Web Scraper 初级用法——Web Scraper 初尝--抓取豆瓣高分电影 | 简易数据分析 04

这是简易数据分析系列的第 4 篇文章。
今天我们开始数据抓取的第一课,完成我们的第一个爬虫。因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:)
有人之前可能学过一些爬虫知识,总觉得这是个复杂的东西,什么 HTTP、HTML、IP 池,在这里我们都不考虑这些东西。一是小的数据量根本不需要考虑,二是这些乱七八糟的东西根本没有说到爬虫的本质。
爬虫的本质是什么?其实就是找规律。
而且爬虫的找规律难度,大部分都是小学三年级的数学题水平。
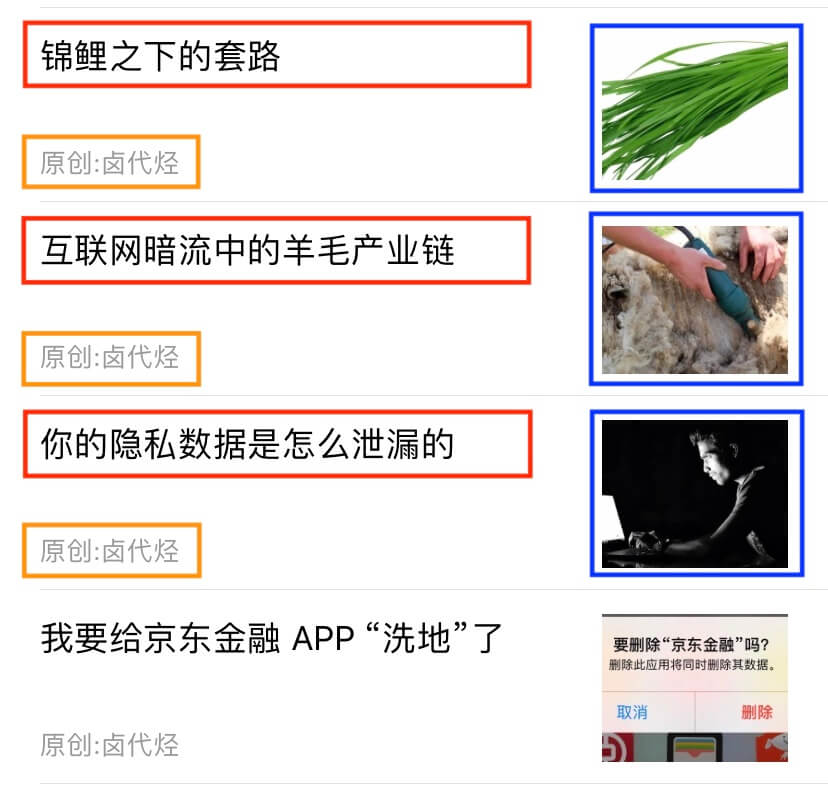
我们下面拿个例子说明一下,下图历史文章的一个截图,我们可以很清晰的看到,每一条推文可以分为三大部分:标题、图片和作者,我们只要找到这个规律,就可以批量的抓取这类数据。
好了,理论的地方我们讲完了,下面我们开始进行实操。
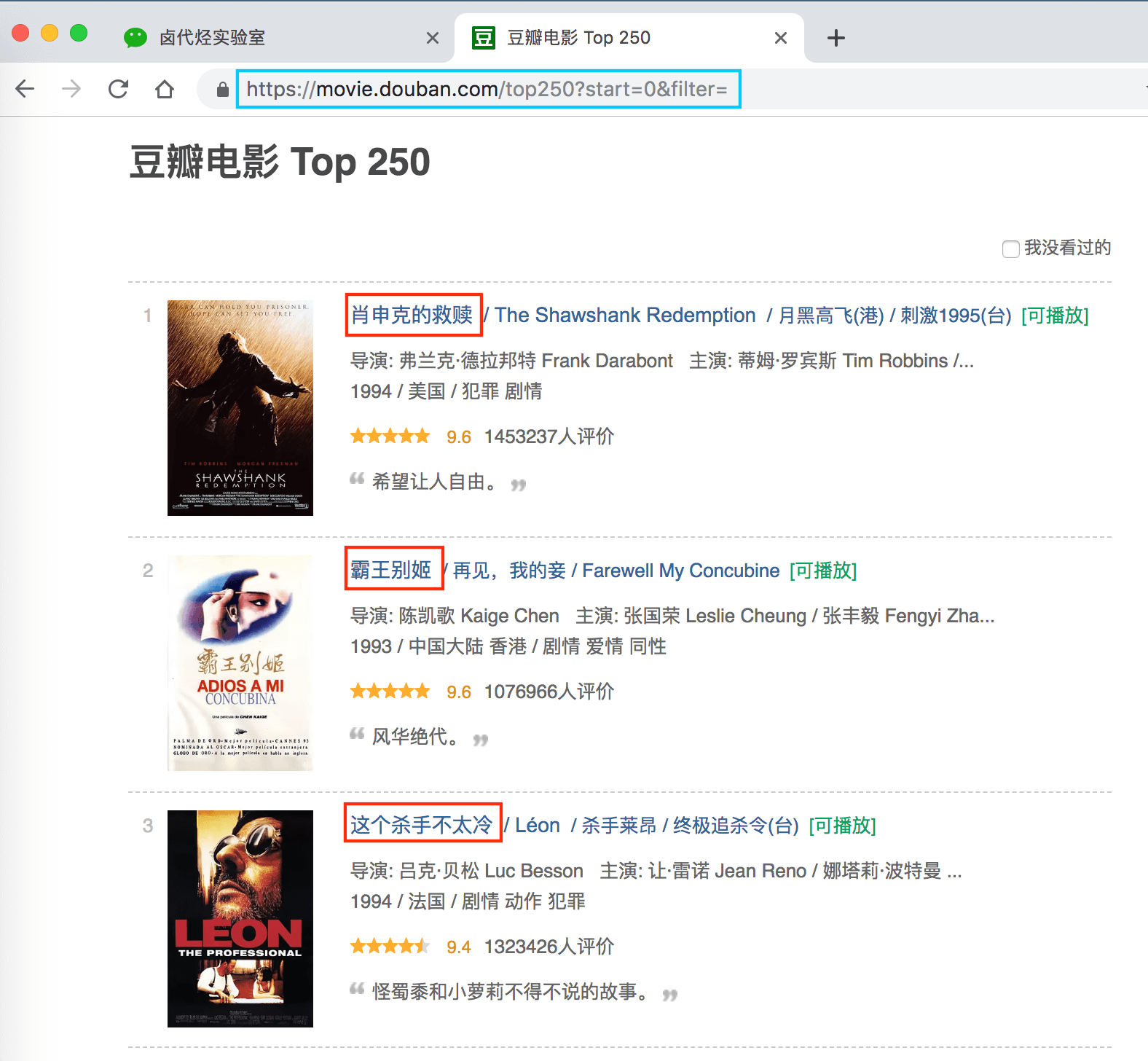
但凡做爬虫练手,第一个爬取的网站一般都是豆瓣电影 TOP 250,网址链接是 https://movie.douban.com/top250?start=0&filter=。第一次上手,我们爬取的内容尽量简单,所以我们只爬取第一页的电影标题。
浏览器按 F12 打开控制台,并把控制台放在网页的下方(具体操作可以看上一篇文章),然后找到 Web Scraper 这个 Tab,点进去就来到了 Web Scraper 的控制页面。

进入 Web Scraper 的控制页面后,我们按照 Create new sitemap -> Create Sitemap 的操作路径,创建一个新的爬虫,sitemap 是啥意思并不重要,你就当他是个爬虫的别名就好了。
我们在接下来出现的输入框里依次输入爬虫名和要爬取的链接。
爬虫名可能会有字符类型的限制,我们看一下规则规避就好了,最后点击 Create Sitemap 这个按钮,创建我们的第一个爬虫。

这时候会跳到一个新的操作面板,不要管别的,我们直接点击 Add new selector 这个蓝底白字的按钮,顾名思义,创建一个选择器,用来选择我们想要抓取的元素。
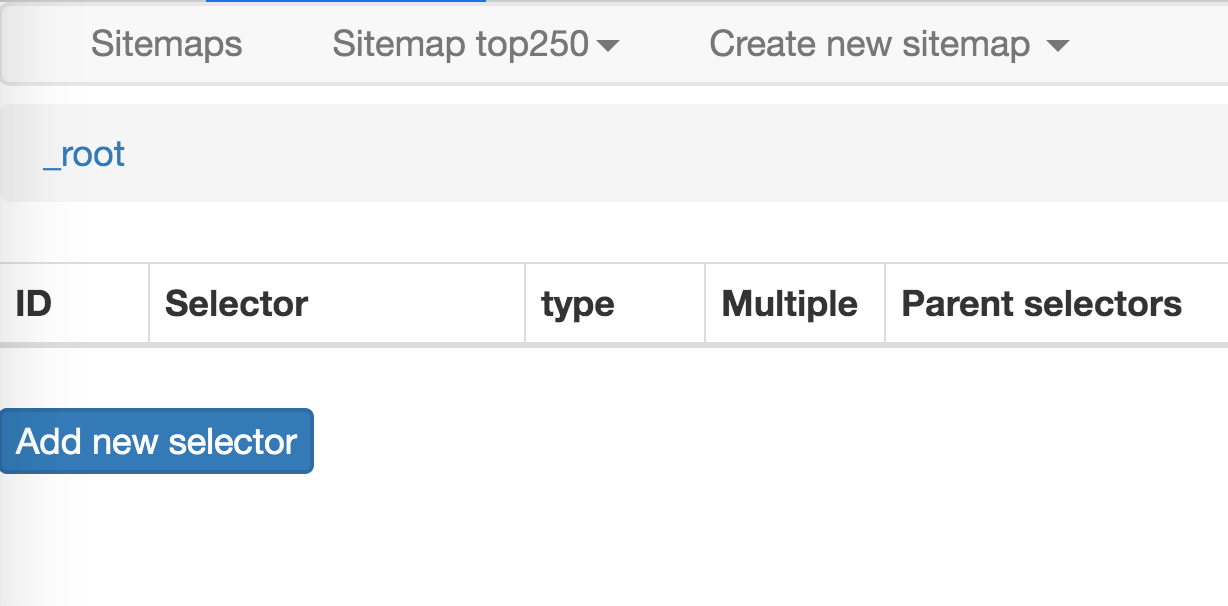
这时候就要开始正式的数据抓取环节了!我们先观察一下这个面板有些什么东西:

1.首先有个 Id,这个就是给我们要爬取的内容标注一个 id,因为我们要抓取电影的名字,简单起见就取个 name 吧;
2.电影名字很明显是一段文字,所以 Type 类型肯定是 Text,在这个爬虫工具里,默认 Type 类型就是 Text,这次的爬取工作就不需要改动了;
3.我们把多选按钮 Multiple 勾选上,因为我们要抓的是批量的数据,不勾选的话只能抓取一个;
4.最后我们点击黄色圆圈里的 Select,开始在网页上勾选电影名字;
当你把鼠标移动到网页时,会发现网页上出现了绿色的方块儿,这些方块就是网页的构成元素,当我们点击鼠标时,绿色的方块儿就会变为红色,表示这个元素被选中了:

这时候我们就可以进行我们的抓取工作了。
我们先选择「肖生克的救赎」这个标题,然后再选择「霸王别姬」这个标题(注意:想达到多选的效果,一定要手动选取两个以上的内容)
选完这两个标题后,向下拉动网页,你就会发现所有的电影名字都被选中了:

拉动网页检查一遍,发现所有的电影标题都被选中后,我们就可以点击 Done selecting!这个按钮,表示选择完毕;
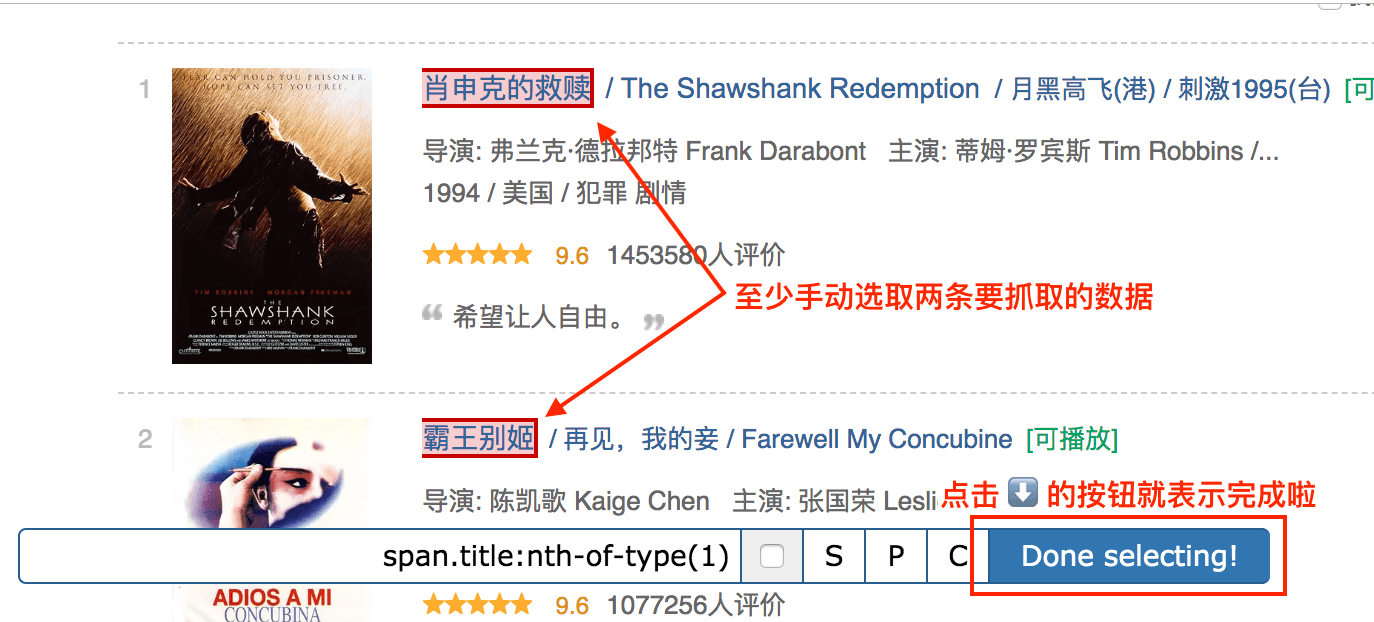
点击按钮后你会发现下图的红框位置会出现了一些字符,一般出现这个就表示选取成功了:

我们点击 Data preview 这个按钮,就可以预览我们的抓取效果了:

没什么问题的话,关闭 Data Preview 弹窗,翻到面板的最下面,有个 Save selector 的蓝色按钮,点击后我们会回退到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚刚的操作内容被记录下来了。
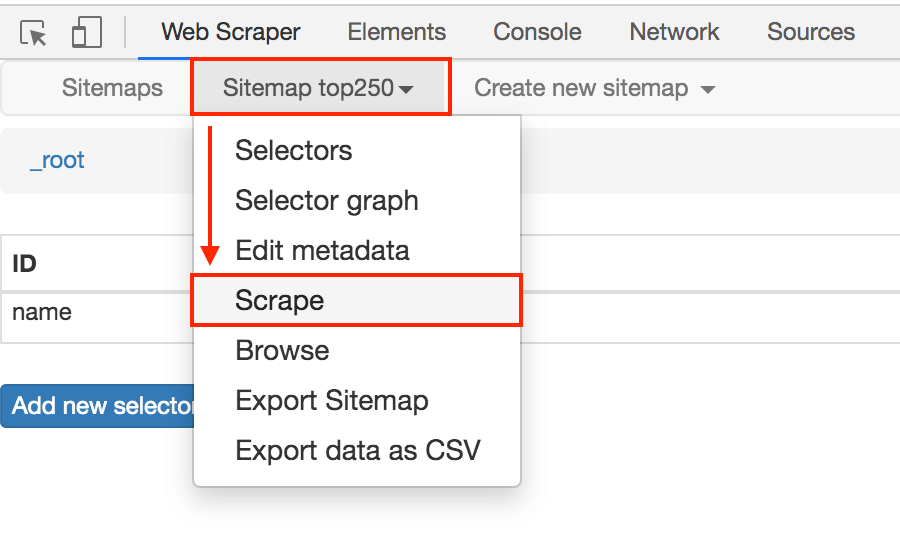
在顶部的 tab 栏,有一个 Sitemap top250 的 tab,这个就是我们刚刚创建的爬虫。点击它,再点击下拉菜单里的 Scrape 按钮,开始我们的数据抓取。
这时候你会跳到另一个面板,里面有两个输入框,先别管他们是什么,全部输入 2000 就好了。
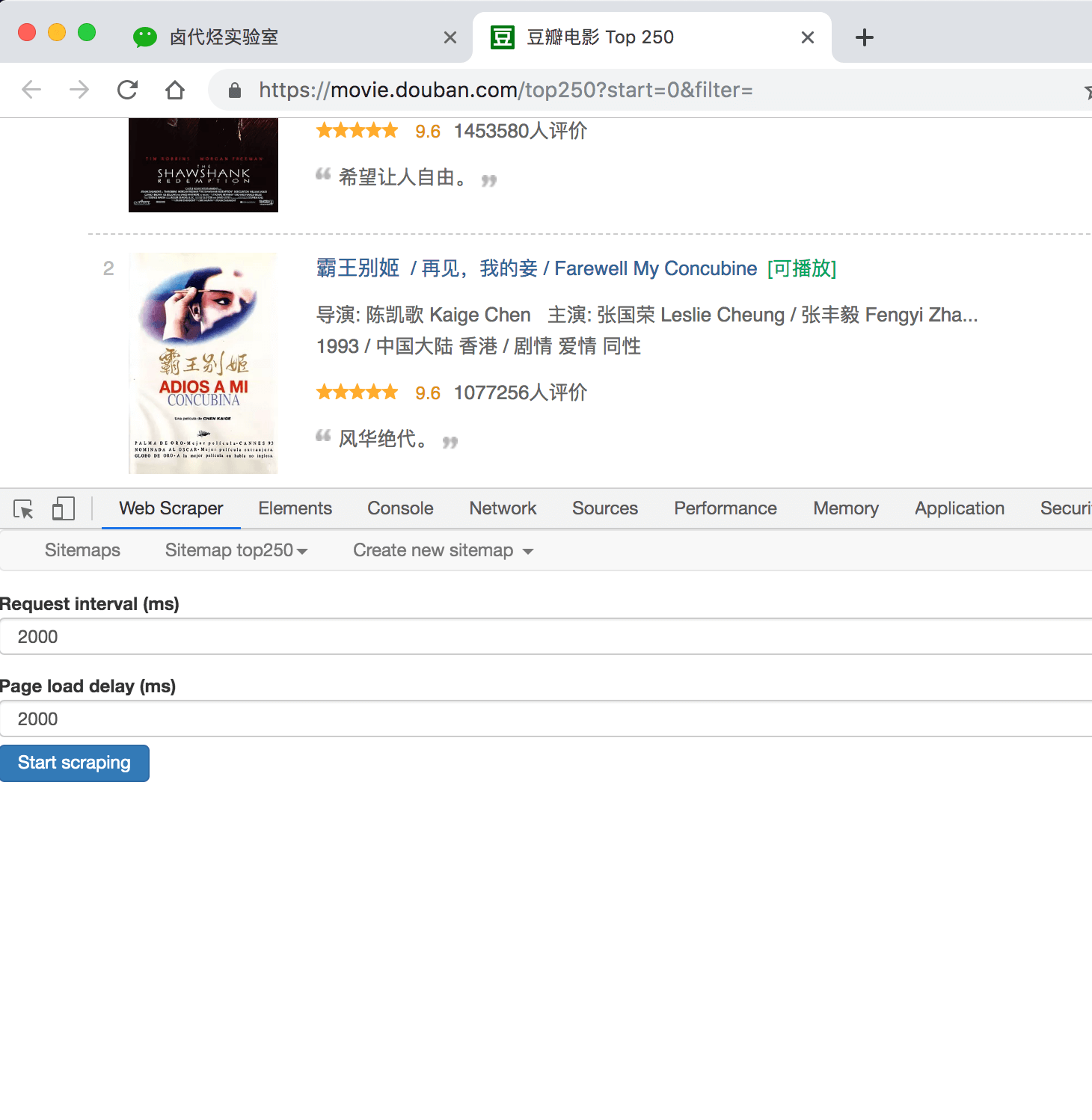
点击 Start scraping 蓝色按钮后,会跳出一个新的网页,Web Scraper 插件会在这里进行数据抓取:
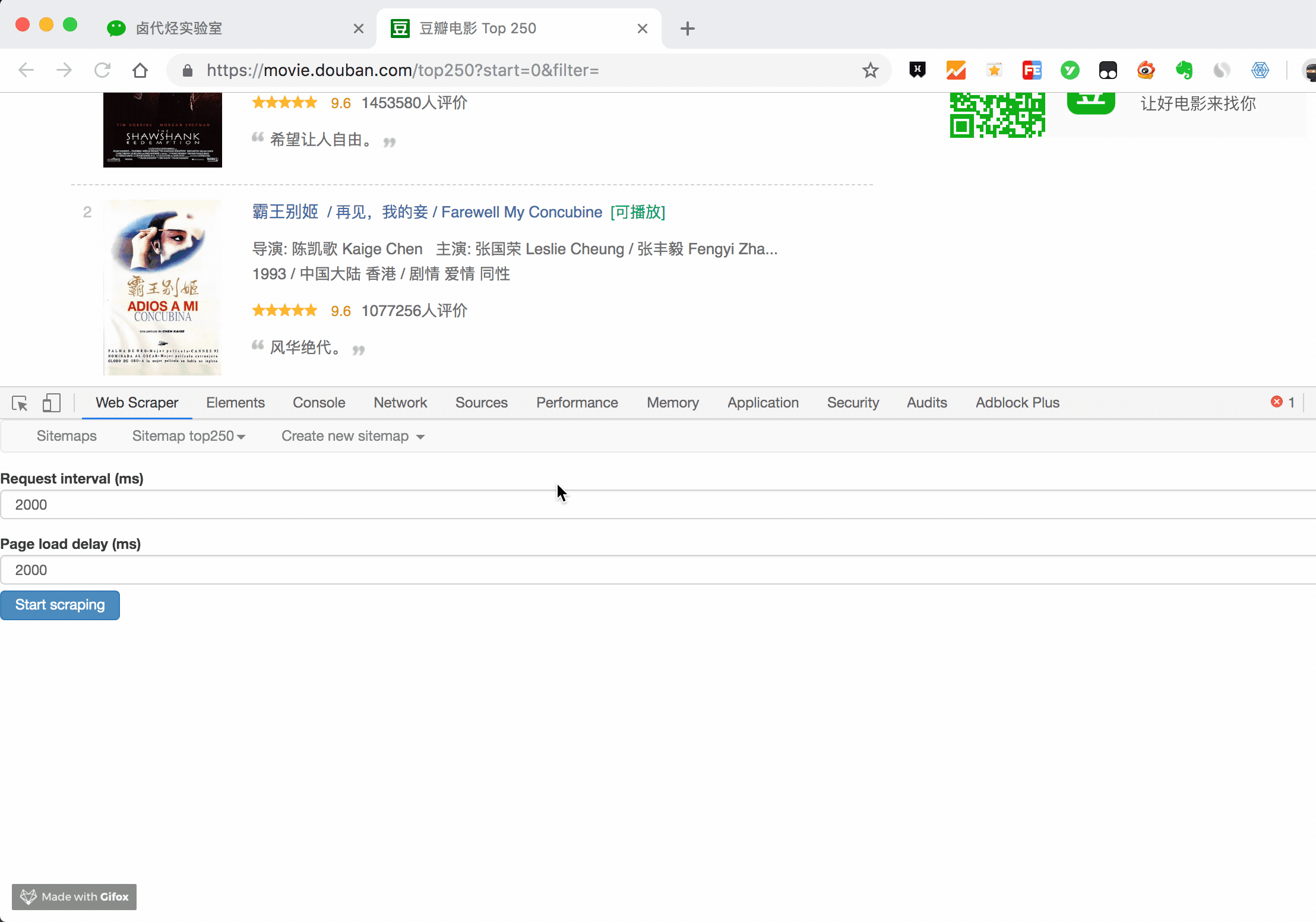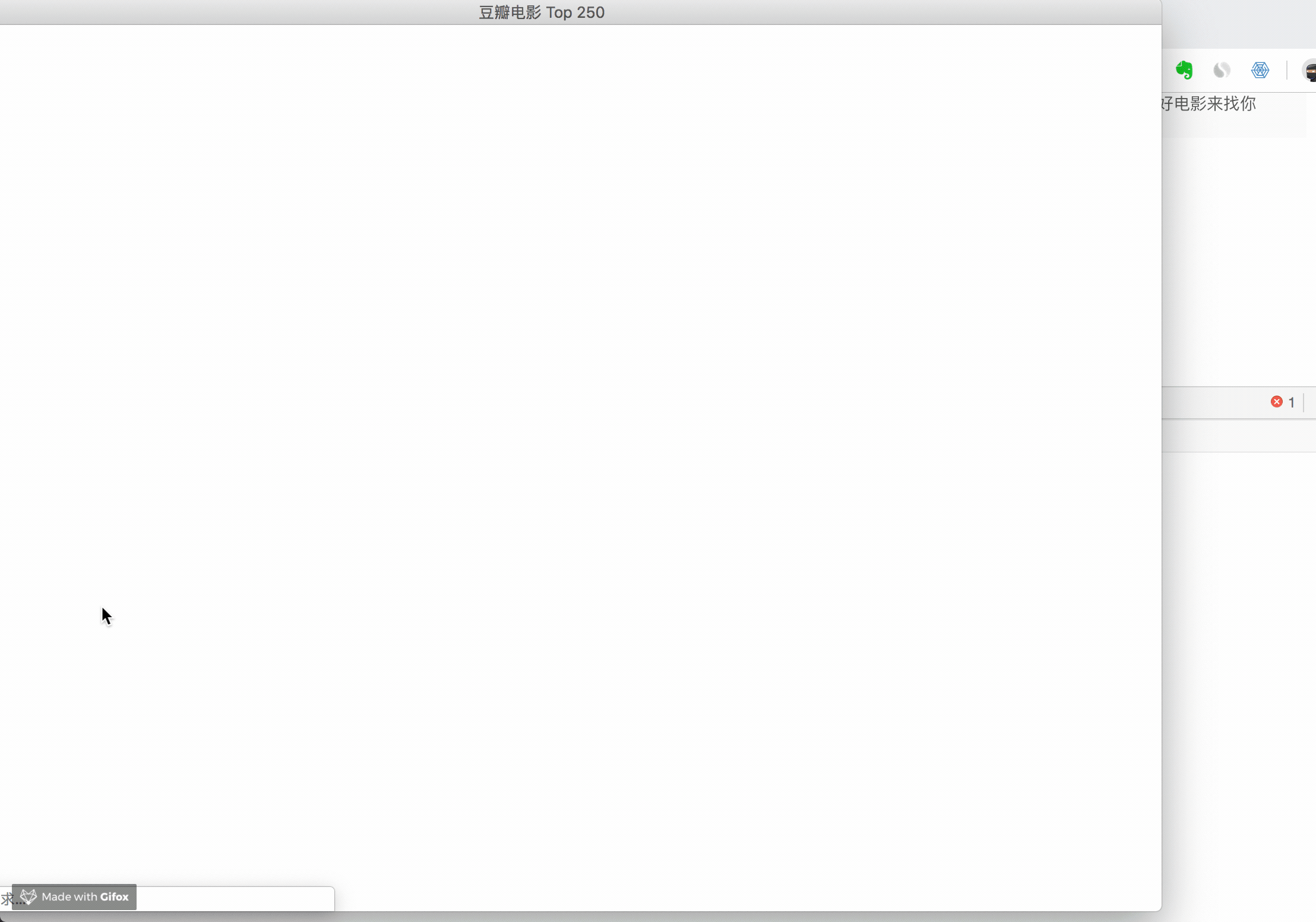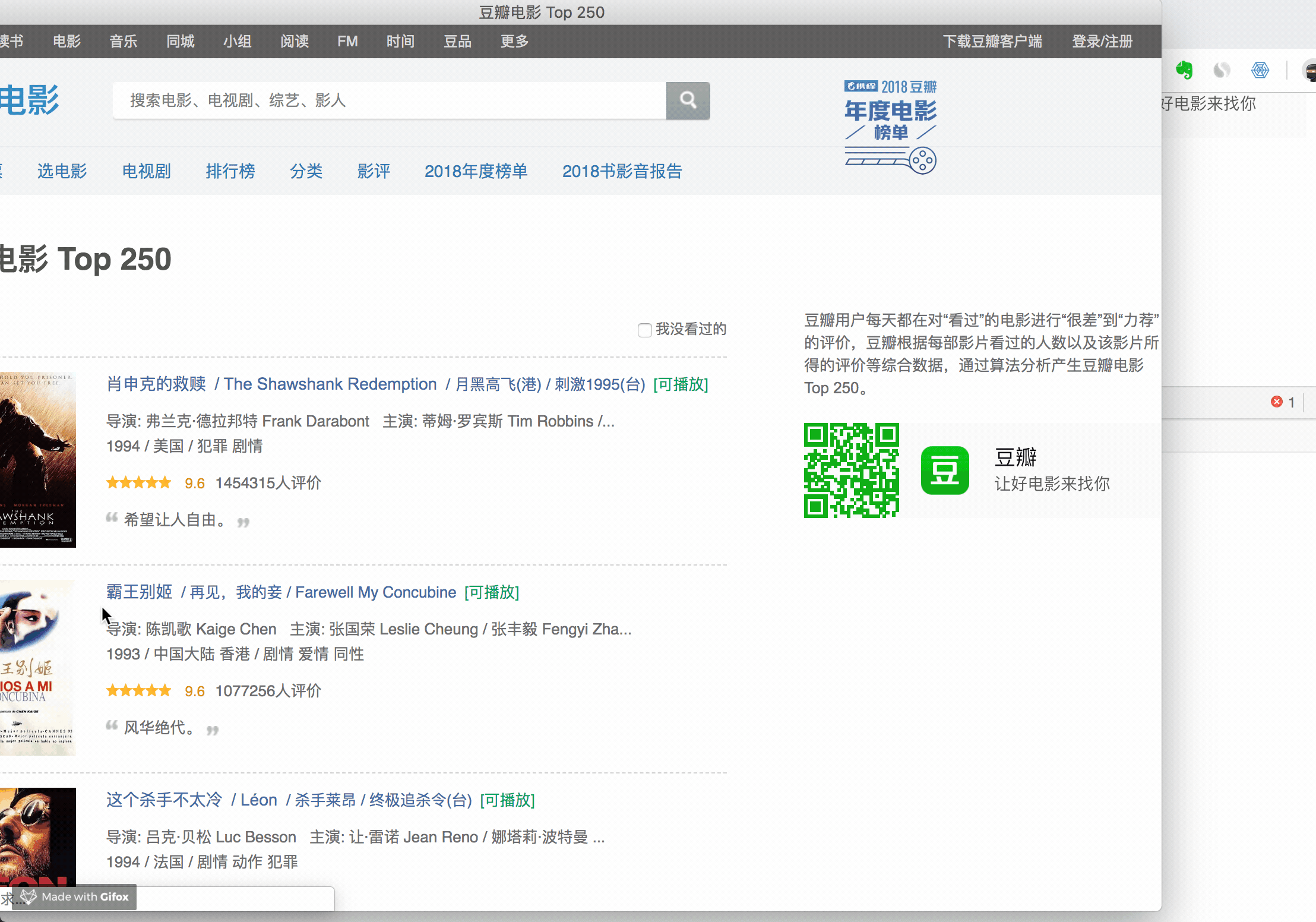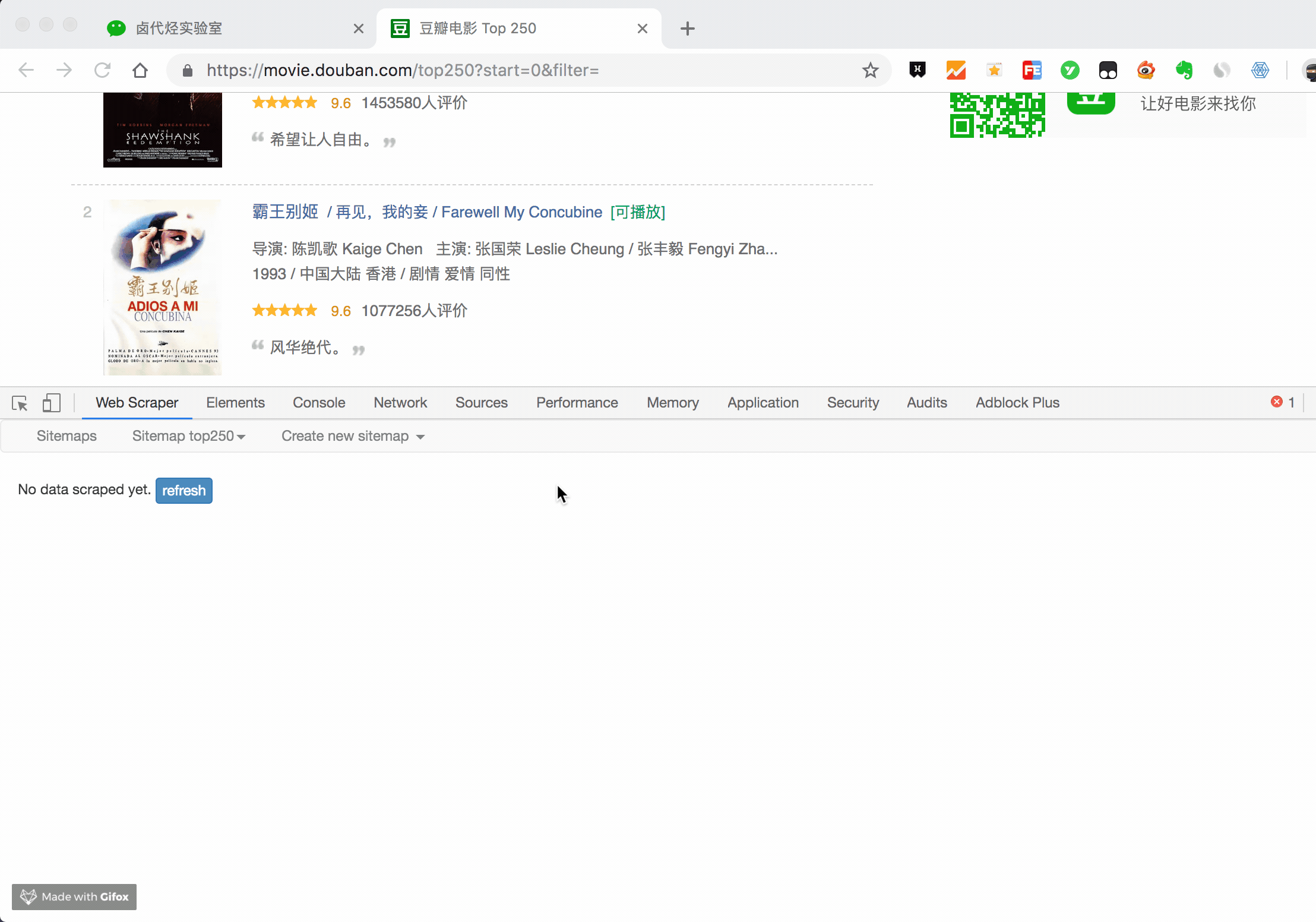
一般弹出的网页自动关闭就代表着数据抓取结束了,我们点击面板上的 refresh 蓝色按钮,就可以看到我们抓取的数据了!
在这个预览面板上,第一列是 web scraper 自动添加的编号,没啥意义;第二列是抓取的链接,第三列就是我们抓取的数据了。
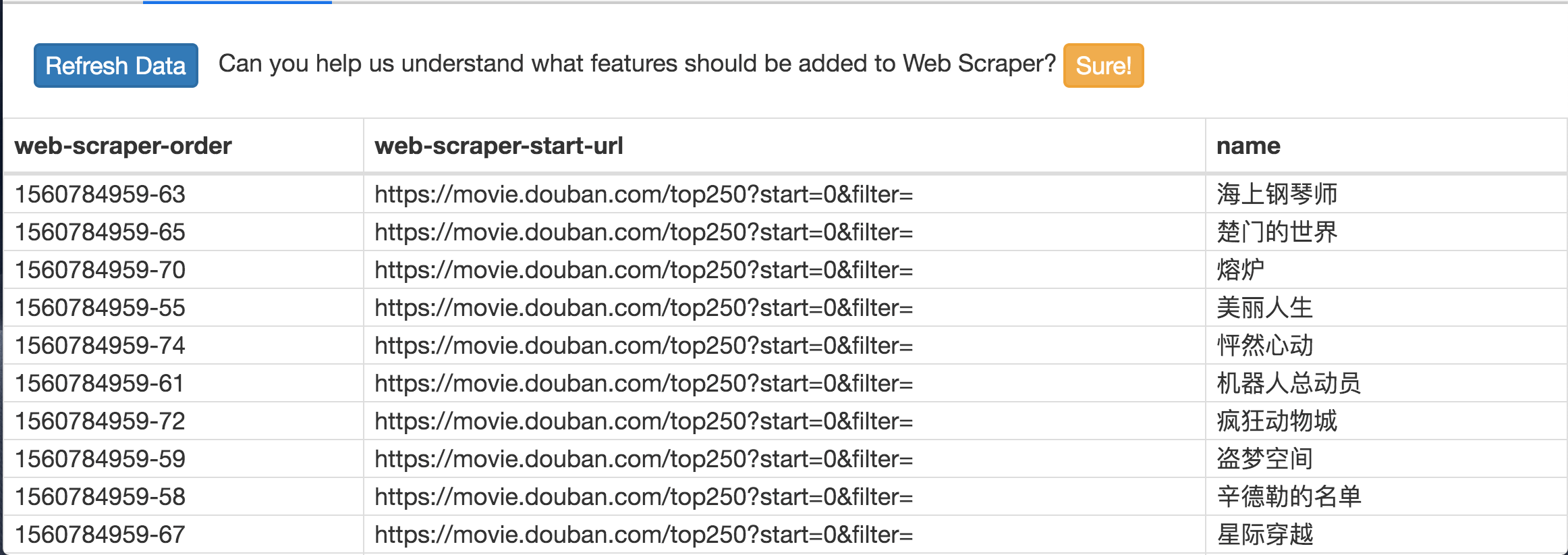
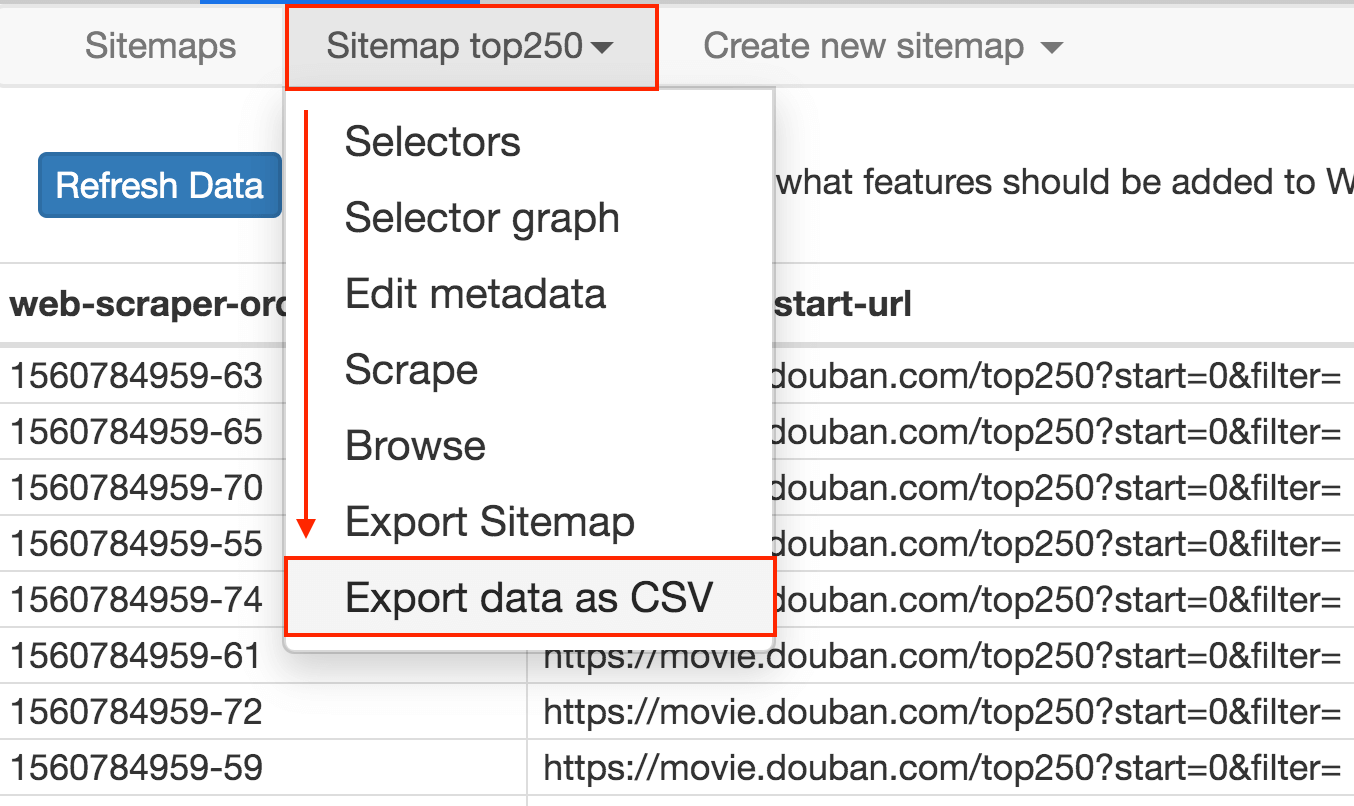
这个数据会存储在我们的浏览器里,我们也可以点击 Sitemap top250 下的 Export data as CSV,这样就可以导出成 .csv 格式的数据,这种格式可以用 Excel 打开,我们可以用 Excel 做一些数据格式化的操作。
今天我们爬取了豆瓣电影TOP250 的第 1 页数据(也就是排名最高的 25 部电影),下一篇我们讲讲,如何抓取所有的电影名。
推荐阅读:
简易数据分析 02 | Web Scraper 的下载与安装
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号