
4.8学习
题目
点击查看代码
布置宴席最微妙的事情,就是给前来参宴的各位宾客安排座位。无论如何,总不能把两个死对头排到同一张宴会桌旁!这个艰巨任务现在就交给你,对任何一对客人,请编写程序告诉主人他们是否能被安排同席。
输入格式:
输入第一行给出3个正整数:N(≤100),即前来参宴的宾客总人数,则这些人从1到N编号;M为已知两两宾客之间的关系数;K为查询的条数。随后M行,每行给出一对宾客之间的关系,格式为:宾客1 宾客2 关系,其中关系为1表示是朋友,-1表示是死对头。注意两个人不可能既是朋友又是敌人。最后K行,每行给出一对需要查询的宾客编号。
这里假设朋友的朋友也是朋友。但敌人的敌人并不一定就是朋友,朋友的敌人也不一定是敌人。只有单纯直接的敌对关系才是绝对不能同席的。
输出格式:
对每个查询输出一行结果:如果两位宾客之间是朋友,且没有敌对关系,则输出No problem;如果他们之间并不是朋友,但也不敌对,则输出OK;如果他们之间有敌对,然而也有共同的朋友,则输出OK but...;如果他们之间只有敌对关系,则输出No way。
输入样例:
7 8 4
5 6 1
2 7 -1
1 3 1
3 4 1
6 7 -1
1 2 1
1 4 1
2 3 -1
3 4
5 7
2 3
7 2
输出样例:
No problem
OK
OK but...
No way
解答
刚看这个题感觉可以用图来写,后来发现可以用并查集
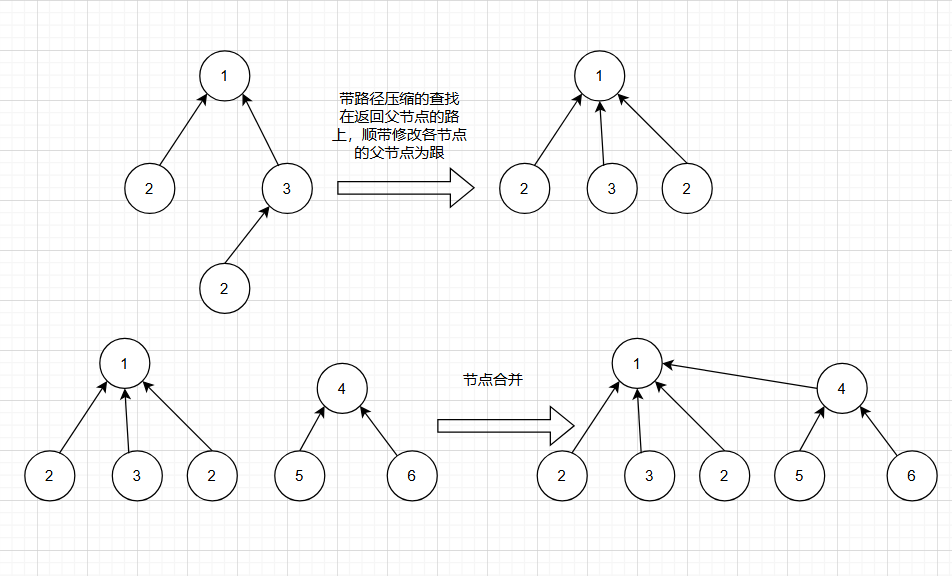
什么是并查集?
包括合并和查找功能的树结构,具有2个重要的函数(查找根节点、合并2个集合)
并查集把具有相同性质的点合并成一个集合,2个人是朋友(性质)我们把它合成一个集合,其中一个人如果还有朋友就把它加入这个集合中。
点击查看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Scanner;
import java.util.StringTokenizer;
public class Main {
static int[] parent;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s = br.readLine();
StringTokenizer st =new StringTokenizer(s);
int n=Integer.parseInt(st.nextToken());
int m=Integer.parseInt(st.nextToken());
int k=Integer.parseInt(st.nextToken());
parent = new int[n+1];
for(int i=1;i<=n;i++) {
parent[i]=i;
}
int[][] enemy = new int[n+1][n+1];
for(int i=0;i<m;i++) {
s = br.readLine();
st =new StringTokenizer(s);
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
int realation=Integer.parseInt(st.nextToken());
if(realation==1) {
union(u, v);
}else {
enemy[u][v]=-1;
enemy[v][u]=-1;
}
}
for(int i=0;i<k;i++) {
s = br.readLine();
st =new StringTokenizer(s);
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
int parentU=findParent(u);
int parentV=findParent(v);
if(parentU==parentV) {
if(enemy[u][v]==0) {
System.out.println("No problem");
}else {
System.out.println("OK but...");
}
}
if(parentU!=parentV) {
if(enemy[u][v]==0) {
System.out.println("OK");
}else {
System.out.println("No way");
}
}
}
}
public static int findParent(int x) {//查找根节点
if(parent[x]==x) {
return x;
}
return parent[x]=findParent(parent[x]);
}
public static void union(int x,int y) {//合并x的根节点和Y的根节点
int rootX=findParent(x);
int rootY=findParent(y);
parent[rootX]=rootY;
}
}
缓存
对于经常访问的数据,每次都从数据库(硬盘)中获取是比较慢,可以利用性能更高的存储来提高系统响应速度,俗称缓存。
合理使用缓存可以显著降低数据库的压力、提高系统性能。
那么,什么样的数据适合缓存呢?一般情况下就 4 个字 “读多写少”,要频繁查询的、不怎么修改的。
具体来说:
高频访问的数据:如系统首页、热门推荐内容等。
计算成本较高的数据:如复杂查询结果、大量数据的统计结果。
允许短时间延迟的数据:如不需要实时更新的排行榜、图片列表等。
在我们的项目中,主页是用户高频访问的内容,调用的获取图片列表的接口也是高频访问的。而且即使数据更新存在一定延迟,也不会对用户体验造成明显影响,因此非常适合缓存。
Redis 分布式缓存
分布式缓存是指将缓存数据分布存储在 多台服务器 上,以便在高并发场景下提供更高的吞吐量和更好的容错性。
Redis 是实现分布式缓存的主流方案,也是后端开发必学的技能。主要是由于它具有下面几个优势:
高性能:基于内存操作,访问速度极快。单节点 Redis 的读写 QPS 可达 10w 次每秒!
丰富的数据结构:支持字符串、列表、集合、哈希、位图等,适用于各种数据结构存储。
分布式支持:可以通过 Redis Cluster 构建高可用、高性能的分布式缓存,还提供哨兵集群机制提升可用性、提供分片集群机制提高可扩展性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号