LVS详解
一、LVS介绍
简介
通用体系结构
LVS集群采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服 务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序,以下是体系结构图(来源http://www.linuxvirtualserver.org/architecture.html):
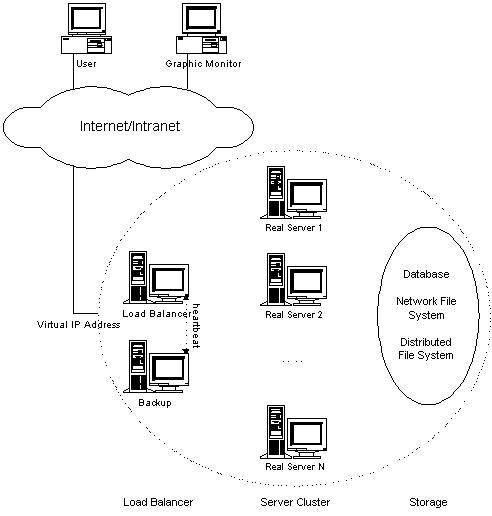
- 负载调度器(load balancer),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行。
- 服务器池(server pool),是一组真正执行客户请求的服务器,可以是WEB、MAIL、FTP和DNS服务器等。
- 共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务,例如数据库、分布式文件系统、网络存储等。
优缺点
- 高并发连接:LVS基于内核网络层面工作,有超强的承载能力和并发处理能力。单台LVS负载均衡器,可支持上万并发连接。稳定性强:是工作在网络4层之上仅作分发之用,这个特点也决定了它在负载均衡软件里的性能最强,稳定性最好,对内存和cpu资源消耗极低。
- 成本低廉:硬件负载均衡器少则十几万,多则几十万上百万,LVS只需一台服务器和就能免费部署使用,性价比极高。
- 配置简单:LVS配置非常简单,仅需几行命令即可完成配置,也可写成脚本进行管理。
- 支持多种算法:支持8种负载均衡算法,可根据业务场景灵活调配进行使用。
- 支持多种工作模型:可根据业务场景,使用不同的工作模式来解决生产环境请求处理问题。
- 应用范围广:因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、数据库、DNS、ftp服务等等。
- 缺点:工作在4层,不支持7层规则修改,机制过于庞大,不适合小规模应用。
组件和专业术语
- ipvsadm:用户空间的客户端工具,用于管理集群服务及集群服务上的RS等;
- ipvs:工作于内核上的netfilter INPUT钩子之上的程序,可根据用户定义的集群实现请求转发;
- VS:Virtual Server ,虚拟服务
- Director: Balancer ,也叫DS(Director Server)负载均衡器、分发器
- RS:Real Server ,后端请求处理服务器,真实服务器
- CIP: Client IP ,客户端IP
- VIP:Director Virtual IP ,负载均衡器虚拟IP
- DIP:Director IP ,负载均衡器IP
- RIP:Real Server IP ,后端请求处理的服务器IP
工作模型
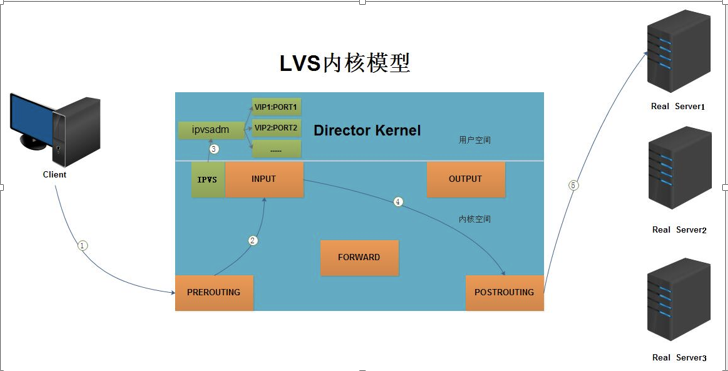
- 当客户端的请求到达负载均衡器的内核空间时,首先会到达PREROUTING链。
- 当内核发现请求数据包的目的地址是本机时,将数据包送往INPUT链。
- LVS由用户空间的ipvsadm和内核空间的IPVS组成,ipvsadm用来定义规则,IPVS利用ipvsadm定义的规则工作,IPVS工作在INPUT链上,当数据包到达INPUT链时,首先会被IPVS检查,如果数据包里面的目的地址及端口没有在规则里面,那么这条数据包将被放行至用户空间。
- 如果数据包里面的目的地址及端口在规则里面,那么这条数据报文将被修改目的地址为事先定义好的后端服务器,并送往POSTROUTING链。
- 最后经由POSTROUTING链发往后端服务器。
二、负载均衡模式
LVS-NAT模式
简介
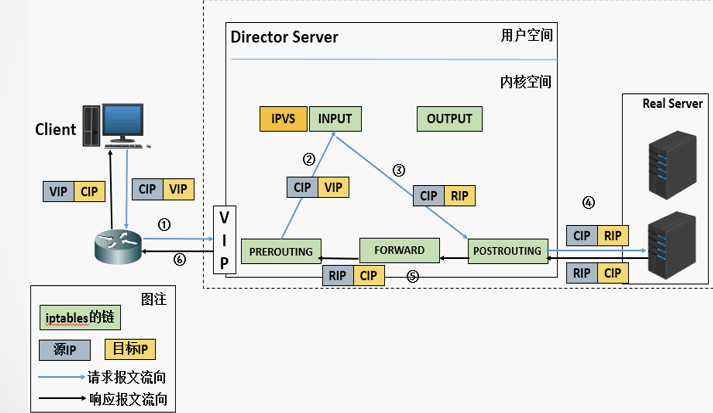
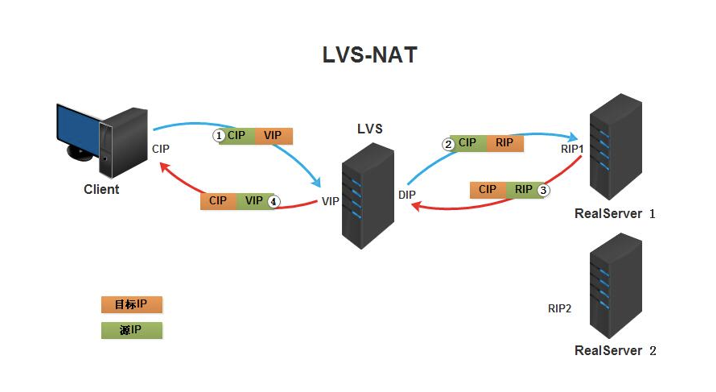
NAT模式称为全称Virtualserver via Network address translation(VS/NAT),是通过网络地址转换的方法来实现调度的。首先调度器(Director)接收到客户的请求数据包时(请求的目的IP为VIP),根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后调度就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP),这样真实服务器(RS)就能够接收到客户的请求数据包了。真实服务器响应完请求后,查看默认路由(NAT模式下我们需要把RS的默认路由设置为DS服务器。)把响应后的数据包发送给DS,DS再接收到响应包后,把包的源地址改成虚拟地址(VIP)然后发送回给客户端。
具体工作流程:
说明:
- NAT技术将请求的报文和响应的报文都需要通过DS进行地址改写,因此网站访问量比较大的时候DS负载均衡调度器有比较大的瓶颈,一般要求最多之能10-20台节点。
- 节省IP,只需要在DS上配置一个公网IP地址就可以了。
- 每台内部的节点服务器的网关地址必须是调度器LB的内网地址。
- NAT模式支持对IP地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致。
LVS-DR模式
简介
全称:Virtual Server via Direct Routing(VS-DR),也叫直接路由模式,用直接路由技术实现虚拟服务器。当参与集群的计算机和作为控制管理的计算机在同一个网段时可以用此方法,控制管理的计算机接收到请求包时直接送到参与集群的节点。直接路由模式比较特别,很难说和什么方面相似,前种模式基本上都是工作在网络层上(三层),而直接路由模式则应该是工作在数据链路层上(二层)。
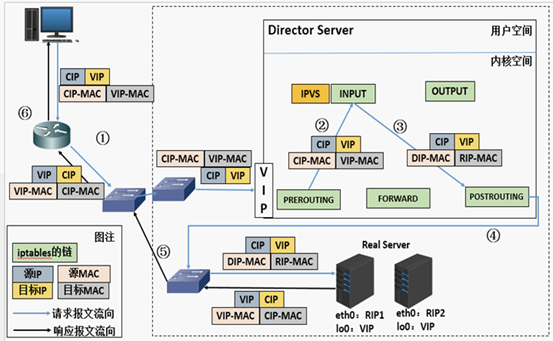
说明:
- 当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。 此时报文的源IP为CIP,目标IP为VIP;
- PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链;
- IPVS比对数据包请求的服务是否为集群服务,若是,将请求报文中的源MAC地址修改为DIP的MAC地址,将目标MAC地址修改RIP的MAC地址,然后将数据包发至POSTROUTING链。 此时的源IP和目的IP均未修改,仅修改了源MAC地址为DIP的MAC地址,目标MAC地址为RIP的MAC地址;
- 由于DS和RS在同一个网络中,所以是通过二层,数据链路层来传输。POSTROUTING链检查目标MAC地址为RIP的MAC地址,那么此时数据包将会发至Real Server;
- RS发现请求报文的MAC地址是自己的MAC地址,就接收此报文。处理完成之后,将响应报文通过lo接口传送给eth0网卡然后向外发出。 此时的源IP地址为VIP,目标IP为CIP;
- 响应报文最终送达至客户端。
地址变化过程
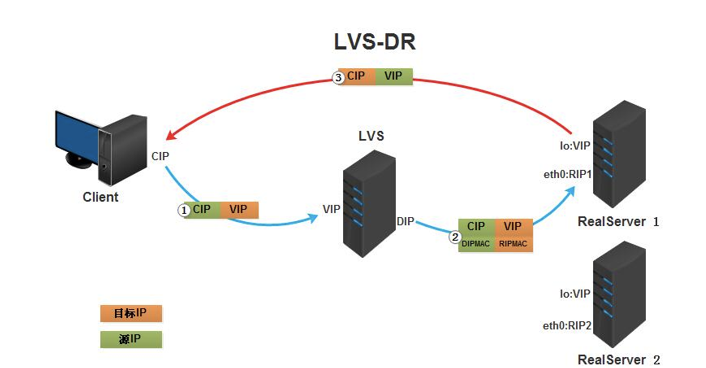
DR模式特点以及注意事项:
- 在前端路由器做静态地址路由绑定,将对于VIP的地址仅路由到Director Server
- 在arp的层次上实现在ARP解析时做防火墙规则,过滤RS响应ARP请求。修改RS上内核参数(arp_ignore和arp_announce)将RS上的VIP配置在网卡接口的别名上,并限制其不能响应对VIP地址解析请求。
- RS可以使用私有地址;但也可以使用公网地址,此时可以直接通过互联网连入RS以实现配置、监控等;
- RS的网关一定不能指向DIP;
- 因为DR模式是通过MAC地址改写机制实现转发,RS跟Dirctory要在同一物理网络内(不能由路由器分隔);
- 请求报文经过Directory,但响应报文一定不经过Director
- 不支持端口映射;
- RS可以使用大多数的操作系统;
- RS上的lo接口配置VIP的IP地址;
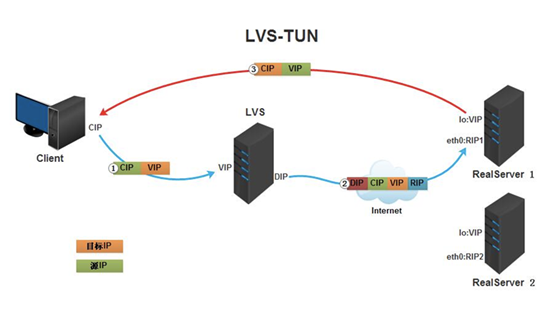
LVS- UN模式
介绍
- 客户端将请求发往前端的负载均衡器,请求报文源地址是CIP,目标地址为VIP。
- 负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将在客户端请求报文的首部再封装一层IP报文,将源地址改为DIP,目标地址改为RIP,并将此包发送给RS。
- RS收到请求报文后,会首先拆开第一层封装,然后发现里面还有一层IP首部的目标地址是自己lo接口上的VIP,所以会处理次请求报文,并将响应报文通过lo接口送给eth0网卡直接发送给客户端。注意:需要设置lo接口的VIP不能在共网上出现
地址变化过程
FULL-NAT模式
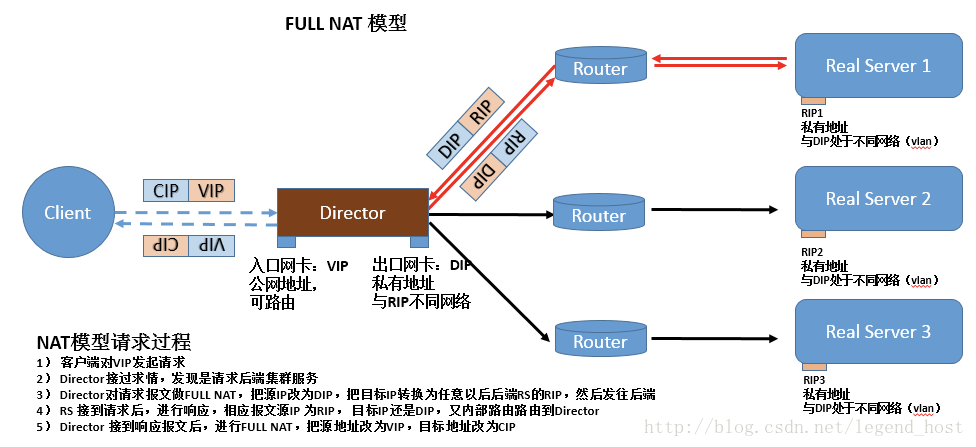
- 首先client 发送请求package给VIP;
- VIP 收到package后,会根据LVS设置的LB算法选择一个合适的RS,然后把package 的目地址修改为RS的ip地址,把源地址改成DS的ip地址;
- RS收到这个package后发现目标地址是自己,就处理这个package ,处理完后把这个包发送给DS;
- DS收到这个package 后把源地址改成VIP的IP,目的地址改成CIP(客户端ip),然后发送给客户端;
- RIP,DIP可以使用私有地址;
- RIP和DIP可以不再同一个网络中,且RIP的网关未必需要指向DIP;
- 支持端口映射;
- RS的OS可以使用任意类型;
- 请求报文经由Director,响应报文也经由Director;
- FULL-NAT因为要经过4次NAT,所以性能比NAT还要低;
- 由于做了源地址转换,RS无法获取到客户端的真实IP;
各个模式的区别
三、调度算法
- 轮叫调度rr(Round-Robin Scheduling)
- 加权轮叫调度wrr(Weighted Round-Robin Scheduling)
- 最小连接调度lc(Least-Connection Scheduling)
- 加权最小连接调度wlc(Weighted Least-Connection Scheduling)
- 基于局部性的最少链接LBLC(Locality-Based Least Connections Scheduling)
- 带复制的基于局部性最少链接LBLCR(Locality-Based Least Connections with Replication Scheduling)
- 目标地址散列调度DH(Destination Hashing Scheduling)
- 源地址散列调度SH(Source Hashing Scheduling)
rr(轮询)
wrr(权重, 即加权轮询)
sh(源地址哈希)
dh(目的地址哈希)
lc(最少链接)
wlc(加权最少链接)LVS的理想算法
LBLC(基于局部性的最少连接)
LBLCR(带复制的基于局部性的最少链接)
四、管理工具ipvsadm使用
ipvsadm是LVS的管理工具,ipvsadm工作在用户空间,用户通过ipvsadm命令编写负载均衡规则。
安装
yum install ipvsadm -y ###文件说明 Unit 文件: ipvsadm.service 主程序:/usr/sbin/ipvsadm 规则保存工具:/usr/sbin/ipvsadm-save 规则重载工具:/usr/sbin/ipvsadm-restore 配置文件:/etc/sysconfig/ipvsadm-config
用法以及参数
ipvsadm --help #查看使用方法及参数 命令: -A, --add-service: #添加一个集群服务. 即为ipvs虚拟服务器添加一个虚拟服务,也就是添加一个需要被负载均衡的虚拟地址。虚拟地址需要是ip地址,端口号,协议的形式。 -E, --edit-service: #修改一个虚拟服务。 -D, --delete-service: #删除一个虚拟服务。即删除指定的集群服务; -C, --clear: #清除所有虚拟服务。 -R, --restore: #从标准输入获取ipvsadm命令。一般结合下边的-S使用。 -S, --save: #从标准输出输出虚拟服务器的规则。可以将虚拟服务器的规则保存,在以后通过-R直接读入,以实现自动化配置。 -a, --add-server: #为虚拟服务添加一个real server(RS) -e, --edit-server: #修改RS -d, --delete-server: #删除 -L, -l, --list: #列出虚拟服务表中的所有虚拟服务。可以指定地址。添加-c显示连接表。 -Z, --zero: #将所有数据相关的记录清零。这些记录一般用于调度策略。 --set tcp tcpfin udp: #修改协议的超时时间。 --start-daemon state: #设置虚拟服务器的备服务器,用来实现主备服务器冗余。(注:该功能只支持ipv4) --stop-daemon: #停止备服务器。 参数: 以下参数可以接在上边的命令后边。 -t, --tcp-service service-address: #指定虚拟服务为tcp服务。service-address要是host[:port]的形式。端口是0表示任意端口。如果需要将端口设置为0,还需要加上-p选项(持久连接)。 -u, --udp-service service-address: #使用udp服务,其他同上。 -f, --fwmark-service integer: #用firewall mark取代虚拟地址来指定要被负载均衡的数据包,可以通过这个命令实现把不同地址、端口的虚拟地址整合成一个虚拟服务,可以让虚拟服务器同时截获处理去往多个不同地址的数据包。fwmark可以通过iptables命令指定。如果用在ipv6需要加上-6。 -s, --scheduler scheduling-method: #指定调度算法,默认是wlc。调度算法可以指定以下8种:rr(轮询),wrr(权重),lc(最后连接),wlc(权重),lblc(本地最后连接),lblcr(带复制的本地最后连接),dh(目的地址哈希),sh(源地址哈希),sed(最小期望延迟),nq(永不排队) -p, --persistent [timeout]: #设置持久连接,这个模式可以使来自客户的多个请求被送到同一个真实服务器,通常用于ftp或者ssl中。 -M, --netmask netmask: #指定客户地址的子网掩码。用于将同属一个子网的客户的请求转发到相同服务器。 -r, --real-server server-address: #为虚拟服务指定数据可以转发到的真实服务器的地址。可以添加端口号。如果没有指定端口号,则等效于使用虚拟地址的端口号。 [packet-forwarding-method]: #此选项指定某个真实服务器所使用的数据转发模式。需要对每个真实服务器分别指定模式。 -g, --gatewaying: #使用网关(即直接路由),此模式是默认模式。 -i, --ipip: #使用ipip隧道模式。 -m, --masquerading: #使用NAT模式。 -w, --weight weight: #设置权重。权重是0~65535的整数。如果将某个真实服务器的权重设置为0,那么它不会收到新的连接,但是已有连接还会继续维持(这点和直接把某个真实服务器删除时不同的)。 -x, --u-threshold uthreshold: #设置一个服务器可以维持的连接上限。0~65535。设置为0表示没有上限。 -y, --l-threshold lthreshold: #设置一个服务器的连接下限。当服务器的连接数低于此值的时候服务器才可以重新接收连接。如果此值未设置,则当服务器的连接数连续三次低于uthreshold时服务器才可以接收到新的连接。 --mcast-interface interface: #指定使用备服务器时候的广播接口。 --syncid syncid:#指定syncid, 同样用于主备服务器的同步。 #以下选项用于list(-l)命令: -c, --connection: #列出当前的IPVS连接。 --timeout: #列出超时 --stats: #状态信息 --rate: #传输速率 --thresholds: #列出阈值 --persistent-conn: #持久连接 --sor: #把列表排序 --nosort: #不排序 -n, --numeric: #不对ip地址进行dns查询 --exact: #单位 -6: 如#果fwmark用的是ipv6地址需要指定此选项。 #如果使用IPv6地址,需要在地址两端加上"[]"。例如:ipvsadm -A -t [2001:db8::80]:80 -s rr
LVS集群管理示例
####管理LVS集群中的RealServer举例 1) 添加RS : -a # ipvsadm -a -t|u|f service-address -r server-address [-g|i|m] [-w weight] #举例1: 往VIP资源为10.1.210.58的集群服务里添加1个realserver ipvsadm -a -t 10.1.210.58 -r 10.1.210.52 –g -w 5 2) 修改RS : -e # ipvsadm -e -t|u|f service-address -r server-address [-g|i|m] [-w weight] #举例2: 修改10.1.210.58集群服务里10.1.210.52这个realserver的权重为3 ipvsadm -e -t 10.1.210.58:80 -r 10.1.210.52 –g -w 3 3) 删除RS : -d # ipvsadm -d -t|u|f service-address -r server-address #举例3: 删除10.1.210.58集群服务里10.1.210.52这个realserver ipvsadm -d -t 10.1.210.58:80 -r 10.1.210.52 4) 清除规则 (删除所有集群服务), 该命令与iptables的-F功能类似,执行后会清除所有规则: # ipvsadm -C 5) 保存及读取规则: # ipvsadm -S > /path/to/somefile # ipvsadm-save > /path/to/somefile # ipvsadm-restore < /path/to/somefile ####管理LVS集群服务的查看 # ipvsadm -L|l [options] options可以为: -n:数字格式显示 --stats 统计信息 --rate:统计速率 --timeout:显示tcp、tcpinfo、udp的会话超时时长 -c:连接客户端数量 #查看lvs集群转发情况 # ipvsadm -Ln #查看lvs集群的连接状态 # ipvsadm -l --stats 说明: Conns (connections scheduled) 已经转发过的连接数 InPkts (incoming packets) 入包个数 OutPkts (outgoing packets) 出包个数 InBytes (incoming bytes) 入流量(字节) OutBytes (outgoing bytes) 出流量(字节) #查看lvs集群的速率 ipvsadm -l --rate 说明: CPS (current connection rate) 每秒连接数 InPPS (current in packet rate) 每秒的入包个数 OutPPS (current out packet rate) 每秒的出包个数 InBPS (current in byte rate) 每秒入流量(字节) OutBPS (current out byte rate) 每秒入流量(字节)
五、案例篇
环境
LVS-DR模式案例
centos7默认已经将ipvs编译进内核模块,名称为ip_vs,使用时候需要先加载该内核模块。
以下步骤需要在DS上进行:
1.加载ip_vs模块
modprobe ip_vs #加载ip_vs模块 cat /proc/net/ip_vs #查看是否加载成功 lsmod | grep ip_vs #查看加载的模块 yum install ipvsadm # 安装管理工具
2.配置调度脚本dr.sh
#!/bin/bash VIP=10.1.210.58 #虚拟IP RIP1=10.1.210.52 #真实服务器IP1 RIP2=10.1.210.53 #真实服务器IP2 PORT=80 #端口 ifconfig ens192:1 $VIP broadcast $VIP netmask 255.255.255.255 up #添加VIP,注意网卡名称 echo 1 > /proc/sys/net/ipv4/ip_forward #开启转发 route add -host $VIP dev ens192:1 #添加VIP路由 /sbin/ipvsadm -C #清空ipvs中的规则 /sbin/ipvsadm -A -t $VIP:80 -s wrr #添加调度器 /sbin/ipvsadm -a -t $VIP:80 -r $RIP1 -g -w 1 #添加RS /sbin/ipvsadm -a -t $VIP:80 -r $RIP2 -g -w 1 #添加RS /sbin/ipvsadm -ln #查看规则
3.执行脚本
[root@app51 ~]# sh dr.sh IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.1.210.58:80 wrr -> 10.1.210.52:80 Route 1 0 0 -> 10.1.210.53:80 Route 1 0 0
以下步骤需要在RS上执行:
1.真实服务RS配置脚本rs.sh
#!/bin/bash VIP=10.1.210.58 #RS上VIP地址 #关闭内核arp响应,永久修改配置参数到/etc/sysctl.conf,目的是为了让rs顺利发送mac地址给客户端 echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up #绑定VIP到RS服务器上 /sbin/route add -host $VIP dev lo:0 #添加VIP路由
2.执行脚本
sh rs.sh
3.配置测试web服务(以一台为示例)
systemctl stop firewalld #关闭防火墙 systemctl disable firewalld #禁止开机启动 yum install httpd #安装httpd ###RS1虚拟主机配置 vi /etc/httpd/conf/httpd.conf ServerName 10.1.210.52:80 echo "RS 10.1.210.52" > /var/www/html/index.html ###RS2虚拟主机配置 vi /etc/httpd/conf/httpd.conf ServerName 10.1.210.53:80 echo "RS 10.1.210.53" > /var/www/html/index.html #启动httpd服务 systemctl start httpd
[root@node1 ~]# for i in {1..10} ;do curl http://10.1.210.58 ;done RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52
LVS-NAT案例
LVS-NAT模式和DR区别要做nat,并且请求和响应都要经过DS,所有需要将RS网关指向DS,由于之前测试过DR模式,在测试NAT模式时候需要将RS环境恢复,RS恢复步骤如下:
echo 0 >/proc/sys/net/ipv4/conf/lo/arp_ignore echo 0 >/proc/sys/net/ipv4/conf/lo/arp_announce echo 0 >/proc/sys/net/ipv4/conf/all/arp_ignore echo 0 >/proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 down
调度服务DS配置
#!/bin/bash VIP=10.1.210.58 #虚拟IP RIP1=10.1.210.52 #真实服务器IP1 RIP2=10.1.210.53 #真实服务器IP2 PORT=80 #端口 ifconfig ens192:1 $VIP broadcast $VIP netmask 255.255.255.255 up #添加VIP echo 1 > /proc/sys/net/ipv4/ip_forward #开启转发 route add -host $VIP dev ens192:1 #添加VIP路由 /sbin/ipvsadm -C #清空ipvs中的规则 /sbin/ipvsadm -A -t $VIP:80 -s wlc #添加调度器 /sbin/ipvsadm -a -t $VIP:80 -r $RIP1 -m -w 1 #添加RS /sbin/ipvsadm -a -t $VIP:80 -r $RIP2 -m -w 1 #添加RS /sbin/ipvsadm -ln #查看规则
RS配置
nat模式RS配置很简单,只需要将RS路由指向DS
vi /etc/sysconfig/network-scripts/ifcfg-ens192 GATEWAY=10.1.210.58 #修改网关至RS地址 systemctl restart network #重启网络
测试
由于这里的环境DS和RS在同一个网段下,NAT模式下如果客户端是同网段情况下,RS响应的时候直接响应给同网段的服务器了并不经过DS,这样就导致客户端会丢弃该请求。如果想要同网段的想要访问到DS则需要添加路由,这里需要RS在响应同网段服务器时候网关指向DS,这样同网段就能访问到DS了,示例:
route add -net 10.1.210.0/24 gw 10.1.210.58
测试结果:
[root@app36 ~]# for i in {1..10} ; do curl http://10.1.210.58 ;done RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52 RS 10.1.210.53 RS 10.1.210.52
六、持久连接
什么是持久连接
在LVS中,持久连接是为了用来保证当来自同一个用户的请求时能够定位到同一台服务器,目的是为了会话保持,而通常使用的会话保持技术手段就是cookie与session。
cookie与session简述
在Web服务通信中,HTTP本身是无状态协议,不能标识用户来源,当用户在访问A网页,再从A网页访问其他资源跳转到了B网页,这对于服务器来说又是一个新的请求,之前的登陆信息都没有了,怎么办?为了记录用户的身份信息,开发者在浏览器和服务器之间提供了cookie和session技术,简单说来在你浏览网页时候,服务器建立session用于保存你的身份信息,并将与之对应的cookie信息发送给浏览器,浏览器保存cookie,当你再次浏览该网页时候,服务器检查你的浏览器中的cookie并获取与之对应的session数据,这样一来你上次浏览网页的数据依然存在。
4层均衡负载导致的问题
- 将来自于同一个用户的请求发往同一个服务器(例如nginx的ip_hash算法);
- 将session信息在服务器集群内共享,每个服务器都保存整个集群的session信息;
- 建立一个session存,所有session信息都保存到存储池中 ;
LVS会话保持实现方式就是通过将来自于同一个用户的请求发往同一个服务器,具体实现分为sh算法和持久连接:
LVS的三种持久连接方式
示例
LVS的持久连接功能需要定义在集群服务上面,使用-p timeout选项。
PPC:
[root@localhost ~]# ipvsadm -At 10.1.210.58:80 -s rr -p 300 #上面命令的意思是:添加一个集群服务为10.1.210.58:80,使用的调度算法为rr,持久连接的保持时间是300秒。当超过300秒都没有请求时,则清空LVS的持久连接模板。
PCC:
# ipvsadm -A -t 10.1.210.58:0 -s rr -p 600 # ipvsadm -a -t 10.1.210.58:0 -r 10.1.210.52 -g -w 2 # ipvsadm -a -t 10.1.210.58:0 -r 0.1.210.53 -g -w 1
PFMC:
######PNMPP是通过路由前给数据包打标记来实现的 # iptables -t mangle -A PREROUTING -d 10.1.210.58 -ens192 -p tcp --dport 80 -j MARK --set-mark 3 # iptables -t mangle -A PREROUTING -d 10.1.210.58 -ens192 -p tcp --dport 443 -j MARK --set-mark 3 # ipvsadm -A -f 3 -s rr -p 600 # ipvsadm -a -f 3 -r 10.1.210.52 -g -w 2 # ipvsadm -a -f 3 -r 10.1.210.52 -g -w 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号