

[python爬虫]爬取人口普查数据分析云南性别歧视/教育问题
之所以做这个东西是因为在NGA上看到了张桂梅校长相关的讨论,有些网友以“张校长用国家的钱建女校,是否有违性别公平“”身边读过书的女孩子数量远多于男孩子“等理由抨击张校长,本着没有调查就没有发言权的原则,我爬取了2010年(为什么不选2020年的原因是想调查更早之前云南省的情况),并做了些数据可视化。先放上结论:女性的受教育人口远低于男性,建女校的钱没白花,而且还需加大投入。
数据来源:http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/indexch.htm
首先是爬虫部分:
1 import json 2 import requests 3 from requests.exceptions import RequestException 4 import re 5 import time 6 7 def get_one_page(url): 8 try: 9 headers = { 10 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36' 11 } 12 response = requests.get(url, headers=headers) 13 if response.status_code == 200: 14 return response.content.decode('ANSI') 15 return None 16 except RequestException: 17 return None 18 19 url = 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/left.htm' 20 21 html = get_one_page(url)
这里把url改成http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/left.htm,获取左侧索引栏
下载数据:
1 from bs4 import BeautifulSoup 2 3 soup = BeautifulSoup(html,'lxml') 4 5 soup.prettify() 6 data_name_list = [] 7 data_xls_list = [] 8 pre_url = 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/' 9 for ul in soup.find_all('ul'): 10 for li in ul.find_all(name='li'): 11 a = li.a 12 #数据格式为xls,去掉其他的 13 if a != None and a.attrs['href'][-1] != 'm': 14 data_name_list.append(li.get_text()) 15 data_xls_list.append(pre_url + a.attrs['href']) 16 17 import urllib 18 import os 19 path = 'C:\\Users\\00\\Desktop\\census_data\\' 20 i = 0 21 for url in data_xls_list: 22 print(url) 23 filename = os.path.join(path, data_name_list[i] + '.xls') 24 urllib.request.urlretrieve(url, filename) 25 i += 1
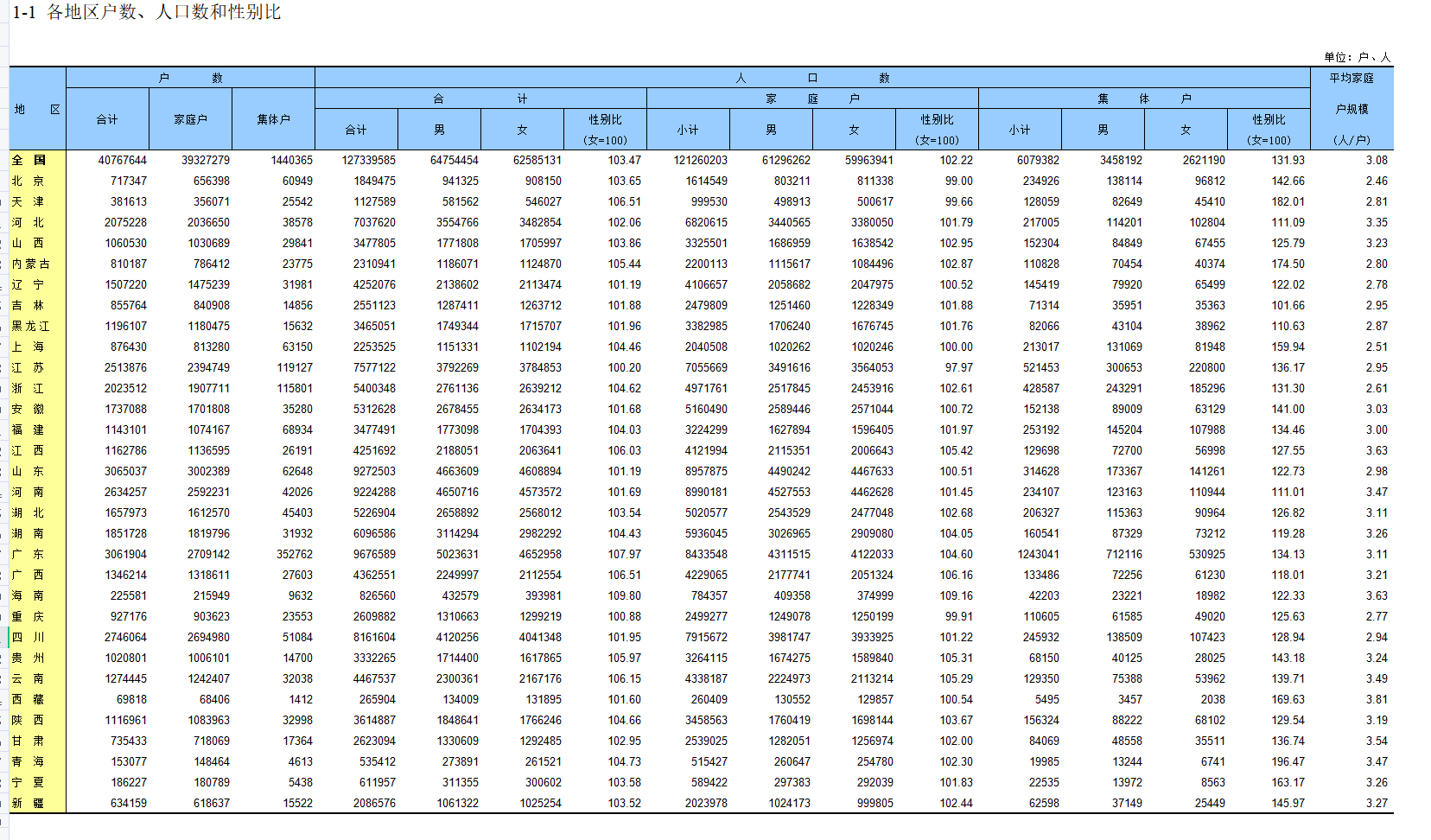
爬下来的数据如图所示:

用pandas读取后有一些无用的行,删除之:
1 import pandas as pd 2 path = 'C:\\Users\\00\\Desktop\\census_data\\' 3 xls_path = path + '1-1 各地区户数、人口数和性别比.xls' 4 df=pd.read_excel(xls_path,sheet_name=0,header=None) 5 6 for i in range(7): 7 df = df.drop(i,axis=0) 8 df = df.reset_index() 9 10 del df['index'] 11 12 df

列命名:
1 new_col = ['地区','户数合计','家庭户合计','集体户合计','人口总数', 2 '男性总数','女性总数','性别比','家庭户人口数','家庭户男性总数', 3 '家庭户女性总数','家庭户性别比','集体户人口数','集体户男性总数', 4 '集体户女性总数','集体户性别比','平均户规模'] 5 df.columns = new_col 6 7 df.info()

全国人口性别比可视化:
1 import matplotlib.pyplot as plt 2 %matplotlib inline 3 4 df1 = df 5 df1 = df1.drop(0,axis=0) 6 df1 7 8 import seaborn as sns 9 import numpy as np 10 bar_width = 0.4 11 plt.rcParams['font.sans-serif']=['SimHei'] 12 plt.rcParams['axes.unicode_minus']=False 13 plt.bar(np.arange(len(df1))-0.2,df1['男性总数'],width=0.4,label='男性总数') 14 plt.bar(np.arange(len(df1))+bar_width-0.2,df1['女性总数'],width=0.4,label='女性总数') 15 plt.xticks(np.arange(len(df1)),df1['地区']) 16 fig = plt.gcf() 17 fig.set_size_inches(20, 10) 18 plt.title('全国人口性别比',fontdict = {'fontsize' : 30}) 19 plt.tick_params(labelsize=10) 20 plt.tight_layout() 21 plt.legend()
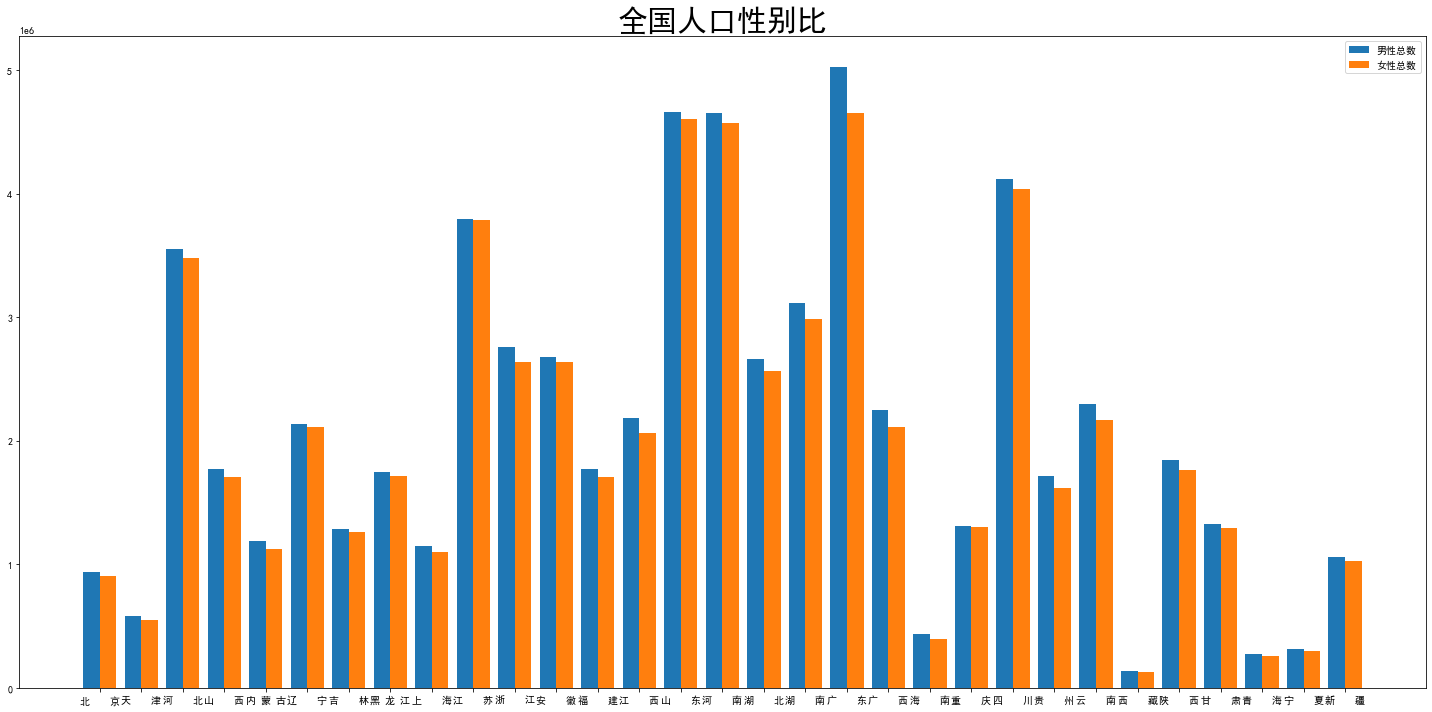
后面全是数据可视化处理了


df1 = df1.sort_values(by=['性别比'],ascending=True,axis=0) df1 = df1.reset_index() df1 = df1.drop('index',axis=1) plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(np.arange(len(df1)),df1['性别比']/100,label='性别比') plt.ylim(1, 1.1) plt.xticks(np.arange(len(df1)),df1['地区']) fig = plt.gcf() fig.set_size_inches(20, 10) plt.title('全国人口性别比',fontdict = {'fontsize' : 30}) plt.tight_layout() plt.legend()
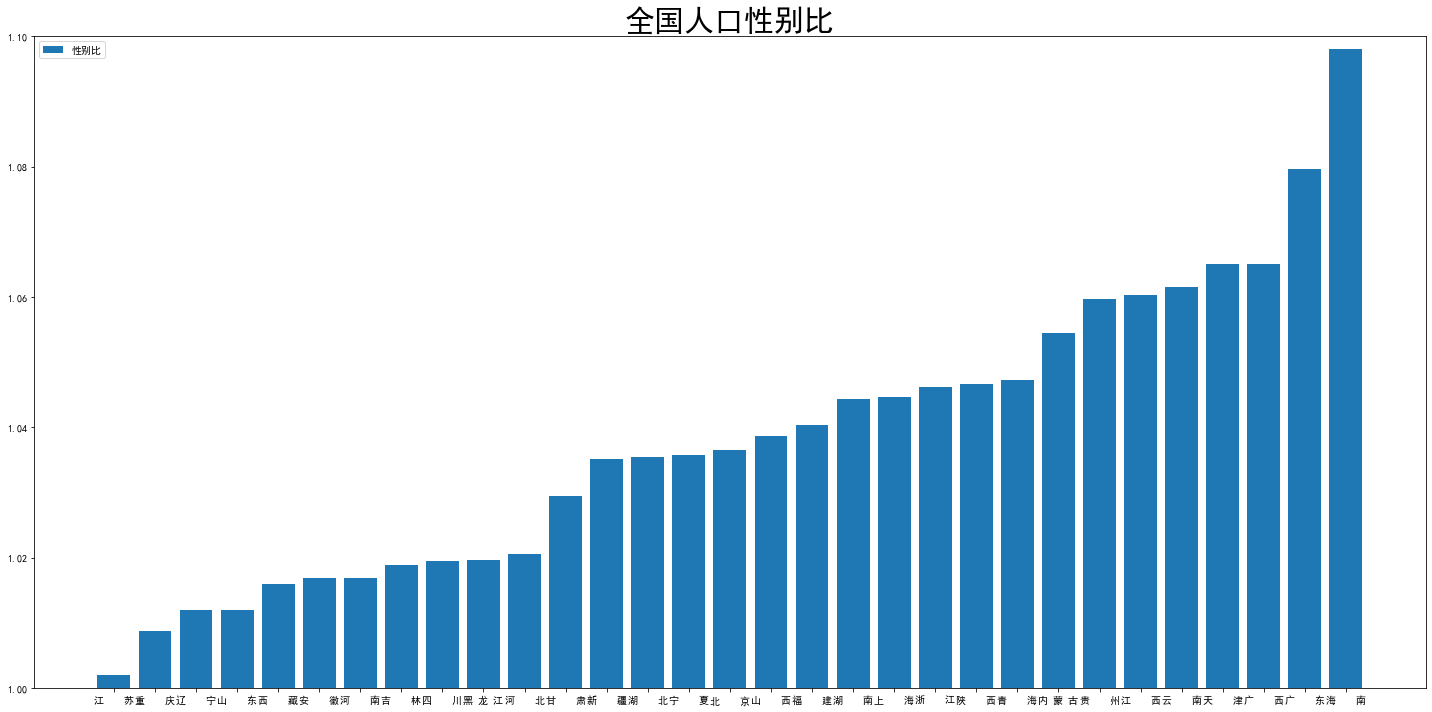
云南性别失衡还挺严重的,不过性别失衡似乎与经济关系不大,广东、北京、上海、江苏等经济发达地区的性别失衡状态差距挺大的
bar_width = 0.4 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(np.arange(len(df1))-0.2,df1['家庭户性别比']/100,width=0.4,label='家庭户性别比') plt.bar(np.arange(len(df1))+bar_width-0.2,df1['集体户性别比']/100,width=0.4,label='集体户性别比') plt.xticks(np.arange(len(df1)),df1['地区']) plt.ylim(0.9, 2) fig = plt.gcf() fig.set_size_inches(20, 10) plt.plot([-1,len(df1)],[1,1]) plt.title('全国人口性别比(家庭户/集体户)',fontdict = {'fontsize' : 30}) plt.tight_layout() plt.legend()
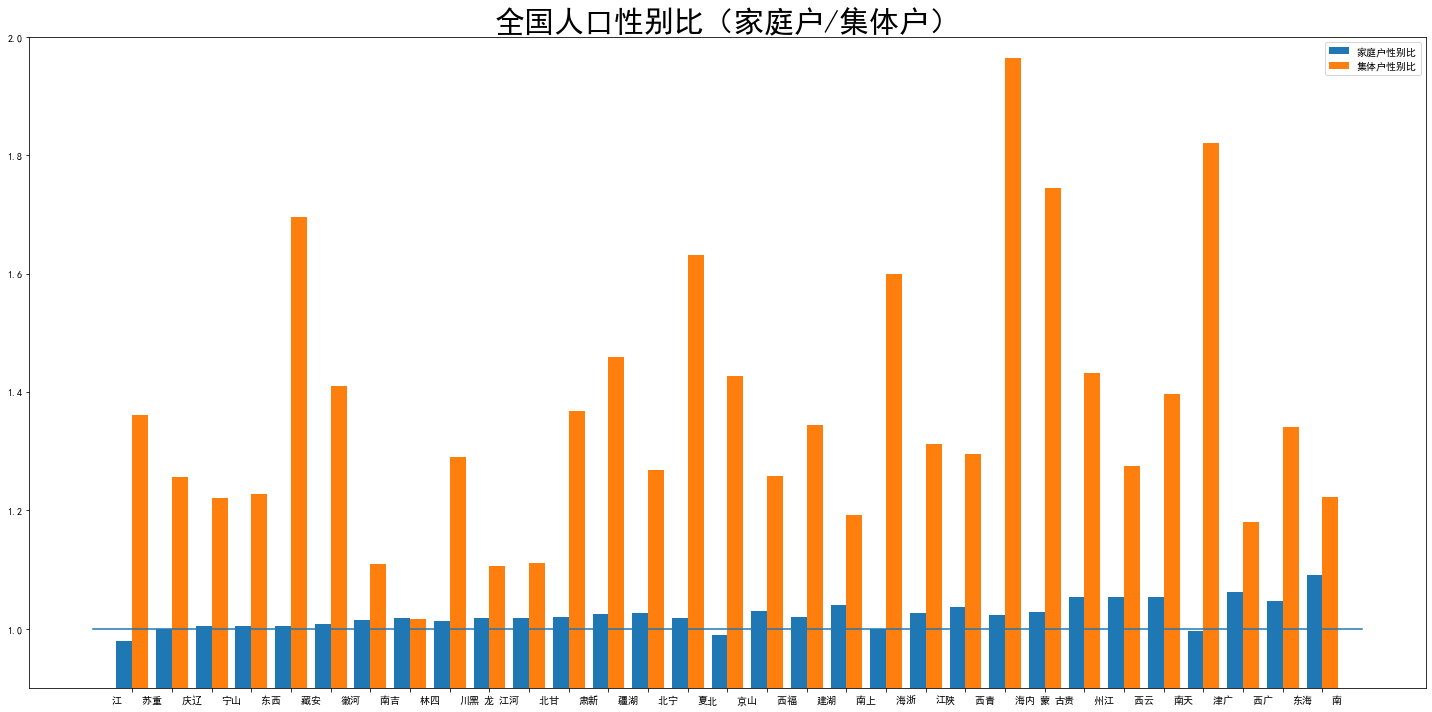
集体户主要反映外来人口情况,看来男性更倾向于出省打工?
import pandas as pd xls_path = path + '1-7 各地区分年龄、性别的人口.xls' df1=pd.read_excel(xls_path,sheet_name=0,header=None) for i in range(5): df1 = df1.drop(i,axis=0) df1 = df1.reset_index() df1 = df1.drop('index',axis=1) new_col = ['地区','人口总数','男性总数','女性总数','0岁人口总数','0岁男性总数','0岁女性总数'] for i in range(1): new_col.append(str(i*4+1) + '-' + str(i*4+4) + '岁人口总数') new_col.append(str(i*4+1) + '-' + str(i*4+4) + '岁男性总数') new_col.append(str(i*4+1) + '-' + str(i*4+4) + '岁女性总数') for i in range(1,20): new_col.append(str(i*5) + '-' + str(i*5+4) + '岁人口总数') new_col.append(str(i*5) + '-' + str(i*5+4) + '岁男性总数') new_col.append(str(i*5) + '-' + str(i*5+4) + '岁女性总数') new_col.append('100岁以上人口总数') new_col.append('100岁以上男性人口总数') new_col.append('100岁以上女性人口总数') df1.columns = new_col xticks = ['0岁'] for i in range(1): xticks.append(str(i*4+1) + '-' + str(i*4+4) + '岁') for i in range(1,20): xticks.append(str(i*5) + '-' + str(i*5+4) + '岁') xticks.append('100岁以上') xinbiebi = [] for i in range(22): xinbiebi.append(df1.iloc[0,i*3+5]/df1.iloc[0,i*3+6]) yunnanxinbiebi = [] for i in range(22): yunnanxinbiebi.append(df1.iloc[25,i*3+5]/df1.iloc[25,i*3+6]) plt.plot(xticks, xinbiebi,label='全国人口性别比') plt.plot(xticks, yunnanxinbiebi,label='云南人口性别比') fig = plt.gcf() fig.set_size_inches(20, 10) plt.tight_layout() plt.title('人口性别比',fontdict = {'fontsize' : 30}) plt.tick_params(labelsize=15) plt.plot([-1,len(xticks)],[1,1]) plt.legend()
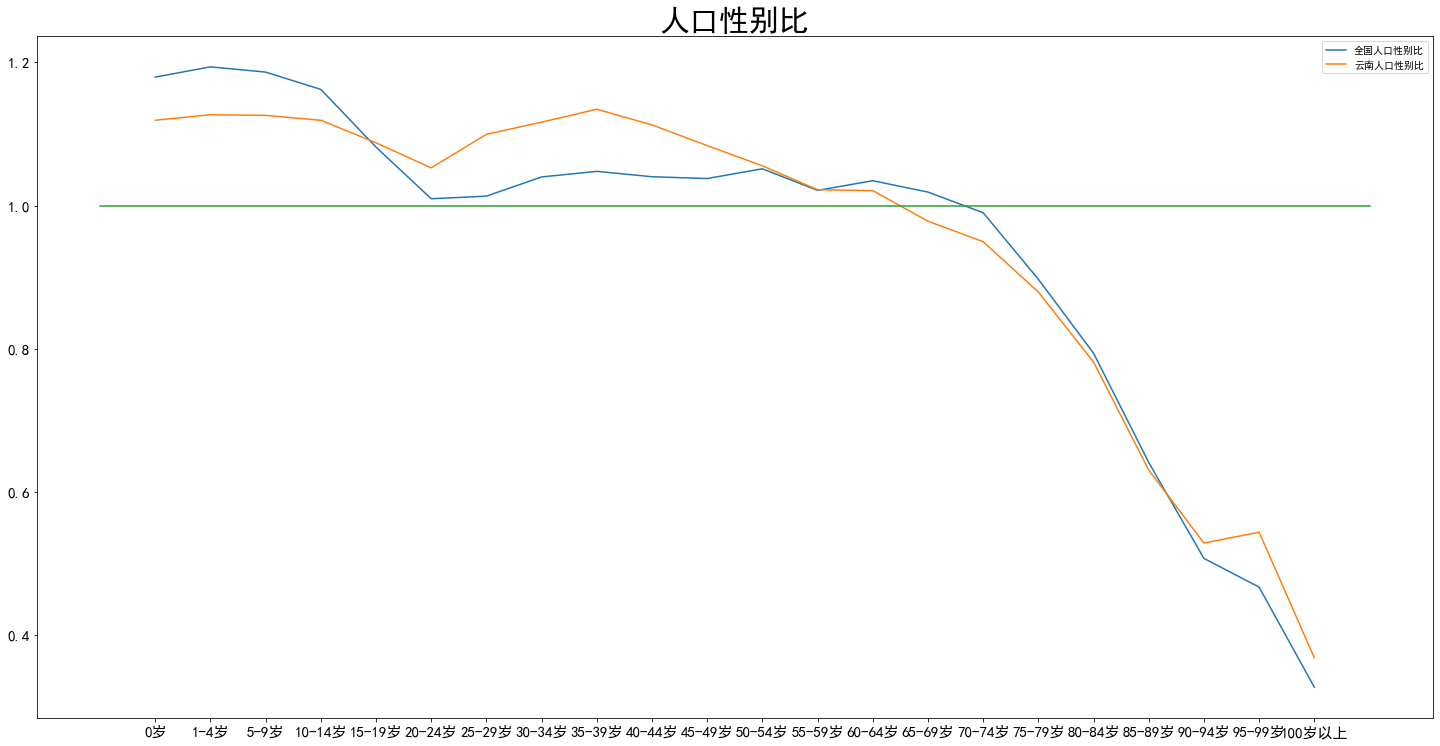
据说女性寿命比男性长4年左右,并且战争时代男性死亡数应该比女性多,所以老龄人口女性比较多;建国之后男性人口数就开始反超并拉开差距了
xls_path = path + '1-8 各地区分性别、受教育程度的6岁及以上人口.xls' df2 = pd.read_excel(xls_path,sheet_name=0,header=None) for i in range(5): df2 = df2.drop(i,axis=0) df2 = df2.reset_index() df2 = df2.drop('index',axis=1) new_col = ['地区','6岁以上人口总数','6岁以上男性总数','6岁以上女性总数', '未上过学人口总数','未上过学男性总数','未上过学女性总数', '小学人口总数','小学男性总数','小学女性总数', '初中人口总数','初中男性总数','初中女性总数', '高中人口总数','高中男性总数','高中女性总数', '专科人口总数','专科男性总数','专科女性总数', '本科人口总数','本科男性总数','本科女性总数', '研究生人口总数','研究生男性总数','研究生女性总数',] df2.columns = new_col xticks = ['未上过学','小学','初中','高中','专科','本科','研究生',] xinbiebi = [] for i in range(len(xticks)): xinbiebi.append(df2.iloc[0,i*3+5]/df2.iloc[0,i*3+6]) yunnanxinbiebi = [] for i in range(len(xticks)): yunnanxinbiebi.append(df2.iloc[25,i*3+5]/df2.iloc[25,i*3+6]) bar_width = 0.4 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(np.arange(len(xinbiebi))-0.2,xinbiebi,width=0.4,label='全国教育人口性别比') plt.bar(np.arange(len(xinbiebi))+bar_width-0.2,yunnanxinbiebi,width=0.4,label='云南教育人口性别比') plt.xticks(np.arange(len(xticks)),xticks) fig = plt.gcf() plt.title('全国教育人口性别比(以女性为基数)',fontdict = {'fontsize' : 30}) plt.plot([-1,len(xinbiebi)],[1,1]) fig.set_size_inches(20, 10) plt.tick_params(labelsize=25) plt.tight_layout() plt.legend()
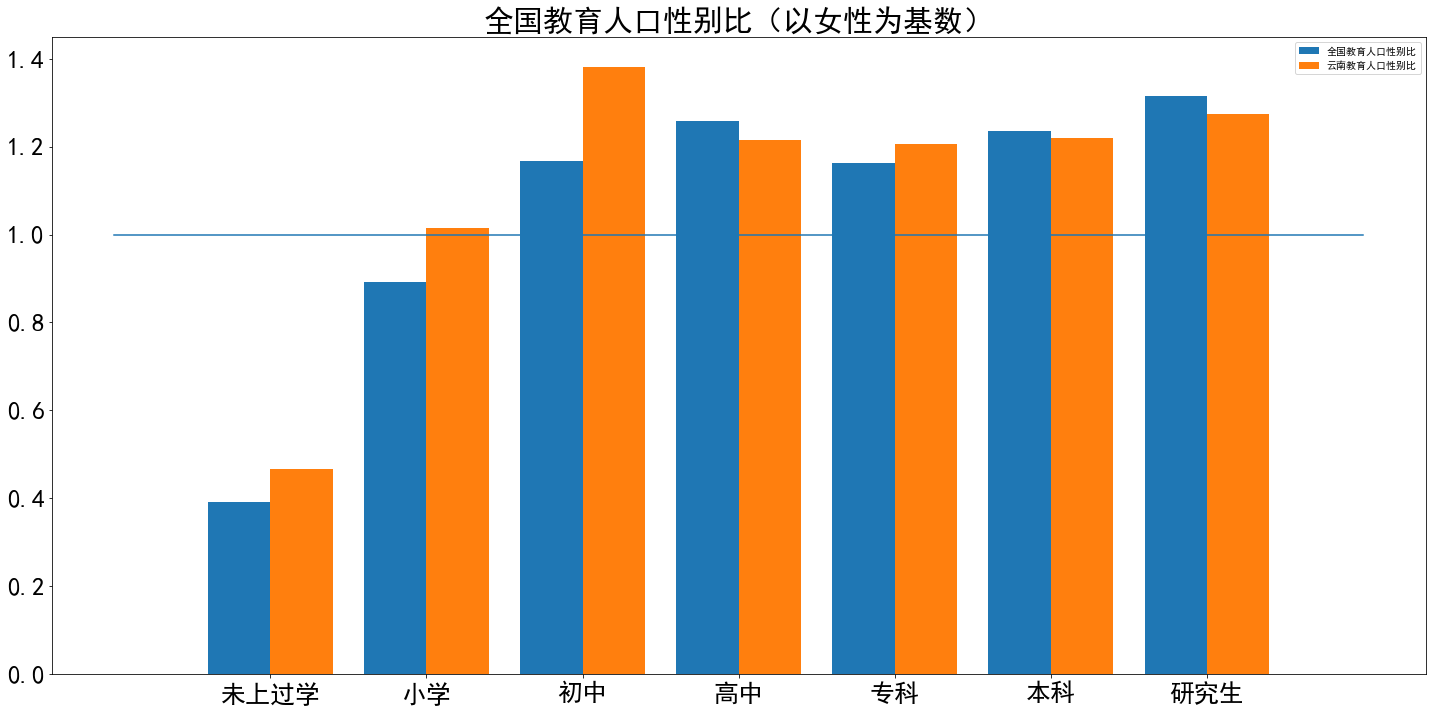
很明显男性受教育人口远超女性,身边统计学可以休矣!但这是不是由于男性人口较多导致的还需再验证
1 xticks = ['未上过学','小学','初中','高中','专科','本科','研究生',] 2 3 xinbiebi = [] 4 for i in range(len(xticks)): 5 xinbiebi.append(df2.iloc[25,i*3+5]) 6 yunnanxinbiebi = [] 7 for i in range(len(xticks)): 8 yunnanxinbiebi.append(df2.iloc[25,i*3+6]) 9 10 bar_width = 0.4 11 plt.rcParams['font.sans-serif']=['SimHei'] 12 plt.rcParams['axes.unicode_minus']=False 13 plt.bar(np.arange(len(xinbiebi))-0.2,xinbiebi,width=0.4,label='男') 14 plt.bar(np.arange(len(xinbiebi))+bar_width-0.2,yunnanxinbiebi,width=0.4,label='女') 15 plt.xticks(np.arange(len(xticks)),xticks) 16 fig = plt.gcf() 17 plt.title('云南教育人口(分性别)',fontdict = {'fontsize' : 30}) 18 plt.plot([-1,len(xinbiebi)],[1,1]) 19 fig.set_size_inches(20, 10) 20 plt.tick_params(labelsize=25) 21 plt.tight_layout() 22 plt.legend()
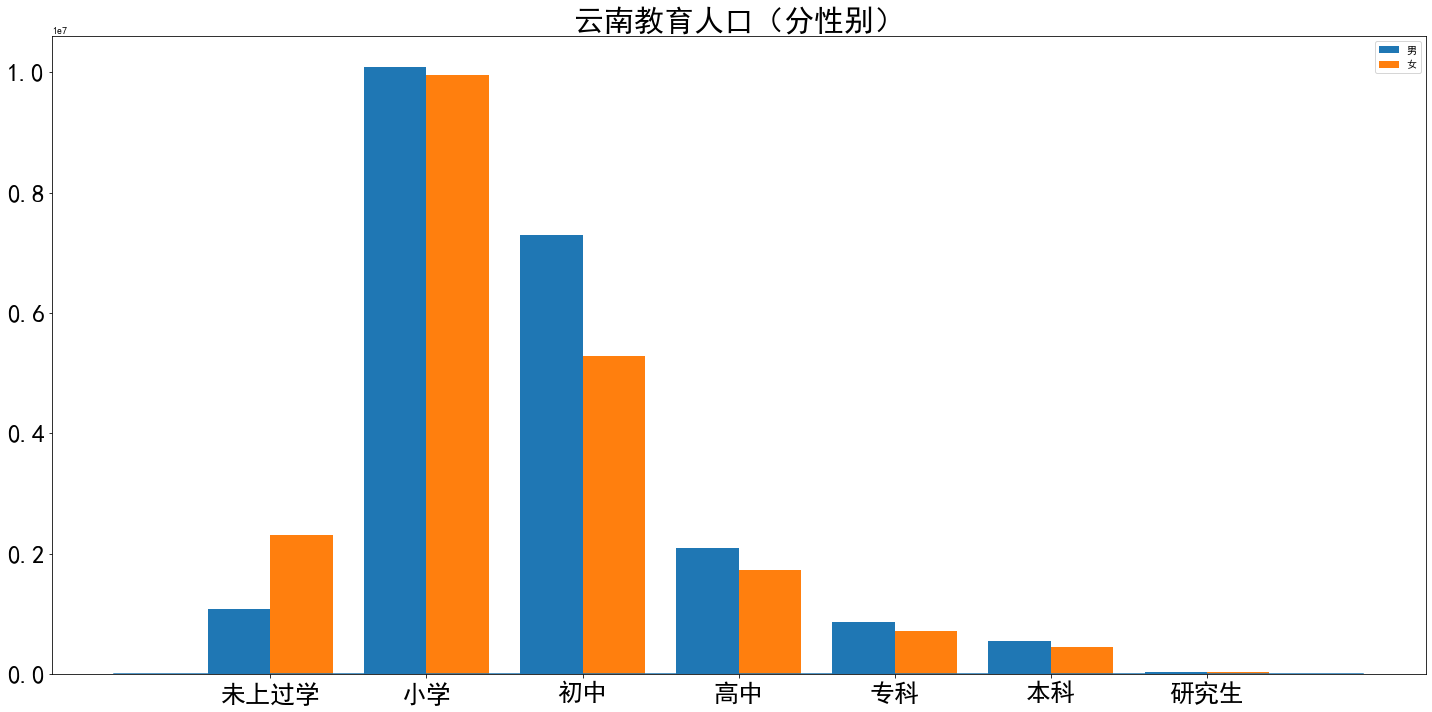
想要妇女撑起半边天,还得先从娃娃的教育抓起啊~未受过教育人口女性是男性的两倍,经济实力又与受教育程度、家庭地位相挂钩,所以加大教育投入势在必行~
xticks = ['未上过学','小学','初中','高中','专科','本科','研究生',] xinbiebi = [] for i in range(len(xticks)): xinbiebi.append(df2.iloc[0,i*3+5]) yunnanxinbiebi = [] for i in range(len(xticks)): yunnanxinbiebi.append(df2.iloc[0,i*3+6]) bar_width = 0.4 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(np.arange(len(xinbiebi))-0.2,xinbiebi,width=0.4,label='男') plt.bar(np.arange(len(xinbiebi))+bar_width-0.2,yunnanxinbiebi,width=0.4,label='女') plt.xticks(np.arange(len(xticks)),xticks) fig = plt.gcf() plt.title('全国教育人口(分性别)',fontdict = {'fontsize' : 30}) plt.plot([-1,len(xinbiebi)],[1,1]) fig.set_size_inches(20, 10) plt.tick_params(labelsize=25) plt.tight_layout() plt.legend()
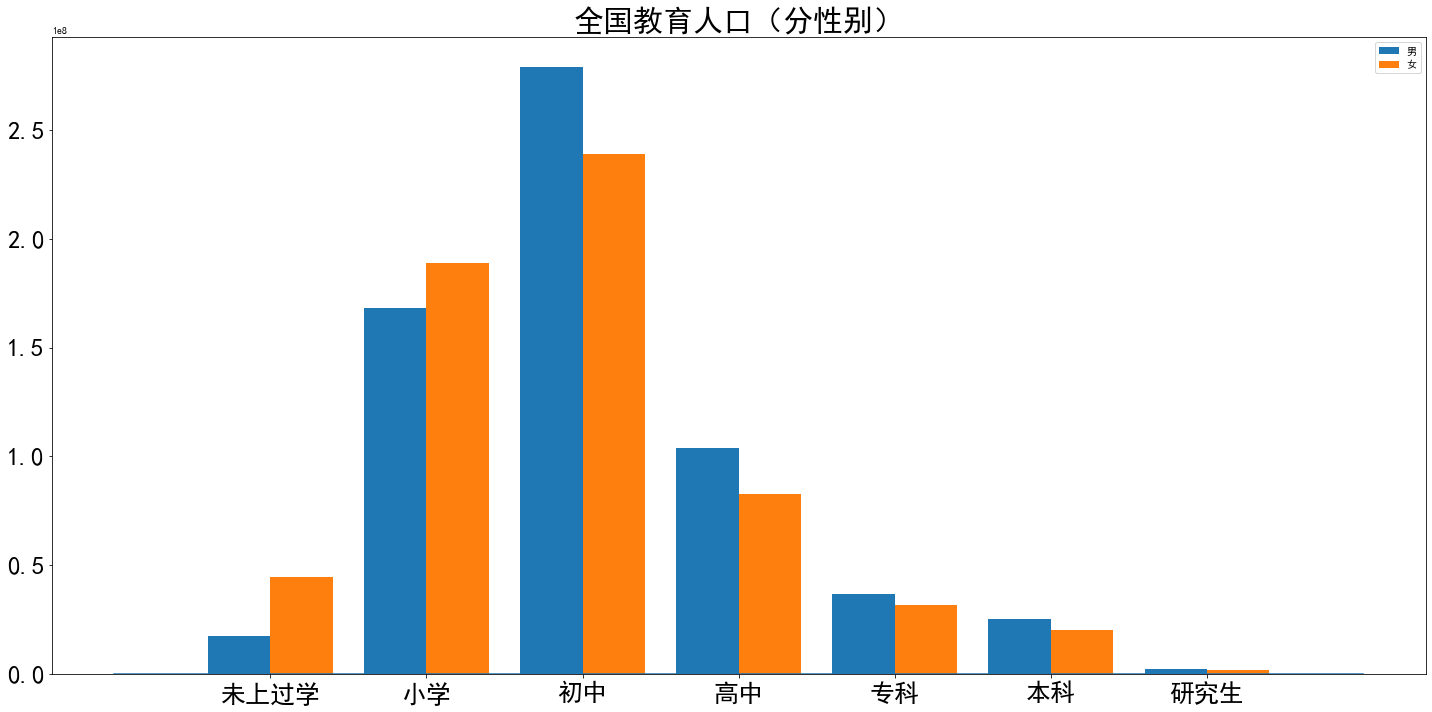
全国情况稍微好一点点,也仅限于义务教育范围内了
xticks = ['未上过学','小学','初中','高中','专科','本科','研究生',] men = [] for i in range(len(xticks)): men.append(df2.iloc[0,i*3+5]*100/(df2.iloc[0,i*3+5]+df2.iloc[0,i*3+6])) women = [] for i in range(len(xticks)): women.append(df2.iloc[0,i*3+6]*100/(df2.iloc[0,i*3+5]+df2.iloc[0,i*3+6])) yunnan_men = [] for i in range(len(xticks)): yunnan_men.append(df2.iloc[25,i*3+5]*100/(df2.iloc[25,i*3+5]+df2.iloc[25,i*3+6])) yunnan_women = [] for i in range(len(xticks)): yunnan_women.append(df2.iloc[25,i*3+6]*100/(df2.iloc[25,i*3+5]+df2.iloc[25,i*3+6])) bar_width = 0.4 plt.bar(np.arange(len(xticks)),men,width=0.4,label='全国男') plt.bar(np.arange(len(xticks)),women,bottom=men,width=0.4,label='全国女') # plt.bar(np.arange(len(xticks)+0.4),yunnan_men,width=0.4,label='云南男') # plt.bar(np.arange(len(xticks)+0.4),yunnan_women,bottom=yunnan_men,width=0.4,label='云南女') fig = plt.gcf() plt.title('全国教育人口(分性别)',fontdict = {'fontsize' : 30}) plt.plot([-1,len(xticks)],[50,50]) plt.xticks(np.arange(len(xticks)),xticks) fig.set_size_inches(20, 10) plt.tick_params(labelsize=25) plt.tight_layout() plt.show()

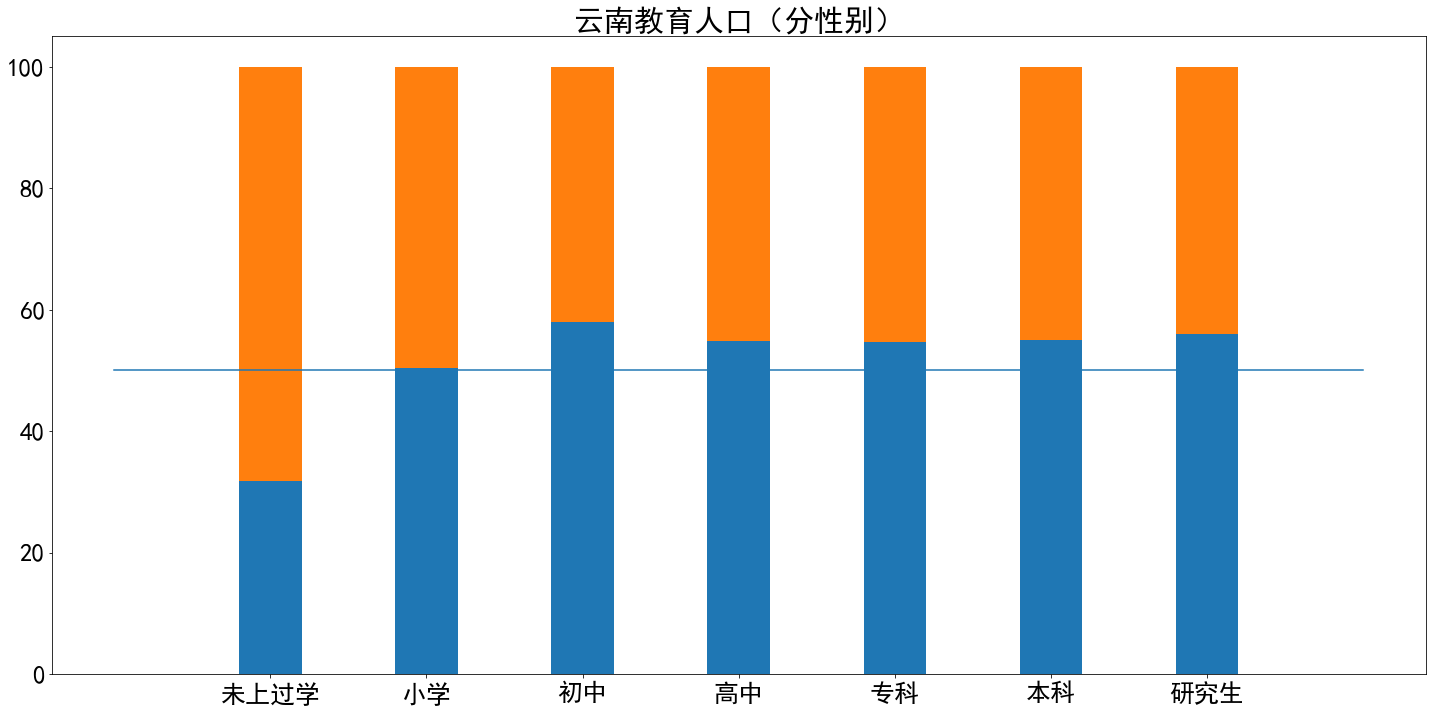
xticks = ['未上过学','小学','初中','高中','专科','本科','研究生',] men = [] for i in range(len(xticks)): men.append(df2.iloc[0,i*3+5]*100/(df2.iloc[0,i*3+5]+df2.iloc[0,i*3+6])) women = [] for i in range(len(xticks)): women.append(df2.iloc[0,i*3+6]*100/(df2.iloc[0,i*3+5]+df2.iloc[0,i*3+6])) yunnan_men = [] for i in range(len(xticks)): yunnan_men.append(df2.iloc[25,i*3+5]*100/(df2.iloc[25,i*3+5]+df2.iloc[25,i*3+6])) yunnan_women = [] for i in range(len(xticks)): yunnan_women.append(df2.iloc[25,i*3+6]*100/(df2.iloc[25,i*3+5]+df2.iloc[25,i*3+6])) bar_width = 0.4 # plt.bar(np.arange(len(xticks)),men,width=0.4,label='全国男') # plt.bar(np.arange(len(xticks)),women,bottom=men,width=0.4,label='全国女') plt.bar(np.arange(len(xticks)),yunnan_men,width=0.4,label='云南男') plt.bar(np.arange(len(xticks)),yunnan_women,bottom=yunnan_men,width=0.4,label='云南女') fig = plt.gcf() plt.title('云南教育人口(分性别)',fontdict = {'fontsize' : 30}) plt.plot([-1,len(xticks)],[50,50]) plt.xticks(np.arange(len(xticks)),xticks) fig.set_size_inches(20, 10) plt.tick_params(labelsize=25) plt.tight_layout() plt.show()
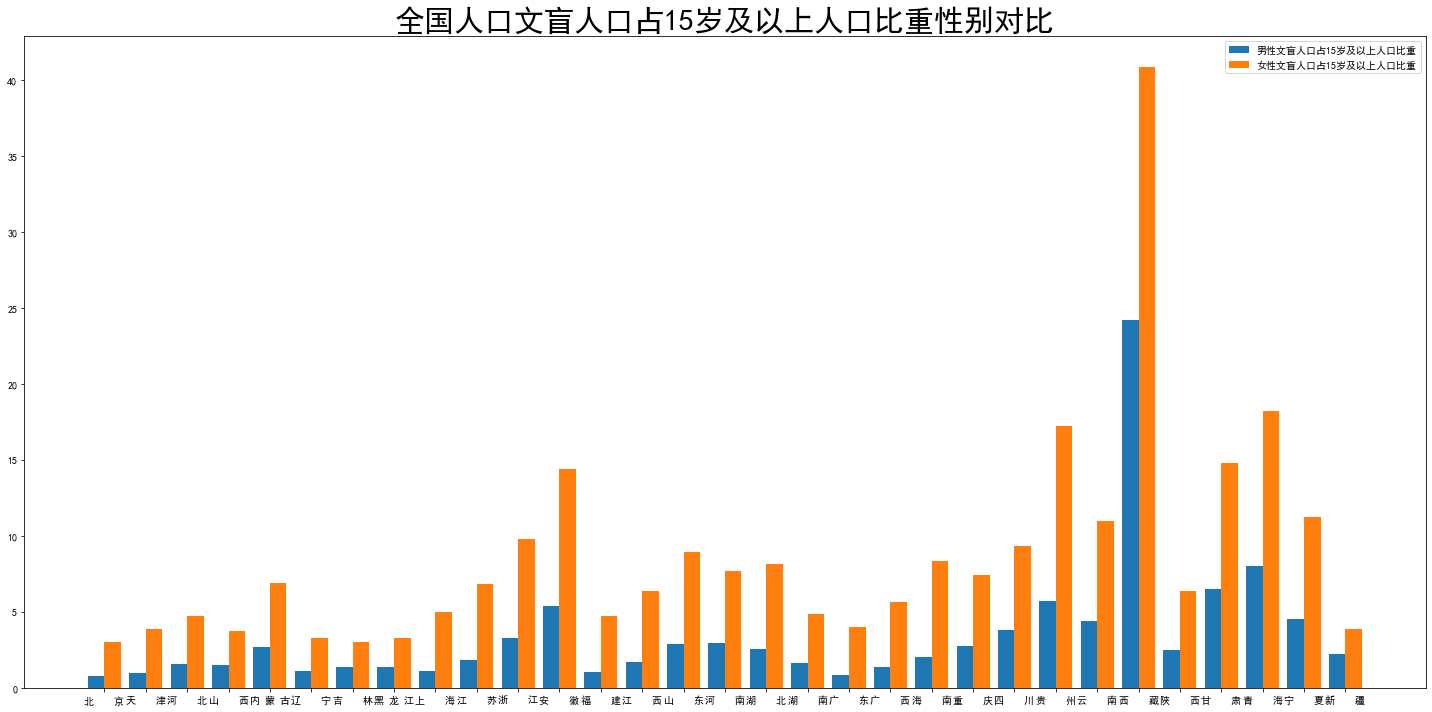
xls_path = path + '1-9 各地区分性别的15岁及以上文盲人口.xls' df3 = pd.read_excel(xls_path,sheet_name=0,header=None) for i in range(6): df3 = df3.drop(i,axis=0) df3 = df3.reset_index() df3 = df3.drop('index',axis=1) new_col = ['地区','15岁以上人口总数','15岁以上男性总数','15岁以上女性总数', '文盲人口总数','文盲男性总数','文盲女性总数', '文盲人口占15岁及以上人口比重','男性文盲人口占15岁及以上人口比重','女性文盲人口占15岁及以上人口比重',] df3.columns = new_col bar_width = 0.4 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.bar(np.arange(len(df3))-0.2,df3['男性文盲人口占15岁及以上人口比重'],width=0.4,label='男性文盲人口占15岁及以上人口比重') plt.bar(np.arange(len(df3))+bar_width-0.2,df3['女性文盲人口占15岁及以上人口比重'],width=0.4,label='女性文盲人口占15岁及以上人口比重') plt.xticks(np.arange(len(df3)),df3['地区']) fig = plt.gcf() fig.set_size_inches(20, 10) plt.title('全国人口文盲人口占15岁及以上人口比重性别对比',fontdict = {'fontsize' : 30}) plt.tick_params(labelsize=10) plt.tight_layout() plt.legend()
1 bar_width = 0.4 2 plt.rcParams['font.sans-serif']=['SimHei'] 3 plt.rcParams['axes.unicode_minus']=False 4 plt.bar(np.arange(len(df3))-0.2,df3['文盲男性总数'],width=0.4,label='文盲男性总数') 5 plt.bar(np.arange(len(df3))+bar_width-0.2,df3['文盲女性总数'],width=0.4,label='文盲女性总数') 6 plt.xticks(np.arange(len(df3)),df3['地区']) 7 fig = plt.gcf() 8 fig.set_size_inches(20, 10) 9 plt.title('全国人口文盲人口性别对比',fontdict = {'fontsize' : 30}) 10 plt.tick_params(labelsize=10) 11 plt.tight_layout() 12 plt.legend()
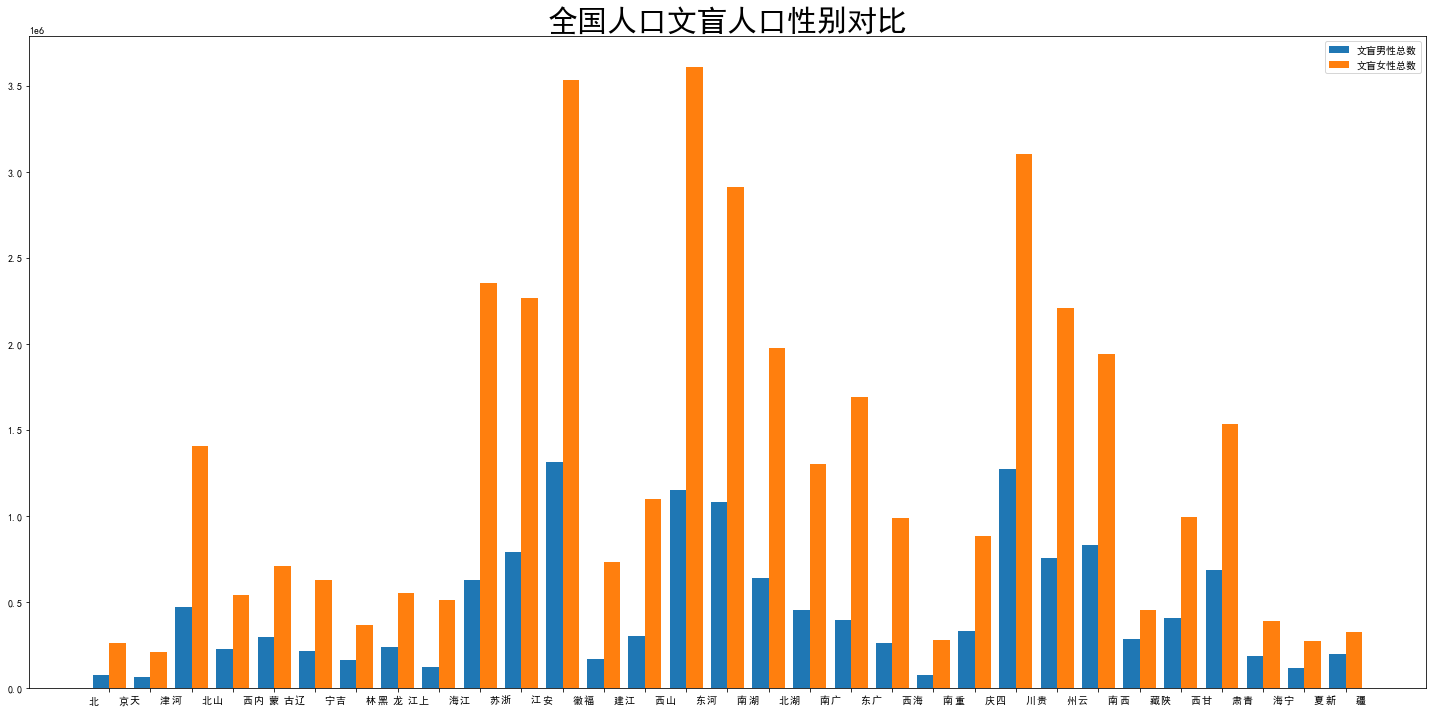
没想到文盲人口几乎每个省份女性都是男性的两倍以上...
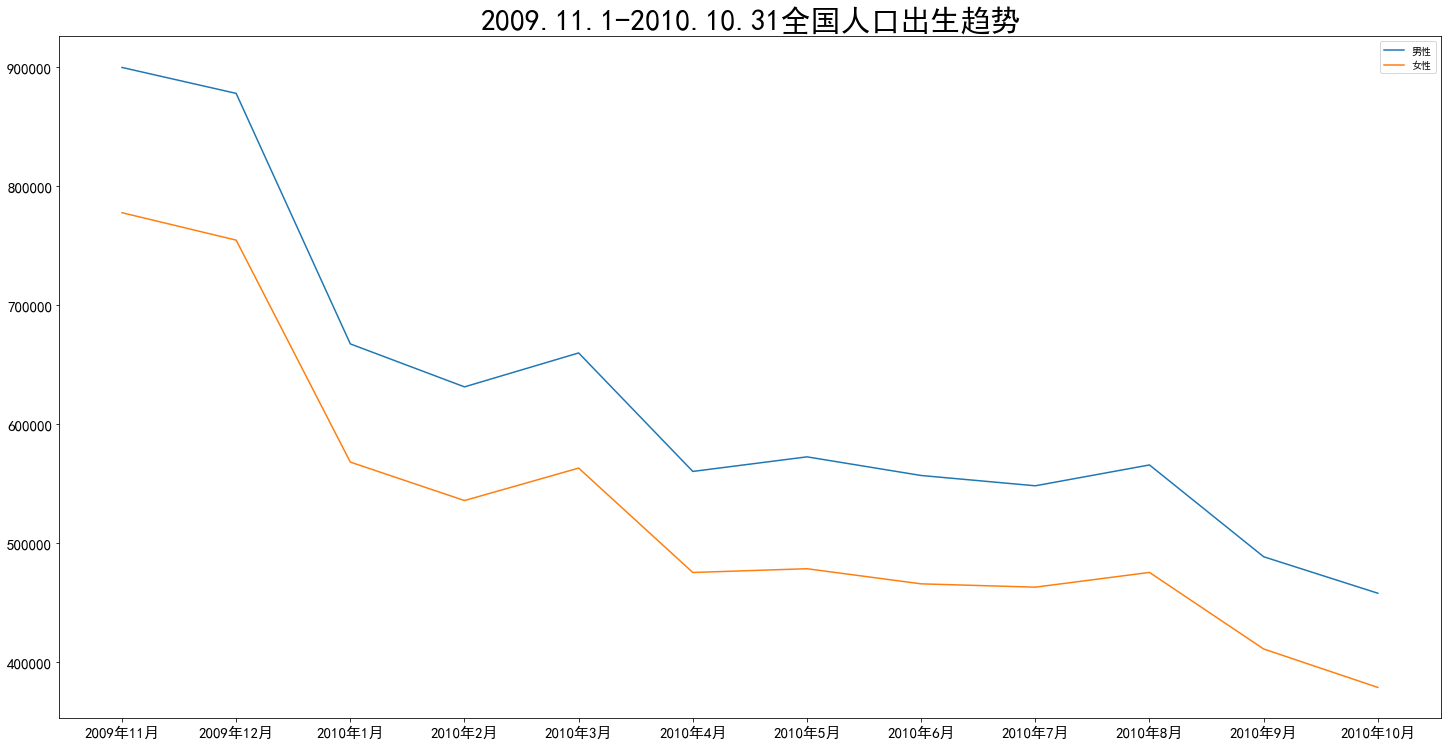
1 xls_path = path + '1-12 各地区分性别、月份的出生人口(2009.11.1-2010.10.31).xls' 2 df4 = pd.read_excel(xls_path,sheet_name=0,header=None) 3 for i in range(5): 4 df4 = df4.drop(i,axis=0) 5 df4 = df4.reset_index() 6 df4 = df4.drop('index',axis=1) 7 8 new_col = ['地区','出生人口总数','出生男性总数','出生女性总数',] 9 year = 2009 10 month = 11 11 for i in range(12): 12 if month > 12 : 13 year += 1 14 month = 1 15 date = str(year) + '年' + str(month) + '月' 16 new_col.append(date + '出生人口总数') 17 new_col.append(date + '出生男性人口总数') 18 new_col.append(date + '出生女性人口总数') 19 month += 1 20 df4.columns = new_col 21 df4.info() 22 23 xticks = [] 24 year = 2009 25 month = 11 26 for i in range(12): 27 if month > 12 : 28 year += 1 29 month = 1 30 date = str(year) + '年' + str(month) + '月' 31 xticks.append(date) 32 month += 1 33 men = [] 34 for i in range(12): 35 men.append(df4.iloc[0,5+i*3]) 36 women = [] 37 for i in range(12): 38 women.append(df4.iloc[0,6+i*3]) 39 plt.plot(xticks, men,label='男性') 40 plt.plot(xticks, women,label='女性') 41 fig = plt.gcf() 42 fig.set_size_inches(20, 10) 43 plt.tight_layout() 44 plt.title('2009.11.1-2010.10.31全国人口出生趋势',fontdict = {'fontsize' : 30}) 45 plt.tick_params(labelsize=15) 46 plt.legend()
xticks = [] year = 2009 month = 11 for i in range(12): if month > 12 : year += 1 month = 1 date = str(year) + '年' + str(month) + '月' xticks.append(date) month += 1 xinbiebi = [] for i in range(12): xinbiebi.append(df4.iloc[0,5+i*3]/df4.iloc[0,6+i*3]) yunnan_xinbiebi = [] for i in range(12): yunnan_xinbiebi.append(df4.iloc[25,5+i*3]/df4.iloc[25,6+i*3]) plt.plot(xticks, yunnan_xinbiebi,label='云南男性/女性出生人口比') plt.plot(xticks, xinbiebi,label='全国男性/女性出生人口比') fig = plt.gcf() fig.set_size_inches(20, 10) plt.tight_layout() plt.title('2009.11.1-2010.10.31全国/云南男性/女性出生人口比',fontdict = {'fontsize' : 30}) plt.tick_params(labelsize=15) plt.legend()

xticks = [] year = 2009 month = 11 for i in range(12): if month > 12 : year += 1 month = 1 date = str(year) + '年' + str(month) + '月' xticks.append(date) month += 1 men = [] for i in range(12): men.append(df4.iloc[25,5+i*3]) women = [] for i in range(12): women.append(df4.iloc[25,6+i*3]) plt.plot(xticks, men,label='男性') plt.plot(xticks, women,label='女性') fig = plt.gcf() fig.set_size_inches(20, 10) plt.tight_layout() plt.title('2009.11.1-2010.10.31云南人口出生趋势',fontdict = {'fontsize' : 30}) plt.tick_params(labelsize=15) plt.legend()
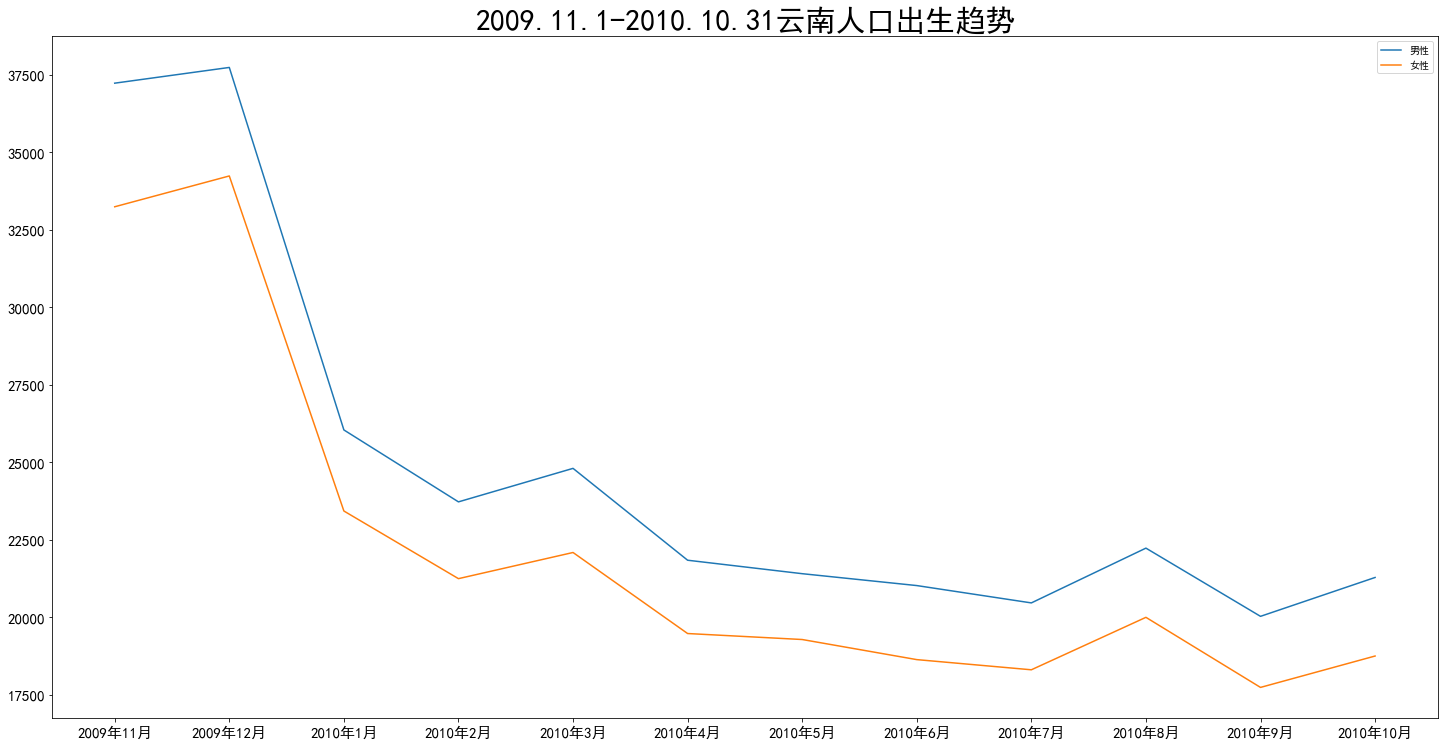

联想到背后的选择性生育/堕胎问题,令人不寒而栗...
结论:对女性给予一定的教育补贴是没错的,甚至还得加大力度;什么时候女性的受教育水平起来了,女性的地位才能真正提高,而不是现在某些极端团体打打拳放放嘴炮就能解决的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号