深度之眼(二十)——Python:Pandas库
文章目录
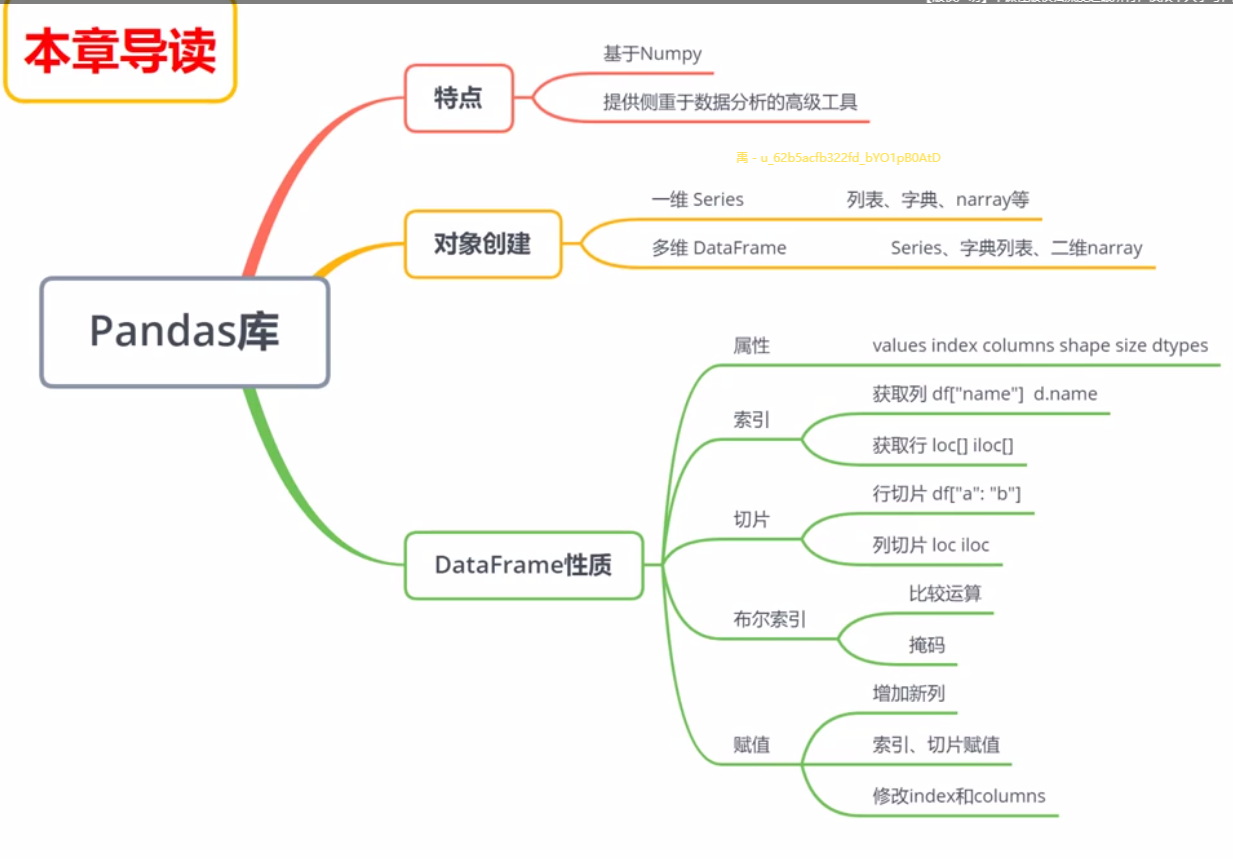
零、导读
零、引子
Numpy在向量化的数值计算中表现优异
但是在处理更灵活、复杂的数据任务:
如为数据添加标签、处理缺失值、分组和透视表等方面
Numpy显得力不从心
而基于Numpy构建的Pandas库,提供了使得数据分析变得更快更简单的高级数据结构和操作工具
一、对象的创建
1.1 一维数组(Series)
通用结构

import pandas as pd
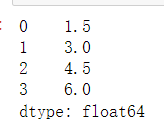
data = pd.Series([1.5,3,4.5,6])
data
data = pd.Series([5,6,7,8],index=["a","b","c","d"],dtype = "float")
data
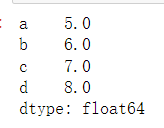
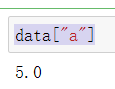
data["a"]
2、用一维numpy数组创建
import numpy as np
x = np.arange(5)
pd.Series(x)

3.用字典创建
.默认以键为index值为data
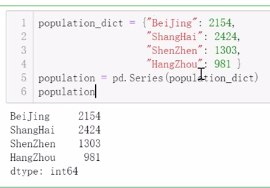
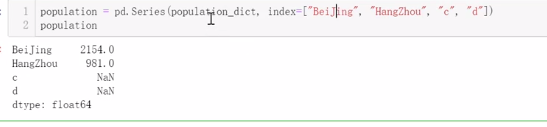
●字典创建,如果指定index,则会到字典的键中筛选,找不到的,值设为NaN
4、data为标量的情况
pd.Series(5,[100,200,300])

1.2 多维数组
DataFrame是带标签数据的多维数组
DataFrame对象的创建
通用结构pd .DataFrame(data, index=index, columns=columns)
data:数据,可以是列表,字典或Numpy数组
index:索引,为可选参数
columns:列标签,为可选参数
p_d = {
"a":1,
"b":5,
"c":7,
"d":6
}
p = pd.Series(p_d)
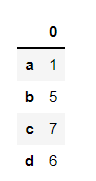
pd.DataFrame(p)
2.通过Series对象字典创建
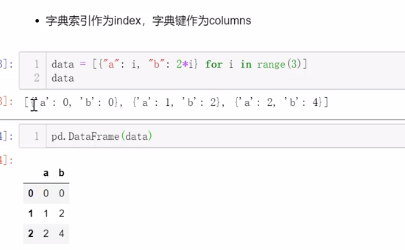
3.通过宇典列表对象创建
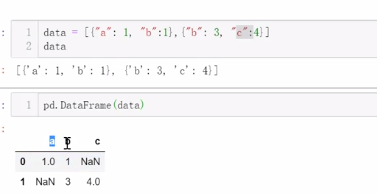
●不存在的键,会默认值为NaN
4、通过Numpy二维数组创建
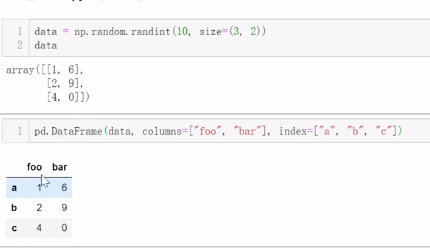
二、DataFrame性质
2.1 属性
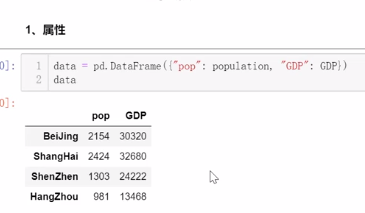
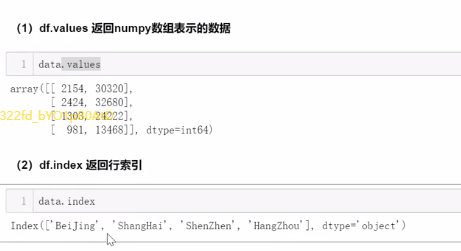
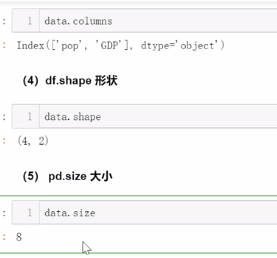
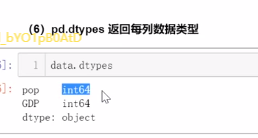
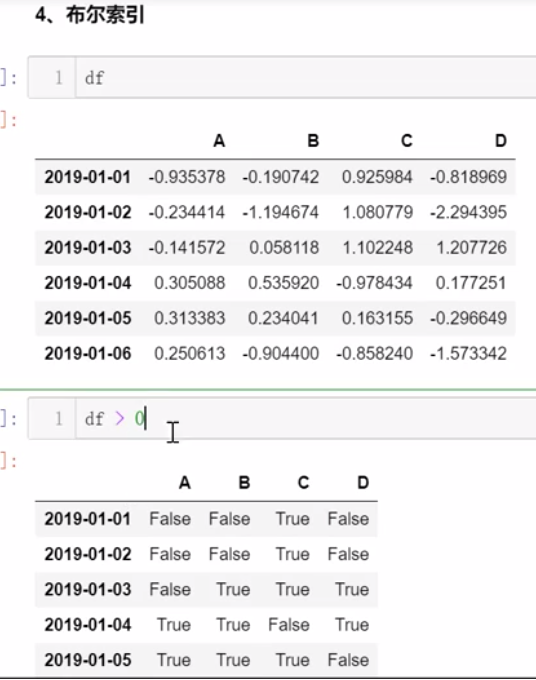
2.2 索引
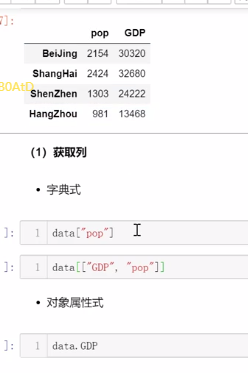
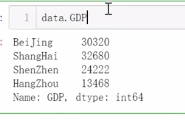
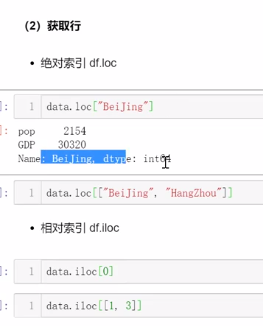
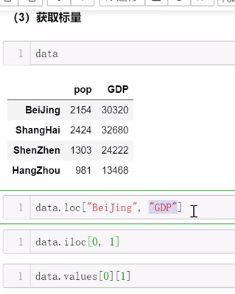

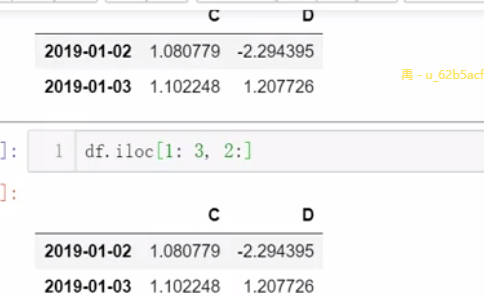
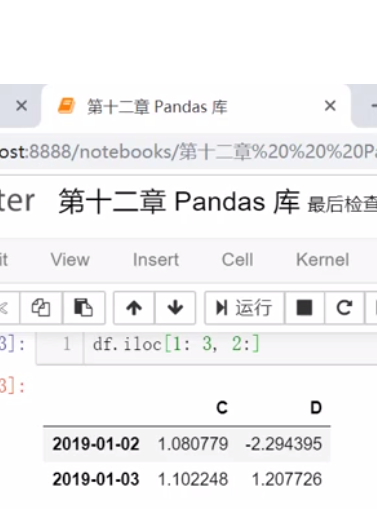
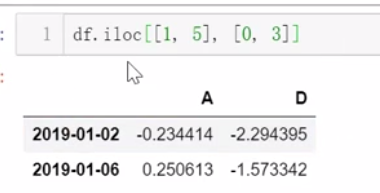
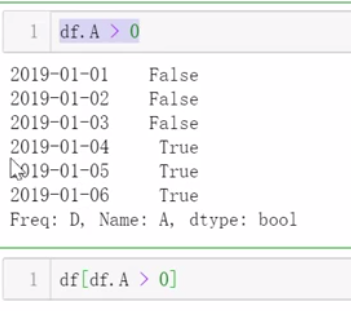
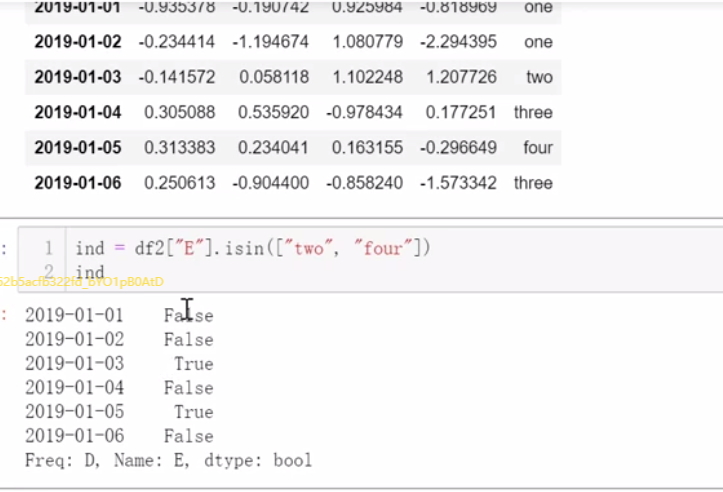
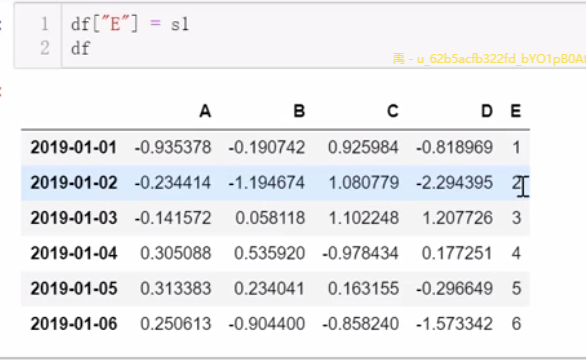
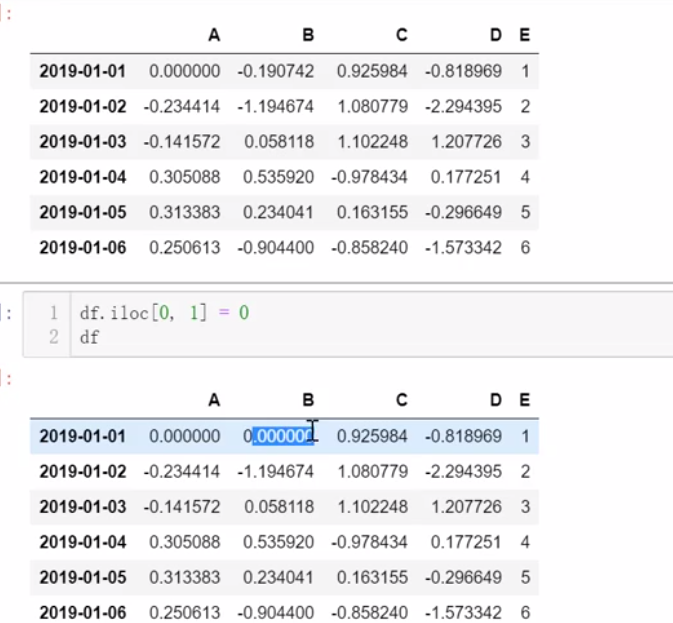
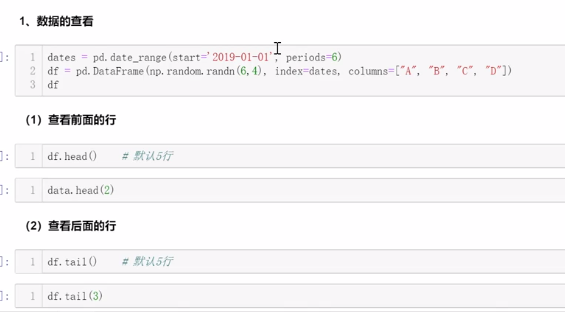
3、切片
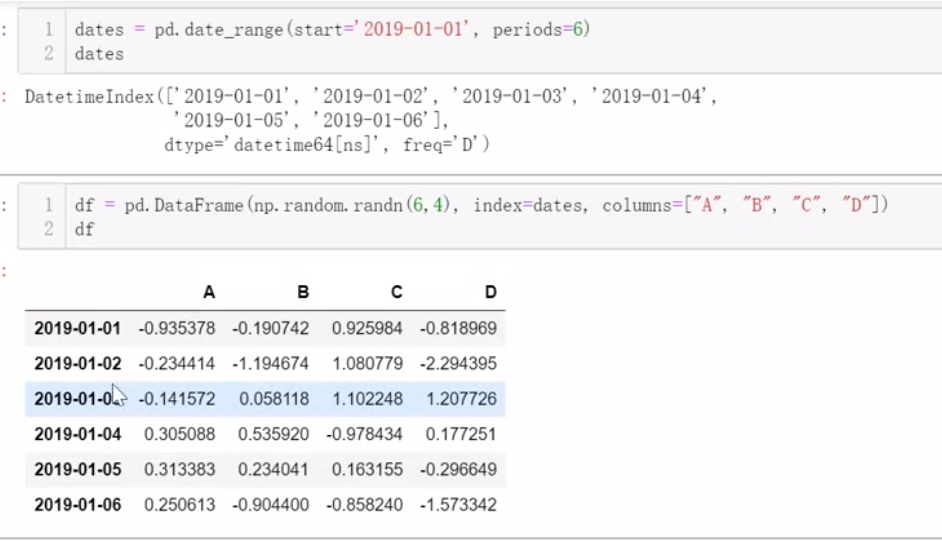
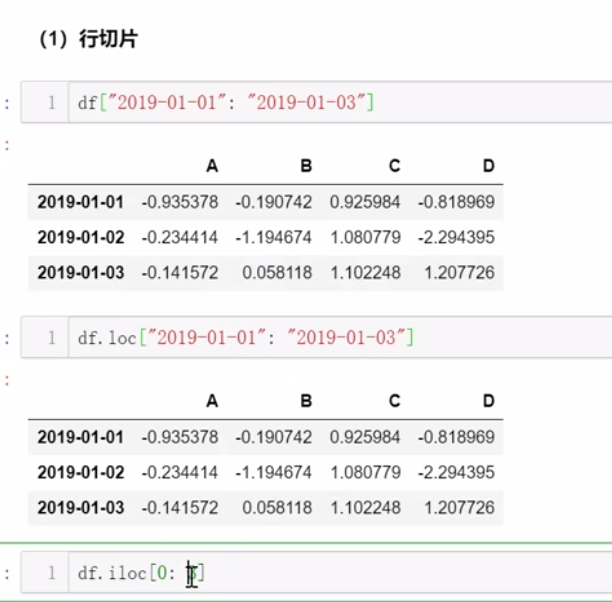
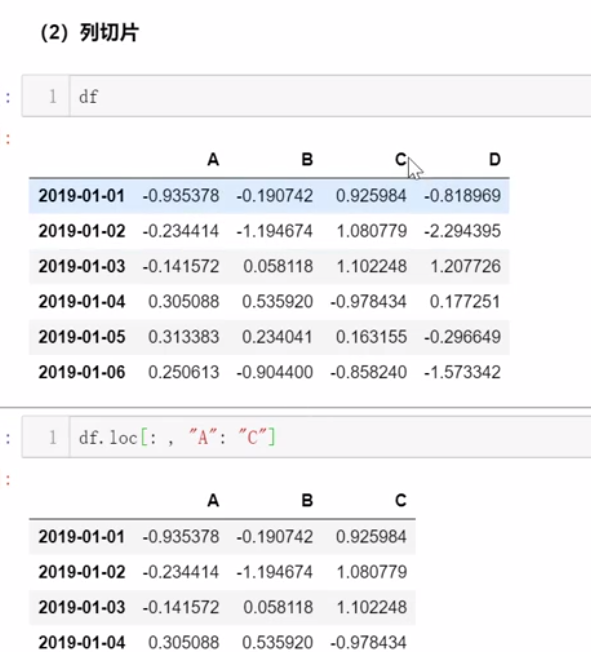
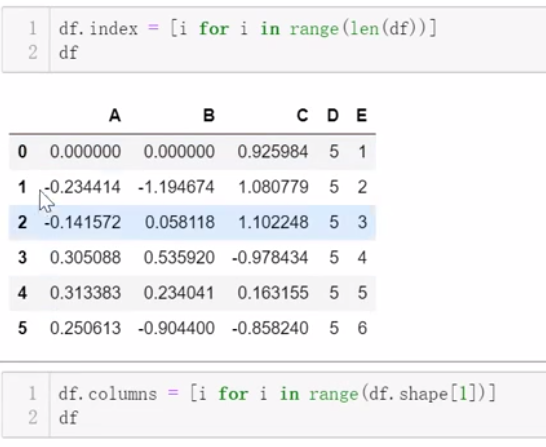
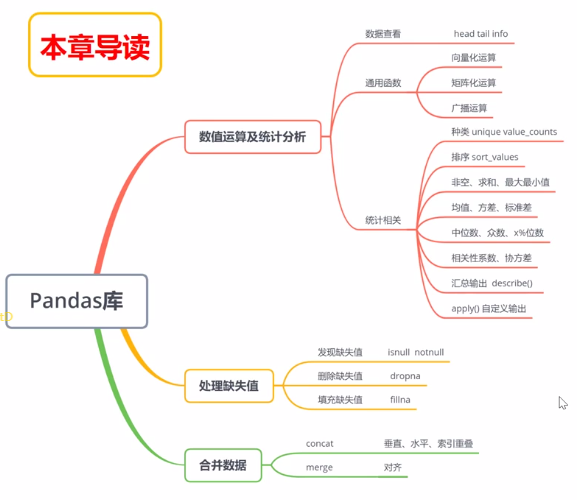
三、数值运算及统计分析
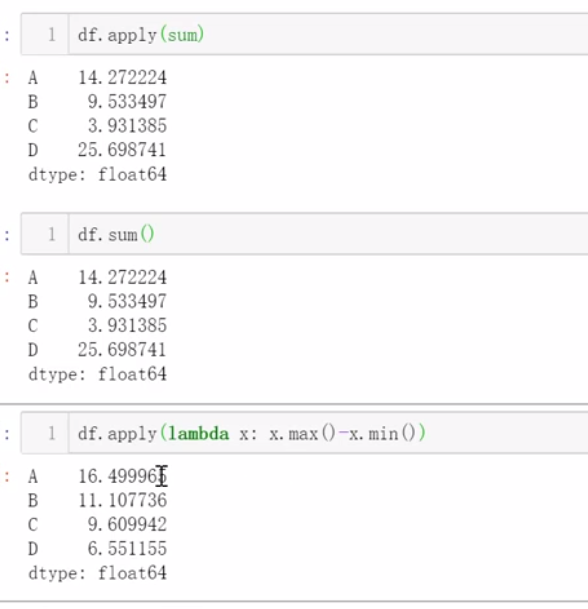
2、Numpy通 用函数同样适用于Pandas
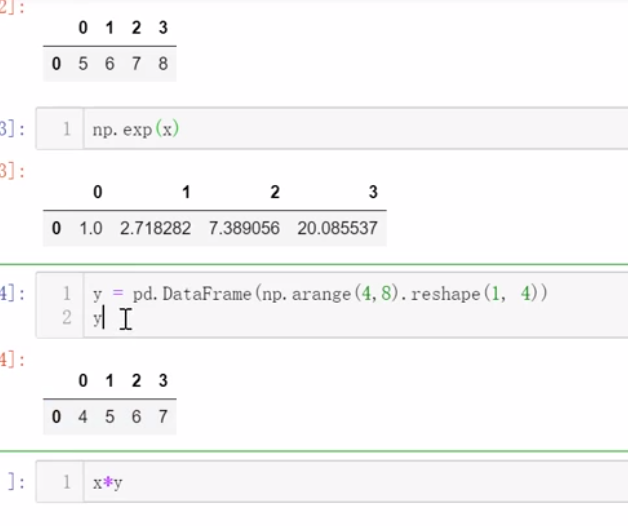
一般来说,纯粹的计算在Numpy里执行的更快
Numpy更侧重于计算,Pandas更侧重于数据处理
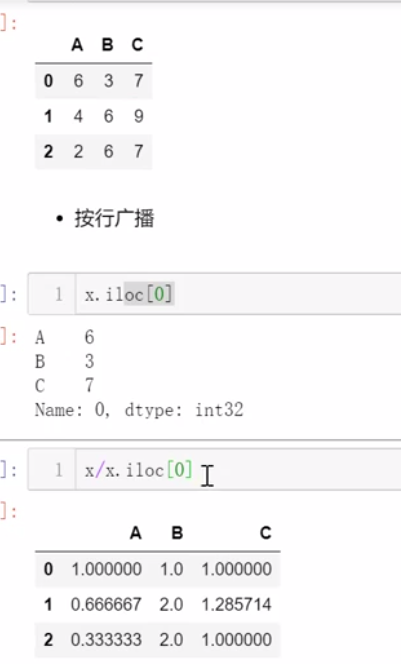
(广播)
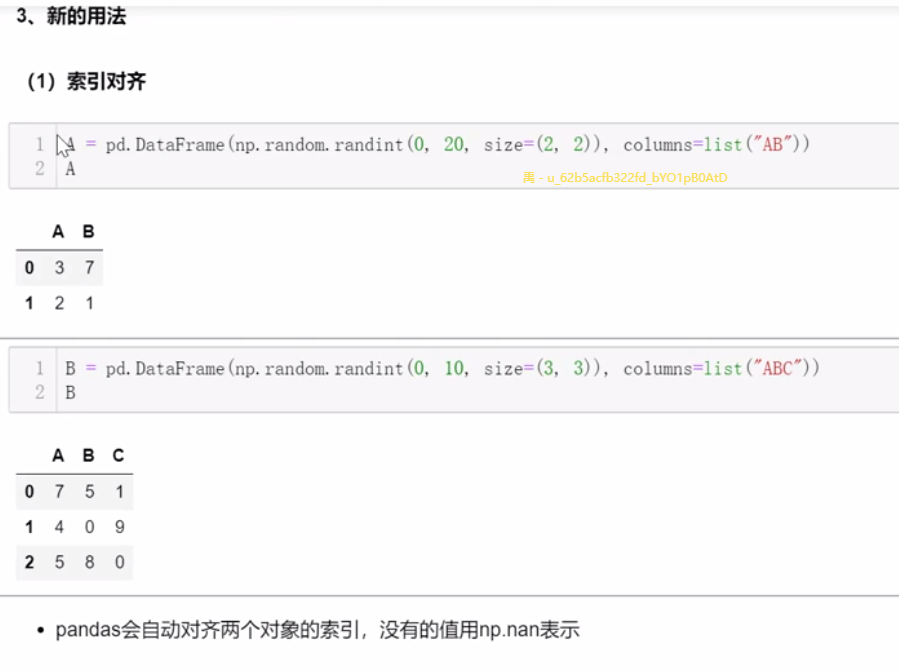
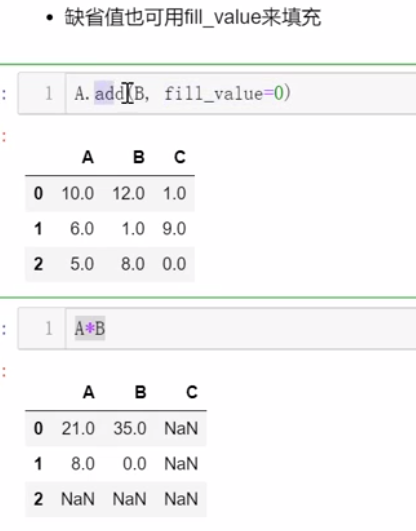
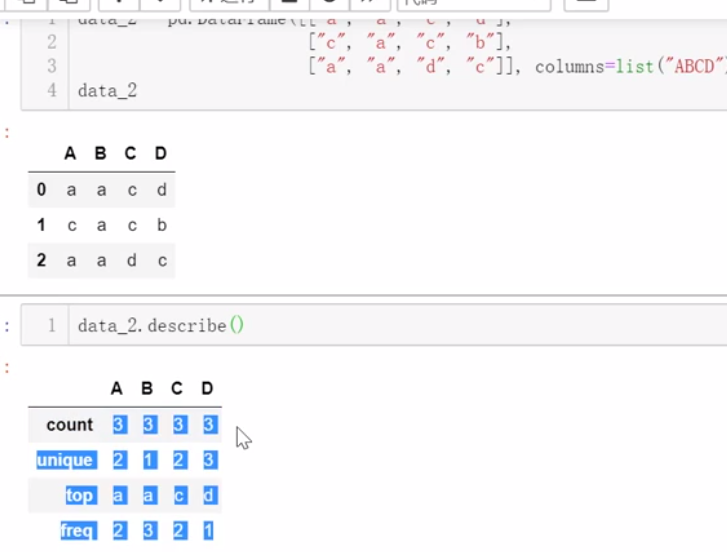
(2)统计相关
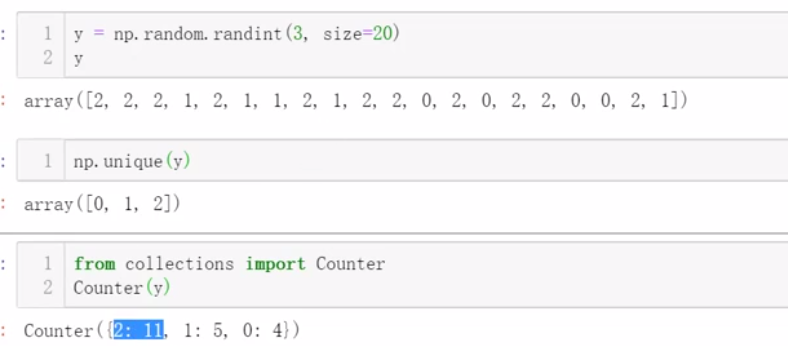
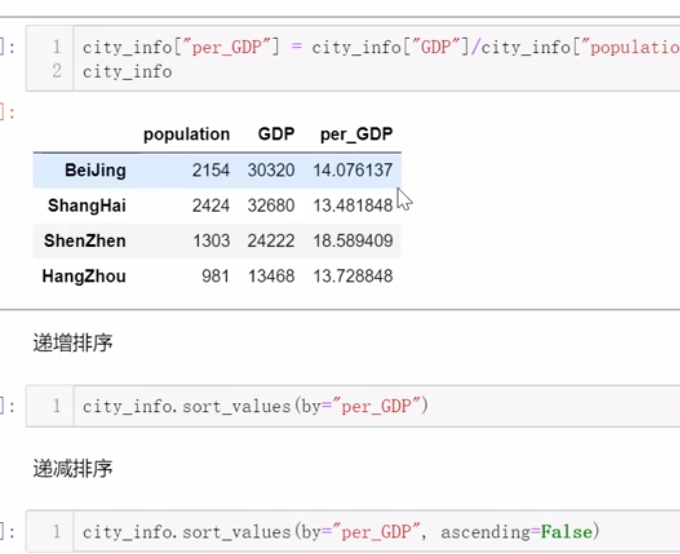
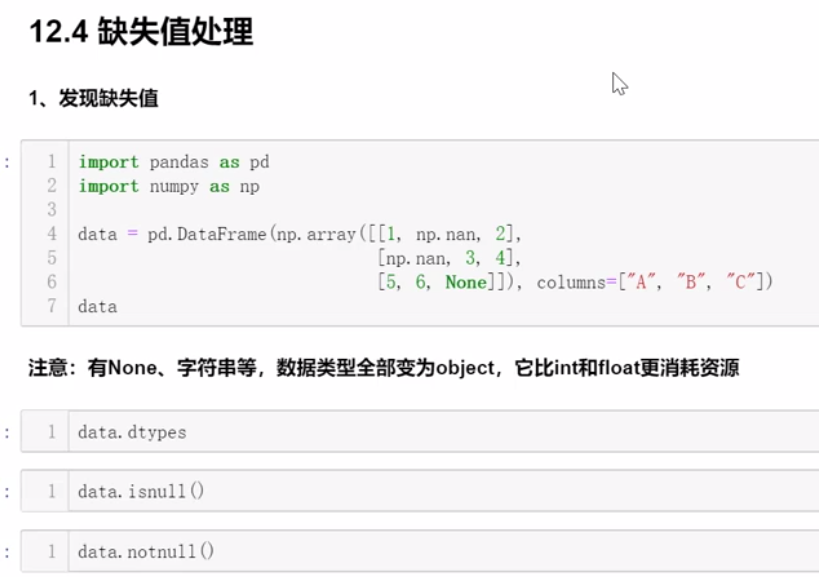
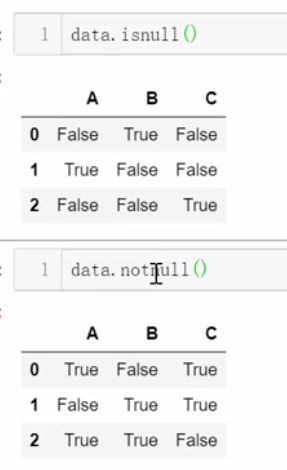
四、缺失值处理
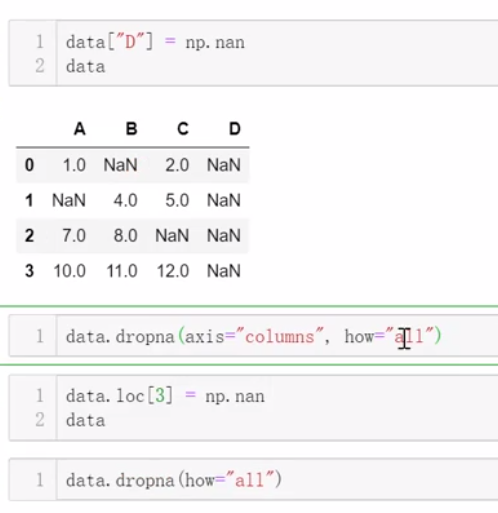
3、填充缺失值

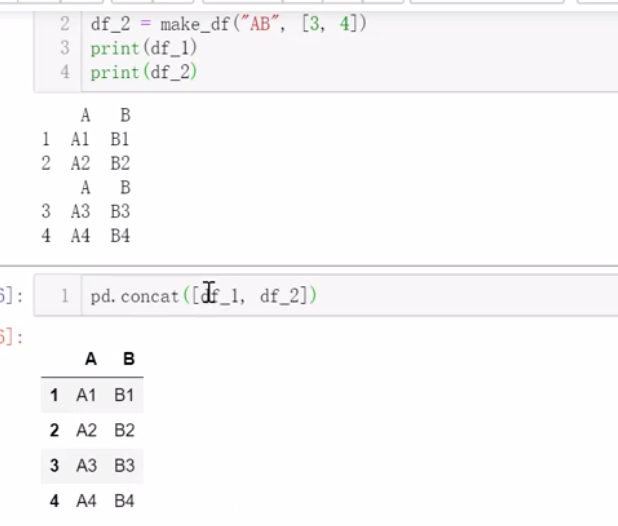
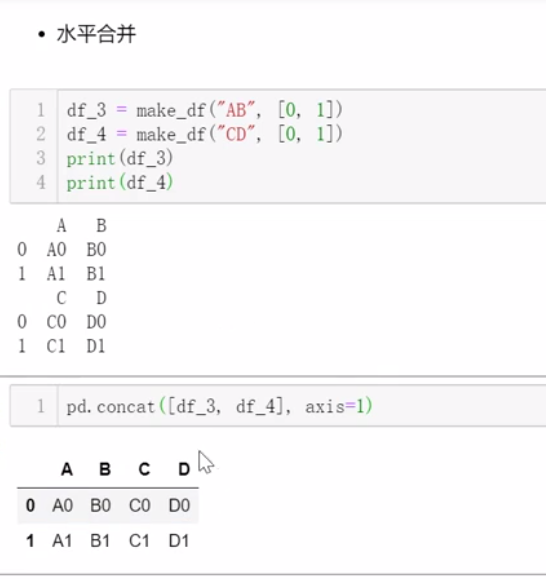
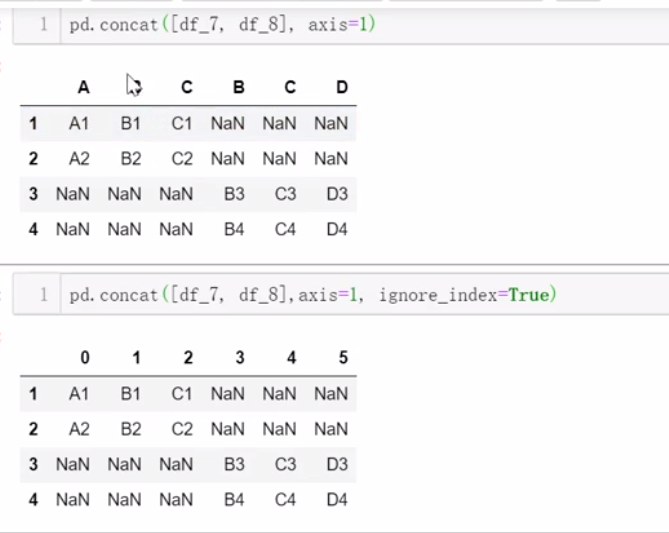
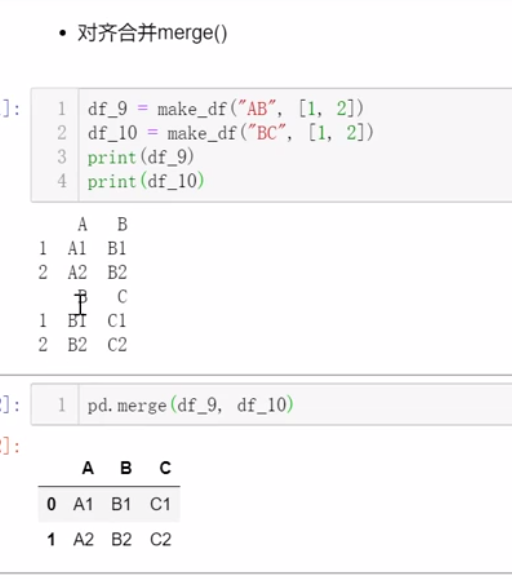
五、合并数据
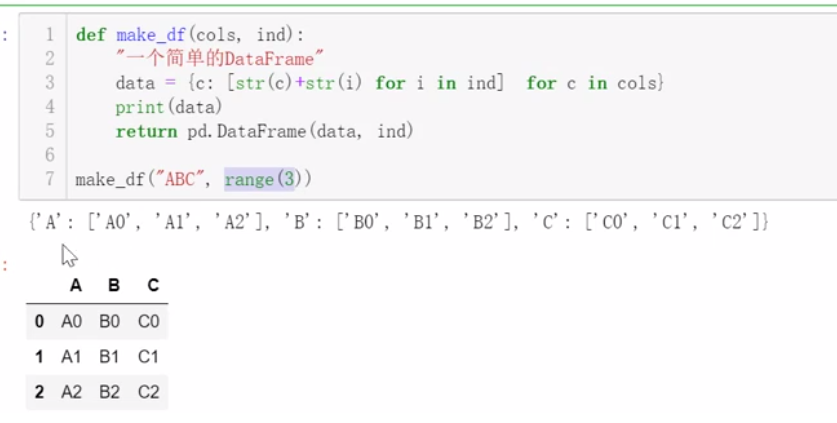
垂直合并
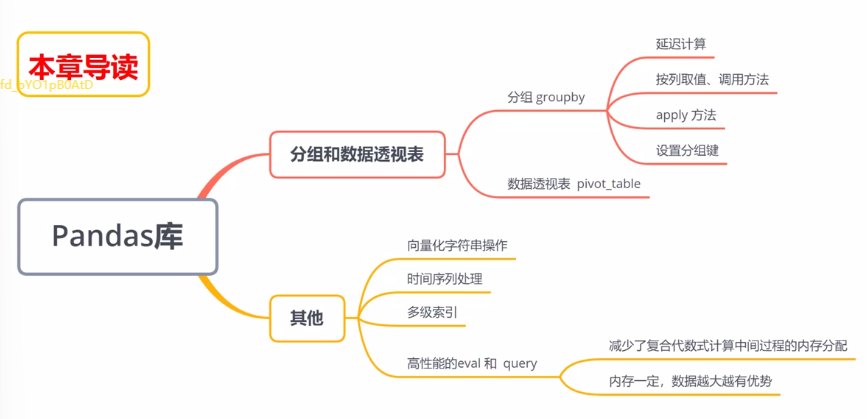
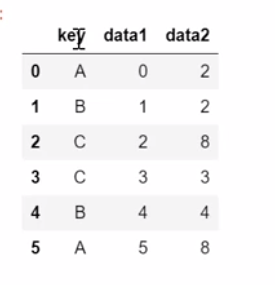
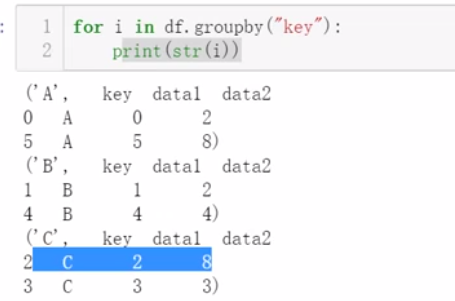
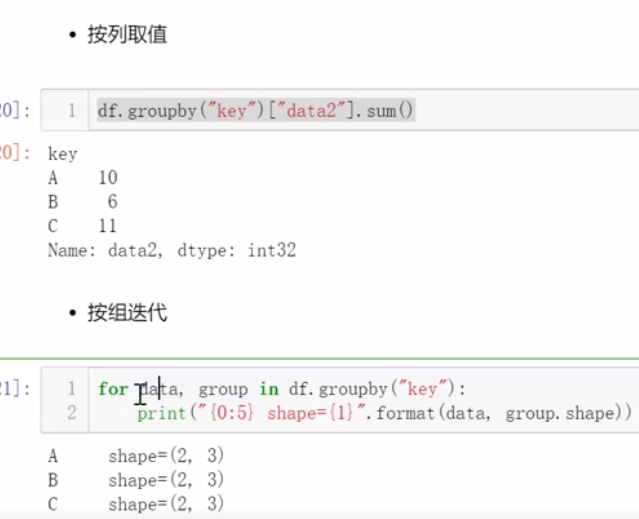
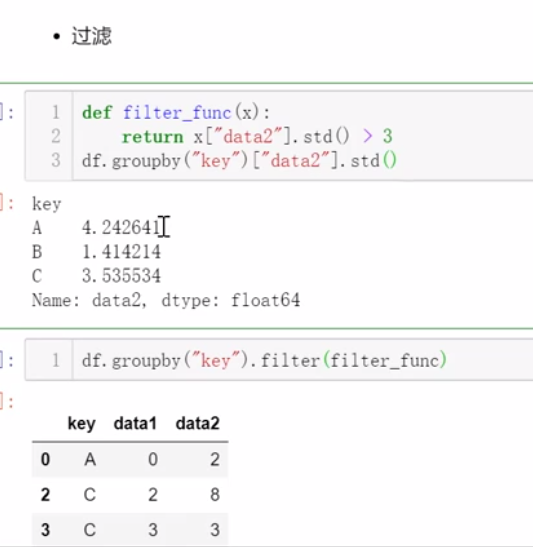
六、分组和数据透视表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号