Luffy Second Modular -- 常用模块
模块:
一个.py 文件我们就称之为一个模块,模块的主要作用就是提高代码的可维护性和可重用性,和命名冲突等
模块分类:
1.自带模块,又称为python标准库。可以使用help('modules')查看,打印的是当前全部的模块,包括自定义的和第三方的
2. 第三方模块,使用pop install 导入的
3. 自定义模块,自己写的py文件
模块的导入:
import xxx
from 【包名】import 【模块名】,【模块名】,。。。。
from 【包名】.【包】 import 【模块名】 as 【别名】
from 【包名】import * 导入所有的模块(不推荐有可能会造成变量名冲突,覆盖掉模块内的功能)
模块被导入,就相当于是执行了该模块.py文件中的代码
模块导入路径:
被导入的模块需要在指定的目录下才可以被导入成功,路径包含当前目录和python自定义目录。优先查找当前目录,如果当前目录中有就不再查找其他目录了。
可以使用 import sys sys.pathpython自定义的目录列表,因为这是一个列表所以是可以被操作的,可以添加一个目录,但是添加的目标只在当前程序的运行过程中有效,一旦当前程序运行结束这个被添加的目录也就失效了
模块的安装方法:
1. 人肉安装方法,到https://pypi.python.org/pypi 去下载对应的模块
完成后解压文件,cmd在当前目录打开,或者进入到当前目标,使用python setup.py build 编译
编译完成后使用 python setup.py install 就可以安装成功
可以使用pip uninstall 【模块名】来删除已安装模块
2. pip install 【模块名】 直接在线安装 会安装到site-packages 下
第三方库国内镜像源:
pip install -i http://pypi.python.com/simple 【模块名】--trusted-host pypi.douban.com
包及跨模块导入:
包:一个文件夹下管理多个模块文件,这个文件夹就被称为包
发生在同一目录级别下使用 from 【包名】import 【模块名】
绝对路径导入,os.path.abspath(__file__)获取当前文件的绝对路径,os.path.dirname()是当前目录的上一次,可以多层嵌套
常用模块:
time模块:
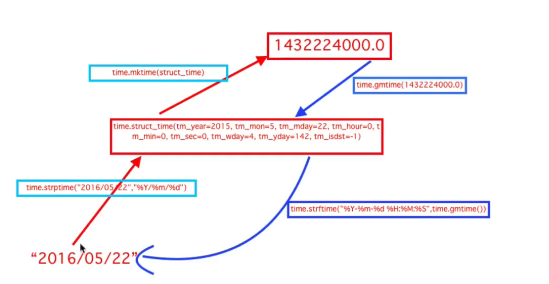
1. time.localtime();返回当前时区的时间 返回结果:time.struct_time(tm_year=2019, tm_mon=3, tm_mday=22, tm_hour=16, tm_min=11, tm_sec=24, tm_wday=4, tm_yday=81, tm_isdst=0),可以把返回值赋值给变量,通过变量取其中的任何值,例如 a = time.localtime() a.tm_year 返回2019
2. time.gmtime(): 返回英国时区的时间,其他同localtime
3. time.mktime():将时间戳反转回按秒的那种例如,time.mktime(a) 返回:1553242368.0
4. time.asctime(): 将时间对象转化为外国表示时间日期的格式 time.asctime(a) 返回:Fri Mar 22 16:12:48 2019
5. time.strftime("%Y/%m/%d %H:%M:%S"):将当前时间或者是指定时间转化为定义好的格式,‘2019/03/22 16:24:45'
5.1 %U 是返回时间是当年的多少周 %p 是显示上午还是下午AM,PM %y 是省略写年份2019 写成 19 time.strftime("%Y/%m/%d %H:%M:%S %U")
6. time.strptime(a,"%Y/%m/%d %H:%M:%S"):将一个时间对象或者是一个字符串按照你后面指定的格式反转为时间戳
6.1 s = time.strftime("%Y/%m/%d %H:%M:%S") time.strptime(s,"%Y/%m/%d %H:%M:%S") 返回:time.struct_time(tm_year=2019, tm_mon=3, tm_mday=22, tm_hour=16, tm_min=36, tm_sec=29, tm_wday=4, tm_yday=81, tm_isdst=-1)
转换关系图:
datetime模块:
1. help(datetime) 看一下把
random模块:
1. random.randint(1,100) 返回1-100之间的一个随机数,范围可变
2. random.random(), 返回一个随机的浮点数,不包含参数
3. random.choice('abcdefghjk'),返回字符串中的随机一个
4. random.sample('abcdefghjk',3) 返回指定个数的字符,返回一个列表,可以用来生存随机验证码
5. random.shuffle([1,2,3,4,5]) 返回一个无序的列表,也叫洗牌
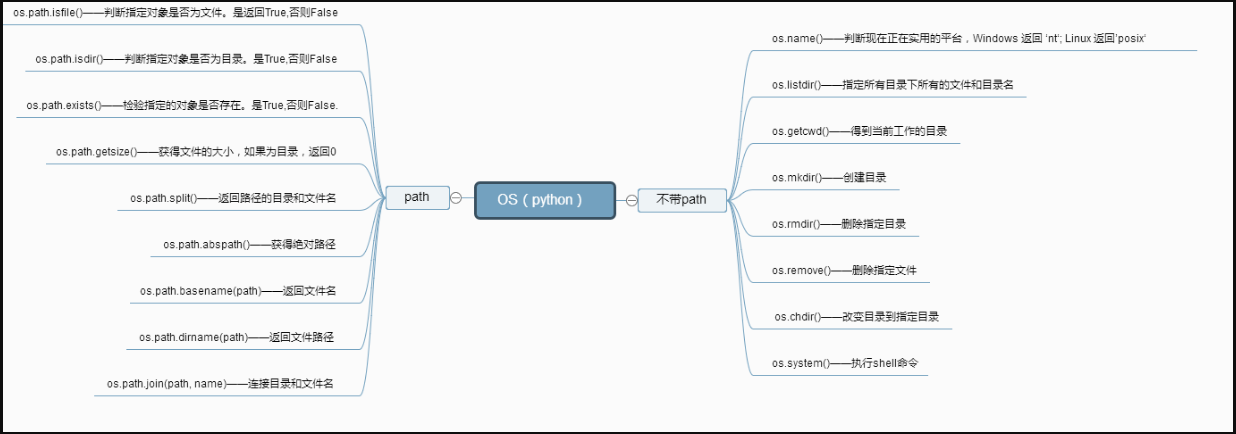
os模块(重点和系统进行交互):
1. os.getcwd() 获取当前脚本的工作目录,是python结束启动的目录,比如你在C盘启动就打印C盘,你在D盘启动就打印D盘
2. os.listdir() 返回当前目录中的所有文件,返回为一个列表
3. os.remove() 删除一个文件
4. os.removedirs(r"d:python") 可以删除文件夹
5. os.path.isfile() 判断是不是一个文件,返回True False
6. os.path.isdir() 判断是不是一个目录,返回True False
7. os.path.isabs() 判断是不是一个绝对路径
8. os.path.exists() 判断路径是不是存在,可以用来验证有没有这个文件
9. os.path.basename() 获取文件名
10. os.system() 运行shell命令
11. os.makedirs(r"d:\\python\test")创建多级目录
12. os.mkdir(r"d:\\python") 创建单个目录
13. os.path.getsize() 获取文件的大小
sys模块:
1. sys.exit("退出时输出的字符")
2. sys.maxsize 能支持的最大的int值
shutil模块:
1. shutil.copyfileobj(【文件对象1】,【文件对象2】) 将文件对象1中的内容拷贝到文件对象2中,前一个是r模式,后一个是w模式,可以加长度参数,长度参数是指定一次读多少数据,不是写入多少数据,一次读十个字节直到读完
2. shutil.copyfile(【文件名1】,【文件名2】) 不需要获取文件对象,直接给文件名就行
3. shutil.copytree(【被拷贝文件夹】,【新文件夹名】,【软链接要不要拷贝默认为False】,【忽略掉指定文件,ignore.ignore_patterns('__init__.py','views.py')】)
4. shutil.rmtree(【删除指定文件夹,全部,递归删除】,ignore_errors[,onerror]忽略错误,比如有的需要权限才能删除)
5. shutil.move(【被移动文件夹名】,【新文件夹名】)相当于剪切的操作,重命名
6. shutile.make_archive("压缩包名【当前文件夹】/路径【指定的路径下】",'zip', root_dir = '被压缩文件路径')
zipfile模块:
shutil中的压缩其实就是调用了zipfile来实现的
z = zipfile.ZipFile('压缩后包名' ,’w')
z.write('被压缩文件')
z.write('被压缩文件目录')如果要压缩目录的话,目录下的文件是不会被压缩的,只能压缩一个目录名
z.write('被压缩文件')
z.close() 关闭文件
解压文件:
z = zipfile.ZipFile("压缩包名",'r')
z.extractall() 解压到当前目录
z.close() 关闭文件
数据序列化:
数据序列化就是把内存数据转成字符串存储到硬盘上面,反序列化就是把硬盘数据重新读取到内存里,变成可执行代码
json模块:
json可以序列化的数据类型有限,只能序列化str,int, tuple, list, dict
1. json.dumps('字典/列表等数据类型') 仅将数据转化成字符串,并不写入文件 和 json.loads('字符串') 将字符串反序列化为可执行代码 一起使用的
作用:并没有把数据写入硬盘是因为,1. 把内存数据通过网络传输给其他人
2. json.dump('字典/列表等数据类型', 文件对象/文件句柄) 可以将数据转换为字符串并写入对应的文件中,文件得先打开并赋值给一个变量,形成文件对象, 和json.locad()配合使用
可以多次dump 但是不能locad多次,会出错
pickle模块:
pickle和json用法基本上一致,也是有dumps和loads dump和load 两个成对的方法,文件扩展名一般已kpl结尾
json可以序列化的数据类型有限,只能序列化str,int, tuple, list, dict , pickle可以支持python中所有的数据类型,但是只能在python中使用,不能跨语言使用
1. dumps是将文件转成字符,json是直接转成字符,pickle是将字符转成bytes字符串
shelve模块:
相对于json和pickle来说可以dump多次也可以load多次,数据结构类似于字典的key value结构,通过get取值,可以重新赋值和删除
xml模块:
相对用的比较少了,相对json来说比较浪费空间
import xml.etree.ElementTree as et
tree = ET.parse('【文件名】') 相当于打开文件 open()
root = tree.getroot() 获取文件的根目录
toot.tag 获取标签root的标签
a = root.iter("【标签名】") 获取指定标签名的标签
a.text获取指定标签下的文本
a.set("属性名",”属性值“) 添加指定的属性名和属性值
a.remove(【标签名】) 删除指定的标签
hashlib模块:
hash是在当前程序/脚本下值不会改变,退出重新进入的话就会不一样。转化后的数据不可逆,hash是152位
md5是值固定不变,md5是一种摘要算法,摘要出的数据是128位十六进制数。md5也是不可逆的,而且更改一位数据MD5的值都会发生巨大的变化,所以MD5常用于数字签名
import hashlib
m = hashlib.md5()
m.update(b'alex') 只能接受bytes字节
m.hexdigest() # 输出MD5值
subprocess模块:
用来和操作系统进行交互的模块,包含三个方法,run,call, popen
run: subprocess.run(['df', '-h'], stderr = subprocess.PIPE, stdout = subprocess.PIPE, check = True) 命令 ,错误信息, 标准输出,是否报错
subprocess.run('df -h|grep disk1', shell=True) 如果shell命令中使用了管道,那么就使用这样的写法执行shell命令
logging模块:
用来记录程序的运行状态,logging包含5个等级 debug(), info(), waring(), error(), critical()
logging.basicConfig(filename ="日志文件名.log 随意起可以不存在,会创建" ,level=logginf.INFO info已下的不记录,也就是debug不记录)
logging.basicConfig(filename="日志文件名.log 随意起,不存在会创建", level=logging.INFO 过滤等级,低于指定等级的不写入,format="%(asctime)s %(message)s" 日志的输出格式,asctime是时间,message是消息,format是日志的格式定义)
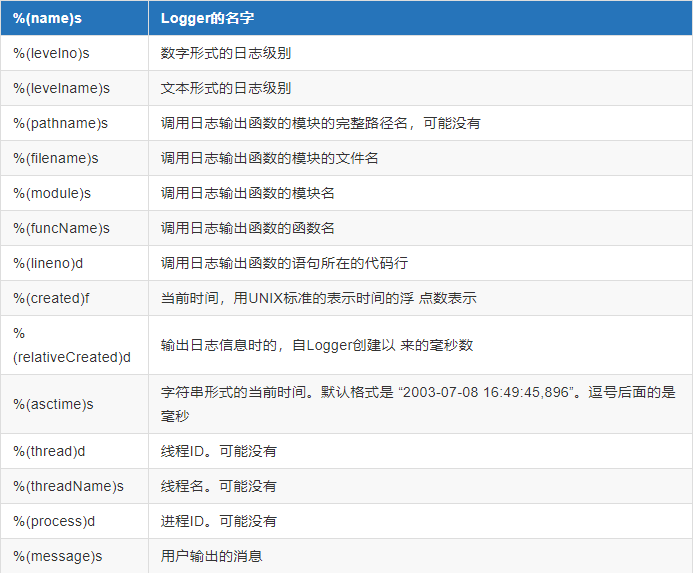
下面是format的全部格式:
logging模块进阶:
# -*- coding:utf-8 -*- # ------- 微雨 -------- import logging # 1. 生成logging对象 logger = logging.getLogger("web") logger.setLevel(logging.DEBUG) # 设置日志的默认级别,全局的 # 2. 生成handler对象 ch = logging.StreamHandler() # 生成屏幕handler对象 ch.setLevel(logging.DEBUG) # 设置输出的屏幕的日志级别 fh = logging.FileHandler('web_log.log') # 生成文件handler对象 fh.setLevel(logging.INFO) # 设置输出的屏幕的日志级别 # 2.1 把handler绑定到logging对象中 logger.addHandler(ch) # 把屏幕handler绑定到logger中 logger.addHandler(fh) # 把文件handler绑定到logger中 # 3. 生成formatter对象 ch_formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s %(message)s") # 生成屏幕formatter对象 fh_formatter = logging.Formatter("%(asctime)s %(name)s %(levelname)s %(lineno)d %(message)s") # 生成文件formatter对象 # 3.1 把formatter对象绑定到handler对象中 ch.setFormatter(ch_formatter) # 把formatter绑定到handler对象中 fh.setFormatter(fh_formatter) # 把formatter绑定到handler对象中 logger.debug('test log debug') # 没有设置级别的时候默认的最低级别是warning,所以debug是不会输出的,也不会被写入 logger.error('test log error') # 没有设置级别的情况下error比warnin要高,所以会输出也会写入 logger.info('test log info') # 设置了日志级别之后才会输出info # 在不同的地方设置日志的级别,最高的是按照全局的日志级别来确定的,如果全局的设置成debug就全部能输出,如果全局的不进行设置的话,那么还是按照全局的默认值来确定,全局的默认值是warning

 浙公网安备 33010602011771号
浙公网安备 33010602011771号