CPU
图片均来自张进教授,仅为笔记用
概述
实现一个能完成以下基本功能的MIPS32 CPU

这会是CPU的基本结构

Register
Register的结构

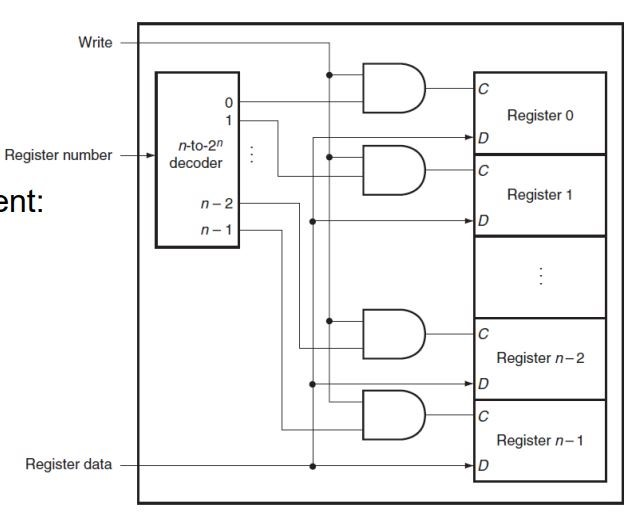
RegWrite的组成
Write是写入信号,Register number是二进制下的目标register编号,通过decoder和and gate来使得Register data仅被写入目标register
RegRead的组成
Read Register是目标register的编号,用一个MUX来挑选出目标register

Clock
时序逻辑需要用clock或者信号来控制,组合逻辑不需要
其中PC和Register是时序逻辑,需要用clock
InstructionMemory和DataMemory我们用信号来控制,不用clock
除此之外都是组合逻辑,不用clock
在单周期CPU中,CPU一周期的工作都在一个clock周期内完成
PC更新占第一个pos edge
Registers读取用neg edge,写回Registers用下一个pos edge
也就是在下一个pos edge,同时触发第一个issue的写回,和第二个issue的PC更新
虽然两件事同时触发,但两件事有一个时间差,并不会冲突
Instructions
R-type
执行一个R-Type Instruction的过程
假设执行一个add t1, t2, t3
这是add的二进制指令格式
rs是t2, rt是t3, rd是t1

那么在Registers中Read register1是rs,read register2是rt,然后把read data数据给到ALU,ALU计算后把结果放到write data,write register是rd

一个lw的执行过程
假设 lw t1, 8(t2)
rs就是t2, rt就是t1

read register1是rs,读出rs数据,然后给到ALU
ALU另一个操作数是指令的后16位的immediate,做extension变成32位
ALU把运算结果给到data memory的address,取出该位置的数据,再把取出的数据放到register的write data,write register是rt

一个sw的执行过程
假设sw t1, 8(t2)
rt就是t1, rs是t2

read register2是rt,取出数据放到read data2,直接给到data memory的write data
read register1是rs,取出数据放到read data1,给到ALU的,ALU再拿到指令中的imm,运算后给到data memory的address
beq
假设是 beg t1, t2, offset
从registers中拿出t1, t2,用ALU判断是否相等,如果相等ALU的Zero为1,否则为0
指令中的立即数部分是offset,做extension
因为offset是指令数的偏移量,需要乘以4,加上(PC+4)得到跳转到的地址
然后用一个mux,如果ALU的Zero是1,则PC变成跳转的地址,否则就是PC+4,即下一条指令

Control
以上的部件再加上一些控制信号,就得到完整的CPU

Registers和ALU中间的Mux控制的是,ALU的第二个操作数选择,Registers的read data2还是指令中的imm
Data memory右边的Mux控制的是,选择把data memory的read data传给Registers,还是把ALU的结果传给Registers
Control中
ALUSrc是由指令高6位opcode控制的
ALU operation则是由指令低位func code控制的,告知ALU要进行什么运算
RegDst是用于控制Registers的Write register从指令中的rt位置拿,还是从rd位置拿。
如果是R-format,RegDst就是1,rd为Write Register;否则rt为Write Register

如果当前指令是beq,Branch则为1,则得到ALU-Zero的值,传入右上角左边的MUX
最右上角的MUX由jump控制,如果Mux为0,则左边的Mux计算出来的地址 (beq或者单纯pc+4) 传入PC
如果opcode识别出指令是jump则Mux为1
将PC前四位和instruction中26位地址拼起来,再补上尾部两个0,写入PC
Pipeline
单周期的CPU效率比较低下
为了保证所有指令都能在一个clock cycle内完成,我们需要把clock cycle的时间设置为长于lw所需的时间,因为lw是所有指令中时间花费最多的
而其他短时间指令就只能等待clock cycle走完才能进行下一次指令,效率低下
Pipeline的想法如下
将一个周期的操作分为多个步骤,将步骤重叠在一起

我们可以将CPU的操作分为5个步骤

single-cycle中,以整套操作做完的时间作为一个cycle
pipeline中以时间最长的步骤的时间作为一个cycle,一个cycle要保证任意一个步骤都能完成

pipeline带来的speedup——加速的比例
用上图的例子,假设clock cycle长度一开始是5(步骤数)
最优情况下每个步骤花费的时间相同,pipeline能使clock cycle长度变为1
如上图,如果步骤之间花费时间不均则clock cycle > 1
假设整套操作进行的次数为n, 操作内步骤有x个,每个步骤花费时间为1
在non-pipelined下,总时间为xn;在pipelined下,总时间为n + x - 1
时间比为\(\frac{xn}{n+x-1}\)
整套操作进行的次数,即n越多,speedup越大,步骤数x越多,speedup越大
Hazard
Hazard就是阻止我们完美地执行pipeline的一些情况,导致的延迟cycle我们称为bubble
常见hazard
Structure Hazard
假如说CPU采用了Von Neumann架构,即中只有一个memory,同时装有data和instruction
那么就无法同时进行fetch instruction和access data,这就叫做Structure Hazard
解决方法就是采用Harvard Structure,把memory分成data和instruction memory
Data Hazard
后一条指令依赖于前一条指令修改的register,那么下一条指令就需要等待上一条指令的write back结束后才能进行ID

forwarding(也叫bypassing)可以解决这种问题,前一个指令进行完EX后,通过一条data path,留给下一个指令的EX

load-use data hazard
和下一条指令的运算依赖于前一条指令的lw,也是用forwarding解决,但需要加一个bubble

control hazard
branch语句和其下一个语句的冲突
常规情况下,下一个语句的IF需要等到branch的情况出来后,也就是上一个指令的EX后再进行,需要较多bubble
我们通过设计新的硬件,使得在ID阶段就可以得到branch的结果,这样子就只需要给下一个语句加一个bubble即可

解决hazard的其他方法
可以在编译时,重新组织指令顺序,尽量避免冲突

static branch prediction
根据一些惯例来猜测branch的结果,比如loop一般会进行比较多次,我们就可以猜测loop会继续进行
dynamic branch prediction
通过硬件手段,在每次branch时统计最近true/false的次数,然后去猜概率更高的方向
这是prediction的结果

load-use data hazard也可以用prediction的方式优化
我们假设后一条运算没有用到前一条lw影响的寄存器,直接执行即可
如果执行到一半发现寄存器被lw影响了,做roll back处理
Multiple Issue
Multiple Issue就是同时进行多个指令的执行

static multiple issue
以下会讲述两个issue的工作
通过编译器对代码进行判断,能把代码分成多个小组——issue packet,把每个小组放进同进一个issue slot,CPU同时执行,编译器需要避免同一个issue packet内的dependency
Naïve static dual issue
就是用两套相同的硬件来实现multiple issue

但我们可以复用两个issue的硬件,来节省硬件
一个PC是可以的,每次+64即可,把两个32位指令看成一条64位的长指令
一个instruction memory也是可以的,一次拿一条64位长指令即可
register可以复用,需要加倍的的接口和控制信号
data memory用原本的结构即可,但需要处理来避免memory上的冲突(见后续)
但ALU不行,需要两个

我们可以将instructions分为两类,每个issue packet放一个type1, 一个type2,type1不会使用data memory,这样就能避免在memory上的冲突

loop unrolling: 有一些代码循环,每个循环之间没有依赖,只是用了重复的寄存器
那我们可以把循环拆开,每个代码块做的事情更多
下图是loop unrolling的例子


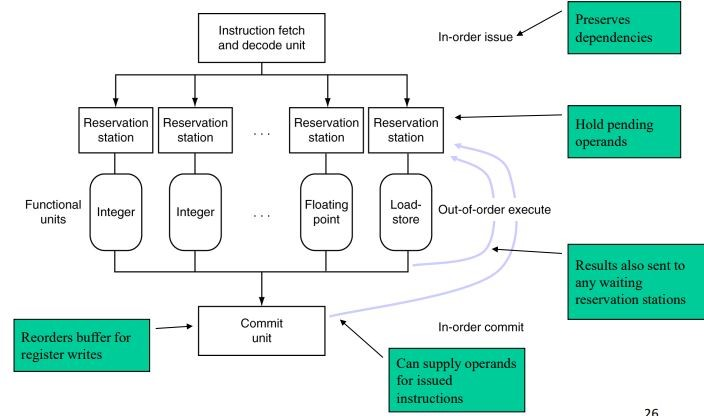
dynamic multiple issue
通过一个superscalar processor,仅在运行时处理,完成multiple issue,由它来决定每个issue slot放多少条指令
superscalar processor分为多个运算管道,每个管道有个reservation station,所有指令按照自己的类型分到不同的管道
当他依赖的东西已经空闲了,他就可以开始运算,运算结果一条路去commit,一条路去到其他对该运算结果有依赖的reservation station
这样实现了指令顺序的“重排”,没有依赖其它指令的指令就可以提前执行
static和dynamic的比较
- superscalar对于branch处理更好,static的方式是重新组织代码,但branch的结果是不确定的,组织比较困难,dynamic的方式则是全部指令都要执行
- static无法预料一些cache miss,导致代码组织不合理,执行时间变长,dynamic则不用关注cache miss


 浙公网安备 33010602011771号
浙公网安备 33010602011771号