正则表达式入门01
导读:
正则表达式归根结底就是一个表达式而已,只不过这个表达式的书写千变万化,学习正则表达式很大程度上就是学习正则表达式的语法规则,让人无比头痛。在学习正则表达式之前建议稳住自己的心态,多看看前辈们对它的描述讲解,让自己对其有一定的认知,然后最好准备好一个练习工具以及相关的正则表达式说明文档来辅助学习,我使用的是Regex Match Tracer工具(好不容易找到的免费的工具),工具的工作环境是这样的:
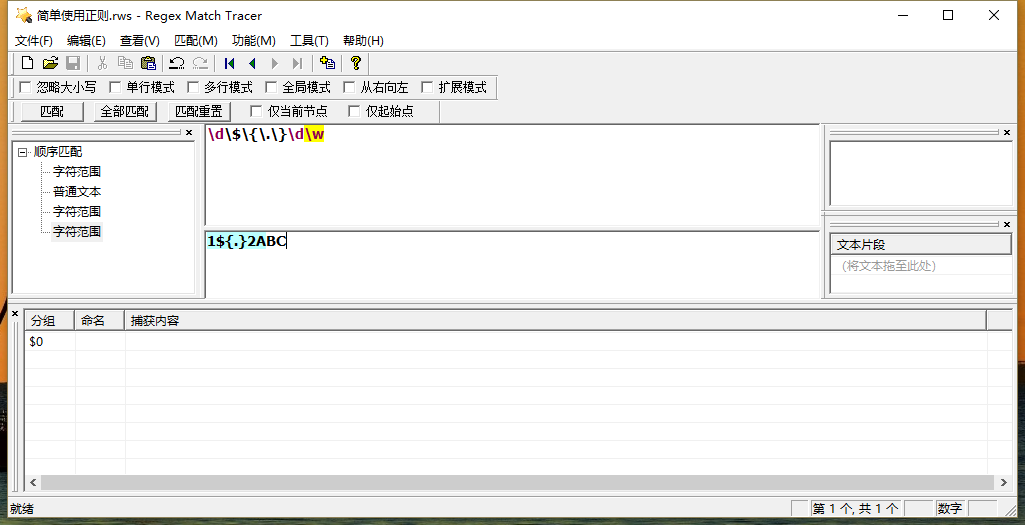
很明显可以看出来上面工具的构造,上面输入内容为正则表达式,下面输入内容为要进行匹配的数据内容,虽简陋但是对于新手入门来说还是够用了。
附上工具下载链接:http://www.regexlab.com/zh/mtracer/download.htm
在线正则表达式解析工具:https://regexper.com/
ps:相信有了它们就算开始学走路也不会摔得太惨,加油吧。
定义:描述了一个规则,通过这个规则可以匹配一类字符串。
优势:一种强大灵活的文本处理"工具",大部分编程语言,数据库,文本编辑器,开发环境都支持正则表达式。
使用流程:
1.分析所要匹配的数据,写出测试用的典型数据。
2.在工具软件中进行匹配测试。
3.在程序中调用通过测试的正则表达式。
接下来开始认识正则表达式里面包含的元素。。。
普通字符:
字母,下划线,数字,汉字以及没有特殊定义的标点符号都是普通字符,在匹配一个字符串的时候匹配与之相同的一个字符。

简单的转义字符:
\n:代表换行符
\t:制表符
\\:代表\本身
\?,\+,\-,\*,\$,\],\[,\{,\},\(,\),\.:匹配这些字符本身
标准字符集合:能够与多种字符匹配,区分大小写,大写是相反的意思
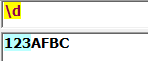
\d:匹配任意一个0-9数字:
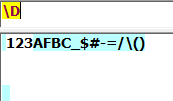
\w:匹配任意一个字母或数字或下划线,也就是A-Z,0-9,_,a-z中任意一个:
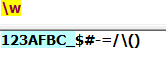
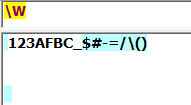
\s:包括空格,制表符,换行等空白字符的其中任意一个:
小数点可以匹配任意一个字符,如果要匹配包括换行\n在内的所有字符,可以使用[\s\S]
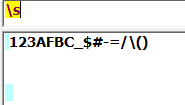
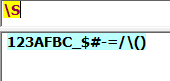

自定义字符集合:[]方括号匹配模式,能够匹配方括号中任意一个字符
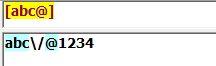
[abc@]:匹配"a","b","c","@"之中任意字符:
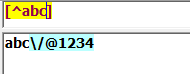
[^abc]:匹配"a","b","c"之外的任意一个字符:
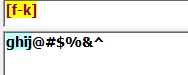
[f-k]:匹配"f"-"k"之间任意一个字母:
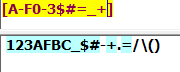
[^A-F0-3]:匹配除"A"-"F"以及0-3之外的任意一个字符:

正则表达式的特殊符号如果被包含在[]中则会失去特殊意义,除了^和-两个符号。
标准字符集合,除小数点以外如果被包含在[]中,自定义字符集合将包含该集合。

量词:修饰匹配次数的特殊符号
{m}:表达式重复m次:
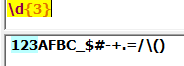
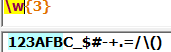
{m,n}:表达式最少重复m次,最多重复n次:
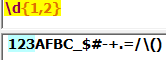
{m,}:表达式最少重复m次:
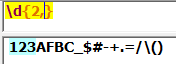
?:匹配表达式0次或1次,相当于{0,1}:
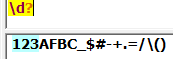
+:匹配表达式至少出现一次相当于{1,}:
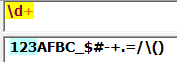
*:匹配表达式不出现或出现任意次,相当于{0,}:
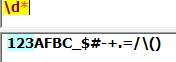
贪婪模式:
匹配字符越多越好,默认为贪婪模式!
非贪婪模式:
匹配字符越少越好,修饰匹配次数的特殊符号后再加上一个?号。

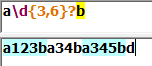
字符边界(零宽):该标记匹配的不是字符而是位置,符合某种条件的位置
^:与字符串开始的地方匹配:

$:与字符串结束的地方匹配:
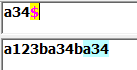
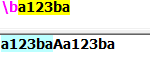
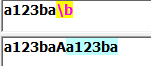
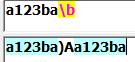
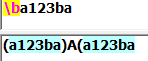
\b:匹配一个单词边界(前面的字符和后面的字符不全是\w):
匹配模式:
1.忽略大小写模式:匹配时忽略大小写,而默认情况下是区分大小写的。
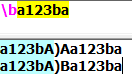
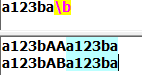
2.单行模式:整个文本看做一个字符串,只有一个开头,一个结尾。使小数点"."可以匹配包含换行符\n在内的任意字符。

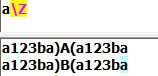
3.多行模式:每行都是一个字符串,都有开头和结尾。使用该模式后,如果需要仅匹配字符串开始和结束位置。可以使用\A和\Z。

选择符和分组:
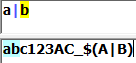
|(分支结构):左右两边表达式为"或"的关系,匹配左边或是右边:

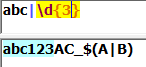
()(捕获组):在被修饰匹配次数时括号内的表达式可以作为整体被修饰,取匹配结果时括号中的表达式匹配到的内容可以被单独得到,每一对括号会分配一个编号,使用()的捕获根据左括号的顺序从1开始自动编号。捕获元素为0的第一个捕获是由整个正则表达式模式匹配的文本:
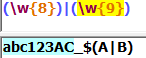

(?:Exception)(非捕获组):一些表达式中不得不使用(),但又不需要保存()中子表达式匹配的内容,这时可以用非捕获组来抵消使用()带来的副作用:


反向引用:(\nnn)
1.每一对()会分配一个编号,使用()的捕获根据左括号的顺序从1开始自动编号。
2.通过反向引用,可以对分组已捕获的字符串来进行引用。
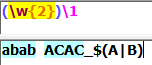
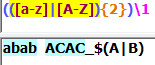
预搜索(零宽断言):
1.只进行子表达式的匹配,匹配内容不计入最终的匹配结果,是零宽度。
2.这个位置应该符合某个条件,判断当前位置的前后字符,是否符合指定的条件,但不匹配前后的字符,是对位置的匹配。
3.正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。占有字符还是零宽度,是针对匹配的内容是否保存到最终的匹配结果中而言的。
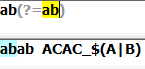
(?=Exp):断言自身出现的位置的后面能匹配表达式Exp:

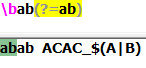
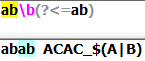
(?<=Exp):断言自身出现的位置的前面能够匹配表达式Exp:

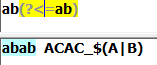
(?!Exp):断言自身出现的位置的后面不能匹配表达式EXP:
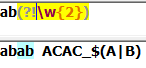

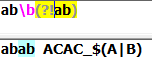
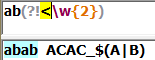
(?<!Exp):断言自身出现的位置的前面不能匹配表达式Exp:
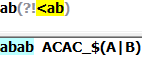
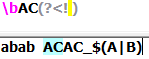
练习:
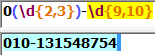
1.匹配座机电话号码 :以"0"开头,中间包含"-"符号
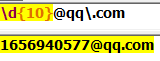
2.匹配邮箱账号:中间包含@符号
(1)qq邮箱:
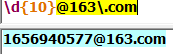
(2)网易邮箱:
(3)移动邮箱:
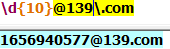
3.匹配移动电信手机号码,以13,,15,18开头的为移动号,17开头的为电信号
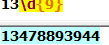
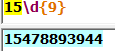
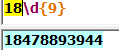
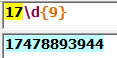
显然这样写可能会出现问题,就是当电话号码的形式发生改变时需要重新定义正则表达式,所以效率较为低下。因此阔以采用更高效的方法来实现这样的操作。
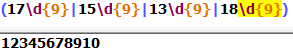
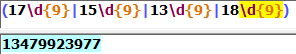



这样写一下子就阔以匹配各种形式的电话号码,简单高效,易用性良好。
ps:文章待完善,后续内容会继续跟进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号