
4.10学习(本地缓存,多级缓存策略)
redis缓存参考(4.8)
Caffeine 本地缓存
当应用需要频繁访问某些数据时,可以将这些数据缓存到应用的内存中(比如 JVM 中);下次访问时,直接从内存读取,而不需要经过网络或其他存储系统。
相比于分布式缓存,本地缓存的速度更快,但是无法在多个服务器间共享数据、而且不方便扩容。
应用场景:
● 不需要共享数据的服务器
● 数据访问量有限的小型数据集
● 高频、低延迟的访问场景(如用户临时会话信息、短期热点数据)。
对于 Java 项目,Caffeine 是主流的本地缓存技术,拥有极高的性能和丰富的功能。比如可以精确控制缓存数量和大小、支持缓存过期、支持多种缓存淘汰策略、支持异步操作、线程安全等。
💡建议,由于本地缓存不需要引入额外的中间件,成本更低。因此如果只是要提升数据访问性能,优先考虑本地缓存而不是分布式缓存。
缓存设计
本地缓存的设计和分布式缓存基本一致,不再赘述。但有 2 个区别:
本地缓存需要自己创建初始化缓存结构(可以简单理解为要自己 new 一个 HashMap)。
由于本地缓存本身就是服务器隔离的,而且占用服务器的内存,key 可以更精简一些,不用再添加项目前缀。
多级缓存
多级缓存是指结合本地缓存和分布式缓存的优点,在同一业务场景下构建两级缓存系统,这样可以兼顾本地缓存的高性能、以及分布式缓存的数据一致性和可靠性。
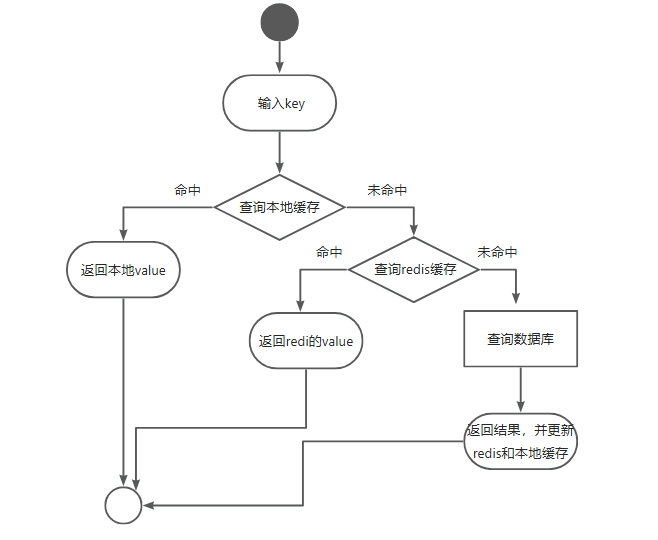
多级缓存的工作流程:
第一级(Caffeine 本地缓存):优先从本地缓存中读取数据。如果命中,则直接返回。
第二级(Redis 分布式缓存):如果本地缓存未命中,则查询 Redis 分布式缓存。如果 Redis 命中,则返回数据并更新本地缓存。
数据库查询:如果 Redis 也未命中,则查询数据库,并将结果写入 Redis 和本地缓存。
流程图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号