
Java 中 HashMap 的原理
Java 中 HashMap 的原理
HashMap 是基于哈希表的数据结构,用于存储键值对(key-value)。其核心是将键的哈希值映射到数组索引位置,通过数组 + 链表(在 Java 8 及之后是数组 + 链表 + 红黑树)来处理哈希冲突。
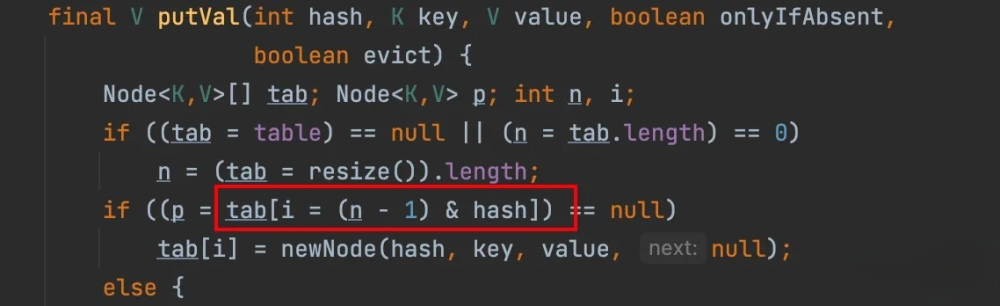
HashMap 使用键的 hashCode() 方法计算哈希值,并通过 indexFor 方法(JDK 1.7 及之后版本移除了这个方法,直接使用 (n - 1) & hash)确定元素在数组中的存储位置。哈希值是经过一定扰动处理的,防止哈希值分布不均匀,从而减少冲突。
HashMap 的默认初始容量为 16,负载因子为 0.75。也就是说,当存储的元素数量超过 16 × 0.75 = 12 个时,HashMap 会触发扩容操作,容量x2并重新分配元素位置。这种扩容是比较耗时的操作,频繁扩容会影响性能。
扩展知识
HashMap 的红黑树优化:
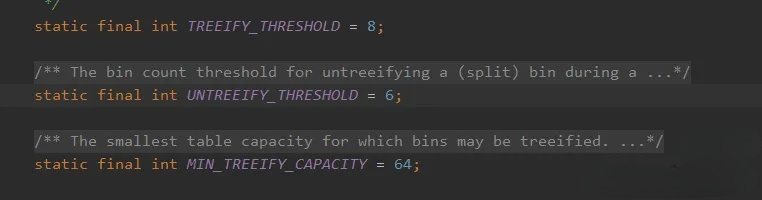
从 Java 8 开始,为了优化当多个元素映射到同一个哈希桶(即发生哈希冲突)时的查找性能,当链表长度超过 8 时,链表会转变为红黑树。红黑树是一种自平衡二叉搜索树,能够将最坏情况下的查找复杂度从 O(n) 降低到 O(log n)。
如果树中元素的数量低于 6,红黑树会转换回链表,以减少不必要的树操作开销。
hashCode() 和 equals() 的重要性:
HashMap 的键必须实现 hashCode() 和 equals() 方法。hashCode() 用于计算哈希值,以决定键的存储位置,而 equals() 用于比较两个键是否相同。在 put 操作时,如果两个键的 hashCode() 相同,但 equals() 返回 false,则这两个键会被视为不同的键,存储在同一个桶的不同位置。
误用 hashCode() 和 equals() 会导致 HashMap 中的元素无法正常查找或插入。
默认容量与负载因子的选择:
默认容量是 16,负载因子为 0.75,这个组合是在性能和空间之间找到的平衡。较高的负载因子(如 1.0)会减少空间浪费,但增加了哈希冲突的概率;较低的负载因子则会增加空间开销,但减少哈希冲突。
如果已知 HashMap 的容量需求,建议提前设定合适的初始容量,以减少扩容带来的性能损耗。
哈希冲突链表法图解
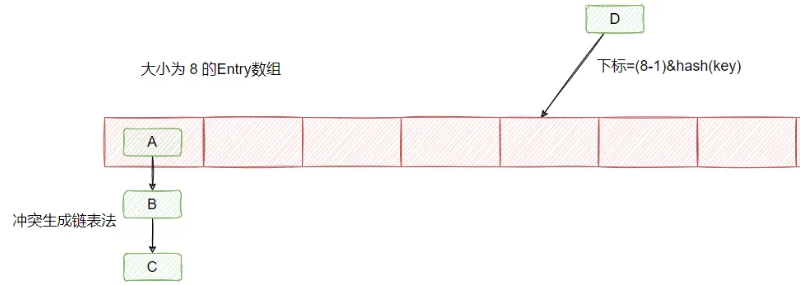
当要塞入一个键值对的时候,会根据一个 hash 算法计算 key 的 hash 值,然后通过数组大小 n-1 & hash 值之后,得到一个数组的下标,然后往那个位置塞入这键值对。
hash 算法是可能产生冲突的,且数组的大小是有限的,所以很可能通过不同的 key 计算得到一样的下标,因此为了解决键值对冲突的问题,采用了链表法,如下图所示:
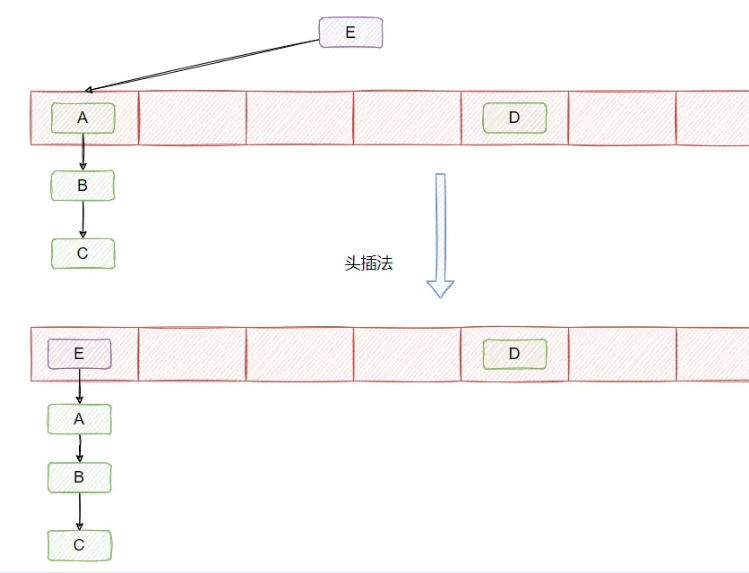
在 JDK1.7 及之前链表的插入采用的是头插法,即每当发生哈希冲突时,新的节点总是插入到链表的头部,老节点依次向后移动,形成新的链表结构。
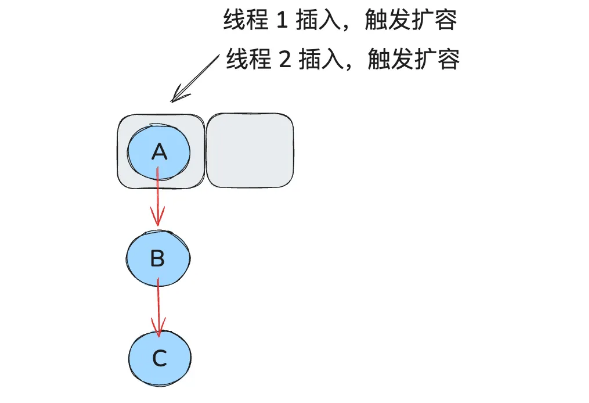
在多线程环境下,头插法可能导致链表形成环,特别是在并发扩容时(rehashing)。当多个线程同时执行 put() 操作时,如果线程 A 正在进行头插,线程 B 也在同一时刻操作链表,可能导致链表结构出现环路,从而引发死循环,最终导致程序卡死或无限循环。
举个例子:
假如此时线程 1 和 2 同时在插入,同时触发了扩容:
▼java
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);//线程1执行到这没cpu时间片,线程2继续执行
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
假设此时,线程 1 中 e 是 A,next 为 B,刚要开始搬运,时间片到了,此时停止操作(停止在源码中注释那一行)。
而线程 2 开始扩容,且成功扩容完毕,此时:

待线程 2 扩容完毕后,线程 1 得到了时间片要开始执行了,它开始执行以下代码:
▼java
e.next = newTable[i]; // A.next = null
newTable[i] = e;
e = next;
此时 A.next = null,因为线程 1 的 newTable 是新建的,此时上面还没有数据,所以 A.next 为 null,且被放到数组上,e 变成 B。
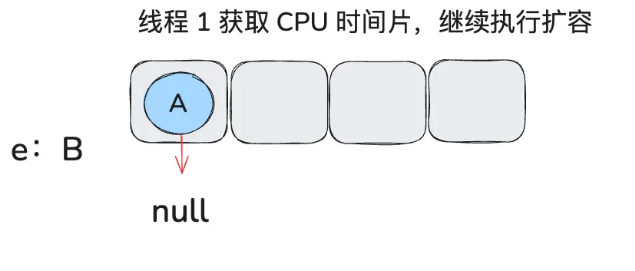
此时继续执行以下代码(看注释):
▼java
do {
Entry<K,V> next = e.next; // e 为 B,e.next 为 A
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // B.next = A
newTable[i] = e; // newTable[i] = B
e = next; // e = A
} while (e != null);
由于线程 2 的操作,e.next 已经变成了 A,hashmap 变成如下结构:
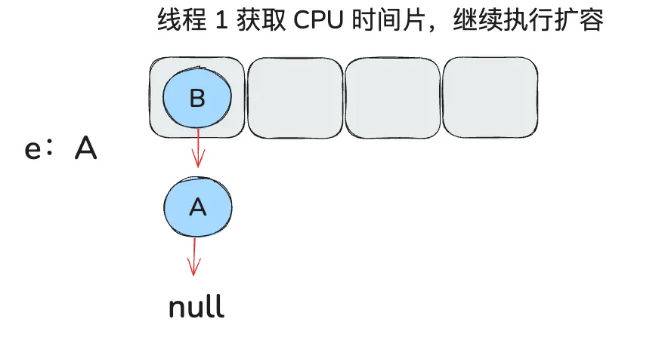
由于 e != null 继续循环执行以下代码:
▼java
do {
Entry<K,V> next = e.next; // e 为 A,e.next 为 null
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // A.next = B
newTable[i] = e; // newTable[i] = A
e = next; // e = null
} while (e != null); // e ==null 跳出循环,此时成环。
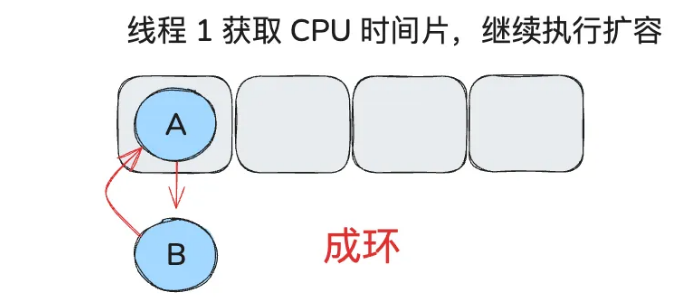
在 JDK1.8 的时候,改成了尾插法,即新的节点插入到链表的尾部,保持插入的顺序。并且引入了红黑树。
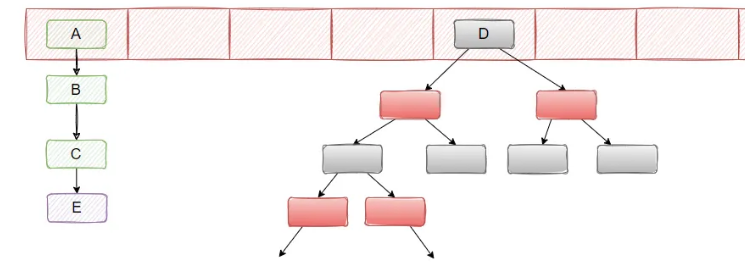
当链表的长度大于 8 且数组大小大于等于 64 的时候,就把链表转化成红黑树,当红黑树节点小于 6 的时候,又会退化成链表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号