分布式锁的几种实现
前言
针对共享资源的互斥访问历来是很多业务系统需要解决的问题。用到分布式锁说明遇到了多个进程共同访问同一个资源的问题。
一般是在两个场景下会防止对同一个资源的重复访问:
- 提高效率。比如多个节点计算同一批任务,如果某个任务已经有节点在计算了,那其他节点就不用重复计算了,以免浪费计算资源。不过重复计算也没事,不会造成其他更大的损失。也就是允许偶尔的失败。
- 保证正确性。这种情况对锁的要求就很高了,如果重复计算,会对正确性造成影响。这种不允许失败。
引入分布式锁势必要引入一个第三方的基础设施,比如 MySQL,Redis,Zookeeper 等。本文聊聊各种实现的方案。
1. 单机锁和分布式锁
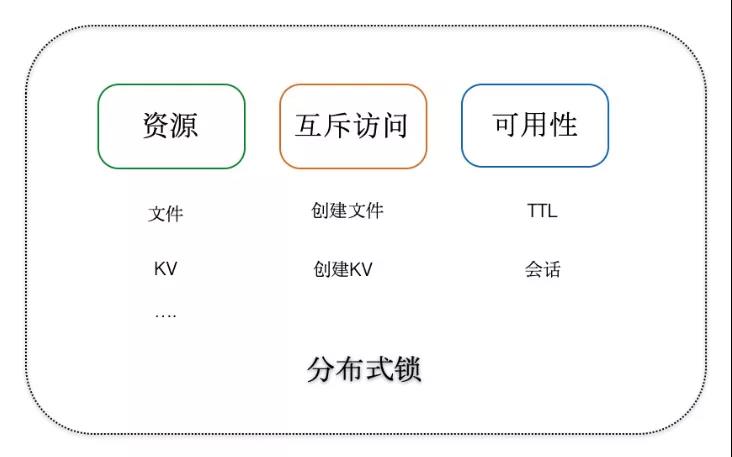
由此抽象一下分布式锁的概念,首先分布式锁需要是一个资源,这个资源能够提供并发控制,并输出一个排他性的状态,也就是:
锁 = 资源 + 并发控制 + 所有权展示
以常见的单机锁为例:
- Spinlock = BOOL +CAS(乐观锁)
- Mutex = BOOL + CAS + 通知(悲观锁)
Spinlock 和 Mutex 都是一个 Bool 资源,通过原子的 CAS 指令:当现在为 0 设置为 1,成功的话持有锁,失败的话不持有锁,如果不提供所有权的展示,例如 AtomicInteger,也是通过资源(Interger)+ CAS,但是不会明确的提示所有权,因此不会被视为一种锁,当然,可以将“所有权展示”这个更多地视为某种服务提供形式的包装。
单机环境下,内核具备“上帝视角”,能够知道进程的存活,当进程挂掉的时候可以将该进程持有的锁资源释放,但发展到分布式环境,这就变成了一个挑战,为了应对各种机器故障、宕机等,就需要给锁提供了一个新的特性:可用性。
如下图所示,任何提供三个特性的服务都可以提供分布式锁的能力,资源可以是文件、KV 等,通过创建文件、KV 等原子操作,通过创建成功的结果来表明所有权的归属,同时通过 TTL 或者会话来保证锁的可用性,通过超时释放,可以避免死锁。
2. 分布式锁的系统分类
根据锁资源本身的安全性,我们将分布式锁分为两个阵营:
-
基于异步复制的分布式系统,例如 mysql,tair,redis 等。
-
基于 paxos 协议的分布式一致性系统,例如 zookeeper,etcd,consul 等。
基于异步复制的分布式系统,存在数据丢失(丢锁)的风险,不够安全,往往通过 TTL 的机制承担细粒度的锁服务,该系统接入简单,适用于对时间很敏感,期望设置一个较短的有效期,执行短期任务,丢锁对业务影响相对可控的服务。
基于 paxos 协议的分布式系统,通过一致性协议保证数据的多副本,数据安全性高,往往通过租约(会话)的机制承担粗粒度的锁服务,该系统需要一定的门槛,适用于对安全性很敏感,希望长期持有锁,不期望发生丢锁现象的服务。
2.1 Redis 实现
Redis 客户端加锁也要根据Redis 部署情况来使用不同的加锁方式。
2.1.1 单机Redis的分布式锁
单机方式可根据lua脚本实现
思路大概是这样的:在redis中设置一个值表示加了锁,然后释放锁的时候就把这个key删除。具体代码是这样的:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET d_lock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这种方式有两大要点:
1)一定要用SET key value NX PXmilliseconds 命令
如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(key永久存在)。
2)value要具有唯一性
这个是为了在解锁的时候,需要验证value是和加锁的一致才删除key。
这是避免了一种情况:假设A获取了锁,过期时间30s,此时35s之后,锁已经自动释放了,A去释放锁,但是此时可能B获取了锁。A客户端就不能删除B的锁了。
如果采用单机部署模式,会存在单点问题,只要redis故障了。加锁就不行了。
2.1.2 集群分布式
redis 集群分布式集群方式有两种
- master-slave + sentinel选举模式
- redis cluster模式
集群使用redis锁的问题:
采用master-slave模式,如果设置锁之后,主机在传输到从机的时候挂掉了,从机还没有加锁信息,如何处理?即采用master-slave模式,加锁的时候只对一个节点加锁,即便通过sentinel做了高可用,但是如果master节点故障了,发生主从切换,此时就会有可能出现锁丢失的问题。
redis cluster 模式下,edis的作者提出可依据RedLock算法:
这个算法的意思大概是这样的:假设redis的部署模式是redis cluster,总共有6个master节点,通过以下步骤获取一把锁:
1.获取当前时间戳,单位是毫秒;
2.轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒;
3.尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2+1);
4.客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了;
5.要是锁建立失败了,那么就依次删除这个锁;
6.只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。
基于Redission的实现:
Javaer都知道Jedis,Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持。Redission也是Redis的客户端,相比于Jedis功能简单。Jedis简单使用阻塞的I/O和redis交互,Redission通过Netty支持非阻塞I/O。
Redission封装了锁的实现,其继承了java.util.concurrent.locks.Lock的接口,让我们像操作我们的本地Lock一样去操作Redission的Lock,下面介绍一下其如何实现分布式锁。
如果自己写代码来通过redis设置一个值,是通过下面这个命令设置的。
SET d_lock unique_value NX PX 30000
这里设置的超时时间是30s,假如我超过30s都还没有完成业务逻辑的情况下,key会过期,其他线程有可能会获取到锁。这样一来的话,第一个线程还没执行完业务逻辑,第二个线程进来了也会出现线程安全问题。所以我们还需要额外的去维护这个过期时间,太麻烦了~我们来看看redisson是怎么实现的:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.1.101:7001")
.addNodeAddress("redis://192.168.1.101:7002")
.addNodeAddress("redis://192.168.1.101:7003")
.addNodeAddress("redis://192.168.1.102:7001")
.addNodeAddress("redis://192.168.1.102:7002")
.addNodeAddress("redis://192.168.1.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("d_lock");
lock.lock();
lock.unlock();
我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
-
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
-
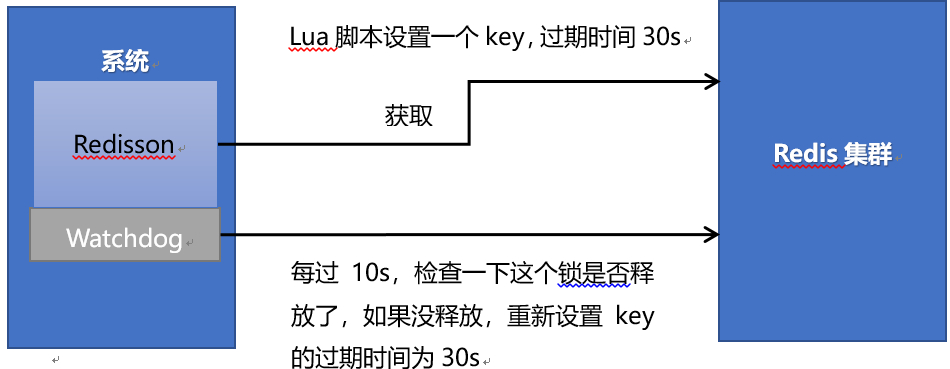
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s
这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
- redisson的“看门狗”逻辑保证了没有死锁发生
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
Redis小结
优点: 对于Redis实现简单,性能对比ZK和Mysql较好。如果不需要特别复杂的要求,那么自己就可以利用setNx进行实现,如果自己需要复杂的需求的话那么可以利用或者借鉴Redission。对于一些要求比较严格的场景来说的话可以使用RedLock。
缺点: 需要维护Redis集群,如果要实现RedLock那么需要维护更多的集群。
2.2 Zookeeper 实现
zk实现分布式锁的落地方案:
-
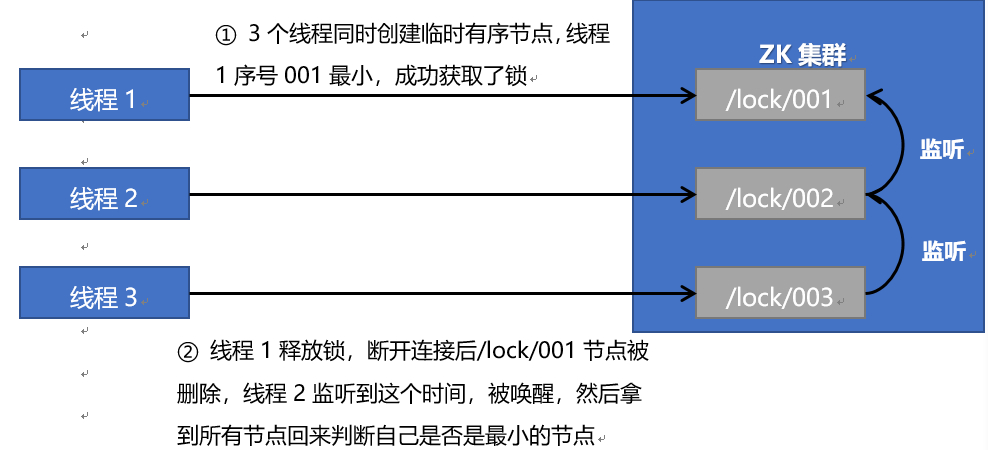
使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
-
创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
-
如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功
-
如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为:
[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:
Curator
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
他的使用方式也比较简单:
InterProcessMutex ipm = new InterProcessMutex(client,"/d_lock");
ipm.acquire();
ipm.release();
其实现分布式锁的核心源码如下:
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1);
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
……
}
}
2.3 基于数据库实现
2.3.1 基于数据库表的排它锁
锁信息存储表结构如下:
CREATE TABLE `t_ms_lock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名',
`desc` varchar(1024) NOT NULL DEFAULT '描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_name` (`name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
当我们想要锁住某个方法时,执行以下SQL:
insert into t_ms_lock(name,desc) values ('name','desc');
因为我们对name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:
delete from t_ms_lock where name ='name';
上面这种简单的实现有以下几个问题:
-
这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用;
- 对于数据库是单点可以搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上;但切换也是单点?
-
这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁;
- 对于没有失效时间,只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍;
-
这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作;
- 对于非阻塞:搞一个while循环,直到insert成功再返回成功;
-
这把锁是不可重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
- 对于非重入, 在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
2.3.2 基于数据库的排它锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
public boolean lock(){
connection.setAutoCommit(false)
while(true){
result = select * from t_ms_lock where name=xxx for update;
if(result==null){
return true;
}
}
return false;
}
在查询语句后面增加forupdate,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上)
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
public void unlock(){
connection.commit();
}
这里还可能存在另外一个问题,虽然我们对name 使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。
还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆。
2.3.3 基于数据库的乐观锁
大多数是基于数据版本(version)的记录机制实现的。何谓数据版本号?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个“version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
注意ABA 问题等。
3. 比较总结
对于redis的分布式锁而言,它有以下缺点:
它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮,即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题。但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”,所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
zookeeper天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
但是如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
我们介绍了几种分布式锁的实现方式,并进行了一些优缺点比较,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以需要根据不同的应用场景选择最适合的方式。
| 比较角度 | 结果 |
|---|---|
| 从理解的难易程度角度(从低到高) | 数据库 > 缓存 > Zookeeper |
| 从实现的复杂性角度(从低到高) | Zookeeper >= 缓存 > 数据库 |
| 从性能角度(从高到低) | 缓存 > Zookeeper >= 数据库 |
| 从可靠性角度(从高到低) | Zookeeper > 缓存 > 数据库 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号