
Python第4次作业 翁聪
设计题1:
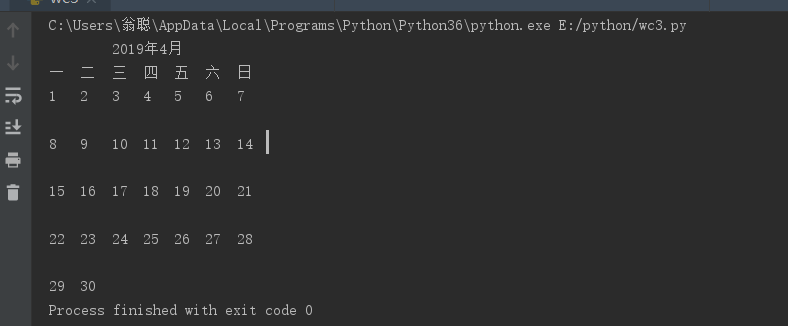
设计一个本月份日历,输出格式如下:

要求:
1.初始化start_day,end_day两个日期
from datetime import datetime
start_day=datetime(2019,4,1)
end_day=datetime(2019,4,30)
其它时间数据生成要用datetime或date模块的方法编程实现
2.不能使用calendar模块生成
#设计一个本月份日历,输出格式如下: #1.初始化start_day,end_day两个日期 #from datetime import datetime #start_day=datetime(2019,4,1) #end_day=datetime(2019,4,30) #其它时间数据生成要用datetime或date模块的方法编程实现 #2.不能使用calendar模块生成 from datetime import * start_day = datetime(2019, 4, 1) end_day = datetime(2019, 4, 30) d = end_day - start_day # 4月份差值 month = start_day.month # 要打印的月份 fist = start_day.weekday() # 4月份的第一天是星期几 day = d.days + 1 # 4月份的天数 count = 0 n = 1 print("\t\t2019年4月") print("一\t二\t三\t四\t五\t六\t日") while n <= fist: # 月份第一天对应星期几,并在前面用空格隔开 n += 1 print("\t", end="") count += 1 if (count % 7 == 0): print("\n") m = 1 while m <= day: # 循环几次与本月天数比较 print(m, "\t", end="") m += 1 count += 1 if (count % 7 == 0): print("\n") # 每七天进行换行
码云网址:https://gitee.com/wc1300/wc/blob/master/python第四次作业1
设计题2:
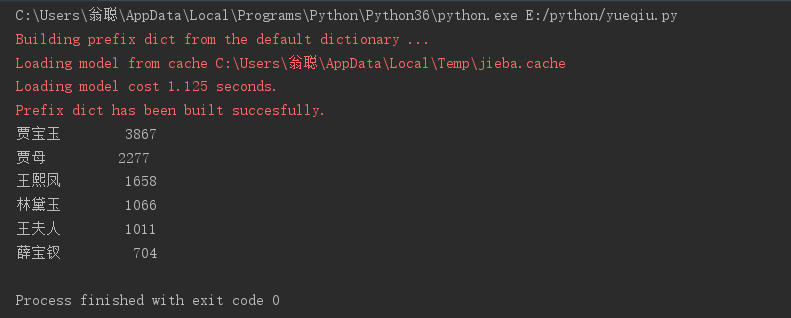
1.参考“三国演义”词频统计程序,实现对红楼梦出场人物的频次统计。
2.(可选)
将红楼梦出场人物的频次统计结果用词云显示。
#1.参考“三国演义”词频统计程序,实现对红楼梦出场人物的频次统计。 #2.(可选) #将红楼梦出场人物的频次统计结果用词云显示。 import jieba excludes = {"什么","一个","我们","那里","你们","如今","说道","知道","起来","姑娘","这里","出来","他们","众人","自己", "一面","只见","太太","奶奶","两个","没有","不是","不知","这个","听见","这样","进来","咱们","告诉","怎么", "就是","东西","回来","只是","老爷","大家","只得","丫头","这些","不敢","出去","所以","的话","不好","姐姐", "鸳鸯"} txt = open(r"E:\python\红楼梦.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt)#精确模式的分词函数,返回一个列表数据类型 counts = {} #定义一个字典 for word in words: if len(word) == 1: continue elif word == "宝玉" or word == "宝二爷" or word == "怡红公子" or word == "绛洞花主" or word == "无事忙" or word == "遮天大王" or word == "混世魔王" or word == "槛内人" or word == "浊玉": rword = "贾宝玉" elif word == "宝钗" or word == "蘅芜君" or word == "宝姐姐" or word == "宝丫头" or word == "宝姑娘": rword = "薛宝钗" elif word == "凤姐" or word == "琏二奶奶" or word=="凤辣子"or word=="凤哥儿"or word=="凤丫头" or word=="凤姐儿" or word == "熙凤道": rword = "王熙凤" elif word == "颦颦" or word == "颦儿" or word == "潇湘妃子" or word == "林姑娘" or word == "林妹妹" or word == "黛玉": rword = "林黛玉" elif word == "晴雯" or word == "勇晴雯" or word == "芙蓉仙子" or word == "病西施": rword = "晴雯" elif word == "老祖宗" or word == "老太太" or word == "史太君" or word == "贾母": rword = "贾母" else: rword = word counts[rword] = counts.get(rword,0) + 1 #词汇加入字典 for word in excludes: del(counts[word]) #从字典中删除无用词 items = list(counts.items())#字典转换为列表 #lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 """x表示列表中的一个元素,x只是临时起的一个名字, 你可以使用任意的名字""" items.sort(key=lambda x:x[1], reverse=True) for i in range(6): #出现的词频统计 word, count = items[i] #将键和值分别赋予列表word和countf print ("{0:<10}{1:>5}".format(word, count))#0:<10左对齐,宽度10,”>5"右对齐
码云网址:https://gitee.com/wc1300/wc/blob/master/python第四次作业2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号