

集合
一、ArrayList集合的操作
ArrayList<泛型> s=new ArrayList<泛型>();
add()添加某个元素,括号内为元素的内容
remove()删除某个元素,括号内可以为元素内容,也可以为索引值
size()计算集合的长度
set()对于某个位置上的元素进行更新操作,括号内第一个为索引值,第二个为更新内容
get()获取指定位置的元素内容,括号内为索引值
当使用add(int,Object)方法向不连续的位置添加数据抛出异常,
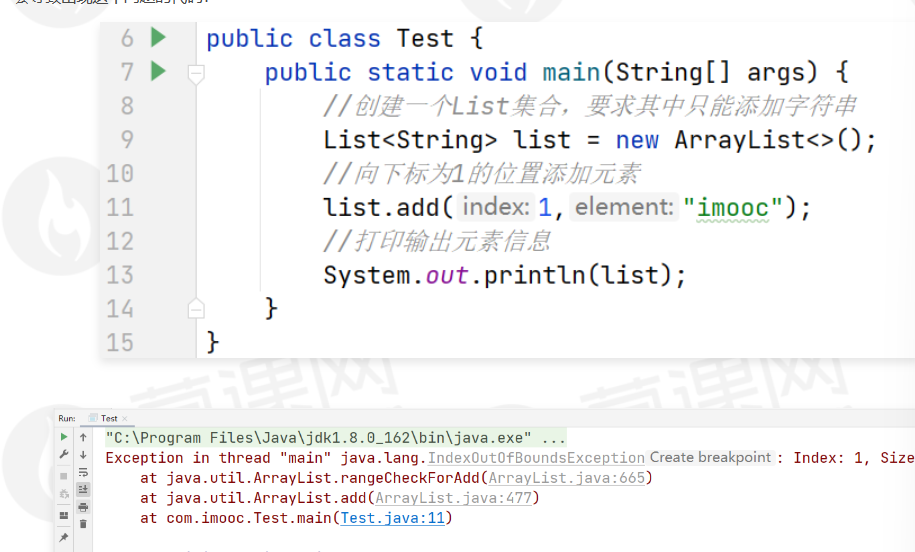
由于在此处向集合中添加数据,正常是0下标开始进行添加,上面代码中,跳过了0下标,直接向下标为1的位置添加元素,有时候添加的位置可能是不可预估的,因此会发合适呢个上面的问题。
ArrayList底层数组实现,数组本身具有长度限制,如果不对用户输入的下标进行验证,那么在实际运行可能出现数组下标越界的现象。避免方式例如下:

ArrayList集合元素的遍历:
for(String book:bookList){ System.out.println(book); } //另外一种遍历方式 bookList.forEach(book->{ System.out.println(book); });
//另外一种遍历方式,迭代器的使用是一次性的,第二次再使用时要重新创建迭代器,因为上次指针指在最后元素的末尾 Iterator<String> itr = bookList.iterator();
while(itr.hasNext()){
String book = itr.next();
System.out.println(book);
}
public class StringSort {
class fruitsCompartor implements Comparator<String>{
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
}
public List<String> sort(List<String> list){
Collections.sort(list);
System.out.println("排序后:");
System.out.println(list);
return list;
}
public static void main(String[] args) {
//给list添加元素
List<String> fruits=new ArrayList<String>();
//输出排序前list中的内容
fruits.add("orange");
fruits.add("tomato");
fruits.add("apple");
fruits.add("litchi");
fruits.add("banana");
System.out.println("排序前:");
System.out.println(fruits);
//对list中的元素进行排序
new StringSort().sort(fruits);
//输出排序后list中的内容
System.out.println("排序1后:");
System.out.println(fruits);
}
}
二、LinkedList集合的操作
LinkedList在保障有序、允许重复的前提下,可以作为队列在队首对位快速追加数据
LinkedList的数据是在内存中分散存储的,基于链表,拥有良好的数据插入速度,但数据访问速度低于ArrayList
三、set集合的操作
set集合是无序,且不允许重复的集合
常见为HashSet,例如:Set<String> mobileSet = new HashSet<String>();
.size() 是判断长度
.contains()是判断是否包含某个元素,括号内是相应的元素内容,返回值是布尔类型的
.add()添加元素内容,括号内为元素,返回值为布尔类型的值
HashSet是按照相应的哈希算法,然后根据哈希值进行元素的排序,元素所占空间连续,占据空间位置根据哈希值进行排列
LinkedHashSet也是按照相应的哈希算法,根据算法排列在一系列空间中,占据空间按照哈希值排列在相应的连续位置,不过会根据元素插入的早晚,指针指向会根据插入早晚进行相应的元素指向,这就导致显示元素时根据插入早晚显示所有元素
TreeSet默认采用自然排序对元素升序排列,也可以实现Comparable接口自定义排序方式public class TreeSetSample{
class IntegerComparator implements Comparator<Integer>{ //如果在此处不是Integer,而是String,则是使用o1.compareTo(o
2)
@Override public int compare(Integer 01,Integer o2){ return o2-o1;//此处如果o2-o1则是降序,如果o1-o2则是升序排列 } } public void sort(){ Set<integer>set = new TreeSet<Integer>(new IntegerComparator()); set.add(100); set.add(234); set.add(231); System.out.println(set); } public static void main(String[] args){ new TreeSetSample().sort(); } }
四、Map映射特点
Key与Value可以时任何引用类型数据,但是Key通常是String
Map中的Key不允许重复,重复为同一个Key设置Value,后者的Value将会覆盖前者的Value
HashMap时Map接口的典型实现类,对于Key进行无序存储,HashMap不能保证数据按照存储顺序读取,且Key全局唯一
HashMap的基础是HashSet,因此具备HashSet的一系列特征,
.put(key,value); 向HashMap中插入数据,一般key为String类型,value为Objext类型,如果key已经存在,则会返回原Object类型的value的值
.get(); 获取相应的Key值的相应value值,括号内为Key值
.containsKey(); 返回某个Key值的键值对是否已经存在,如果存在则返回true
.containsValue(); 返回某个Value值的键值对是否已经存在,如果存在则返回true
.size();返回一共键值对数目
.remove(); 删除某个键值对,返回类型为Object类型,括号内为Key的值
Map的遍历:
public void doForLoop(Map map){ Set<String>keys = map.keySet(); for(String s : keys){ System.out.println(k + ":" + map.get(k)); } }
public void doForEach(Map map){ map.forEach((key,value)->{ System.out.println(key + ":" + value); }); }
public void doIterator(Map map){ Iterator<Map.Entry<String,Object>>itr = map.entrySet().iterator(); while(itr.hasNext()){ Map.Entry<String,Object>entry = itr.next(); System.out.println(entry.getKey() + ":" + entry.getValue()); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号