数据
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
#endpoint 这个对象的名称空间、endpoint对象的服务名、exnpoint 的端口名称
action: keep
# 采集满足条件的实例,其他实例不采集
regex: default;kubernetes;https
# 正则匹配到的默认空间下的 service 名字是 kubernetes ,协议是 https 的 endpoint 类型保留下来
# ----------------------------------------------------------------------------
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
#应用中自定义暴露的指标,也许你暴露的 API 接口不是 /metrics 这个路径,那么你可以在这个POD 对应的 service 中做一个 "prometheus.io/path = /mymetrics" 声明, 上 面的意思就是把你声明的这个路径赋值给 __metrics_ 其实就是让 prometheus 来获取自定义应用暴露的 metrices 的具体路径,不过这里写的要和 service 中做好约定 如果 service 中这样写 prometheus.io/app-metricspath: '/metrics' 那么 你这里就要__meta_kubernetes_service_annotation_prometheus_io_app_metrics_path 这样写 。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
#暴露自定义的应用的端口,就是把地址和你在 service 中定义的 "prom etheus.io/port =<port>" 声明做一个拼接 然后赋值给 __address__,这样 prometheus 就能获取自定义应用的端口,然后通过这个端口再结合 __metrics_ 来获取指标,如果 __metrics_ 值不是默认的 /metrics 那么就要使用上面的标签替换来获取真正暴露的具体路径 。
- action: labelmap
# action: labelmap # 保留下面匹配到的标签
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
# 替换 __meta_kubernetes_namespace 变成 kubernetes_namespace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
4.4 创建deploy文件
cat <<EOF> /opt/k8s-cfg/prometheus/prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
securityContext:
runAsUser: 0
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: Always
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
- --web.enable-lifecycle
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus/prometheus.yml
name: prometheus-config
subPath: prometheus.yml
- mountPath: /prometheus/
name: prometheus-storage-volume
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
items:
- key: prometheus.yml
path: prometheus.yml
mode: 0644
- name: prometheus-storage-volume
nfs:
server: 192.168.5.8
path: /data/nfs
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/prometheus-deploy.yaml
# 查看POD情况
kubectl get pods -n monitor-sa -o wide

4.5 创建service文件
cat <<EOF> /opt/k8s-cfg/prometheus/prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/prometheus-svc.yaml
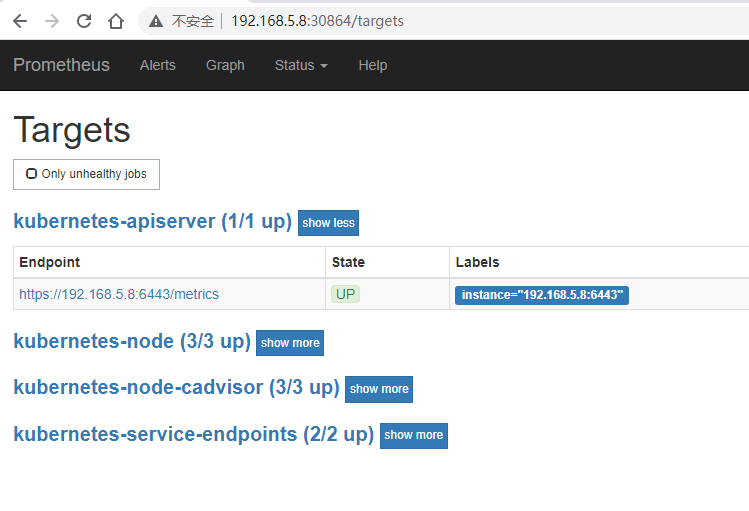
# 查看service 状态
kubectl get svc -n monitor-sa -o wide

5 可视化 UI 界面 Grafana 接入
5.1 Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知 给告警接收方 。它主要有以下六大特点:
-
展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
-
数据源: Graphite InfluxDB OpenTSDB Prometheus Elasticsearch CloudWatch 和KairosDB 等;
-
通知提醒:以可视方式定义最重要指标的警报规则, Grafana 将不断 计算并发送通知,在数据达到阈值时通过 Slack 、 PagerDuty 等获得通知;
-
混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
-
注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记 。
5.2 部署Grafana
1)创建deploy文件
cat <<EOF> /opt/k8s-cfg/prometheus/grafana-deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: monitor-sa
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/grafana-deploy
2)创建service文件
cat <<EOF> /opt/k8s-cfg/prometheus/grafana-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: monitoring-grafana
namespace: monitor-sa
labels:
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
spec:
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/grafana-svc.yaml
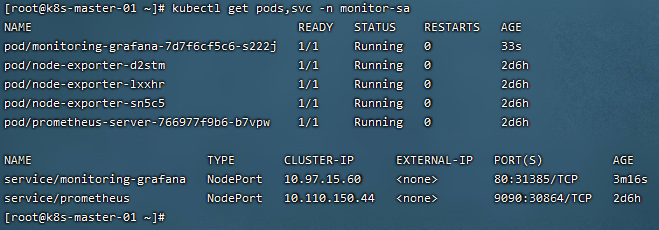
3)查看部署情况
kubectl get pods,svc -n monitor-sa
4)访问Grafana web页面
http://192.168.5.8:31385/
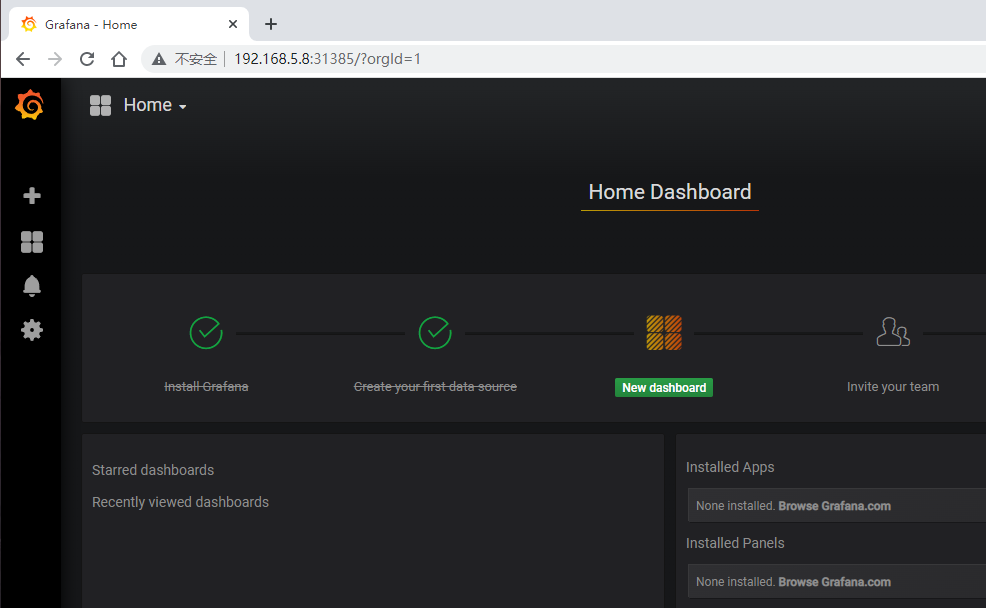
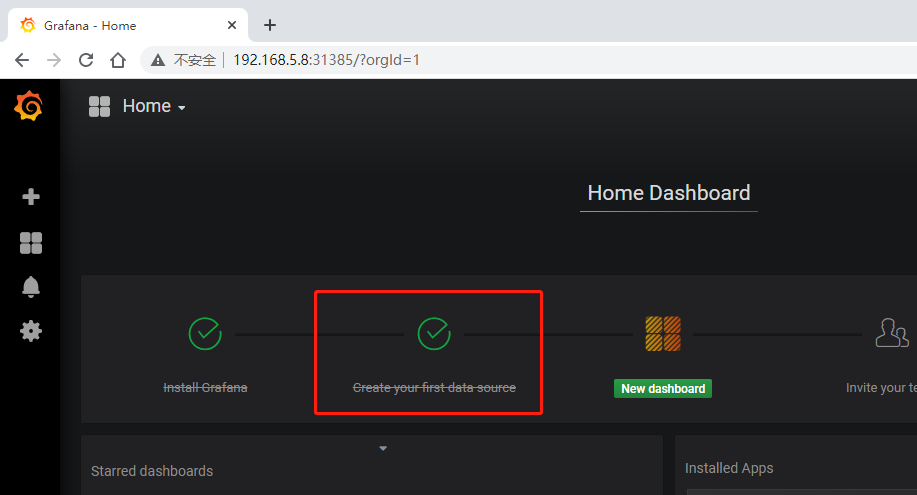
5.3 接入 Prometheus 数据源
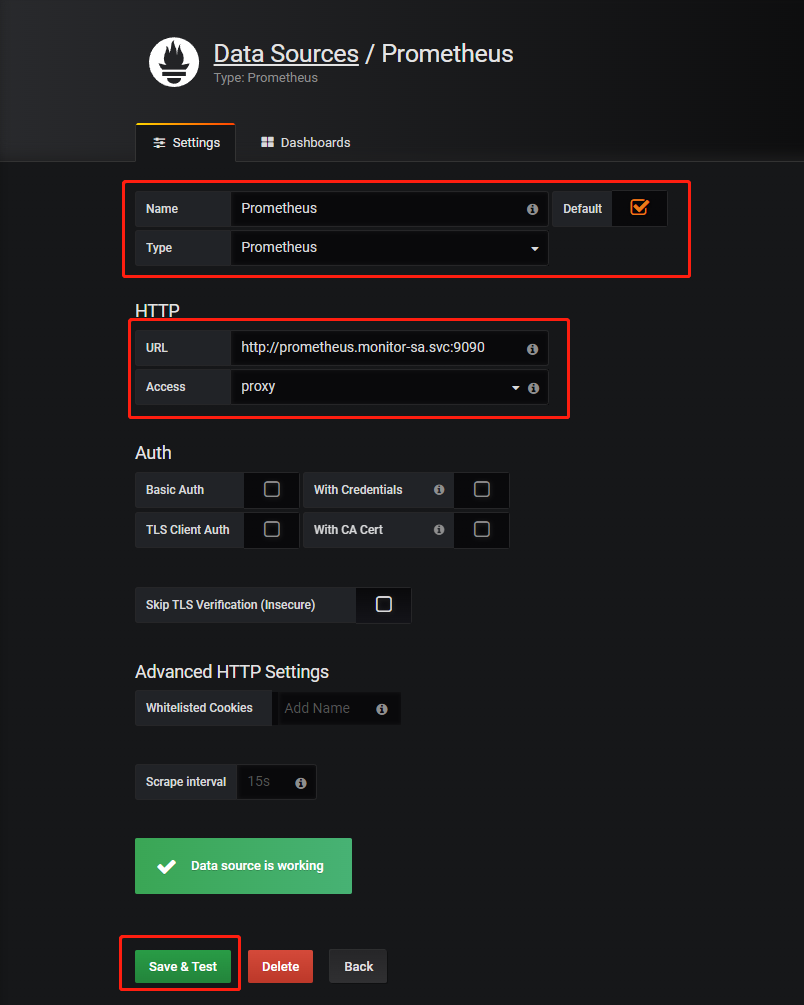
1)接入数据源
# 全质量域名
http://prometheus.monitor-sa.svc:9090
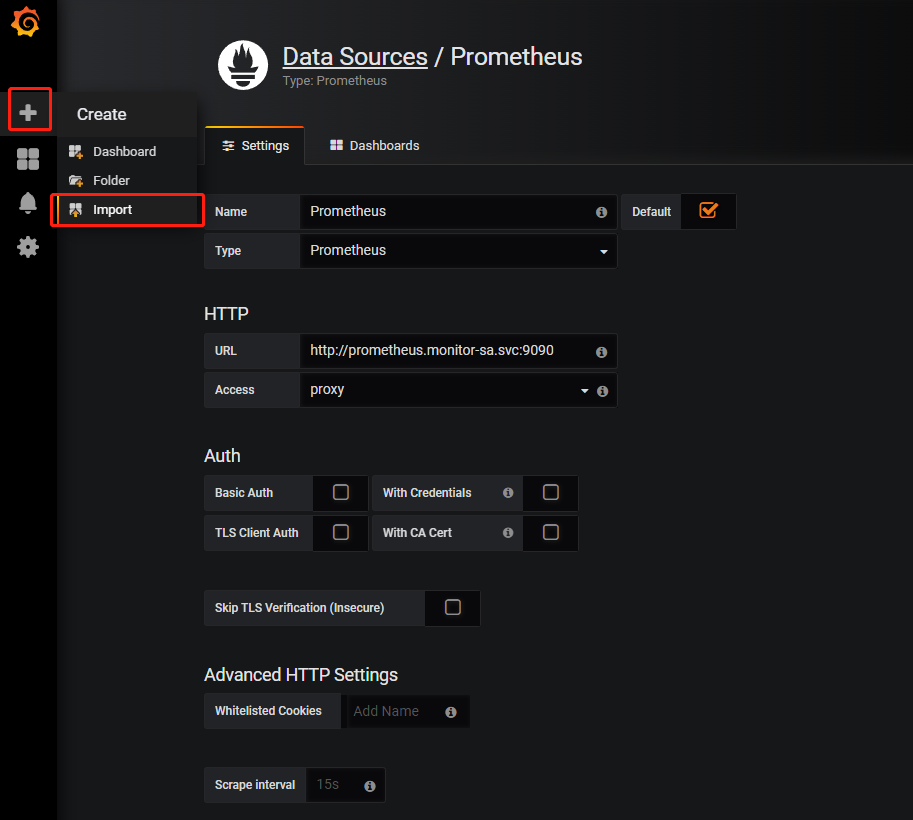
2)导入node节点监控模板
监控模板下载地址:
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
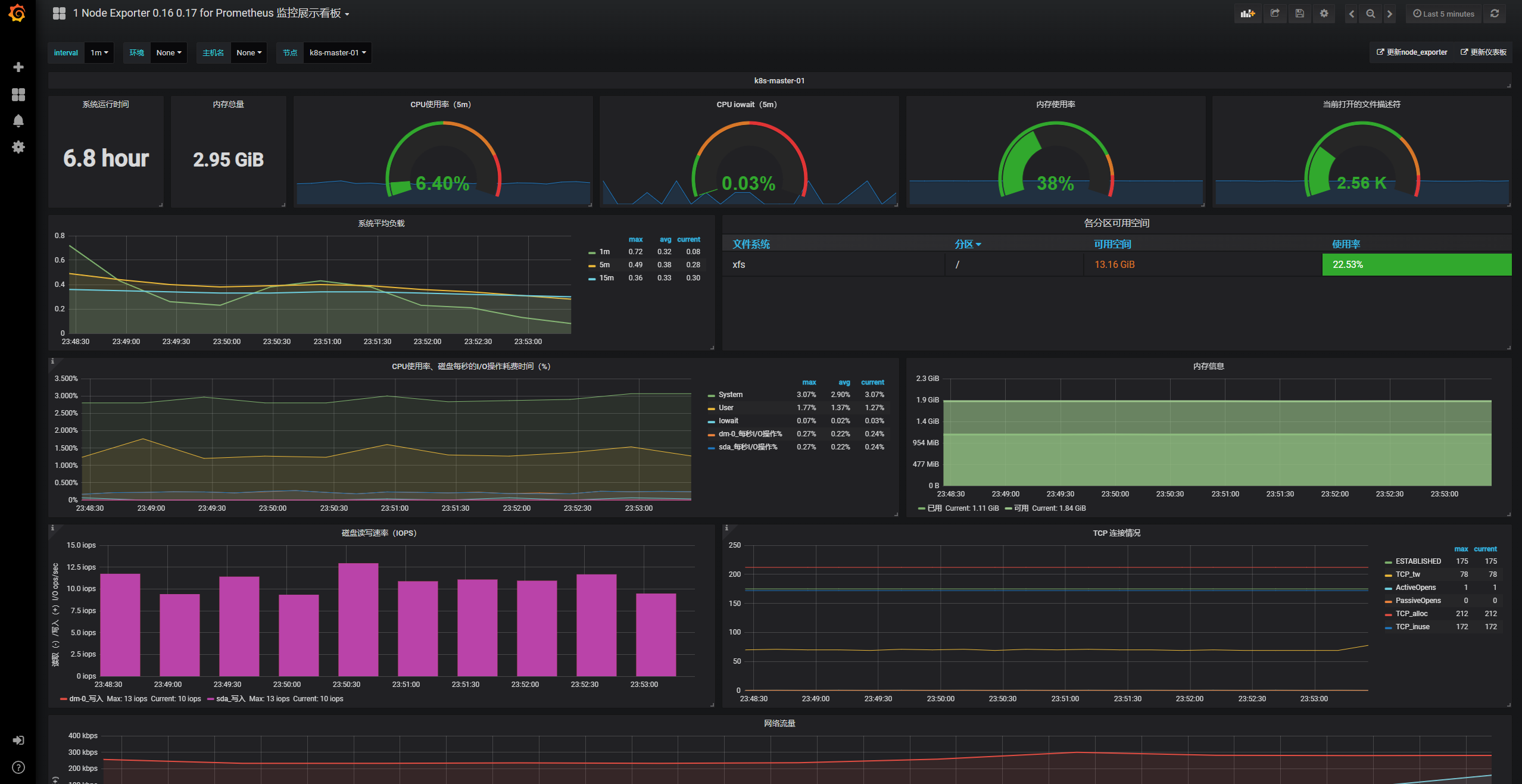
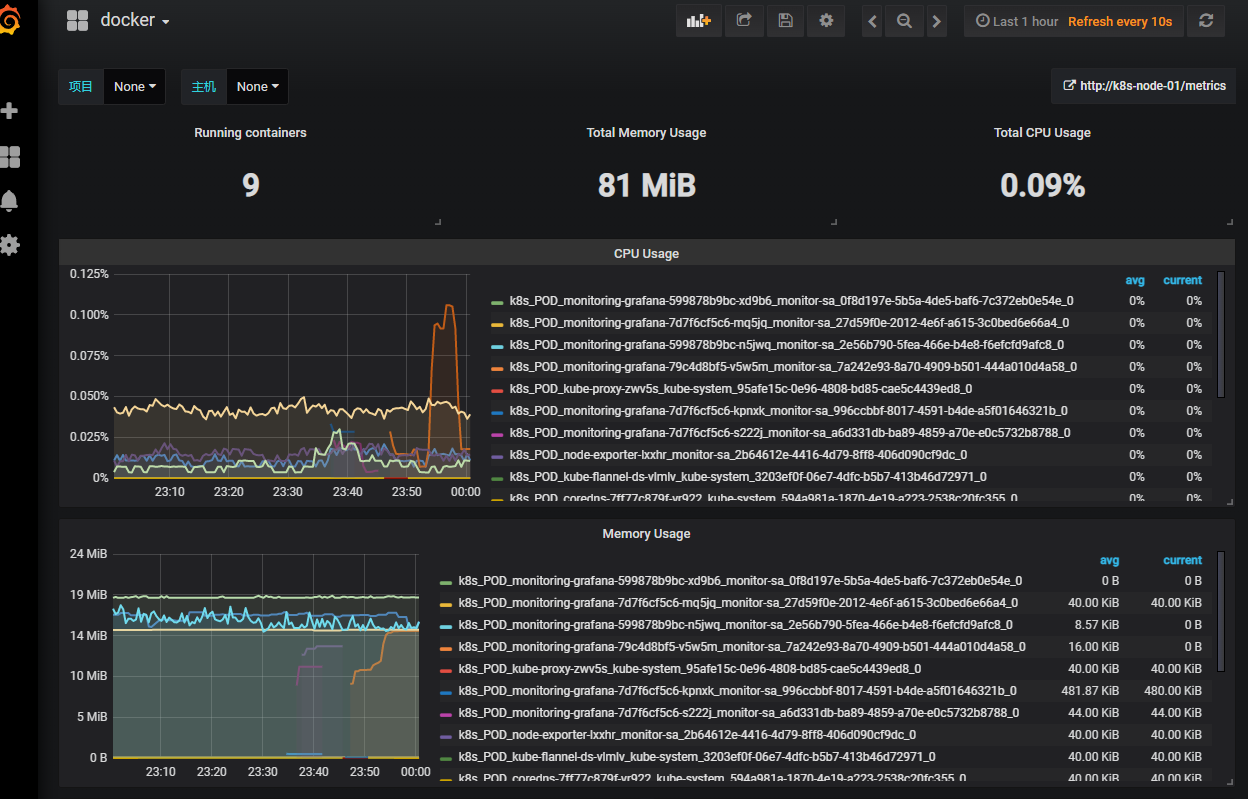
3)导入docker监控模板
监控模板下载地址:
https://grafana.com/grafana/dashboards/10619
6 安装kube-state-metrics组件
kube-state-metrics 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment 、Node 、 Pod ,需要注意的是 kube state metrics 只是简单的提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如 Deployment 、 Pod 、副本状态等;调度了多少个 replicas ?现在可用的有几个?多少个 Pod 是 running/stopped/terminated 状态? Pod 重启了多少次?有多少 job 在运行中。
安装kube-state-metrics 组件
1)创建RBAC
cat <<EOF> /opt/k8s-cfg/prometheus/kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/kube-state-metrics-rbac.yaml
2)安装 kube-state-metrics 组件
cat <<EOF> /opt/k8s-cfg/prometheus/kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
ports:
- containerPort: 8080
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/kube-state-metrics-deploy.yaml
3)创建 service
cat <<EOF> /opt/k8s-cfg/prometheus/kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
EOF
kubectl apply -f /opt/k8s-cfg/prometheus/kube-state-metrics-svc.yaml
4)查看部署情况
kubectl get pods,svc -n kube-system
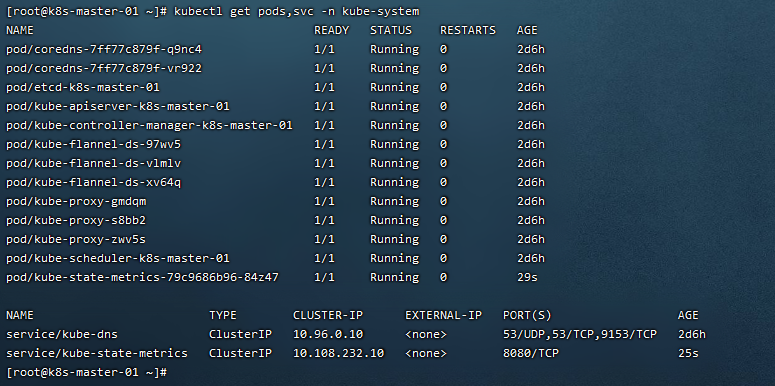
5)添加采集数据
监控模板下载地址:
https://grafana.com/grafana/dashboards/13332

 浙公网安备 33010602011771号
浙公网安备 33010602011771号