Luffy Second Modular -- 函数
函数的定义:
函数是指将一组语句的集合通过一个名字给封装起来,想要执行这一组语句的时候,直接调用函数名就可以了。
函数的特点:
1. 减少代码的重复率,可在做相同的事情的时候多次调用函数。
2. 使程序变得可扩展,
3. 使程序变得易于维护,如果要修改功能的话只需要修改函数就可以了,在每一次调用函数的地方就都修改了
函数参数:
形参:
个人理解,形参就是一个占位符,并不代表实际的数据,且只能在函数的内部去使用,使用完立刻就释放掉
实参:
是在内存中实际存在的数值,可以在函数内使用,也可以在函数外使用
位置参数:
给函数传递参数的时候需要按照形参的排列顺序给参数传递实参。形参按顺序接受实参
默认参数:
函数的形参可以有默认值,但是有默认值的参数要放在位置参数的后面,不然位置参数按顺序接受参数的时候会乱
关键字参数:
给函数传递参数的时候可以按照形参的名字去传递,这样的话就不用按照位置去传递了。但是关键字参传递的时候要放在位置参数的后面,不然也会乱
非固定参数1 (*args):
非固定参数,顾名思义就是不确定个数的参数,一个形参可以接收一个或多个实参,非固定参数必须得放在位置参数后面,同上。保存为一个元组,如果需要传递一个字典或者是元组,需要在字典或者元组的前面加上*号,如果不加的话传递的实参列表会被作为形参元组的一个元素。
非固定参数2(**kwarge):
前面是接受多个参数,封装称为一个元组,**kwargs的话接收的是未定义的关键字参数,也就是在形参里面没有定义的参数,可以用name=’alex‘的形式传递给**kwargs。接受的参数会封装称为一个字典类型,key就是参数名,val就是变量值,如果要传递一个字典需要加上**
函数的返回值:
return,函数执行到return后就表示一个函数的结束,下面再有代码就不会被执行了。
函数的返回值只能是一个值,要过要返回多个值可以用逗号分割,但是return会把多个值封装为一个字典再返回
函数的返回值可以是任意值
函数的局部变量:
局部变量就是定义在函数内部的变量,函数内部可以使用,不能在函数的外部使用。如何函数内部的变量和函数外部的变量重名的话,那么函数内部的变量和函数外部的变量是两个独立的变量。
函数的内部可以调用全局变量,但是函数外部却不能调用函数的内部变量。
如果想在函数内部修改全局变量,就需要在函数内部声明该变量是全局变量,global,就是告诉函数这个变量是一个全局变量
函数内部是可以对列表,字典等数据类型进行修改的,列表的形态是一个内存地址里面包含多个内存地址,外部的内存地址是不可以被修改的,但是内部的内层地址是可以在函数内部被修改的。
函数的嵌套:
函数的嵌套,函数嵌套的函数使用变量的遵循的规则是一层一层的找,内部的先找上一层的,上一层找不到再找上上层的。
还有就是那个先执行那个先改变,先调用外层函数,外层函数改变了变量的值,再执行内层函数,那么内层函数如果使用的也是全局变量,那么变量的值已经被改变了
函数的作用域:
一个函数就是一个作用域,当函数定义完成的时候,作用域就已经生成了,嵌套函数其实就是作用域互相嵌套,作用域内的变量,查找规则是自内向外的查找。
当函数被调用的时候,不管是在哪里被调用的,都会回到最初定义它的那个作用域里面去执行。
匿名函数:
匿名函数使用lambda 定义,定义完成后只是一个函数空间,并不能被调用,得先给lambda指定一个变量才能被调用,调用方法是一样的加上括号调用,匿名函数一般都是和其他的方法搭配使用,使用完就释放,没有必要去定义它
def func(x,y):
return x * y
lambda x,y : x*y
匿名函支持的最复杂的运算是三元运算 :
lambda x ,y :x *y if x >y else x / y
同:
def func(x , y):
if x > y:
return x * y
else:
return x / y
匿名函数和map方法的组合应用:
1 # 将一个列表内的元素自乘一遍再返回 2 data = list(range(10)) 3 for index ,i in enumerate(data): 4 data[index] = i * i 5 print(data) 6 7 # 第二种:使用map方法 8 def f1(n): 9 return n * n 10 print(list(map(f1,data))) 11 12 # 第三种使用map + lambda 13 print(list(map(lambda n: n * n, data))) # map方法是接收一个函数和一个可迭代对象,将可迭代对象的元素,挨个传递给前面的函数去处理
高阶函数:
一个函数接收另一个函数作为参数,那么这个函数就被称为是高阶函数,函数的返回值是一个函数也被称为是高阶函数。
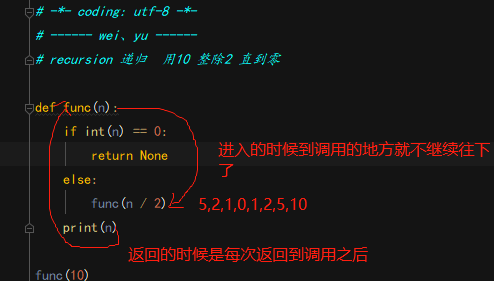
函数的递归调用:
人理解迭代,神理解递归。递归是一层一层的进去,再一层一层的出来,必须要有结束条件,否则就和死循环一下。 见下文
个人理解的递归和栈就是每递归一次就在栈里面放一次数据,然后每退出一次就把栈里面的数据拿出来一个,遵循着先进后出的原则
例如:
递归进去: 1, 2, 3, 4, 5 出来就是: 5, 4, 3, 2, 1 先进后出,后进先出,和枪的弹夹类似,最先放进去的子弹最后被打出。
例如对用10除2 直到0
函数的内置方法:
all() :
被判断的对象如果是可迭代类型,那么可迭代类型中全部的值都必须为True,否则就返回False,但是如果可迭代类型本身是空的,那么all会返回Ture这个是需要主要的
any():
和上面的相反,如果这个参数中的元素中有一个是True就是True,全是False的时候才是False
dir():
打印当前程序中的所有变量(待补充)
hex():
将一个数转化为16进制数
slice():
定义一个切片的规则,例如 s = slice(1,3,2) 起始,结束,步长,a = [1,2,3,4,5],a[s] 的结果就是[2]
divmod(x,y):
求参数的整除和余数
eval():
将字符串转为可执行代码,只能转换一行。
ord(),chr():
ord("a") 97 返回参数在ascII表中的数字位,chr(97) a 返回参数在Ascii中的字符
sum():
例如传入一个列表,列表中全部是数字,可以计算列表中元素的加和
fileter()
和map类似,是取出满足条件的值,list(fileter(lambda(x : x >2 [1, 2, 3, 4, 5])) 返回[3, 4,5]
functools.reduce():
和map,fileter 类似 functools.reduce(lambda x ,y : x *y / x + y [1,2,3,4,5,6]))可以进行加啊乘啊的操作
pow():
求参数的多少次幂
bytes():
返回参数的bytes类型
float():
返回参数的浮点数类型
print():
print(valuse, sep="分隔符", end="默认是换行,可以改成其他的" ,file = "文件路径,需要先打开文件,传入文件句柄")
callable():
判断参数是否可以被调用,可以加括号的是可以被调用的,例如一个函数,返回True/False
vars():
和dir(),类似,dir是打印变量名,vars是打印变量名加上变量对应的值
locals():
一般在函数内使用,打印函数的局部变量,所有的局部变量
global():
打印全局变量
zip():
可以将两个列表的值一一对应,如果两个列表长度一致那就全部对应,长度不一致多出的就丢弃掉。对应起来后是一个列表内包含一个一个的元组
round():
round(1.232323,2) 保留参数的几位小数,1.23 返回
hash():
可以将字符串编译成为数字,可以对数字进行排序,排序完成后再去查找对应字符串的值,可以实现二分查找类似的查找算法
函数的命名空间:
命名空间又称为名称空间(name space)等,是存放变量名的空间,是存储变量名和变量值对应关系的空间,x = 1 那么名称空间内存储的就是 x 和 1 的内存地址的对应关系 类似 x : 1的内存地址,的key/value形式
locals:输出函数内名称空间内所有的变量名和对应关系,打印当前空间内的全部变量对应关系,例如在函数内就打印函数的,在程序内就打印程序的
globals: 打印当前程序/脚本的名称空间内的全部变量和对应关系
builtins: 内置模块的名称空间,程序一运行就有的模块和变量名就是放在这个里面的 使用dir(__butilins__)打印
一个变量的作用域是在名称空间内的,超出名称空间的范围就不能被访问了,例如函数内的变量作用域就在函数内,是因为他的名称空间的范围就是这个函数,超出范围就访问不到了。作用域是因为有了名称空间才有作用域,一个变量的作用域就是这个变量的名称空间
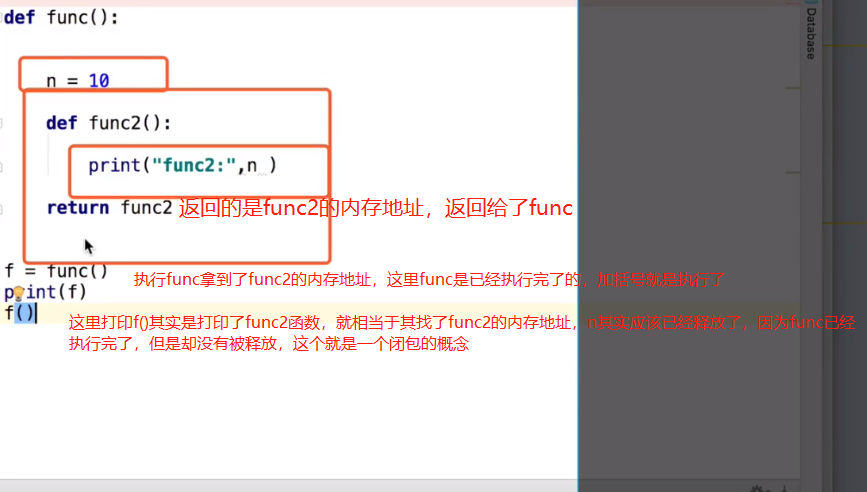
函数的闭包(概念):
闭包其实就是函数之间互相的嵌套,然后内存函数使用了外层函数的变量,而且在外层函数执行的时候又返回了内存函数的内存地址,那么外层的变量是不会被释放的,因为内层函数还是在使用中,这种就是一个闭包的概念
装饰器(重点):
# 现在需要对欧美专区和河南专区加入认证功能 # 认证模块: user_status = False def login(func): def inner(): _username = 'alex' _password = 'alex123' global user_status if user_status == False: username = input('username:>>>') password = input('user pasowrd:>>>') if username == _username and password == _password: print('welcom login......') user_status = True else: print('wrong username or password!') else: print("用户已登陆,验证通过") if user_status: func() # 执行形参 return inner """ 加入认证模块,对要VIP权限的板块进行身份认证,是VIP就让用,不是就不让 """ def home(): print("------- 首页 -------") def america(): print("------- 欧美专区 -------") #@login # 等价于japan = login(japan) def japan(): print("------- 日韩专区 -------") #@login # 语法糖(装饰器) def henan(): print("------- 河南专区 -------") henan = login(henan) # 不加括号就是不执行,就是把函数的内存地址给传到login中了,到login中给形参加上括号再执行,把login的内存地址再次赋值给一个变量,那这边变量就相当于是login函数,再加上括号就是调用login函数 america = login(america) # 和上面一样先把内存地址传进去,到里面执行形参
""" 执行的顺序是先右后左 hanan = login(hanan) 把函数henan的地址传递给了login函数, login函数中的inner其实一开始并没有被执行,loing接收了函数henan的地址之后就返回了,返回的就是inner的内存地址 并把inner的地址再次的赋值给了变量henan,这个变量指向的就是inner的内存地址 把henan变量加上()去执行,就相当于是执行了inner """
"""
加参数的装饰器:
流程同上一样,要给原来的函数加上参数,且参数是不固定的,有的有参数,有的没有,有的还有多个,那么就要用到*args和**kwargs非固定参数来实现
我执行新的变量的时候其实执行的是inner函数,那么参数就要加给inner函数,inner中执行的是func形参,其实形参就是老的函数,也就是henan或者japan,形参就需要传递给func
"""
user_status = False
def login(func):
def inner(*args,**kwargs):
_username = 'alex'
_password = 'alex123'
global user_status
if user_status == False:
username = input('username:>>>')
password = input('user pasowrd:>>>')
if username == _username and password == _password:
print('welcom login......')
user_status = True
else:
print('wrong username or password!')
else:
print("用户已登陆,验证通过")
if user_status:
func(*args,**kwargs) # 执行形参
return inner
henan() # 这里其实是认证函数返回的内存地址,加上括号进行调用,但是名字还是一样的,用户调用名字还是原来那个,中间其实已经经过一次认证了 japan() 2019-03-17
列表生成式:
列表生成式顾名思义就是用来生成列表,元组等数据类型的快速办法a = [i if i<5 else i*i for i in range(10)] 其中for i in range(10)这个就是列表生成式, i if i<5 else 这个是三元表达式,意思是如果i<5就等于i 否则就把i * i
生成器:
1. 不可以回退
2. 需要一个拿一个,内存中保存的是公式,并不是实际的数据
3. 达到最大值后再继续就报错
a = (i for i in range(5)) 要用小括号包起来,不能使用中括号,使用中括号就是列表生成式了。生成公式后使用next(a) 来调用
使用循环调用生成器终止后不会报错,使用for不会报错,使用while会报错
函数生成器: # 只要函数中含有yield就表示该函数为生成器,且函数内return不会返回值
def range2(n):
count = 0:
while count < n:
yield count # 暂停函数,并向外返回变量的值
count += 1
a = range(10)
next(a) or a.__next__() 同效 # 达到最大值后会报错
for i in a: # 达到最大值不会报错
print(i)
总结:next()是唤醒生成器并给外部返回一个值,send() 是唤醒生成器并给生成器传递一个值,该值可以在生成器内部被接收到,传递的值是传递到yield的位置(也有可能next就是调用了a.send(None),未考证)
函数迭代器:
可以被next()函数调用并不断返回下一个值的对象就是迭代器:iterator
注意列表、字典等是可迭代对象,并不是迭代器,但是可以使用iter将列表字典等变成迭代器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号