数据分窗的讨论
对于数据处理工作,数据分窗是一个很常见的操作,以信号采样序列为例,通常的方式有几种做法:
1. 以序列的第一个元素为基准,按步长滑移,按窗口尺寸切分;然而序列会因为处理的方式的不同会
对头尾部分进行一定程度的切除,会不会对最终分窗产生影响呢?下图显示了切除不会对最终结果
产生大影响,只是相当于删除首尾窗口,但是,使用此种处理,其余因素对分窗的影响效果不直观。
不同步长分窗结果,实际上是对单位步长分窗结果的采样!筒子们哇,在做特征提取时,改步长参数,
不需要从头再做,只需要从单位步长特征中抽样即可。

2. 1中提及的分窗做法让人感觉不是很良好,给大家奉上规范的分窗方式吧:
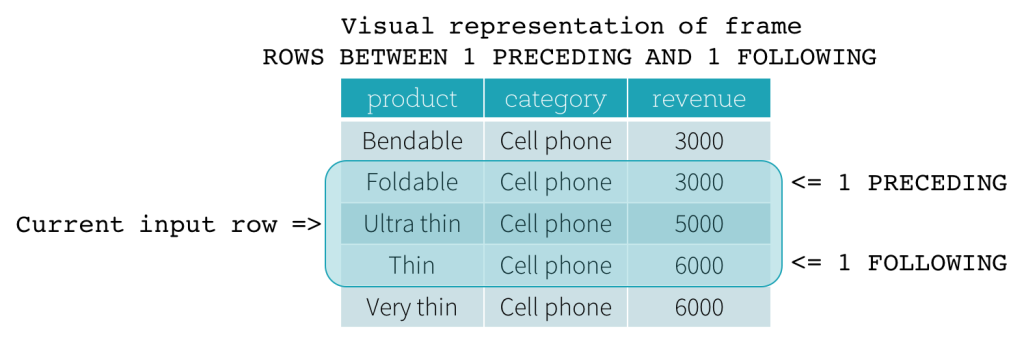
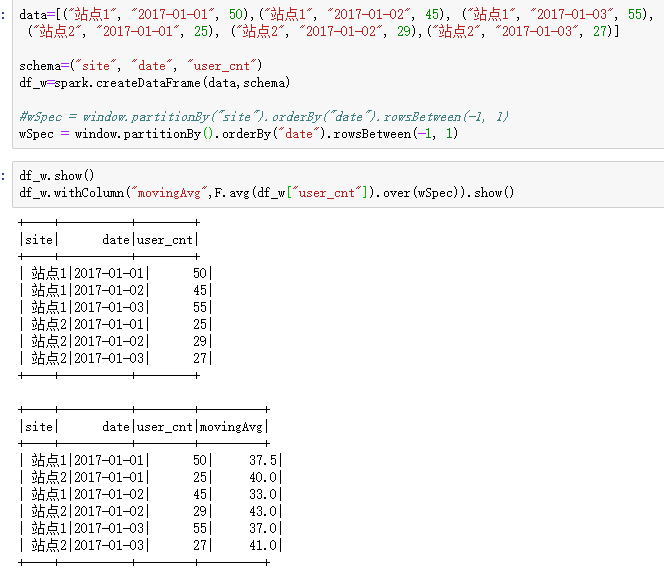
a. 以当前行的位置(index)为参考,将index前后偏移一定数量的即得到窗口对象,其实这需要一定序关系,所以
对于无序的先整理个顺序出来。
b. 以当前行的属性值 (value) 为参考,向周围扩散一定的值范围。
其实这也没有什么特别,比较符合人们的思考方式!
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html

https://jaceklaskowski.gitbooks.io/mastering-spark-sql/spark-sql-RelationalGroupedDataset.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号