Flink输出到JDBC
1.代码
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//温度传感器读取样例类
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object JdbcSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//source
val inputStream = env.readTextFile("sensor1.txt")
//transform
import org.apache.flink.api.scala._
val dataStream = inputStream.map(x => {
val arr = x.split(",")
SensorReading(arr(0).trim, arr(1).trim.toLong, arr(2).trim.toDouble)
})
//sink
dataStream.addSink(new MyJdbcSink())
env.execute("jdbc sink test")
}
}
class MyJdbcSink() extends RichSinkFunction[SensorReading] {
//定义sql连接、预编译器
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
//初始化 创建连接和预编译语句
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "用户名", "密码") //test库
insertStmt = conn.prepareStatement("insert into temperatures(sensor, temp) values (?, ?)")
updateStmt = conn.prepareStatement("update temperatures set temp = ? where sensor = ?")
}
//调用连接,执行sql
override def invoke(value: SensorReading, context: SinkFunction.Context[_]): Unit = {
//执行更新语句
updateStmt.setDouble(1, value.temperature) //1和2对应updateStmt里面sql的问号的位置
updateStmt.setString(2, value.id)
updateStmt.execute()
//如果update没有查到数据,就执行插入操作
if(updateStmt.getUpdateCount == 0) {
insertStmt.setString(1, value.id)
insertStmt.setDouble(2, value.temperature)
insertStmt.execute()
}
}
//关闭
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
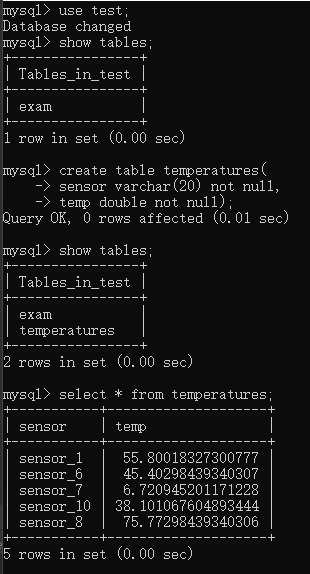
2.结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号