JAVA解析XML与C#解析XML(DOM,SAS,JDOM,DOM4J)
-
[1、XML解析总览]
本章导航-----XML解析思维导图
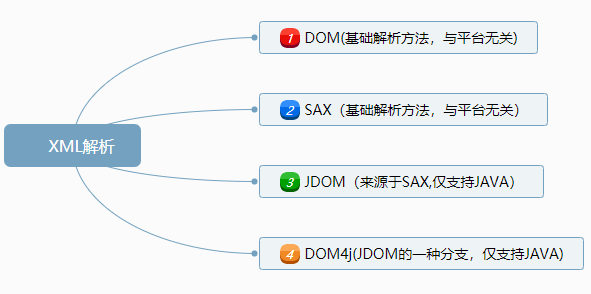
XML的解析方式分为四种:1、DOM解析;2、SAX解析;3、JDOM解析;4、DOM4J解析。其中前两种属于基础方法,是官方提供的平台无关的解析方式;后两种属于扩展方法,它们是在基础的方法上扩展出来的,只适用于java平台。a:DOM解析---采用dom解析,会将xml文档全部载入到内存中,然后将xml文档中的所有内容转换为tree上的节点(对象);
优点:可以随机解析访问文档中的数据、可以修改文件、可以创建xml文件;
缺点:适合解析小文件,对内存要求高b:SAX解析---基于事件处理的机制;sax解析xml文件时,遇到开始标签,结束标签,开始解析文件,文件解析结束,字符内容,空白字符等都会触发各自的方法;
优点:适合解析大文件,对内存要求不高;轻量级的解析数据方式,效率更高
缺点:不能随机解析;不能修改XML文件,只能进行查询;编码比较麻烦,很难同时访问XML文件中的多处不同数据;c:JDOM解析---JDOM 直接为JAVA编程服务。它利用更为强有力的JAVA语言的诸多特性(方法重载、集合概念以及映射),把SAX和DOM的功能有效地结合起来,简化了DOM读取操作的过程,简化了输出DOM树的操作。
特点:Jdom同时具有DOM修改文件的优点和SAX读取快速的优点;仅使用具体类,而不使用接口;API大量使用了Collections类。d:DOM4J解析---DOM4J解析xml文件比DOM和SAX还有JDOM都要更强大.但是DOM4J并不是Java官方提供的操作接口,要使用DOM4J可以到官网中下载DOM4J.jar包,将jar包导入到项目中即可使用.
特点:DOM4j解析的好处在与简化了,xml文档数据的增删改查和xml文档的输出操作,方便了开发人员的操作,便于理解. -
[2、XML有什么作用]
本章导航-----XML的重要性
[XML出现的地方]XML不是一种可执行的程序,它只是一种数据的载体,不过由于这种数据载体的格式简单易懂,加上良好的扩充性能,使得XML的用处十分广泛。从框架的各种配置文件到Ajax中的数据交换,再到Web Service的推行、SOA理念的应用等等,都离不开XML。
[XML的作用]
第一: 数据传输需要一定的格式(数据的可读性;将来的扩展;将来的维护)
第二: 配置文件,之前使用的.properties资源文件中描述的信息不丰富
第三: 保存数据,充当小型的数据库,保存数据一般是使用数据库保存,或者使用一般的文件保存,这个时候也可以选择XML文件,因为XML可以描述复杂的数据关系。从普通文件中读取数据的速度肯定是比从数据库中读取数据的速度快,只不过这样不是很安全而已. -
[3、C#的DOM解析XML]
本章导航-----C#的DOM解析

[涉及到C#中具体的类及方法]在System.XML命名空间中有以下几个用于XML的类:
a:XMLTextReader—提供以快速、单向、无缓冲的方式存取XML数据。(单向意味着你只能从前往后读取XML文件,而不能逆向读取)b:XMLValiddatingReader—与XMLTextReader类一起使用,提供验证DTD、XDR和XSD构架的能力。
c:XMLDocument—遵循W3C文档对象模型规范的一级和二级标准,实现XML数据随机的、有缓存的存取。一级水平包含了DOM的最基本的部分,而二级水平增加多种改进,包括增加了对名称空间和级连状图表(CSS)的支持。
d:XMLTextWriter—生成遵循W3C XML1.0规范的XML文件。
no_1:XmlDocument:加载xml文档.eg:XmlDocument document = new XmlDocument();document.load(@"D:\C#\books.xml");
no_2:XmlElement:用于返回一个元素实例.e.g:XmlElement element = document.DocumentElement; //常用来返回一个根节点
XmlElement类包含许多方法和属性,可以处理树的节点和属性
1)FirstChild:返回根元素节点后的第一个子节点
2)LastChild:返回根元素节点后的最后一个子节点
3)ParentNode:返回当前元素的父节点
4)NextSibling:返回当前节点的父节点下的下一个节点
5)HasChildNodes:用来检查当前元素是否有子元素
no_3:XmlText:表示开关标记之间的文本,是特殊的节点,属性有:1)InnerText:获取当前节点范围内的所有子节点的文本连接起来的字符串
2)InnerXml:获取当前节点范围内的所有子节点的文本连接起来的字符串,包含标记
no_4:XML修改解析(1)创建节点
创建节点方法:
1)CreateElement:用来创建XmlDocument类型的节点
2)CreateAttribute:用来创建XmlAttribute类型的节点
3)CreateTextNode:用来创建XmlTextNode类型的节点
4)CreateNode:用来创建任意类型的节点,包含上述三种以及其他(2)创建节点后添加操作:
1)AppendChild:把创建的节点类型追加到XmlNode类型或其他派生类型的节点后
2)InsertAfter:将新节点插入到特定的位置
3)InsertBefore:将新节点插入到特定位置(3)删除节点
1)RemoveChild:删除当前节点范围内的一个指定的子节点
2)RemoveAll:删除该节点范围内的所有子节点(4)修改节点
1)ReplaceChild:用新子节点替换旧子节点
no_5:XML查询解析(1)使用XmlDocument 方法
XmlDocument document = new XmlDocument();
document.Load(filePath);
XmlNodeList list = document.GetElementsByTagName("book");
foreach (XmlNode node in list)
{
listBox1.Items.Add(node.Name);//listBox1类型是ListBox
}
(2)使用XPath选择特定的节点的方法
1)SelectSingleNode:用来选择一个节点,如果有多个,则返回第一个节点
2)SelectNodes:返回一个节点的集合,类型是XmlNodesList;选择特定的节点的方法参数XPath;XPath是XML文档的查询语言
具体参考Microsoft C#API
[代码示例]using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Xml;namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
try
{
//xml文件存储路径
string myXMLFilePath = "C:\MyComputers.xml";
//生成xml文件
GenerateXMLFile(myXMLFilePath);
//遍历xml文件的信息
GetXMLInformation(myXMLFilePath);
//修改xml文件的信息
ModifyXmlInformation(myXMLFilePath);
//向xml文件添加节点信息
AddXmlInformation(myXMLFilePath);
//删除指定节点信息
DeleteXmlInformation(myXMLFilePath);
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}private static void GenerateXMLFile(string xmlFilePath)
{
try
{
//初始化一个xml实例
XmlDocument myXmlDoc = new XmlDocument();
//创建xml的根节点
XmlElement rootElement = myXmlDoc.CreateElement("Computers");
//将根节点加入到xml文件中(AppendChild)
myXmlDoc.AppendChild(rootElement);//初始化第一层的第一个子节点
XmlElement firstLevelElement1 = myXmlDoc.CreateElement("Computer");
//填充第一层的第一个子节点的属性值(SetAttribute)
firstLevelElement1.SetAttribute("ID", "11111111");
firstLevelElement1.SetAttribute("Description", "Made in China");
//将第一层的第一个子节点加入到根节点下
rootElement.AppendChild(firstLevelElement1);
//初始化第二层的第一个子节点
XmlElement secondLevelElement11 = myXmlDoc.CreateElement("name");
//填充第二层的第一个子节点的值(InnerText)
secondLevelElement11.InnerText = "Lenovo";
firstLevelElement1.AppendChild(secondLevelElement11);
XmlElement secondLevelElement12 = myXmlDoc.CreateElement("price");
secondLevelElement12.InnerText = "5000";
firstLevelElement1.AppendChild(secondLevelElement12);XmlElement firstLevelElement2 = myXmlDoc.CreateElement("Computer");
firstLevelElement2.SetAttribute("ID", "2222222");
firstLevelElement2.SetAttribute("Description", "Made in USA");
rootElement.AppendChild(firstLevelElement2);
XmlElement secondLevelElement21 = myXmlDoc.CreateElement("name");
secondLevelElement21.InnerText = "IBM";
firstLevelElement2.AppendChild(secondLevelElement21);
XmlElement secondLevelElement22 = myXmlDoc.CreateElement("price");
secondLevelElement22.InnerText = "10000";
firstLevelElement2.AppendChild(secondLevelElement22);//将xml文件保存到指定的路径下
myXmlDoc.Save(xmlFilePath);
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}private static void GetXMLInformation(string xmlFilePath)
{
try
{
//初始化一个xml实例
XmlDocument myXmlDoc = new XmlDocument();
//加载xml文件(参数为xml文件的路径)
myXmlDoc.Load(xmlFilePath);
//获得第一个姓名匹配的节点(SelectSingleNode):此xml文件的根节点
XmlNode rootNode = myXmlDoc.SelectSingleNode("Computers");
//分别获得该节点的InnerXml和OuterXml信息
string innerXmlInfo = rootNode.InnerXml.ToString();
string outerXmlInfo = rootNode.OuterXml.ToString();
//获得该节点的子节点(即:该节点的第一层子节点)
XmlNodeList firstLevelNodeList = rootNode.ChildNodes;
foreach (XmlNode node in firstLevelNodeList)
{
//获得该节点的属性集合
XmlAttributeCollection attributeCol = node.Attributes;
foreach (XmlAttribute attri in attributeCol)
{
//获取属性名称与属性值
string name = attri.Name;
string value = attri.Value;
Console.WriteLine("{0} = {1}", name, value);
}
//判断此节点是否还有子节点
if (node.HasChildNodes)
{
//获取该节点的第一个子节点
XmlNode secondLevelNode1 = node.FirstChild;
//获取该节点的名字
string name = secondLevelNode1.Name;
//获取该节点的值(即:InnerText)
string innerText = secondLevelNode1.InnerText;
Console.WriteLine("{0} = {1}", name, innerText);//获取该节点的第二个子节点(用数组下标获取)
XmlNode secondLevelNode2 = node.ChildNodes[1];
name = secondLevelNode2.Name;
innerText = secondLevelNode2.InnerText;
Console.WriteLine("{0} = {1}", name, innerText);
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}private static void ModifyXmlInformation(string xmlFilePath)
{
try
{
XmlDocument myXmlDoc = new XmlDocument();
myXmlDoc.Load(xmlFilePath);
XmlNode rootNode = myXmlDoc.FirstChild;
XmlNodeList firstLevelNodeList = rootNode.ChildNodes;
foreach (XmlNode node in firstLevelNodeList)
{
//修改此节点的属性值
if (node.Attributes["Description"].Value.Equals("Made in USA"))
{
node.Attributes["Description"].Value = "Made in HongKong";
}
}
//要想使对xml文件所做的修改生效,必须执行以下Save方法
myXmlDoc.Save(xmlFilePath);
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}}
private static void AddXmlInformation(string xmlFilePath)
{
try
{
XmlDocument myXmlDoc = new XmlDocument();
myXmlDoc.Load(xmlFilePath);
//添加一个带有属性的节点信息
foreach (XmlNode node in myXmlDoc.FirstChild.ChildNodes)
{
XmlElement newElement = myXmlDoc.CreateElement("color");
newElement.InnerText = "black";
newElement.SetAttribute("IsMixed", "Yes");
node.AppendChild(newElement);
}
//保存更改
myXmlDoc.Save(xmlFilePath);
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}private static void DeleteXmlInformation(string xmlFilePath)
{
try
{
XmlDocument myXmlDoc = new XmlDocument();
myXmlDoc.Load(xmlFilePath);
foreach (XmlNode node in myXmlDoc.FirstChild.ChildNodes)
{
//记录该节点下的最后一个子节点(简称:最后子节点)
XmlNode lastNode = node.LastChild;
//删除最后子节点下的左右子节点
lastNode.RemoveAll();
//删除最后子节点
node.RemoveChild(lastNode);
}
//保存对xml文件所做的修改
myXmlDoc.Save(xmlFilePath);
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}
} -
[C#的SAX解析XML]
本章导航-----C#的SAX解析
-
[准备工作]
.net封装了对SAX的具体实现,可以通过调用里面的方法,进行具体的代码操作。第三方下载地址
-
-
[JAVA的JAXP之DOM解析XML]
本章导航-----JAVA中的DOM解析
-
[JAXP介绍(Java API for XMLProcessing)]
JAXP 是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成.在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
-
[具体步骤]
step1、创建解析器工厂对象 DocumentBuildFactory;
step2、由解析器工厂对象创建解析器对象DocumentBuilder;
step3、由解析器对象对指定XML文件进行解析,构建相应的DOM树,创建Document对象;
step4、以Document对象为起点对DOM树的节点进行查询;
step5、使用Document的getElementsByTagName方法获取元素名称,生成一个NodeList集;
step6、遍历集合; -
[具体代码]
要解析的xml文件
<产品唯一ID>产品唯一ID</产品唯一ID>
<通用名>通用名</通用名>
<商品名>商品名</商品名>
<剂型>剂型</剂型>
<批准文号>批准文号</批准文号>
<规格>规格</规格>
<包装说明>包装说明</包装说明>
<包装单位>包装单位</包装单位>
<生产企业>生产企业</生产企业>
<大包装转换比>大包装转换比</大包装转换比>
<中包装转换比>中包装转换比</中包装转换比>
<备注>备注</备注>
<库存>库存</库存>
<供应价>供应价</供应价>
<是否上架>是否上架</是否上架>
<产品唯一ID>a121</产品唯一ID>
<通用名>b12</通用名>
<商品名>c231</商品名>
<剂型>dewrwer</剂型>
<批准文号>e324324</批准文号>
<规格>f45645</规格>
<包装说明>g4543</包装说明>
<包装单位>hq324e2</包装单位>
<生产企业>i76</生产企业>
<大包装转换比>j453</大包装转换比>
<中包装转换比>k4r43r</中包装转换比>
<备注>le4tr4</备注>
<库存>mq3e2</库存>
<供应价>nefrw</供应价>
<是否上架>o56</是否上架>
具体的解析代码
import java.io.;//导入java.io包下的所有类
import org.w3c.dom.;//使用org.w3c.dom操作XML文件
import org.xml.sax.SAXException;//使用org.xml.sax.SAXException读取文件
import javax.xml.parsers.*; //导入 javax.xml.parsers包下的所有类
public class Test{//类名
public static void main(String[] args){//程序主入口函数,带命令行参数
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//创建DOM模式的解析器工厂对象
try{//try代码块,当发生异常时会转到catch代码块中
DocumentBuilder builder=factory.newDocumentBuilder();//得到一个DOM解析器对象
Document doc=builder.parse(new File("D:\test\XML.xml"));//打开指定路径下的xml文件
NodeList nl=doc.getElementsByTagName("hang");//获得文件的值
for (int i=0; i < nl.getLength(); i++){//for循环的条件
System.out.println(doc.getElementsByTagName("产品唯一ID").item(i).getFirstChild().getNodeValue());//获取“产品唯一ID”的信息
System.out.println(doc.getElementsByTagName("通用名").item(i).getFirstChild().getNodeValue());//获取“通用名”的信息
System.out.println(doc.getElementsByTagName("商品名").item(i)
.getFirstChild().getNodeValue());//获取“商品名”的信息
System.out.println(doc.getElementsByTagName("剂型").item(i)
.getFirstChild().getNodeValue());//获取“剂型”的信息
System.out.println(doc.getElementsByTagName("批准文号").item(i)
.getFirstChild().getNodeValue());//获取“批准文号”的信息
System.out.println(doc.getElementsByTagName("规格").item(i)
.getFirstChild().getNodeValue());//获取“规格”的信息
System.out.println(doc.getElementsByTagName("包装说明").item(i)
.getFirstChild().getNodeValue());//获取“包装说明”的信息
System.out.println(doc.getElementsByTagName("包装单位").item(i)
.getFirstChild().getNodeValue());//获取“包装单位”的信息
System.out.println(doc.getElementsByTagName("生产企业").item(i)
.getFirstChild().getNodeValue());//获取“生产企业”的信息
System.out.println(doc.getElementsByTagName("大包装转换比").item(i)
.getFirstChild().getNodeValue());//获取“大包装转换比”的信息
System.out.println(doc.getElementsByTagName("中包装转换比").item(i)
.getFirstChild().getNodeValue());//获取“中包装转换比”的信息
System.out.println(doc.getElementsByTagName("备注").item(i)
.getFirstChild().getNodeValue());//获取“备注”的信息
System.out.println(doc.getElementsByTagName("库存").item(i)
.getFirstChild().getNodeValue());//获取“库存”的信息
System.out.println(doc.getElementsByTagName("供应价").item(i)
.getFirstChild().getNodeValue());//获取“供应价”的信息
System.out.println(doc.getElementsByTagName("是否上架").item(i)
.getFirstChild().getNodeValue());//获取“是否上架”的信息
System.out.println();//输出空字符进行格式调整
}
}
catch (ParserConfigurationException e){//当try代码块有异常时转到catch代码块
e.printStackTrace();//在命令行打印异常信息出错的位置及原因
}
catch (SAXException e){//当try代码块有异常时转到catch代码块
e.printStackTrace();//在命令行打印异常信息出错的位置及原因
}
catch (IOException e){//当try代码块有异常时转到catch代码块
e.printStackTrace();//在命令行打印异常信息出错的位置及原因
}
} -
-
[JAVA的JAXP之SAX解析XML]
本章导航-----JAXP之SAX解析XML
-
[具体步骤]
step1:得到xml文件对应的资源,可以是xml的输入流,文件和uri
step2:得到SAX解析工厂(SAXParserFactory)
step3:由解析工厂生产一个SAX解析器(SAXParser)
step4:传入输入流和handler给解析器,调用parse()解析 -
[具体代码]
创建一个books.xml的配置文件
<书架>
<书>
<书名 name="dddd">java web就业</书名>
<作者>张三</作者>
<售价>40</售价>
</书>
<书>
<书名 name="xxxx">HTML教程</书名>
<作者>自己</作者>
<售价>50</售价>
</书>
</书架>创建一个javaBean实体类
package sax;
public class Book {
private String name;
private String author;
private String price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return "Book [name=" + name + ", author=" + author + ", price=" + price + "]";
}
}创建一个ListHandler类,实现ContentHandler相关方法
新建一个ListHandler类,这个类需要DefaultHandler或者实现ContentHandler接口。该类是SAX解析的核心所在,我们要重写以下几个我们关心的方法。
a:startDocument():文档解析开始时调用,该方法只会调用一次
b:startElement(String uri, String localName, String qName, Attributes attributes):标签(节点)解析开始时调用
参数含义--uri:xml文档的命名空间;localName:标签的名字;qName:带命名空间的标签的名字;attributes:标签的属性集
c:characters(char[] ch, int start, int length):解析标签的内容的时候调用
参数含义--ch:当前读取到的TextNode(文本节点)的字节数组;start:字节开始的位置,为0则读取全部;length:当前TextNode的长度
d:endElement(String uri, String localName, String qName):标签(节点)解析结束后调用
e:endDocument():文档解析结束后调用,该方法只会调用一次class ListHandler implements ContentHandler{
/**
* 当读取到第一个元素时开始做什么
*/@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
System.out.print("<"+qName);
for(int i=0;atts!=null&&i<atts.getLength();i++){
String attName=atts.getQName(i);
String attValueString=atts.getValue(i);
System.out.print(" "+attName+"="+attValueString);
System.out.print(">");
}}
/**
* 表示读取到第一个元素结尾时做什么
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</"+qName+">");}
/**
* 表示读取字符串时做什么
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.print(new String(ch,start,length));}
@Override
public void setDocumentLocator(Locator locator) {
// TODO Auto-generated method stub}
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub}
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub}
@Override
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// TODO Auto-generated method stub}
@Override
public void endPrefixMapping(String prefix) throws SAXException {
// TODO Auto-generated method stub}
@Override
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub}
@Override
public void processingInstruction(String target, String data)
throws SAXException {
// TODO Auto-generated method stub}
@Override
public void skippedEntity(String name) throws SAXException {
// TODO Auto-generated method stub}
}
创建程序入口类
public static void main(String[] args) throws Exception {
//1.创建解析工厂
SAXParserFactoryfactory=SAXParserFactory.newInstance();
//2.得到解析器
SAXParser sp=factory.newSAXParser();
//3得到解读器
XMLReader reader=sp.getXMLReader();
//设置内容处理器
reader.setContentHandler(new ListHandler());
//读取xml的文档内容
reader.parse("src/Book.xml");}
-
-
[JAVA的JAXP之JDOM解析XML]
本章导航-----JDOM解析XML
-
[具体步骤]
step1、下载jar包,这里用到的是jdom_1.1.jar
step2、了解jdom_1.1中的主要的类:参考https://blog.csdn.net/vb1088blog/article/details/425532 -
[具体代码]
package com.aisino.xml;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.StringReader;
import java.util.Iterator;
import java.util.List;
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import org.jdom.output.Format;
import org.jdom.output.XMLOutputter;
import com.aisino.util.CommonUtil;public class XMLParser {
static{
//手工加载配置文件
PropertyConfigurator.configureAndWatch("F:\workspace\JavaSample\log4jj.properties");
}//文件路径
final static String filePath = "F:\workspace\JavaSample\src\com\aisino\xml\";/**
* log4j
*/
private static Logger logger = Logger.getLogger(XMLParser.class);/**
*
* 方法功能描述
*
* @param args
* @throws Exception
* @return void
* @exception 异常描述
* @see
*/
public static void main(String[] args) throws Exception {
//读文件到内存
Document doc = new XMLParser().readXMLFileToDocument(filePath + "students.xml");//写Document到文件
new XMLParser().writeDocumentToFile(doc, filePath + "service.xml");//查询Document
new XMLParser().queryXML(doc);//添加元素和属性
new XMLParser().addElementAndAttributeToDocument(doc);//克隆
new XMLParser().copyElementAndToTree(doc);//修改XML
new XMLParser().updateXML(doc);//删除XML元素和属性
new XMLParser().removeXMLContent(doc);new XMLParser().writeDocumentToFile(doc, filePath + "service.xml");
//内存中的Document->String
String docS = new XMLOutputter().outputString(doc);
logger.info("docs:" + docS);//String->Document
Document doc1 = new SAXBuilder().build(new StringReader(docS));
new XMLParser().writeDocumentToFile(doc1, "StringToDocument.xml");
}/**
*
* 读xml文件到内存
*
* @param fileName 文件名
* @return
* @return Document
* @exception 异常描述
* @see
*/
public Document readXMLFileToDocument(String fileName) {
SAXBuilder saxb = new SAXBuilder();try {
Document doc = saxb.build(new File(fileName));
return doc;
} catch (JDOMException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
}return null;
}/**
*
* 写Document到文件
*
* @param doc 文件
* @param fileName 文件名
* @return void
* @exception 异常描述
* @see
*/
public void writeDocumentToFile(Document doc, String fileName) {
XMLOutputter xo = new XMLOutputter(Format.getPrettyFormat());try {
xo.output(doc, new FileWriter(new File(fileName)));
} catch (IOException e) {
//e.printStackTrace();
}
}/**
*
* 查询Document
*
* @param doc
* @return void
* @exception 异常描述
* @see
*/
@SuppressWarnings("unchecked")
public void queryXML(Document doc) {
//获得根元素
Element rootElement = doc.getRootElement();
logger.info("rootElement:" + rootElement);//获得根元素的所有孩子元素
List rootChildren = rootElement.getChildren();
logger.info("rootChildren:" + rootChildren);//获得元素的指定名称的所有元素
List studentChildren = rootElement.getChildren("student");
logger.info("studentChildren:" + studentChildren);//获得指定名称的第一个元素
Element studentChild = rootElement.getChild("student");
logger.info("studentChild:" + studentChild);//对studnetChildren进行迭代
Iterator studentChildIte = studentChildren.iterator();
while(studentChildIte.hasNext()){
Element studentElement = (Element)studentChildIte.next();//获得元素名称和值
String studentName = studentElement.getName();
String studentValue = studentElement.getValue();
logger.info("studentName:" + studentName);
logger.info("studentValue:" + studentValue);//获得元素的所有属性
List studentAttributes = studentElement.getAttributes();
Attribute currentAttribute = studentElement.getAttribute("studentid");
logger.info("currentAttribute:" + currentAttribute);if(studentAttributes != null){
Iterator studentAttrIte = studentAttributes.iterator();
while(studentAttrIte.hasNext()){
Attribute currentAttr = (Attribute)studentAttrIte.next();//取得属性的名称和值
String curAttrName = currentAttr.getName();
String curAttrValue = currentAttr.getValue();
logger.info("curAttrName:" + curAttrName + " curAttrValue:" + curAttrValue);
}
}
}
}/**
*
* 向XML中添加元素和属性
*
* @param doc
* @return void
* @exception 异常描述
* @see
*/
@SuppressWarnings("unchecked")
private void addElementAndAttributeToDocument(Document doc) {
//根元素
Element rootElement = doc.getRootElement();//新元素
Element companyElement = new Element("aisino");
rootElement.addContent(companyElement);//添加文本值
companyElement.setText(CommonUtil.setStrUTF8Encode("航天信息软件"));//【第一种】添加属性
Attribute addressid = new Attribute("addressid",CommonUtil.setStrUTF8Encode("杏石口路甲18号"));
Attribute companygender = new Attribute("gender","3");
companyElement.setAttribute(addressid);
companyElement.setAttribute(companygender);//【第二种】添加属性
List companyAttrsList = companyElement.getAttributes();
Attribute age = new Attribute("age","5");
companyAttrsList.add(age);
Attribute people = new Attribute("people","200");
companyAttrsList.add(people);
}/**
*
* 克隆(复制)XML元素
*
* @param doc
* @return void
* @exception 异常描述
* @see
*/
private void copyElementAndToTree(Document doc) {
Element rootElement = doc.getRootElement();//获得指定元素的第一个元素
Element studentElement = rootElement.getChild("student");//克隆,复制
Element cloneStudentElement = (Element)studentElement.clone();rootElement.addContent(cloneStudentElement);
cloneStudentElement.setText("hanhuayi");
cloneStudentElement.getAttribute("studentid").setValue("4");
}/**
*
* 修改XML
*
* @param doc
* @return void
* @exception 异常描述
* @see
*/
private void updateXML(Document doc) {
Element rootElement = doc.getRootElement();//获得指定名称的第一个孩子元素
Element studentElement = (Element)rootElement.getChild("student");studentElement.setName("stud");
studentElement.setText("newText");
studentElement.getAttribute("studentid").setValue("11");
studentElement.getAttribute("age").setValue("201");
}/**
*
* 删除XML元素
*
* @param doc
* @return void
* @exception 异常描述
* @see
*/
private void removeXMLContent(Document doc) {
Element rootElement = doc.getRootElement();//获得指定元素的第一个元素
Element studentElement = rootElement.getChild("student");
rootElement.removeContent(studentElement);
}
}
-
-
[JAVA的DOM4J解析XML]
本章导航-----DOM4J解析XML
-
[具体步骤]
step1、下载jar包(推荐一个jar包的下载网站: https://mvnrepository.com/ )
step2、认识jar包中的主要类:参考https://blog.csdn.net/qq_43386754/article/details/85651049 -
[具体代码]
package com.xml.dom4j;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;import com.xml.dom.Student;
public class Dom4JTest {
public ListgetAllStudent(){
Listlist=new ArrayList<>();
//构建解析器
SAXReader dom=new SAXReader();
try {
Document doc=
dom.read("src/com/xml/dom/stu.xml");
//获取根标签
Element root=doc.getRootElement();
//获取二级标签,只获取元素标签,忽略掉空白的
//文本
Listers=root.elements();
for(Element er:ers){
Student stu=new Student();
//获取名字
// String name=er.getName();
// System.out.println(name);
//获取所有的属性
// Listattrs=er.attributes();
//获取属性的值
// System.out.println(attrs.get(0).getValue());
//获取单个属性
String id=er.attributeValue("id");
stu.setId(Long.parseLong(id));
Listsans=er.elements();
for(Element san:sans){
if(san.getName().equals("name")){
// san.getText();
// san.getTextTrim();
// Object obj=san.getData();
stu.setName(san.getText());
}else if(san.getName().equals("age")){
stu.setAge(Integer.parseInt((String) san.getData()));
}
}
list.add(stu);
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
/*
*添加对象方法
/
public void addStudent(Student stu){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
//添加元素的同时返回当前元素
Element stuE=root.addElement("student");
//设置元素属性
stuE.addAttribute("id", stu.getId()+"");
Element nameE=stuE.addElement("name");
//设置文本内容
nameE.setText(stu.getName());
Element ageE=stuE.addElement("age");
ageE.setText(stu.getAge()+"");
//移除元素
//root.remove(stuE);
//第一个参数表示路径,
//第二个参数表示格式
//不写格式输出的时候,新增加的内容直接一行插入
// XMLWriter writer=
// new XMLWriter(
// new FileOutputStream(
// "src/com/xml/dom/stu.xml"));
//OutputFormat format=OutputFormat.createPrettyPrint();
//docment中的tree全部转化为一行内入写入
OutputFormat format=OutputFormat.createCompactFormat();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/
*删除对象方法
*/
public void remove(long id){
SAXReader sax=new SAXReader();
try {
Document doc=
sax.read("src/com/xml/dom/stu.xml");
Element root=doc.getRootElement();
Listers=root.elements();
for(Element er:ers){
String ids=er.attributeValue("id");
if(id==Long.parseLong(ids)){
er.getParent().remove(er);
break;
}
}
OutputFormat format=
OutputFormat.createPrettyPrint();
XMLWriter writer=
new XMLWriter(
new FileOutputStream(
"src/com/xml/dom/stu.xml"),format);
writer.write(doc);
writer.flush();
writer.close();
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args) {
new Dom4JTest().remove(3);
// new Dom4JTest().addStudent(
// new Student(3,"briup",55));
// Listlist=new Dom4JTest().getAllStudent();
// for(Student s:list){
// System.out.println(s);
// }
}
}
-
posted on 2019-07-22 10:39 NoMatterTryAgain 阅读(351) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号