

ps-2 prometheus+alertmanager 告警实战
参考博文:https://www.cnblogs.com/gered/p/13496950.html https://www.cnblogs.com/baozexu/articles/13628352.html
飞书告警: https://cloud.tencent.com/developer/article/2291974
钉钉告警:https://www.cnblogs.com/JIKes/p/18183559
钉钉+邮件:https://blog.csdn.net/JessonLiu_/article/details/135393981 https://blog.csdn.net/qq_42263280/article/details/141819970
5. alertmanager-钉钉告警
背景
目前的告警通知采用grafana来通知dingding群,这只是grafana的一个功能,所以在灵活性上还是有很多缺陷的,不如专门做告警通知的alertmanager方便
grafana告警
优点:
- 可以发送趋势图,并且配置上来讲比较方便,直接在监控图里配置即可,比较简单
缺点:
- 不能创建一个告警模板应用到一批实例上,意味着我们要每个实例都去配置一下告警,非常麻烦。
- 不能分组,比如: 一个集群的多台机器,都挂掉了,那我们可能一下分别收到5,6个告警,这样大量冗余消息,时间长了人可能会有疏忽。
- 告警恢复的消息,不能显示恢复的是哪个机器,只有一个ok和告警名,多个告警下来,具体是哪个恢复了我们也不知道。
alertmanger告警
优点:
- 可分组、静默、抑制(三大特性)来灵活控制告警规则发送到微信,钉钉,邮件,比如多个机器同个级别的告警可以合并成一个,避免冗余邮件。
- 告警恢复是完整显示信息的,恢复后我们可以知道是哪个机器恢复了,这直接完美替代了grafana的缺点。
缺点:
- 相对于grafana来讲,配置流程上要繁琐许多,并且很多字段也需要熟悉,dingding之类告警还需要安装第三方插件实现。维护起来确实有成本,但是一次配置好了,就可以慢慢享受它带来的优点了
核心概念
1. 分组
将类似性质的警报分类到单个通知中。这在较大的中断期间特别有用,因为许多系统同时发生故障,并且可能同时触发数百到数千个警报。这样解决了警报冗余
2. 抑制
抑制是一种概念,即在某些其他警报已触发时禁止显示某些警报的通知,比如server01触发了严重级别的警报,那警告(waring)级别的就没必要在通知了。抑制就是干这个用的
3. 静默
静默是一种在给定时间内简单地将警报静音的简单方法。静音是根据匹配器配置的,就像路由树一样。将检查传入警报是否与活动静默的所有相等或正则表达式匹配器匹配。如果这样做,则不会为该警报发送任何通知。 静默是在警报管理器的 Web 界面中配置的。场景就比如: 某一台机器设置了数据备份的定时任务,每天凌晨这段时间会占用大量CPU或内存,会超过阈值触发告警,那我们设置静默将其”静音“, 杜绝不必要的告警信息
整体实现思路
- 部署alertmanager
- 部署prometheus-webhook(实现钉钉告警的第三方插件)
- 在alertmanager.yml配置文件中配置邮箱服务器,模板路径,路由数,分组,接收人(定义接受的对象,如邮箱,微信,钉钉)
- 在prometheus-webhook配置文件config.yml中,来配置钉钉机器人的密钥与url(提前加好机器人),引用模板文件(就是alertmanager定义的模板)
- 配置Prometheus与Alertmanager通信
- 在Prometheus中创建告警规则
- 重启服务,测试
一. 安装Alertmanger
1.1 安装包下载
#alertmanager
地址1:https://prometheus.io/download/
地址2:https://github.com/prometheus/alertmanager/releases
#prometheus-webhook
https://github.com/timonwong/prometheus-webhook-dingtalk/releases
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v0.3.0/prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz
1.2 两个安装包解压安装在/opt/下
tar zxvf alertmanager-xxxx.tar.gz
ln -s alertmanager-0.24.0.linux-amd64 alertmanager
tar zxvf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz
ln -s prometheus-webhook-dingtalk-2.0.0.linux-amd64/ /opt/prometheus-webhook
1.3 两个服务service文件
alertmanager:
# cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
[Service]
ExecStart=/opt/alertmanager/alertmanager --config.file=/opt/alertmanager/alertmanager.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
prometheus-webhook:
# cat /usr/lib/systemd/system/prometheus-webhook.service
[Unit]
Description=Prometheus Dingding Webhook
[Service]
ExecStart=/opt/prometheus-webhook/prometheus-webhook-dingtalk --config.file=/opt/prometheus-webhook/config.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动服务
systemctl start alertmanager
systemctl start prometheus-webhook.service
二. 配置Prometheus
1. 配置Prometheus与Alertmanager通信
打开prometheus的配置文件 /opt/prometheus/prometheus.yml , /opt/prometheus/prometheus2.yml 分别进行修改(根据实际情况,有两个prometheus实例)
找到并修改为如下内容:
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "rules/*.yml"
2. 创建规则目录
mkdir -pv /opt/prometheus/rules
3. 配置规则
注意: 这里列举两个常用的规则文件,其余根据实际情况自行修改(可以去prometheus的web页面上自己先查一遍,看表达式是否正确查出数据)
a. 主机存活告警文件,分组名为servers_survival:
root@rancher2x.hw:/opt/prometheus/rules# cat servers_survival.yml
groups:
- name: servers_survival
rules:
- alert: 节点存活--测试--应用服务器 #告警规则名称
expr: up{job="hw-nodes-test-rancher"} == 0
for: 1m #等待评估时间
labels: #自定义标签,定义一个level标签,标记这个告警规则警告级别: critical严重,warning警告
level: critical
annotations: #指定附加信息(邮件标题文本)
summary: "机器 {{ $labels.instance }} 挂了"
description: "服务器{{$labels.instance}} 挂了 (当前值: {{ $value }})"
- alert: 节点存活--华为云--生产其他服务器
expr: up{job="hw-nodes-prod-other"} == 0
for: 1m
labels:
level: critical
annotations:
summary: "机器 {{ $labels.instance }} 挂了"
description: "{{$labels.instance}} 宕机(当前值: {{ $value }})"
- alert: 节点存活--华为云--生产ES服务器
expr: up{job="hw-nodes-prod-ES"} == 0
for: 1m
labels:
level: critical
annotations:
summary: "机器 {{ $labels.instance }} 挂了"
description: "{{$labels.instance}} 宕机(当前值: {{ $value }})"
b. 主机状态告警文件,分组名为servers_status:
root@rancher2x.hw:/opt/prometheus/rules# cat servers_status.yml
groups:
- name: servers_status
rules:
- alert: CPU负载1分钟告警
expr: node_load1{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"} / count (count (node_cpu_seconds_total{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"}) without (mode)) by (instance, job) > 2.5
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} 1分钟CPU负载(当前值: {{ $value }})"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job!~"(IDC-GPU|hw-nodes-prod-ES|nodes-test-GPU|nodes-dev-GPU)"}[30m])) by (instance) > 0.85
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU使用率告警 "
description: "{{$labels.instance}} CPU使用率超过85%(当前值: {{ $value }} )"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job=~"(IDC-GPU|hw-nodes-prod-ES)"}[30m])) by (instance) > 0.9
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} CPU使用率超过90%(当前值: {{ $value }})"
- alert: 内存使用率告警
expr: (1-node_memory_MemAvailable_bytes{job!="IDC-GPU"} / node_memory_MemTotal_bytes{job!="IDC-GPU"}) * 100 > 90
labels:
level: critical
annotations:
summary: "{{ $labels.instance }} 可用内存不足告警"
description: "{{$labels.instance}} 内存使用率已达90% (当前值: {{ $value }})"
- alert: 磁盘使用率告警
expr: 100 - (node_filesystem_avail_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*" } / node_filesystem_size_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*"}) * 100 > 85
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} 磁盘使用率告警"
description: "{{$labels.instance}} 磁盘使用率已超过85% (当前值: {{ $value }})"
4. 热加载prometheus配置
curl -X POST http://localhost:9090/-/reload
去web上查看确认rules是否被prometheus加载

1661222036735.png
三. 配置Alertmanger
上面配置了prometheus与alertmanager的通信,接下来我们配下alertmanager来实现发送告警信息给我们
这里我们主要以钉钉告警为例子
1. 钉钉上添加一个钉钉机器人,
设置好名字,群组,选择加签,确定。
2. 修改prometheus-webook配置文件绑定申请的机器人
我只绑定了一个webhook所以只要配置到webhook1
root@rancher2x.hw:/opt/prometheus-webhook# cat config.yml
## Customizable templates path
templates:
## - templates/alertmanager-dingtalk.tmpl
- /opt/alertmanager/dingding3.tmpl # 配置告警模板的所在位置
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxx # 配置机器人的webhook_url
# secret for signature
secret: SEC65342be21ab54b730da9347be9307b7831bd65adf1c99406fedc786f62fecb98 # 配置加签(申请的时候那串数字)
message:
title: '{{ template "ops.title" . }}' # 给这个webhook应用上 模板标题 (ops.title是我们模板文件中的title 可在下面给出的模板文件中看到)
text: '{{ template "ops.content" . }}' # 给这个webhook应用上 模板内容 (ops.content是我们模板文件中的content 可在下面给出的模板文件中看到)
3. 告警模板文件
root@rancher2x.hw:/opt/# cat /opt/alertmanager/dingding3.tmpl
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.level }}
**故障主机**: {{ .Labels.instance }}
**告警信息**: {{ .Annotations.description }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.level }}
**故障主机**: {{ .Labels.instance }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "ops.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "ops.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ops.link.title" }}{{ template "ops.title" . }}{{ end }}
{{ define "ops.link.content" }}{{ template "ops.content" . }}{{ end }}
{{ template "ops.title" . }}
{{ template "ops.content" . }}
4. 修改alertmanager配置文件为如下内容
注:这里也加上了邮件相关的配置
root@rancher2x.hw:/opt/alertmanager# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'xxx@163.com'
smtp_auth_username: 'xxxx@163.com'
smtp_auth_password: '邮箱的授权码'
smtp_require_tls: false
templates:
- '/opt/alertmanager/*.tmpl' #告警模板位置
route:
group_by: ['servers_survival','servers_status'] # 根据告警规则组名进行分组
group_wait: 30s # 分组内第一个告警等待时间,10s内如有第二个告警会合并一个告警
group_interval: 5m # 发送新告警间隔时间
repeat_interval: 30m #重复告警间隔发送时间,如果没处理过多久再次发送一次
receiver: 'dingtalk_webhook' # 接收人
receivers:
- name: 'ops'
email_configs:
- to: 'tianye@163.com'
html: '{{ template "email.to.html" .}}'
headers: { Subject: "[WARNING]Prometheus告警邮件" }
send_resolved: true
- name: 'dingtalk_webhook'
webhook_configs:
- url: 'http://localhost:8060/dingtalk/webhook1/send' # 填写prometheus-webhook的webhook1 url
send_resolved: true # 在恢复后是否发送恢复消息给接收人
5. 重启服务
systemctl restart prometheus-webhook.service
systemctl restart alertmanager.service
四. 测试
- 我们可以通过故意调整阈值 或者 停掉告警检测中主机上的node_exporter探针来测试一下
root@rs02.test.hw:~# systemctl stop node_exporter.service
-
prometheus上可以看到已经触发了告警规则阈值
![img]()
image.png
-
此时钉钉群里收到了告警邮件 (这里图示是恢复探针后,告警和恢复消息一起展示)
![img]()
1661223198483.png


以上只是初步使用 ,后面更新我们更好的利用好三大特性中的抑制和静默完成最佳实践
———————————————————————————————————————————————————
20220831更新:
Alertmanager之抑制
场景:
当我们的分级告警时,比如:
- 平时监控 server-01机器的存活,也监控这台机器的nginx服务存活时,当主机宕机后,我们会同时收到 server-01挂掉和nginx服务挂掉 两条警报(甚至连带更多),显然对我们来讲,这都是没必要发出的邮件,真正造成这个告警的原因是-主机宕机这个警告,所以我们只需要关注这个就好,别的没必要发了。
- 平时监控 jenkins主机的内存使用率,85%定为warnning级别,90%定为critical级别 ,在内存飙升的过程中,可能刚触发完85%又触发了90%,所以我们也会收到两个告警。比如下图:

image.png
所以这个情况需要,一段时间内,同一个主机的critical级别要抑制住warning级别,减少冗余发送。
操作
我们用监控nginx和docker服务做一个实践

image.png
分别停了nginx和docker服务后,收到两个告警。

image.png
恢复以上服务,现在只需要在alertmanager配置文件中加入(顶级配置),再次重启alertmanager
inhibit_rules:
# source_match: 匹配当前告警发生后其他告警抑制掉
- source_match:
level: 'critical'
# target_match:被抑制告警
target_match:
level: 'warning'
# equal: 只有包含指定标签才可成立规则,这里表示两个告警级别的主机都“相同”时,成功抑制 ,这里也可以写多个标签
equal: ['instance']
再次尝试停掉nginx和docker,可以看到只有critical的告警

image.png
Alertmanager之静默
场景
今晚有业务维护,需要停掉nginx服务,必然会发生警告,所以我们可以将这个告警提前 "静音"
操作
还是以上nginx服务告警为例。
打开alertmanager的web页面(127.0.0.1:9093),点击 New Silence,将匹配项填上去,完成创建。
匹配项:
可以是alertname(就是你prometheus中rules告警规则yml文件中的name),job ,instance,这些在Promethues中可用的都可以。

alertmanager静默.png
完成创建后,停掉nginx
systemctl stop nginx
告警已经触发,prometheus已经将警告给了alertmanager,但是alertmanager将这个项“静音”了,我们维护的时候不会收到告警

5.2. 准备资源配置清单
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'linux_hy_1992@163.com'
smtp_auth_username: 'linux_hy_1992@163.com'
smtp_auth_password: 'linux1992'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '1659775014@qq.com'
send_resolved: true
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com/public/alertmanager:v0.14.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
# Prometheus调用alert采用service name。不走ingress域名
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 9093
5.3. 应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/configmap.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/deployment.yaml
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/devops/prometheus/alertmanager/service.yaml
5.4. 添加告警规则
[root@hdss7-200 ~]# cat /data/nfs-volume/prometheus/etc/rules.yml # 配置中prometheus目录下
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
[root@hdss7-200 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml # 在末尾追加,关联告警规则
......
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"
# 重载配置文件,即reload
[root@hdss7-21 ~]# kubectl exec prometheus-78f57bbb58-6tcmq -it -n kube-system -- kill -HUP 1
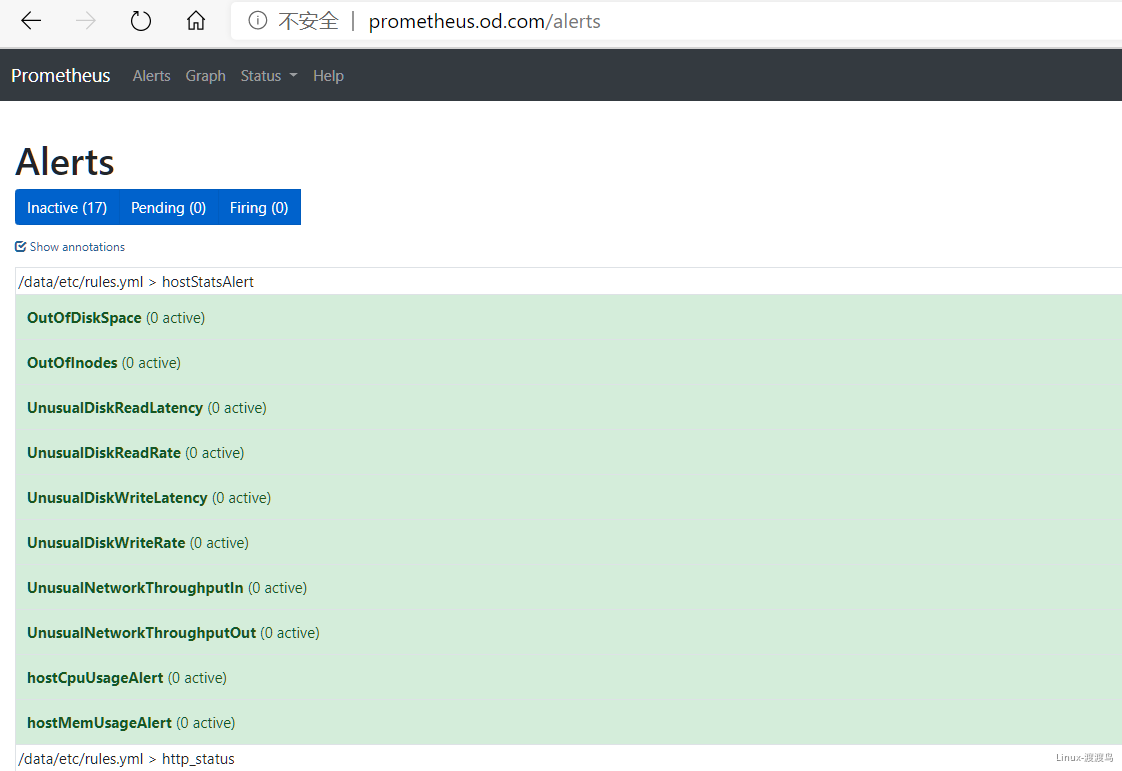
6. Prometheus的使用
6.1. Prometheus配置文件解析
# 官方文档: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
[root@hdss7-200 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s # 数据抓取周期,默认1m
evaluation_interval: 15s # 估算规则周期,默认1m
scrape_configs: # 抓取指标的方式,一个job就是一类指标的获取方式
- job_name: 'etcd' # 指定etcd的指标获取方式,没指定scrape_interval会使用全局配置
tls_config:
ca_file: /data/etc/ca.pem
cert_file: /data/etc/client.pem
key_file: /data/etc/client-key.pem
scheme: https # 默认是http方式获取
static_configs:
- targets:
- '10.4.7.12:2379'
- '10.4.7.21:2379'
- '10.4.7.22:2379'
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints # 目标资源类型,支持node、endpoints、pod、service、ingress等
scheme: https # tls,bearer_token_file都是与apiserver通信时使用
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: # 对目标标签修改时使用
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep # action支持:
# keep,drop,replace,labelmap,labelkeep,labeldrop,hashmod
regex: default;kubernetes;https
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:10255
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:4194
- job_name: 'kubernetes-kube-state'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]
regex: .*true.*
action: keep
- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']
regex: 'node-exporter;(.*)'
action: replace
target_label: nodename
- job_name: 'blackbox_http_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: http
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+);(.+)
replacement: $1:$2$3
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox_tcp_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [tcp_connect]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: tcp
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'traefik'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: keep
regex: traefik
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
alerting: # Alertmanager配置
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files: # 引用外部的告警或者监控规则,类似于include
- "/data/etc/rules.yml"
6.2. Pod接入Exporter
当前实验部署的是通用的Exporter,其中Kube-state-metrics是通过Kubernetes API采集信息,Node-exporter用于收集主机信息,这两项与Pod无关,部署完毕后直接使用即可。
根据Prometheus配置文件,可以看出Pod监控信息获取是通过标签(注释)选择器来实现的,给资源添加对应的标签或者注释来实现数据的监控。
6.2.1. Traefik接入
# 在traefik的daemonset.yaml的spec.template.metadata 加入注释,然后重启Pod
annotations:
prometheus_io_scheme: traefik
prometheus_io_path: /metrics
prometheus_io_port: "8080"
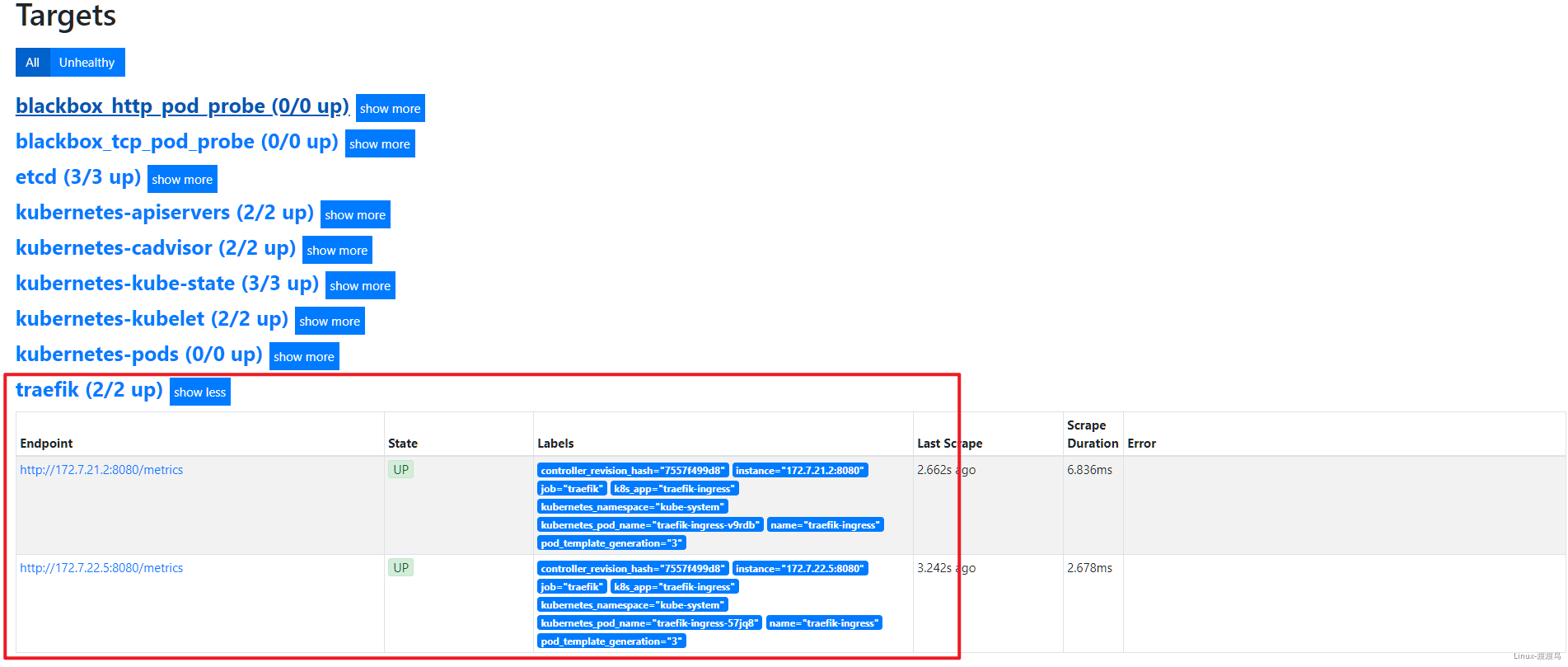
6.2.2. 接入Blackbox监控
# 在对应pod的注释中添加,以下分别是TCP探测和HTTP探测,Prometheus中没有定义其它协议的探测
annotations:
blackbox_port: "20880"
blackbox_scheme: tcp
annotations:
blackbox_port: "8080"
blackbox_scheme: http
blackbox_path: /hello?name=health
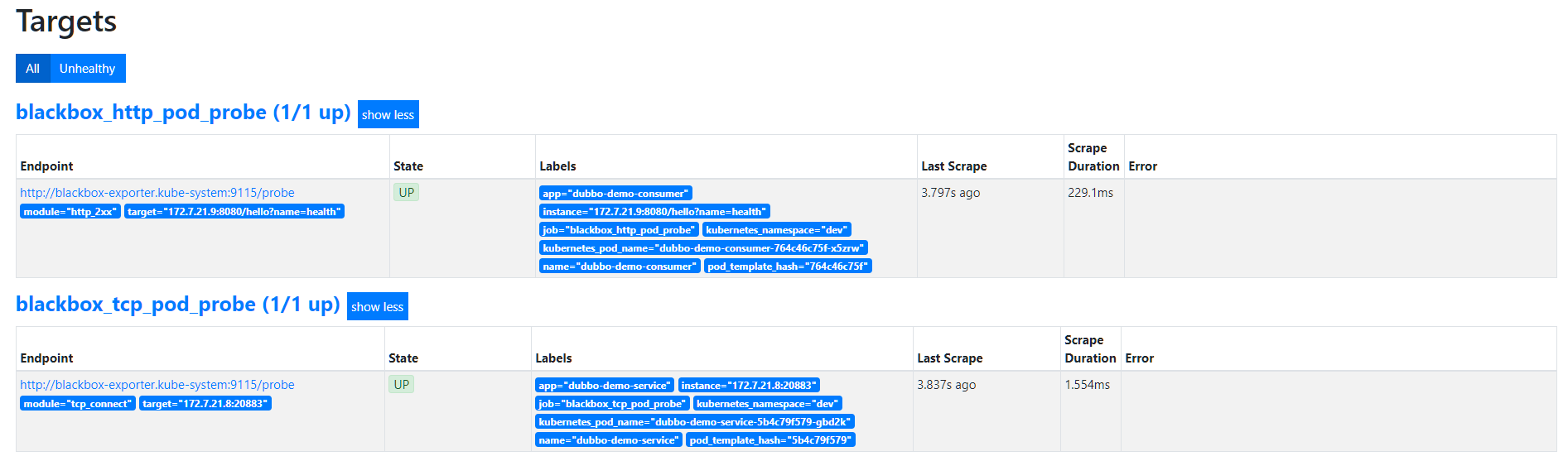
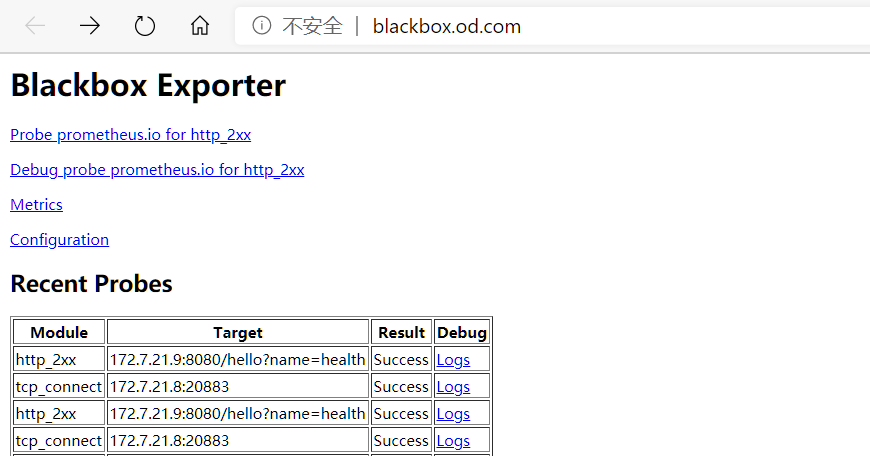
6.2.3. Pod接入监控
# 在对应pod的注释中添加,该信息是jmx_javaagent-0.3.1.jar收集的,开的端口是12346。true是字符串!
annotations:
prometheus_io_scrape: "true"
prometheus_io_port: "12346"
prometheus_io_path: /
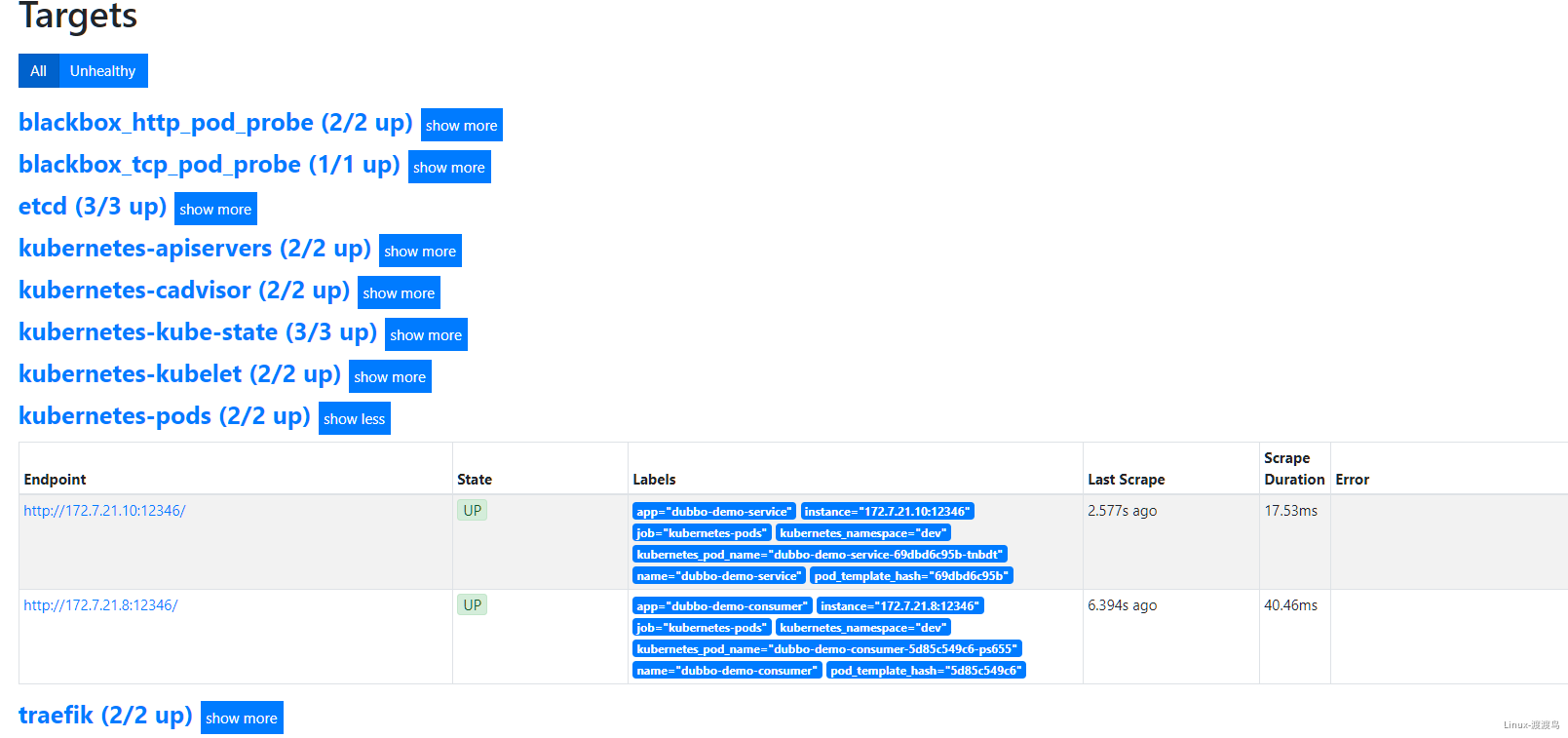
6.3. 测试Alertmanager
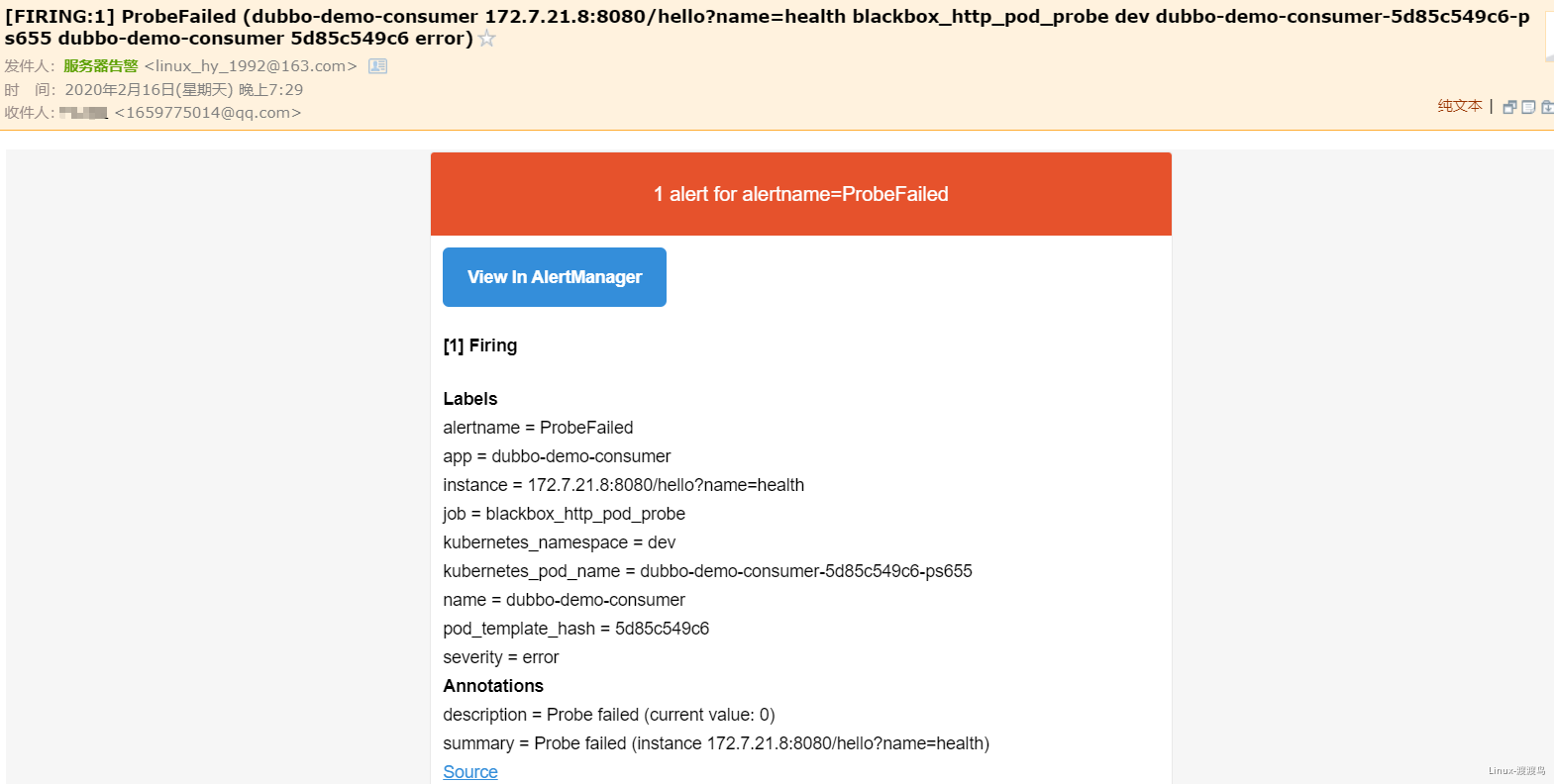
- 当停掉dubbo-demo-service的Pod后,blackbox的HTTP会探测失败,然后触发告警:
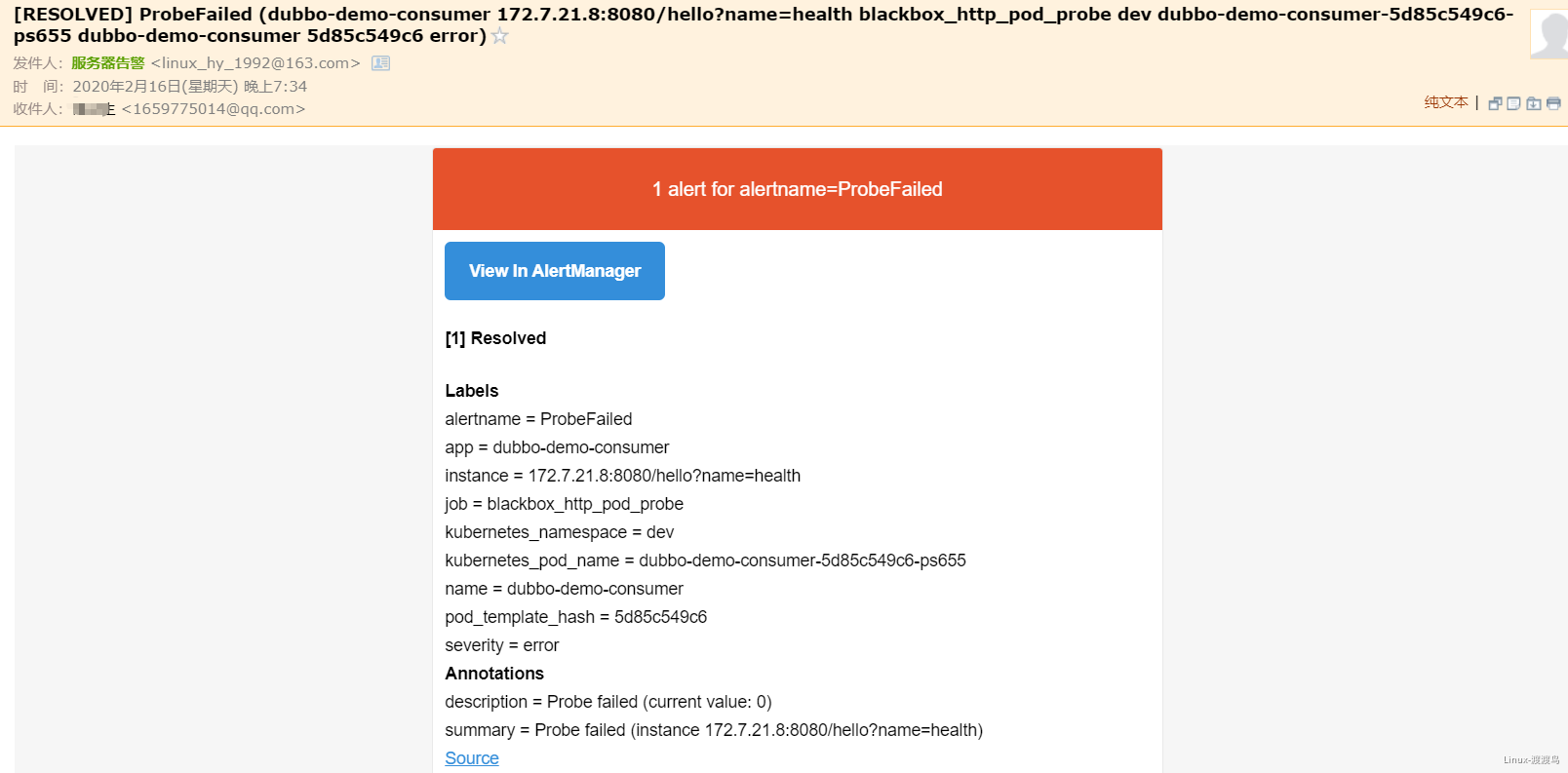
- 在此启动dubbo-demo-service的Pod后,告警恢复
#常用 exporter下载地址:
1.node_exporter下载
https://github.com/prometheus/node_exporter/releases
2.blackbox_exporter下载
https://github.com/prometheus/blackbox_exporter/releases
3.consul_exporter下载
https://github.com/prometheus/consul_exporter/releases
4.graphite_exporter下载
https://github.com/prometheus/graphite_exporter/releases
5.haproxy_exporter下载
https://github.com/prometheus/haproxy_exporter/releases
6.memcached_exporter下载
https://github.com/prometheus/memcached_exporter/releases
7.mysqld_exporter下载
https://github.com/prometheus/mysqld_exporter/releases
9.pushgateway下载
https://github.com/prometheus/pushgateway/releases
10.statsd_exporter下载
https://github.com/prometheus/statsd_exporter/releases
11.prometheus win版本下载
https://github.com/prometheus/prometheus/releases
12.prometheus Linux版本下载
https://github.com/prometheus/prometheus/releases
13.prometheus下载
https://github.com/prometheus/prometheus/releases
14.alertmanager下载
https://github.com/prometheus/alertmanager/releases
15.elasticsearch_exporter 下载
https://github.com/justwatchcom/elasticsearch_exporter/releases
16.redis_exporter下载
https://github.com/oliver006/redis_exporter/releases
17.snmp_exporter下载
https://github.com/prometheus/snmp_exporter/releases
18.kafka_exporter下载
https://github.com/danielqsj/kafka_exporter/releases
19.mysqld_exporter下载
https://github.com/prometheus/mysqld_exporter/releases
20.postgres_exporter下载
https://github.com/wrouesnel/postgres_exporter/releases
21.statsd_exporter下载
https://github.com/prometheus/statsd_exporter/releases
21.mongodb_exporter下载
https://github.com/percona/mongodb_exporter/releases
23.apache_exporter下载
https://github.com/Lusitaniae/apache_exporter/releases
24.mesos_exporter下载
https://github.com/mesos/mesos_exporter/releases
25.process-exporter下载
https://github.com/ncabatoff/process-exporter/releases
26.oracledb_exporter下载
https://github.com/iamseth/oracledb_exporter/releases
27.ebpf_exporter下载
https://github.com/cloudflare/ebpf_exporter/releases
28.grafana下载
Grafana安装包下载包:https://grafana.com/grafana/download
https://dl.grafana.com/oss/release
29.Prometheus下载地址
Prometheus安装包:https://prometheus.io/download/
https://github.com/prometheus/prometheus/releases

 浙公网安备 33010602011771号
浙公网安备 33010602011771号