
吴怖卫---第二次作业
| 这个作业属于哪个课程 | <至诚软工实践F班> |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | <学习Fiddler,抓取数据包,进行数据分析,获取所需要的数据> |
| Github 地址 | https://github.com/563433225/212106736 |
使用到的软件:
①谷歌浏览器
②Fiddler
③IDEA编译器
参考信息网:B站
使用语言:Java
jar包添加网:mvnrepository
JSON在线解析网:JSON在线视图查看器
任务一:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
解题思路:
本次作业用到Fiddler,微信小程序,一开始使用模拟器,但一直无法正常在模拟器和备用手机上使用朴朴软件,最终选择微信小程序朴朴进行操作。
首先在选定监听的朴朴商品页面,在使用Fiddler进行数据抓取。获取到朴朴页面有js文件进行传输,获取的js问价的呢get请求地址,添加协议头,获取内容,再通过json在线视图查看器,查看所欲内yi容所在节点下,获取到指定节点后,一节节往下,到达所需要到达的节点,在通过节点内的Key值,通过方法获取指定Key值对应的Value,然后将数据进行搭配输出。
①抓取数据
此截图为需要抓取数据的朴朴商品截图

Fiddler数据抓取截图

②数据分析
朴朴中我们所需要的数据在data节点下,每个所需要的资源,已在图片上打上备注
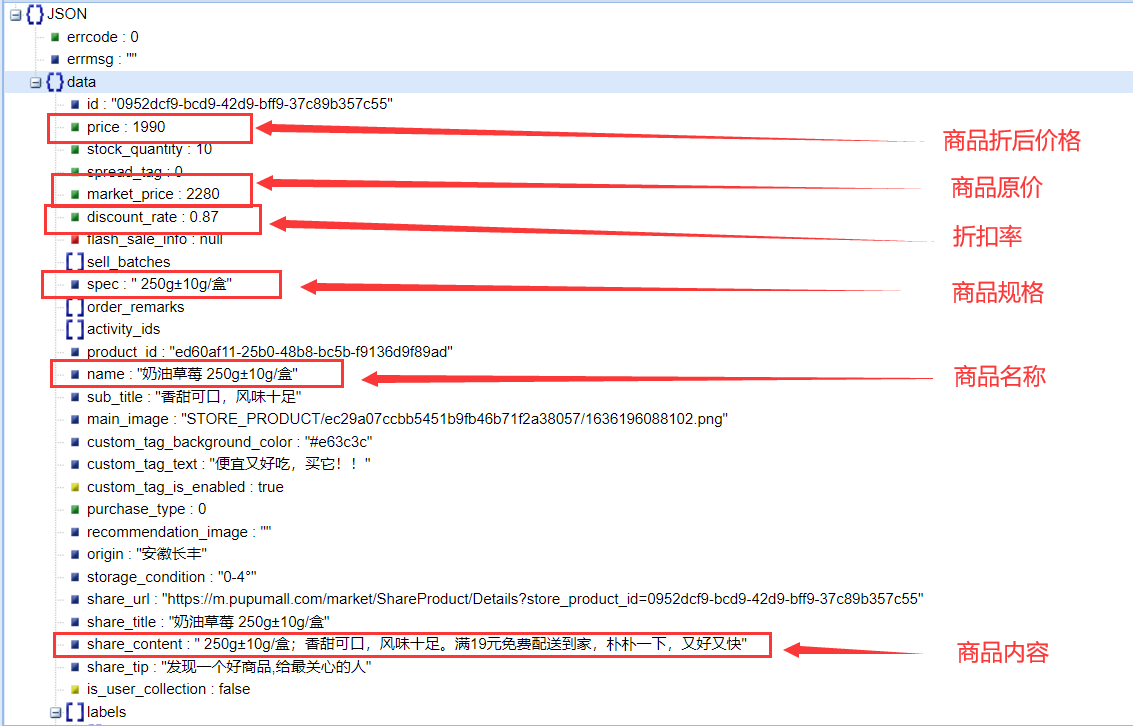
③代码解析
本次抓包代码使用的语言是 Java
1.连接朴朴,获取js文件
//连接方法
private static String getDocument( String sUrl) throws Exception {
//创建HttpClient对象,打开浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
//发起Gget请求,输入网址
HttpGet httpGet = new HttpGet(sUrl);
//添加协议头
httpGet.addHeader("Host","j1.pupuapi.com\n");
httpGet.addHeader("Connection","keep-alive");
httpGet.addHeader("Accep","application/json");
httpGet.addHeader("Authorization","Bearer eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIiLCJhdWQiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiaXNfbm90X25vdmljZSI6IjEiLCJpc3MiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiZ2l2ZW5fbmFtZSI6IuWNq-WNq-WTnyIsImV4cCI6MTY0NzU5NjMzMywidmVyc2lvbiI6IjIuMCIsImp0aSI6IjM2ZmM4NDRmLWI1MDctNGQwNi05MDEzLWQxZGUxYzYwYTMwYiJ9.QGA4veRF5F7vpNXtGjnFL1vg2w17KWLP90D6OyoUImI");
httpGet.addHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat");
httpGet.addHeader("content-type",":application/json");
httpGet.addHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36");
httpGet.addHeader("open-id","oMwzt0N-TOFXilsZAEJo3hOq6MtM");
httpGet.addHeader("pp-os"," 0");
httpGet.addHeader("pp-placeid","8eb75536-f871-452a-a3a8-37a3611eed13");
httpGet.addHeader("pp-userid","36fc844f-b507-4d06-9013-d1de1c60a30b");
httpGet.addHeader("pp-version:","2021063100");
httpGet.addHeader("pp_storeid","7f10e39a-57cb-41a6-94f2-d5bf4e2abbbc");
httpGet.addHeader("Referer","https://servicewechat.com/wx122ef876a7132eb4/156/page-frame.html");
//发其请求,返回响应数值,200为响应成功,使用httpClient对象发其请求
response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode()==200){
HttpEntity httpEntity = response.getEntity();
String content = EntityUtils.toString(httpEntity);
return content;
}
return null;
}
2.上半部分的代码
private static void top() throws Exception {
//使用连接方法
String dom = getDocument(pupu);
//System.out.println(dom);
//将放回的字符串转换为json
JSONObject jsonObject = new JSONObject(dom);
//按节点查找
JSONObject data = jsonObject.getJSONObject("data");
//获取name的value
String name =data.getString("name");
//当前价格
double price = data.getDouble("price")/100;
//原价
double market_price = data.getDouble("market_price")/100;
//规格
String spec= data.getString("spec");
//内容详情
String share_content = data.getString("share_content");
System.out.println("---------------"+name+"---------------");
System.out.println("规格:"+spec);
System.out.println("价格:"+price);
System.out.println("原价/折扣价:"+market_price+"/"+price);
System.out.println("详细内容:"+share_content);
}
3.分隔线代码
private static void centile() throws Exception {
//使用连接方法
String dom = getDocument(pupu);
//将放回的字符串转换为json
JSONObject jsonObject = new JSONObject(dom);
//按节点查找
JSONObject data = jsonObject.getJSONObject("data");
//获取name的value
String name =data.getString("name");
System.out.println("---------------\""+name+"\"的价格波动---------------");
}
4.实时监听代码
private static void monitor() {
new Timer().schedule(new TimerTask() {
//执行监听次数
private int count = 10;
@Override
public void run() {
try {
if (count>0){
//使用连接方法
String dom = getDocument(pupu);
//将放回的字符串转换为json
JSONObject jsonObject = new JSONObject(dom);
//按节点查找
JSONObject data = jsonObject.getJSONObject("data");
//获取name的value
String name =data.getString("name");
//当前价格
double price = data.getDouble("price")/100;
//当前系统时间
String date = String.format("%tF %1$tT ",LocalDateTime.now());
System.out.println("当前时间为:"+date+" 【"+name+"】的价格为:"+price);
//执行过后减少一次
count--;
}
else {
//停止监听
cancel();
}
} catch (Exception e) {
e.printStackTrace();
}
}
},0,2000);//启动延时为0,每隔2秒执行一次
}
5.主方法main()
private static CloseableHttpResponse response = null;
private static String pupu = "https://j1.pupuapi.com/client/product/storeproduct/detail/7f10e39a-57cb-41a6-94f2-d5bf4e2abbbc/ed60af11-25b0-48b8-bc5b-f9136d9f89ad";
public static void main(String[] args) throws Exception {
//头代码
top();
System.out.println();
//第二行标题
centile();
//实时监听方法
monitor();
}
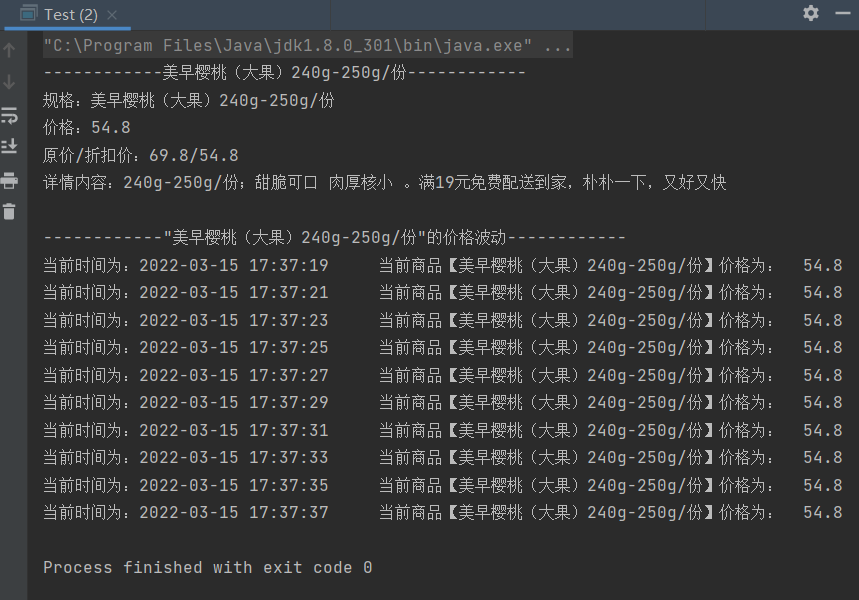
④结果截图
任务二:爬取自己的知乎收藏夹,以每个收藏夹的名称为大类,其下展示各个具体收藏文章的名称及其链接
解题思路:
首先拥有知乎账号,并且按要求完成收藏夹内容。
通过Fiddler工具获取到知乎的网页请求连接和协议头,通过html页面发现,所有的文件内容所在位置都一致,所以首先通过html页面获取到 a 标签内的内容以及所对应的链接。通过链接访问子文件夹下的数据,进行获取。
①抓取数据
首先获取html上的标签,按 标签的 class 查找

每个收藏夹下的文件js数据

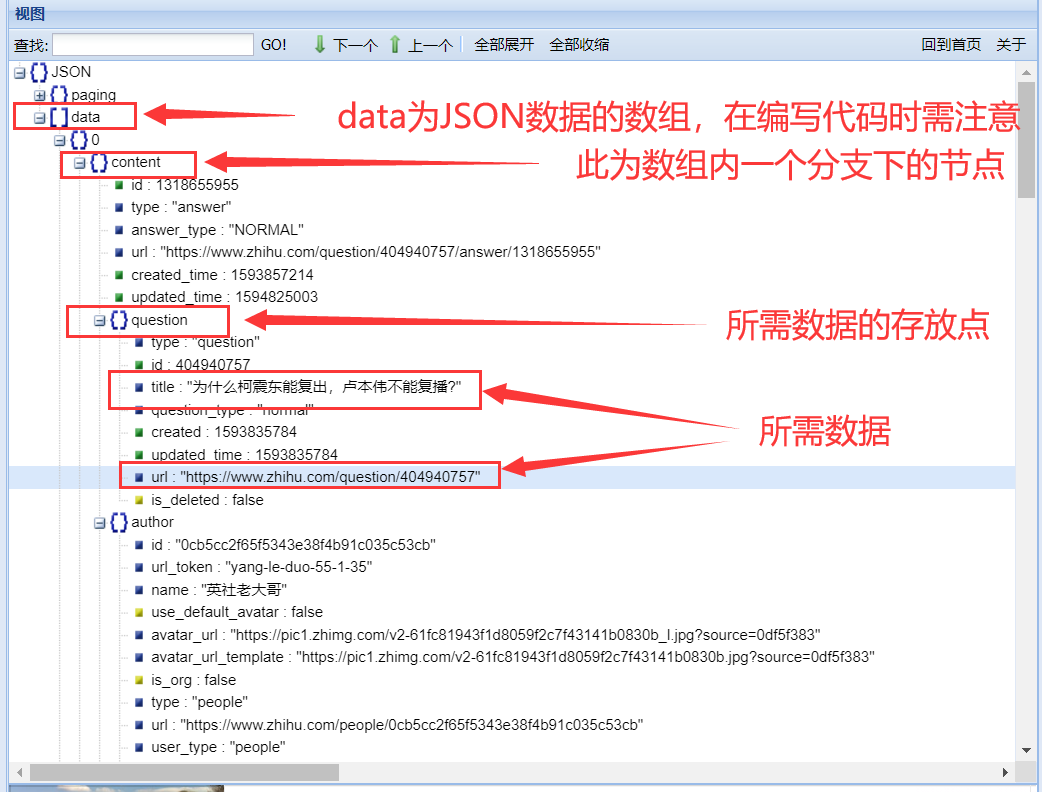
②数据分析
通过Fiddler获取的js文件,通过视图解析,获取到所在位置
③代码解析
1.Test类---主类
public static void main(String[] args) throws Exception {
//getDocument()访问方法
Document doc = getDocument("https://www.zhihu.com/people/wei-wei-59-66-16/collections");
//获取标题
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
//根据class获取到 页面元素内容
Elements tables1 = doc.getElementsByClass("SelfCollectionItem-title");
//System.out.println(tables1);
//根据 a 标签来划分
Elements a = tables1.select("a");
String str ="[{";
for(int j=0;j<a.size();j++) {
System.out.println("");
//获取到标签中的内容
String text = a.get(j).text();
System.out.println("收藏夹名称: "+text);
//获取A标签的href 网址 select 获取到当前A标签 attr href 获取到地址
String s = a.get(j).select("a").attr("href");
//正则表达式,获取网页最后的数字id 添加trim防止两端有空格
//id:为该收藏夹的ID编码
String id = Pattern.compile("[^0-9]").matcher(s).replaceAll("").trim();
//System.out.println(id.trim());"{\"title\":\""+title+"\",\"url\":\""+url+"\"},";
//下面的Jsonsj.geturl()为Jsonjs类的geturl()方法,用于实现每个收藏夹下的子文件查找
//id:为该收藏夹的ID编码
str = str +"\"favorites\":\""+text+"\","+Jsonsj.geturl("https://www.zhihu.com/api/v4/collections/"+id+"/items?offset=0&limit=20")+",";
}
str = str.substring(0,str.length() - 1);
str = str+"}]";
System.out.println("本次数据的JSON格式:"+str);
}
2.Test类的连接方法
private static Document getDocument( String sUrl) throws IOException {
//访问的url点至,第二个是超时时间
Document doc2 = null;
//创建网站连接
Connection connect = Jsoup.connect(sUrl);
//添加协议头
connect.header("Host","www.zhihu.com");
connect.header("Connection","keep-alive");
connect.header("Cache-Control","max-age=0");
connect.header("sec-ch-ua"," \" Not A;Brand\";v=\"99\", \"Chromium\";v=\"99\", \"Google Chrome\";v=\"99\"");
connect.header("sec-ch-ua-mobile","?0");
connect.header("sec-ch-ua-platform","\"Windows\"");
connect.header("Upgrade-Insecure-Requests","1");
connect.header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36");
connect.header("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");
connect.header("Sec-Fetch-Site","same-origin");
connect.header("Sec-Fetch-Mode","navigate");
connect.header("Sec-Fetch-User","?1");
connect.header("Fetch-Dest","document");
//连接网址
doc2 = connect.get();
return doc2;
}
3.Jsonsj类
private static CloseableHttpResponse response = null;;
//通过JSON获取所需要的信息
public static String geturl(String url) throws Exception {
String str = "";
String s = extracted(url);
//将获取的字符串存储到json中
JSONObject jsonResult = new JSONObject(s);
// System.out.println(jsonResult);
//这是json数组,所以用到JSONArray
JSONArray json1 = jsonResult.getJSONArray("data");
//System.out.println(json1);
//System.out.println(json1);
for (int i = 0; i < json1.length(); i++) {
//按节点查找
JSONObject jo1 = json1.getJSONObject(i);
JSONObject jo2 = jo1.getJSONObject("content");
JSONObject jo3 =jo2.getJSONObject("question");
String title = jo3.getString("title");
String utl = jo3.getString("url");
System.out.println(title);
System.out.println(utl);
str= str+"{\"title\":\""+title+"\",\"url\":\""+url+"\"},";
}
str = str.substring(0,str.length() - 1);
str = "\"count\":["+str+"]";
return str;
}
4.Jsonsj类的连接方法
//连接方法
private static String extracted( String us) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
//输入网址,发起get请求,创建HttpGet对象
HttpGet httpGet = new HttpGet(us);
response = httpClient.execute(httpGet);
try{
//响应代码为200,则链接成功
if (response.getStatusLine().getStatusCode() == 200) {
//解析响应,获取数据
HttpEntity httpEntity = response.getEntity();
String s = EntityUtils.toString(httpEntity);
return s;
}else {
System.out.println("连接失败");
}
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}finally {
//关闭连接
response.close();
}
return null;
}
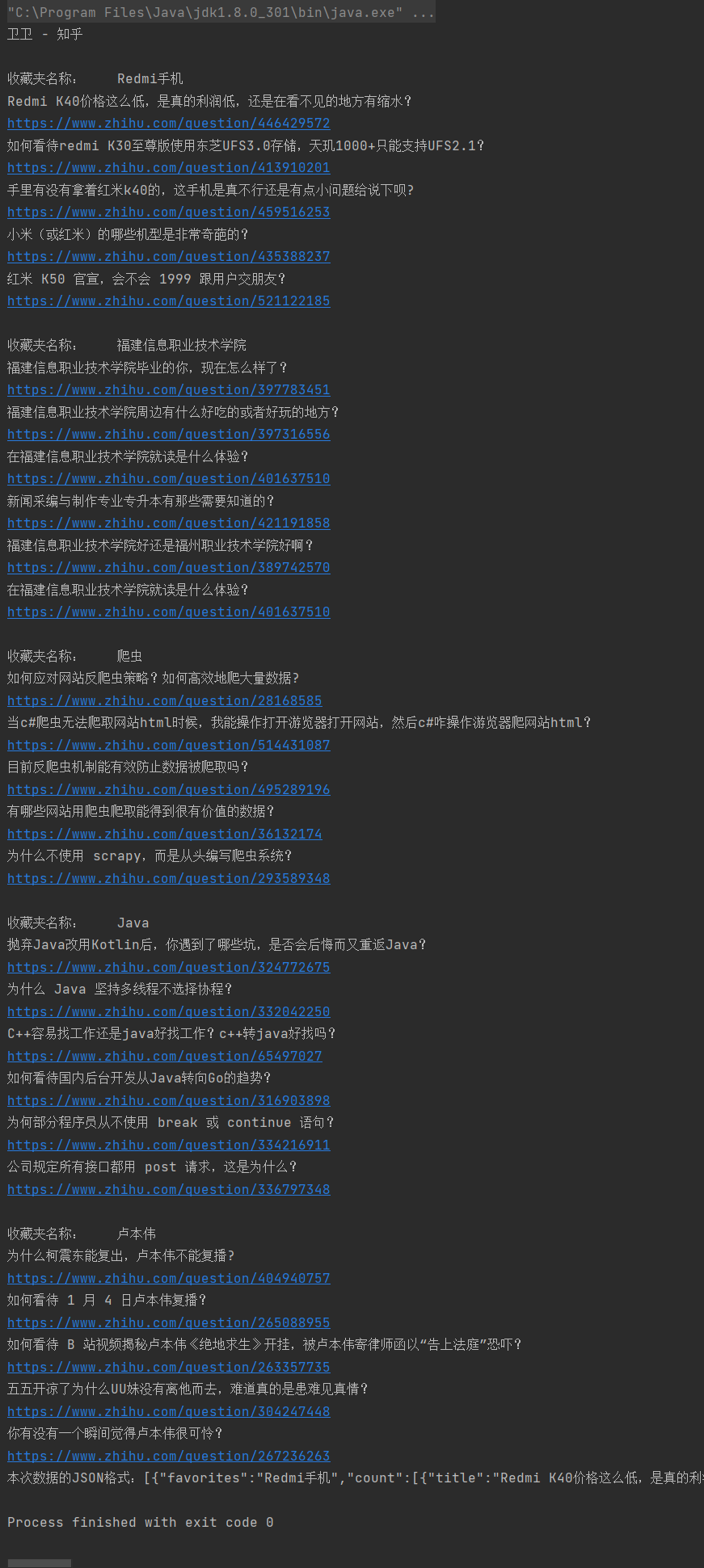
④结果截图
GitHub提交
问题,总结及反思
本次作业使用的一切可以说是完全新的一个知识,从来没有接触过这类的学习,在大家选择python完成作业时,我还是选择使用Java,都说使用python会快,但我觉得大家都写一样的话,那就没意思了,虽然Java在编写的过程中会困难很多,但只要努力学习,查阅资料的话,也可以完成,本次作业的学习耗时四天时间,在这四天中学习了很多新的知识。
从刚开始朴朴连接访问的时候,访问的方式使用了两三种,试了很多次,最后获取网站的json数据也耗费了许多时间。
在知乎任务中,投机取巧先从html中,通过class来锁定所欲要的a标签的文本内容和href链接,在访问文件下的时候出现了问题,比如获取的href链接为 /question/265088955 ,我就直接在前面加上http://www.zhihua,com ,合并在一起访问,以为结束的时,却发现访问不出我需要的数据,每个这样合在一起使用访问的链接,全部都指向一了一个地址 https://www.zhihu.com/people/undefined ,在这时我陷入了死循环,在我问过舍友后才了解到,获取到的href链接没错,,但是返回的数据是js文件数据,我这是恍然大悟,再次通过Fiddler软件找到了所欲要的js文件,通过对比,每个收藏夹之间请求的get链接只有id不一样,所以截取到id,放入指定的链接格式,便可以使用了。
知乎任务的代码中还是存在问题,有的子文件可能是评论,无法获取内容,在这我需要在继续学习,要将所有在收藏夹下的都读取出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号