ORM
ORM简介
- MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。(Object Relational Mapping,简称ORM)(将来会学一个sqlalchemy,是和他很像的,但是django的orm没有独立出来让别人去使用,虽然功能比sqlalchemy更强大,但是别人用不了)
- 类对象--->sql--->pymysql--->mysql服务端--->磁盘,orm其实就是将类对象的语法翻译成sql语句的一个引擎,明白orm是什么了,剩下的就是怎么使用orm,怎么来写类对象关系语句。
ORM基本使用
创建模型类
在应用文件夹的models.py文件中写上如下内容
# 属性对应的字段,默认都是不能为空的,也就是加了not null约束
class Book(models.Model):
# 如果没有指定主键字段,默认orm会给这个表添加一个名称为id的主键自增字段
# 如果制定了,以指定的为准,那么orm不在创建那个id字段了
# nid = models.AutoField(primary_key=True) #int primary_key auto_increment,
title = models.CharField(max_length=32) #varchar 书籍名称
# price = models.FloatField() #
price = models.DecimalField(max_digits=5, decimal_places=2) # 999.99 价格
pub_date = models.DateField() # date 出版日期
publish = models.CharField(max_length=32) #出版社名称
# xx = models.CharField(max_length=18, null=True, blank=True) # null=True,blank=True允许该字段数据为空
# xx = models.CharField(max_length=18, default='xxx') # null=True,blank=True允许该字段数据为空
Book生成的表名称为 应用名称_模型类名小写
python manage.py makemigrations
#这个命令会生成新的数据库迁移文件,
生成migrations文件夹的000x开头的文件
python manage.py migrate
# 执行init.py
# 运行 python manage.py migrate 命令会将通过 makemigrations 生成的数据库迁移文件应用到数据库中
ORM联接Mysql
1 创建数据库
create database orm01 charset=utf8mb4;
2 settings.py配置文件中写上如下内容
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'orm01',
'HOST':'127.0.0.1',
'PORT':3306,
'USER':'root',
'PASSWORD':'', #有密码的填密码
}
}
3 安装pymysql
pip install pymsyql
4 在项目主目录下的__init__.py文件中写上如下内容
import pymysql
pymysql.install_as_MySQLdb()
5 执行数据库同步指令
python manage.py migrate
只要换了新的数据库,migrate会重新执行migrations文件
ORM的增删改查
[!WARNING]
get返回的是模型类对象 不能使用一些方法
增加
# 添加数据记录 方式1
new_book = models.Book(
# id=2,
title='金太郎',
price=9.9,
# pub_date=datetime.datetime.now(), #添加时间日期类型数据时可以是时间日期类型的数据,也可以是字符串数据
pub_date='2022-02-02',
publish='32期红浪漫出版社'
# 有默认值的或者可以为空的或者主键字段,都可以不用传值
)
new_book.save()
# 添加方式2 create方法,create方法的返回值为 新添加的数据的模型类对象
new_book = models.Book.objects.create(
title='金太郎4',
price=19.9,
# pub_date=datetime.datetime.now(),
pub_date='2022-04-02',
publish='32期红浪漫出版社'
)
print(new_book.title) #通过模型类对象,直接获取属性对应的值
print(new_book.price)
print(type(new_book)) # <class 'app1.models.Book'> 都是app1.models.Book
"""批量添加"""
obj_list = []
for i in range(10):
book_obj = models.Book(
title=f'少年阿宾{i}',
price=10 + i,
pub_date=f'2022-04-1{i}',
publish='32期红浪漫出版社'
)
obj_list.append(book_obj)
models.Book.objects.bulk_create(obj_list) # bulk_create 批量添加
查询
# models.py下
def __str__(self):
return self.title
"""
方便打印QuerySet类型
方便打印<QuerySet [<Book: 金太郎>, <Book: 金太郎>, <Book: 金太郎4>, <Book: 少年阿宾0>, <Book: 少年阿宾1>, <Book: 少年阿宾2>, <Book: 少年阿宾3>, <Book: 少年阿宾4>, <Book: 少年阿宾5>, <Book: 少年阿宾6>, <Book: 少年阿宾7>, <Book: 少年阿宾8>, <Book: 少年阿宾9>]>
"""
# 返回queryset 类似于列表 可用[0]取 除了get都返回queryset
book_objs = models.Book.objects.all()
book_objs = models.Book.objects.filter(id=3)
models.Book.objects.filter() # 同all
models.Book.objects.filter(id=100) #查不到数据,不会保存,返回空干的queryset类型数据
book_objs = models.Book.objects.get(id=3) #条件查找 结果为: 模型类对象
models.Book.objects.get() 也是查所有 #error
# 但是get方法的查询结果有要求,有且只能有一条
# 查询结果多于一条也会报错
删
models.Book.objects.filter(id=3).delete() queryset类型数据可以调用delete方法删除查询结果数据
models.Book.objects.get(id=4).delete() 模型类对象也可以调用delete方法删除数据
改
# 修改方式1 通过queryset类型数据修改
models.Book.objects.filter(id=5).update(
price=20,
title='xxxx'
)
# 修改方式2 通过模型类对象来修改
ret = models.Book.objects.get(id=5)
ret.price = 30
ret.title = '少年阿宾00'
ret.save()
一些时间参数
# 数据库中DatetimeField、DateField、TimeField这个三个时间字段,都可以设置如下属性
(7)auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
(8)auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段,标识这条记录最后一次的修改时间。
models.userinfo.objects.filter(id=1).update(
#update不能触发自动更新时间的auto_now参数的作用,
# 如果用update方法来更新记录,并保存更新记录的时间,需要我们手动给该字段传入当前时间
# name='xxoo',
# b1=datetime.datetime.now()
#
# )
# 这种save方式能够触发auto_now参数自动更新修改时间的动作
ret = models.userinfo.objects.get(id=2)
ret.name='xxoo2'
ret.save()
"""
django默认用的utc时间来操作时间数据,
如果需要改为本地时区来存储时间,那么需要修改django的配置文件
在settings.py文件中修改如下内容
"""
```python
# USE_TZ = True
USE_TZ = False
```
模糊查询
[!IMPORTANT]
通过字段加双下划线
#基于双下划线的模糊查询
# 查询书名以少年开头的哪些书
# obj_list = models.Book.objects.filter(title__startswith='少年') #以什么开头
# obj_list = models.Book.objects.filter(title__endswith='梅') #以什么结尾
# obj_list = models.Book.objects.filter(title__startswith='p') #区分大小写
# obj_list = models.Book.objects.filter(title__istartswith='p') #不区分大小写
# obj_list = models.Book.objects.filter(title__contains='th') #包含
# obj_list = models.Book.objects.filter(title__icontains='th') #包含 不区分大小写
# obj_list = models.Book.objects.filter(price__gt=15) 大于
# obj_list = models.Book.objects.filter(price__gte=15) 大于等于
# obj_list = models.Book.objects.filter(price__lt=15) 小于
# obj_list = models.Book.objects.filter(price__lte=15) 小于等于
# obj_list = models.Book.objects.filter(price=15 or price=18 or price=30)
# obj_list = models.Book.objects.filter(price__in=[15,18,30]) 价格等于15或者等于18或者等于30的书籍
# obj_list = models.Book.objects.filter(price__range=[15, 20]) #价格大于等于15并且小于等于20, between and
# obj_list = models.Book.objects.filter(id=10, price=15) #逗号连接的查询条件就是and的关系
# obj_list = models.Book.objects.filter(pub_date__year='2020') #2020年的所有书籍
# obj_list = models.Book.objects.filter(pub_date__year='2020',pub_date__month='11') #2020年11月份的所有书籍
# obj_list = models.Book.objects.filter(pub_date__year='2020',pub_date__month='11',pub_date__day='25') #2020年11月5号的所有书籍
obj_list = models.Book.objects.filter(pub_date='2020-11-25') #2020年11月5号的所有书籍
print(obj_list)
```
ORM查询常用API
exclude
"""
返回结果为queryset类型数据,通过objects控制器可以调用,queryset类型数据也能调用
"""
obj_list = models.Book.objects.exclude(id=2)
obj_list = obj_list.filter(title='少年阿宾1')
obj_list = obj_list.all()
obj_list = models.Book.objects.exclude(id=2).filter(title__contains='少年').exclude(id=5)
order_by
# 返回结果为queryset类型数据,queryset类型数据可以调用这个方法 默认升序
obj_list = models.Book.objects.all().order_by('-id') #-id加个-号表示按照该字段降序排列, desc asc
'''select * from app01_book order by id desc;'''
obj_list = models.Book.objects.all().order_by('price', '-id') #按照价格升序排列,价格相同的按照id降序排列
reverse
# 翻转必须在排序数据的基础上
# 返回结果为queryset类型数据,queryset类型数据可以调用这个方法
obj_list = models.Book.objects.all().order_by('-id').reverse()
count
# queryset类型数据可以调用这个方法,返回值为数字
obj_list = models.Book.objects.all().count()
exists
# queryset类型数据可以调用这个方法,返回值为模型类对象
obj_list = models.Book.objects.all().first()
obj_list = models.Book.objects.all()[0]
values
# 可以获取指定字段数据
objects可以调用, queryset也能调用,返回结果还是queryset,内容为一个个字典数据
obj_list = models.Book.objects.values('title', 'price')
obj_list = models.Book.objects.filter(id=5).values('title', 'price')
values_list
# 可以获取指定字段数据,返回结果还是queryset,内容为一个个元组数据
obj_list = models.Book.objects.values_list('title', 'price')
obj_list = models.Book.objects.filter(id=5).values_list('title', 'price')
distinct
obj_list = models.Book.objects.values('price').distinct()
print(obj_list)
ORM多表创建
from django.db import models
# Create your models here.
# 作者表
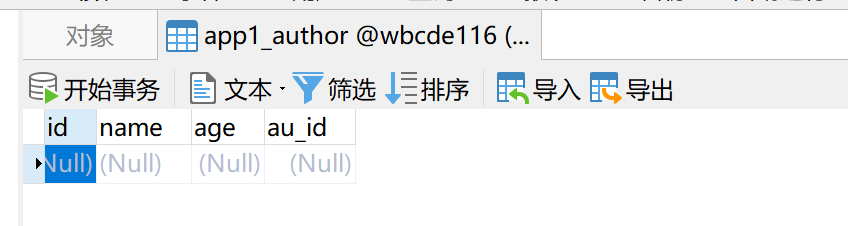
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# django2.x版本必须手动指定on_delete=models.CASCADE级联模式
# 一对一关系 foreign key + unique
au = models.OneToOneField(to="AuthorDetail", to_field="id", on_delete=models.CASCADE)
# au = models.OneToOneField("AuthorDetail") 可省略
# au = models.IntegerField() # 一般为了防止联级更新这么设置
# au = models.OneToOneField("AuthorDetail", db_constraint=False) # 取消约束效果 防止联级更新
# db_constraint=False取消foreign key的强制约束效果,还可以继续使用orm的提供的属性或者方法来操作关系记录
# 作者详细信息表 一些不常用的信息单独放在一个表 为了快速查询
class AuthorDetail(models.Model):
birthday = models.DateField()
telephone = models.BigIntegerField()
addr = models.CharField(max_length=64)
# 出版社表
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
# 书籍表
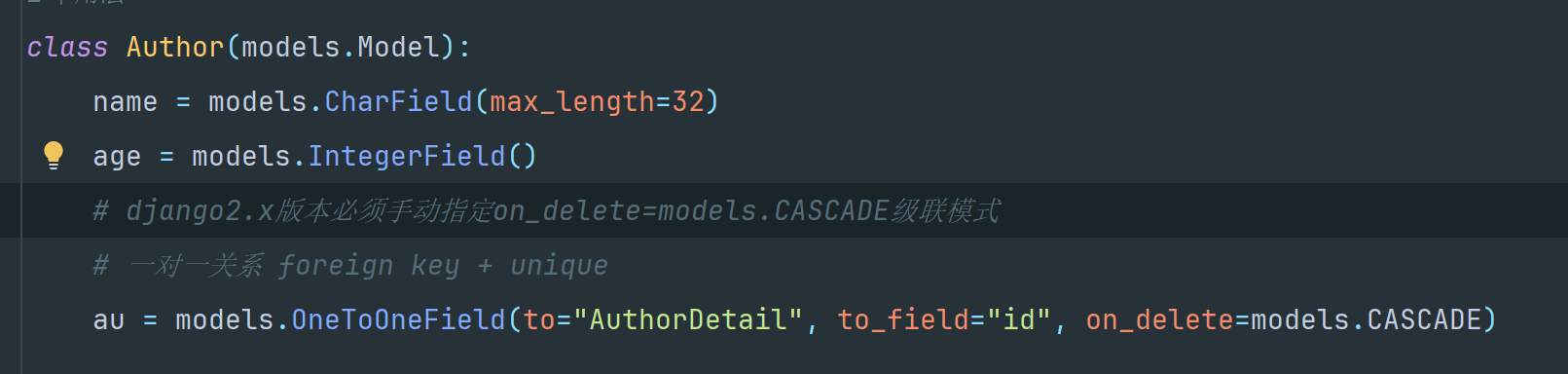
class Book(models.Model):
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=5, decimal_places=2)
# 一对多
publishs = models.ForeignKey(to="Publish", to_field="id", on_delete=models.CASCADE)
# 同创建下面注释的第三张表实现多对多
authors = models.ManyToManyField('Author') # 见图的表名
# class authortobook(models.Model):
# book_id = models.ForeignKey('Book')
# author_id = models.ForeignKey('Author')
一对一的外键
[!IMPORTANT]
属性是OneToOneField或者ForeignKey,那么生成的对应字段是 属性名称_id 见图
多对多生成的表名

多表的增
一对一的关系增加
ret = models.AuthorDetail.objects.create(
birthday='2000-12-12',
telephone=176,
addr='惠州',
)
print(type(ret))
# <class 'app1.models.AuthorDetail'>
models.Author.objects.create(
name='元涛',
age=18,
# au_id=ret.id, #如果用的是属性名称_id,那么值为关联记录的id值
au=ret, # 如果写属性名称来添加关系数据,那么值为关联记录的模型类对象
)
一对多的关系增加
# 一对多
# pub_obj = models.Publish.objects.get(id=1)
models.Book.objects.create(
title='白洁2',
price=10,
publishDate='1980-07-07',
# publishs=pub_obj, #如果写属性名称来添加关系数据,那么值为关联记录的模型类对象
publishs_id=2,
)
return HttpResponse("ok")
多对多的关系增加
# 多对多
book_obj = models.Book.objects.get(title='金鳞岂是池中物')
author1 = models.Author.objects.get(id=1)
author2 = models.Author.objects.get(id=2)
book_obj.authors.add(author1,author2) # 可以以类对象添加
book_obj.authors.add(1, 2) # 也可以以值
多表的删除
级联删除只会级联删除带有外键的表
# 删除 # 外键关联到这条作者记录的都会被删除(级联模式下)
# 一对一
models.AuthorDetail.objects.get(id=2).delete()
# 一对多
models.Book.objects.get(id=1).delete()
# 多对多删除
book_obj = models.Book.objects.get(id=4)
book_obj.authors.remove(1) # 4 1 删除第三张表中id为4 并且作者id为1的记录
book_obj.authors.clear() # 清空 第三张表中的书籍id为5的所有记录
book_obj.authors.remove(1, 4) #删除多条 # 41 44
book_obj.authors.remove(*[1, 4]) #删除多条
多表的修改
# 一对一
models.Author.objects.filter(id=3).update(
age=38,
au_id=5,
# au=models.AuthorDetail.objects.get(id=5),
)
# 一对多
models.Book.objects.filter(id=4).update(
title='白洁1',
# publishs=models.Publish.objects.get(id=2),
publishs_id=2
)
# 多对多
obj = models.Book.objects.get(id=5)
obj.authors.set(['1','3']) #clear + add 跟新,先清空book_id为5的第三张表里的记录,再添加5 1和5 3记录
多表的查询子查询
基于子查询(嵌套查询)
一对一的查询
# 一对一的
#正向查询(关系属性在哪个表里面,通过这个表的数据去查询另外一张表的数据,就是正向查询)
# 正向查询靠属性,反向查询靠表名小写
# 查询一下闻哥这个作者的手机号
obj = models.Author.objects.get(name='闻哥')
# obj.au #这就找到了关联的详细信息表里面的那个记录对象
print(obj.au.telephone)
# 查询手机号为555的作者姓名
# 反向查询 一对一不用小写
obj = models.AuthorDetail.objects.get(telephone='555')
obj.author #这就找到了关联的作者表表里面的那个记录对象
print(obj.author.name)
一对多的查询
# 方法一
# 一对多
# 正向查询
查询白洁1这本书是哪个出版社出版的
obj = models.Book.objects.get(title='白洁1')
obj.publishs #找到了关联的出版社记录
print(obj.publishs.name)
# 查询闻哥出版社出版了哪些书
# 反向查询
# 反向查询在一对多的关系是,使用 表名小写_set
obj = models.Publish.objects.get(name='闻哥出版社')
books = obj.book_set.all()
for book in books:
print(book.title)
多对多的查询
# 多对多
# 查询一下白洁2这本书的作者是谁
# 正向查询
obj = models.Book.objects.filter(title='白洁2').first()
obj.authors.all() #类似objects控制器
objs = obj.authors.all()
for i in objs:
print(i.name)
# 查询一下何导写了哪些书
# 反向查询
obj = models.Author.objects.get(name='何导')
objs = obj.book_set.all()
for i in objs:
print(i.title)
多表查询双下划线查询/join查询
#####基于双下划线的跨表查询 -- mysql连表查询
# select app01_authordetail.telephone from app01_author inner join app01_authordetail on app01_author.au_id = app01_authordetail.id;
# select app01_authordetail.telephone from app01_authordetail inner join app01_author on app01_author.au_id = app01_authordetail.id;
# 正向查询靠属性, 反向查询靠表名小写 正向方向只是join的前后位置
# 一对一的
# 查询一下闻哥这个作者的手机号
ret = models.Author.objects.filter(name='闻哥').values('au__telephone')
<QuerySet [{'au__telephone': '222'}]>
# 反向查询 表名小写__键
ret = models.AuthorDetail.objects.filter(author__name='闻哥').values('telephone')
print(ret) #<QuerySet [{'telephone': '222'}]>
# 一对多的
# 查询白洁1这本书是哪个出版社出版的
ret = models.Book.objects.filter(title='白洁1').values('publishs__name')
<QuerySet [{'publishs__name': '闻哥出版社'}]>
print(ret)
ret = models.Publish.objects.filter(book__title='白洁1').values('name')
print(ret) #<QuerySet [{'name': '闻哥出版社'}]>
# 多对多
# 查询一下白洁2这本书的作者是谁
ret = models.Book.objects.filter(title='白洁2').values('authors__name')
<QuerySet [{'authors__name': '闻哥'}, {'authors__name': '何导'}]>
print(ret)
ret = models.Author.objects.filter(book__title='白洁2').values('name')
print(ret) #<QuerySet [{'name': '何导'}, {'name': '闻哥'}]>
多表聚合查询
from django.db.models import Avg,Max,Min,Sum,Count
# 查询所有书籍的平均价格
"""
group 后 返回字典数据 aggregate
"""
# 以下返回一样
ret = models.Book.objects.all().aggregate(Avg('price'))
ret = models.Book.objects.aggregate(Max('price'),Avg('price'))
{'price__max': Decimal('19.00')} # 字典类型数据
# 取别名
ret = models.Book.objects.aggregate(m=Max('price'), a=Avg('price'))
# 取出需要的值
ret = models.Author.objects.annotate(m=Max('book__price')).values('name','m')
# <QuerySet [{'name': '苑昊', 'm': None}, {'name': '何导', 'm': Decimal('17.00')}, {'name': '闻哥', 'm': Decimal('19.00')}]>
多表分组查询
# 查询一下每个出版社出版书的平均价格
# 默认是用Publish的id字段值作为分组依据,自动会找book表里面的publishs_id去分组
# 只annotate分组 不取values 是一个 <QuerySet [<Publish: Publish object (1)>]>
ret = models.Publish.objects.annotate(a=Avg('book__price')).values('a','name','city')
#<QuerySet [{'name': '32期桔色成人出版社', 'city': '沙河', 'a': 12.5}, {'name': '闻哥出版社', 'city': '松兰堡', 'a': 14.0}, {'name': '牡丹花出版社', 'city': '洛阳', 'a': 13.75}]>
"""
SELECT `app1_publish`.`name`, `app1_publish`.`city`, AVG(`app1_book`.`price`) AS `a` FROM `app1_publish` LEFT OUTER JOIN `app1_book` ON (`app1_publish`.`id` = `app1_book`.`publishs_id`) GROUP BY `app1_publish`.`id` ORDER BY NULL LIMIT 21;
"""
ret = models.Book.objects.values('publishs_id').annotate(a=Avg('price'))
# select avg(price) from app01_book group by publishs_id;
# print(ret)
ORM操控锁
# 原生sql加锁
select * from app01_book where id=1 for update; # 手动加锁
orm加锁
models.Book.ojects.filter(id=1).select_for_update()
#用法1:给函数做装饰器来使用
from django.db import transaction
@transaction.atomic
def viewfunc(request):
d1 = {
'name':'chao',
}
username = request.GET.get('name')
sid = transaction.savepoint() #创建保存点
models.Book.ojects.filter(id=1).select_for_update() # 挂锁
do_stuff() # 可以写一些处理Mysql的语句
try:
# 一些py判断代码
except:
#保存点一般是代码运行路基过程中,代码出了问题,需要手动回滚事务时使用
transaction.savepoint_rollback(sid) #回滚到保存点
return HttpResponse('别瞎搞,滚犊子')
# 用法2:作为上下文管理器来使用
from django.db import transaction
def viewfunc(request):
do_stuff() #sql 不在事务里
with transaction.atomic():
# This code executes inside a transaction.
do_more_stuff() #sql 在事务里
do_other_stuff() #不在事务里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号