多线程
多进程
进程的概念
进程就是正在运行的程序,它是操作系统中,资源分配的最小单位.
资源分配:分配的是cpu和内存等物理资源
进程号是进程的唯一标识同一个程序执行两次之后是两个进程
进程和进程之间的关系: 数据彼此隔离,通过socket通信
并行与并发
并发:一个cpu同一时间不停执行多个程序
并行: 多个cpu同一时间不停执行多个程序
进程调度
# 先来先服务fcfs(first come first server):先来的先执行
# 短作业优先算法:分配的cpu多,先把短的算完
# 时间片轮转算法:每一个任务就执行一个时间片的时间.然后就执行其他的.
# 多级反馈队列算法
越是时间长的,cpu分配的资源越少,优先级靠后
越是时间短的,cpu分配的资源越多
进程的三态图
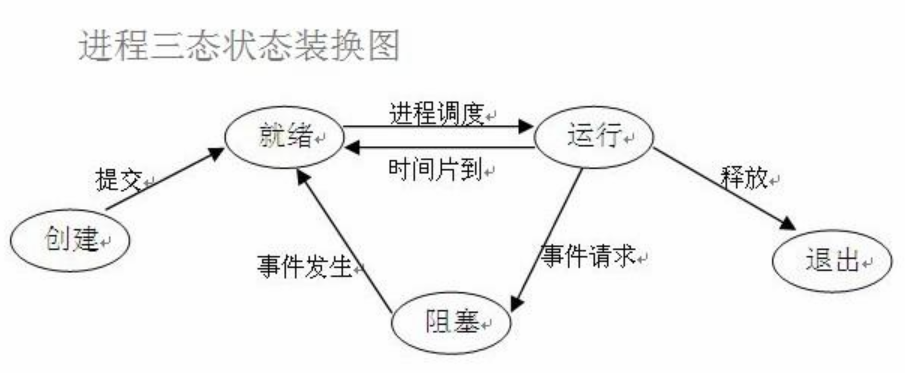
(1)就绪(Ready)状态
只剩下CPU需要执行外,其他所有资源都已分配完毕 称为就绪状态。
(2)执行(Running)状态
cpu开始执行该进程时称为执行状态。
(3)阻塞(Blocked)状态
由于等待某个事件发生而无法执行时,便是阻塞状态,cpu执行其他进程.例如,等待I/O完成input、申请缓冲区不能满足等等。
代码理解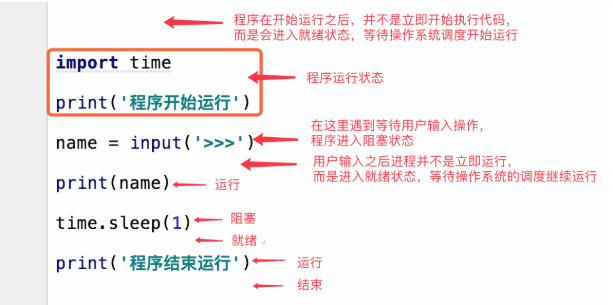
同步 异步 / 阻塞 非阻塞
场景在多任务当中
同步:必须等我这件事干完了,你在干,只有一条主线,就是同步
异步:没等我这件事情干完,你就在干了,有两条主线,就是异步
阻塞:比如代码有了input,就是阻塞,必须要输入一个字符串,否则代码不往下执行
非阻塞:没有任何等待,正常代码往下执行.
# 同步阻塞 :效率低,cpu利用不充分
# 异步阻塞 :比如socketserver,可以同时连接多个,但是彼此都有recv
# 同步非阻塞:没有类似input的代码,从上到下执行.默认的正常情况代码
# 异步非阻塞:效率是最高的,cpu过度充分,过度发热 液冷
python的多进程理解
进程的使用
import os
"""
# 获取当前进程号
res = os.getpid()
print(res)
# 获取当前进程的父进程
res = os.getppid()
print(res) 单个来看是pycharm
"""
from multiprocessing import Process
def func():
# 1.子进程id:3561,2.父进程id:3560
print("1.子进程id:{},2.父进程id:{}".format(os.getpid(),os.getppid()))
if __name__ == "__main__":
# 在windos下需要使用这个主程序判断 不然会递归报错 开启子进程类似于粘贴到另一个文件中
# 创建子进程 ,返回进程对象
p = Process(target=func)
# 调用子进程
p.start()
# 3.主进程id:3560,4.父进程id:3327
print("3.主进程id:{},4.父进程id:{}".format(os.getpid(),os.getppid()))
# 整体异步执行 顺序未知
带有参数的进程
# ### 进程 process
# 整体异步执行 顺序未知
import os
from multiprocessing import Process
# (2) 创建带有参数的进程
def func(n):
time.sleep(1)
for i in range(1,n+1): # 0 ~ n-1
print(i)
print("1.子进程id:{},2.父进程id:{}".format(os.getpid(),os.getppid()))
if __name__ == "__main__":
n = 6
# target=指定任务 args = 参数元组
p = Process(target=func , args=(n,)) # 需要,来说明是一个元祖进行传惨
p.start()
for i in range(1,n+1):
print("*" * i)
进程之间的数据隔离
from multiprocessing import Process
import time
total = 100
def func():
global total
total += 1
print(total)
if __name__ == "__main__":
p = Process(target=func)
p.start() # 101
print(total) # 100
进程之间的异步性
"""
1.多个进程之间是异步的并发程序,因为cpu调度策略问题,不一定先执行哪一个任务
默认来看,主进程执行速度稍快于子进程,因为子进程创建时,要分配空间资源可能会阻塞
阻塞态,cpu会立刻切换任务,以让程序整体的速度效率最大化
2.默认主进程要等待所有的子进程执行结束之后,在统一关闭程序,释放资源
若不等待,子进程可能不停的在系统的后台占用cpu和内存资源形成僵尸进程.
为了方便进程的管理,主进程默认等待子进程.在统一关闭程序;
"""
def func(n):
print("1.子进程id:{},2.父进程id:{}".format(os.getpid(),os.getppid()) , n )
if __name__ == "__main__":
for i in range(1,11):
p = Process(target=func,args=(i,))
p.start()
print("主进程执行结束了 ... " , os.getpid() )
同步进程
join基本语法
import os
from multiprocessing import Process
def func():
print("发送第一封邮件 : 我的亲亲领导,你在么?")
if __name__ == "__main__":
p = Process(target=func)
p.start()
p.join() # 小阻塞 在子进程结束时立刻运行后续代码
print("发送第二封邮件 : 我想说,工资一个月给我涨到6万")
多进程中的场景
def func(i):
time.sleep(1)
print("发送第一封邮件{} : 我的亲亲领导,你在么?".format(i))
if __name__ == "__main__":
lst = []
for i in range(1,11):
p = Process(target=func,args=(i,))
p.start()
# join 写在里面会导致程序变成同步 运行一个子程序就会阻塞
lst.append(p)
# 把所有的进程对象都放在列表中,统一使用.join进行管理;
for i in lst:
i.join()
print("发送第二封邮件 : 我想说,工资一个月给我涨到6万")
自定义进程类
基本语法
import os
from multiprocessing import Process
# 继承多进程的派生
class MyProcess(Process):
def run(self):
print("1.子进程id:{},2.父进程id:{}".format(os.getpid(),os.getppid()))
if __name__ == "__main__":
p = MyProcess()
p.start()
带有参数的自定义进程类
import os
from multiprocessing import Process
class MyProcess(Process):
def __init__(self,name):
# 手动调用一下父类的构造方法,完成父类成员的初始化;
super().__init__()
self.name = name
def run(self):
print("1.子进程id:{},2.父进程id:{}".format(os.getpid(),os.getppid()))
print(self.name)
if __name__ == "__main__":
p = MyProcess("我是参数")
p.start()
守护进程
[!IMPORTANT]
当主程序结束时 立即杀死守护进程 kill
基础语法
from multiprocessing import Process
import time
def func():
print("start... 当前的子进程")
print("end ... 当前的子进程")
if __name__ == "__main__":
p = Process(target=func)
# 在进程启动之前,设置守护进程
p.daemon = True
p.start()
print("主进程执行结束 ... ")
监控报活
ef alive():
while True:
print("3号服务器向总监控服务器发送报活信息: i am ok~")
time.sleep(1)
def func():
while True:
try:
print("3号服务器负责抗住3万用户量的并发访问...")
time.sleep(3)
# 主动抛出执行错误的异常,触发except分支
raise RuntimeError
except:
print("3号服务器扛不住了.. 快来修理我..")
break
if __name__ == "__main__":
p1 = Process(target=alive)
p2 = Process(target=func)
p1.daemon = True
p1.start()
p2.start()
# 必须等待p2这个子进程执行完毕之后,再放行主进程下面的代码
# 下面主进程代码执行结束,立刻杀死守护进程,失去了报活功能;
p2.join()
print("主进程执行结束 .... ")
Lock
基本语法
from multiprocessing import Process,Lock
# 底层通过socket共享状态
# 创建一把锁
lock = Lock()
# 上锁
lock.acquire()
# lock.acquire() # 连续上锁,造成了死锁现象;
print("我在袅袅炊烟 .. 你在焦急等待 ... 厕所进行时 ... ")
# 解锁
lock.release()
对于Lock的使用
# 1.读写数据库当中的票数
def wr_info(sign , dic=None):
if sign == "r":
with open("ticket",mode="r",encoding="utf-8") as fp:
dic = json.load(fp)
return dic
elif sign == "w":
with open("ticket",mode="w",encoding="utf-8") as fp:
json.dump(dic,fp) # 向其写入 字典形式的票数
# dic = wr_info("w",dic={"count":0}) # 写入票数
# 2.执行抢票的方法
def get_ticket(person):
# 先获取数据库中实际票数
dic = wr_info("r")
# 模拟一下网络延迟
time.sleep(random.uniform(0.1,0.7))
# 判断票数
if dic["count"] > 0:
print("{}抢到票了".format(person))
# 抢到票后,让当前票数减1
dic["count"] -= 1
# 更新数据库中的票数
wr_info("w",dic)
else:
print("{}没有抢到票哦".format(person))
# 3.对抢票和读写票数做一个统一的调用
def main(person,lock):
# 查看剩余票数
dic = wr_info("r")
print("{}查看票数剩余: {}".format(person,dic["count"]))
# 上锁
lock.acquire()
# 开始抢票
get_ticket(person)
# 解锁
lock.release()
if __name__ == "__main__":
lock = Lock()
lst = ["梁新宇","康裕康","张保张","于朝志","薛宇健","韩瑞瑞","假摔先","刘子涛","黎明辉","赵凤勇"]
# 多线程调用 创建的是抢票的异步程序 执行是同步
for i in lst:
p = Process( target=main,args=( i , lock ) )
p.start()
"""
创建进程,开始抢票是异步并发程序
直到开始抢票的时候,变成同步程序,
先抢到锁资源的先执行,后抢到锁资源的后执行;
按照顺序依次执行;是同步程序;
"""
Semphore
Semaphore 本质上就是锁,只不过是多个进程上多把锁,可以控制上锁的数量
基本语法
from multiprocessing import Semaphore , Process
import time , random
# 同一时间允许多个进程上5把锁
sem = Semaphore(5)
#上锁
sem.acquire()
print("执行操作 ... ")
#解锁
sem.release()
对于Semphore使用
from multiprocessing import Semaphore , Process
import time , random
def singsong_ktv(person,sem):
# 上锁
sem.acquire()
print("{}进入了唱吧ktv , 正在唱歌 ~".format(person))
# 唱一段时间
time.sleep( random.randrange(4,8) )
print("{}离开了唱吧ktv , 唱完了 ... ".format(person))
# 解锁
sem.release()
if __name__ == "__main__":
sem = Semaphore(5)
lst = ["赵凤勇" , "沈思雨", "赵万里" , "张宇" , "假率先" , "孙杰龙" , "陈璐" , "王雨涵" , "杨元涛" , "刘一凤" ]
for i in lst:
p = Process(target=singsong_ktv , args = (i , sem) )
p.start()
事务锁Event
基本语法
[!IMPORTANT]
通过修改属性的值控制阻塞时间 或 函数内限定时间
"""
# 阻塞事件 :
e = Event()生成事件对象e
e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False]
# 如果是True 不加阻塞
# 如果是False 加阻塞
# 控制这个属性的值
# set()方法 将这个属性的值改成True
# clear()方法 将这个属性的值改成False
# is_set()方法 判断当前的属性是否为True (默认上来是False)
"""
from multiprocessing import Process,Event
import time , random
e = Event()
# 默认属性值是False.
print(e.is_set())
# 判断内部成员属性是否是False
e.wait()
# 如果是False , 代码程序阻塞
print(" 代码执行中 ... ")
# 2
e = Event()
# 将这个属性的值改成True
e.set()
# 判断内部成员属性是否是True
e.wait()
# 如果是True , 代码程序不阻塞
print(" 代码执行中 ... ")
# 将这个属性的值改成False
e.clear() # 清除True
e.wait()
print(" 代码执行中 .... 2")
# 3
e = Event()
e.wait(3) # wait(3) 代表最多等待3秒;
print(" 代码执行中 .... 3")
红绿灯事件
from multiprocessing import Process,Event
import time , random
# 红绿灯切换
def traffic_light(e):
# 红灯亮 -> <==== 一段时间 ST is false ==== > 绿灯亮 -> 修改ST
print("红灯亮")
while True:
if e.is_set():
# 绿灯状态 -> 切红灯
time.sleep(1)
print("红灯亮")
# True => False
e.clear()
else:
# 红灯状态 -> 切绿灯
time.sleep(1)
print("绿灯亮")
# False => True
e.set()
# 车的状态
def car(e, i):
# 判断是否是红灯,如果是加上wait阻塞
if not e.is_set():
print("car{} 在等待 ... ".format(i))
e.wait()
# 否则不是,代表绿灯通行;
print("car{} 通行了 ... ".format(i))
if __name__ == "__main__":
lst = []
e = Event() # 创建事件
# 创建交通灯
p1 = Process(target=traffic_light, args=(e,))
# 设置红绿灯为守护进程
p1.daemon = True
p1.start()
# 创建小车进程
for i in range(1, 21):
time.sleep(random.randrange(2))
p2 = Process(target=car, args=(e, i))
p2.start()
lst.append(p2)
# 需要设置一个join等待 多线程的小车需要运行结束后 再 关闭主进程携带关闭守护进程
for i in lst:
i.join() # 不可以加在创建进程时候 会阻塞创建进程
print("关闭成功 .... ")
进程通信问题
进程队列queue
进程队列 实现进程之间IPC通信
基本语法
put and get
from multiprocessing import Process,Queue
# 创建进程队列
q = Queue()
q.put(1)
q.put(2)
q.put(3)
# print( q.get() )
# print( q.get() )
# print( q.get() )
# print( q.get() ) 在获取不到任何数据时,会出现阻塞
put_nowait and ger_nowait
from multiprocessing import Process,Queue
# 引入线程模块; 为了捕捉queue.Empty异常;
import queue # 只是为了捕捉queue.Empty 这个异常类
# put_nowait() 非阻塞版本的put
# 设置当前队列最大长度为3 ( 元素个数最多是3个 )
"""在指定队列长度的情况下,如果塞入过多的数据,会导致阻塞"""
q2 = Queue(3)
try:
q2.put_nowait(111)
q2.put_nowait(222)
q2.put_nowait(333)
q2.put_nowait(444)
except:
pass
# get_nowait() 拿不到数据报异常
"""[windows]效果正常 [linux]不兼容"""
try:
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
except : #queue.Empty
pass
生产者和消费者模型
单生产者和消费者基础版
"""问题 : 当前模型,程序不能正常终止 """
# 需要手动在队列的最后,加入标识None, 终止消费者模型
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
# 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p1.start()
p2.start()
p2.join() # 在生产完所有的物品后 立刻增加一个None 结束While
q.put(None) # 香蕉0 香蕉1 香蕉2 香蕉3 香蕉4 None
多个生产者和消费者基础班
""" 问题 : 虽然可以解决问题 , 但是需要加入多个None , 代码冗余"""
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
# 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p1_1 = Process( target=consumer,args=(q , "赵世超") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p2_2 = Process( target=producer,args=(q , "赵凤勇" , "大蒜" ) )
p1.start()
p1_1.start()
p2.start()
p2_2.start()
# 等待所有数据填充完毕
p2.join()
p2_2.join()
# 把None 关键字放在整个队列的最后,作为跳出消费者循环的标识符;
q.put(None) # 给第一个消费者加一个None , 用来终止
q.put(None) # 给第二个消费者加一个None , 用来终止
# ...
JoinableQueue 队列
基础语法
"""
put 存放
get 获取
task_done 计算器属性值-1
join 配合task_done来使用 , 阻塞
put 一次数据, 队列的内置计数器属性值+1
get 一次数据, 通过task_done让队列的内置计数器属性值-1
join: 会根据队列计数器的属性值来判断是否阻塞或者放行
队列计数器属性是 等于 0 , 代码不阻塞放行
队列计数器属性是 不等 0 , 意味着代码阻塞
"""
from multiprocessing import JoinableQueue
jq = JoinableQueue()
jq.put("王同培") # +1
jq.put("王伟") # +2
print(jq.get())
print(jq.get())
# print(jq.get()) 取不到东西会阻塞
jq.task_done() # -1
jq.task_done() # -1
jq.join()
print(" 代码执行结束 .... ")
使用的JoinableQueue改善
# ### 2.使用JoinableQueue 改造生产着消费者模型
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 让队列的内置计数器属性-1
q.task_done()
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = JoinableQueue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p1.daemon = True # 杀死While
p1.start()
p2.start()
p2.join() # 阻拦主程序的执行
# 必须等待队列中的所有数据全部消费完毕,再放行jq队列的判断
q.join()
print("程序结束 ... ")
Manager共享对象
字典共享
# ### Manager ( list 列表 , dict 字典 ) 进程之间共享数据
from multiprocessing import Process , Manager ,Lock
def mywork(data,lock):
# 为了程序更精准 才加锁
lock.acquire()
data["count"] -= 10
lock.release()
if __name__ == "__main__":
lst = [] # 进程列表
m = Manager()
lock = Lock()
# 多进程中的共享字典
data = m.dict( {"count":5000} )
print(data , type(data) )
for i in range(10): # 最好小于1000
p = Process(target=mywork,args=(data,lock))
p.start()
lst.append(p)
# 必须等待子进程所有计算完毕之后,再去打印该字典,否则报错;
for i in lst:
i.join()
print(data)
列表共享
# ### Manager ( list 列表 , dict 字典 ) 进程之间共享数据
from multiprocessing import Process , Manager ,Lock
def mywork(data,lock):
# 共享列表
data[0] += 1
if __name__ == "__main__":
lst = []
m = Manager()
lock = Lock()
# 多进程中的共享列表
data = m.list( [100,200,300] )
# 进程数超过1000,处理该数据,死机(谨慎操作)
for i in range(10):
p = Process(target=mywork,args=(data,lock))
p.start()
lst.append(p)
# 必须等待子进程所有计算完毕之后,再去打印该字典,否则报错;
for i in lst:
i.join()
print(data)
多线程
线程的概念
进程是资源分配的最小单位
线程是计算机中调度的最小单位线程的缘起
资源分配需要分配内存空间,分配cpu:
分配的内存空间存放着临时要处理的数据等,比如要执行的代码,数据
而这些内存空间是有限的,不能无限分配
目前配置高的主机,5万个并发已是上限.线程概念应用而生.线程的特点
线程是比较轻量级,能干更多的活,一个进程中的所有线程资源是共享的.
一个进程至少有一个线程在工作
线程的缺陷
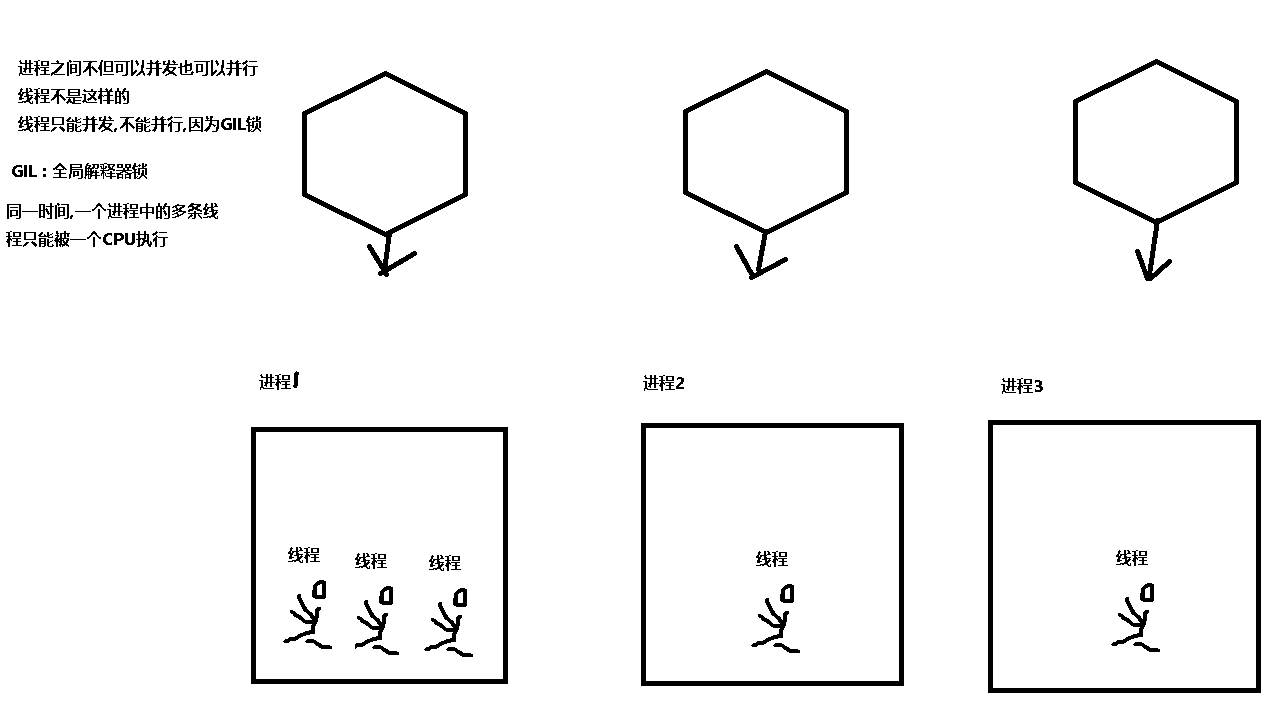
python中的线程可以并发,但是不能并行(同一个进程下的多个线程不能分开被多个cpu同时执行)
原因:
全局解释器锁(Cpython解释器特有) GIL锁:
同一时间,一个进程下的多个线程只能被一个cpu执行,不能实现线程的并行操作
python是解释型语言,执行一句编译一句,而不是一次性全部编译成功,不能提前规划,都是临时调度
容易造成cpu执行调度异常.所以加了一把锁叫GIL想要并行的解决办法:
(1)用多进程间接实现线程的并行
(2)换一个Pypy,Jpython解释器
但是不能真正意义上解决
程序分为计算密集型和io密集型
对于计算密集型程序会过度依赖cpu,但网页,爬虫,OA办公,这种io密集型的程序里,python绰绰有余
[!IMPORTANT]
GIL 是 Python 解释器中的一个全局锁,它确保同一时间只有一个线程在解释器中执行字节码。
线程的基本语法
from threading import Thread
from multiprocessing import Process
import os , time , random
def func(i):
time.sleep(random.uniform(0.1,0.9))
print("当前进程号:{}".format(os.getpid()) , i)
if __name__ == "__main__":
for i in range(10):
t = Thread(target=func,args=(i,)) # 开启线程
t.start()
print(os.getpid())
进程和线程速度的对比
from threading import Thread
from multiprocessing import Process
import os , time , random
# 多线程速度
def func(i):
print( "当前进程号:{} , 参数是{} ".format(os.getpid() , i) )
if __name__ == "__main__":
lst = []
startime = time.time()
for i in range(10000):
t = Thread(target=func,args=(i,))
t.start()
lst.append(t)
# print(lst)
for i in lst:
i.join()
endtime = time.time()
print("运行的时间是{}".format(endtime - startime) ) # 运行的时间是1.8805944919586182
# 多进程速度
if __name__ == "__main__":
lst = []
startime = time.time()
for i in range(10000):
p = Process(target=func,args=(i,))
p.start()
lst.append(p)
# print(lst)
for i in lst:
i.join()
endtime = time.time()
print("运行的时间是{}".format(endtime - startime) ) # 运行的时间是101.68004035949707
多线程是数据共享的
num = 100
lst = []
def func():
global num
num -= 1
for i in range(100):
t = Thread(target=func)
t.start()
lst.append(t)
for i in lst:
i.join()
print(num)
自定义线程类
from threading import Thread
class MyThread(Thread):
def __init__(self,name):
# 手动调用父类的构造方法
super().__init__()
# 自定义当前类需要传递的参数
self.name = name
def run(self):
print( "当前进程号{},name={}".format(os.getpid() , self.name) )
if __name__ == "__main__":
t = MyThread("我是线程")
t.start()
print( "当前进程号{}".format(os.getpid()) )
线程常用相关属性
# 线程.is_alive() 检测线程是否仍然存在
# 线程.setName() 设置线程名字
# 线程.getName() 获取线程名字
# 1.currentThread().ident 查看线程id号 # from threading import currentThread
# 2.enumerate() 返回目前正在运行的线程列表 # from threading import enumerate
# 3.activeCount() 返回目前正在运行的线程数量 # from threading import activeCount
from threading import Thread
def func():
time.sleep(1)
if __name__ == "__main__":
t = Thread(target=func)
t.start()
# 检测线程是否仍然存在 需要运行
print( t.is_alive() )
# 线程.getName() 获取线程名字
print(t.getName())
# 设置线程名字
t.setName("抓API接口")
print(t.getName())
from threading import currentThread
from threading import enumerate
from threading import activeCount
def func():
time.sleep(0.1)
print("当前子线程号id是{},进程号{}".format( currentThread().ident ,os.getpid()) )
if __name__ == "__main__":
t = Thread(target=func)
t.start()
print("当前主线程号id是{},进程号{}".format( currentThread().ident ,os.getpid()) )
for i in range(5):
t = Thread(target=func)
t.start()
# 返回目前正在运行的线程列表
lst = enumerate()
print(lst,len(lst))
# 返回目前正在运行的线程数量 (了解)
print(activeCount())
守护线程
# ### 守护线程 : 等待所有线程全部执行完毕之后,自己在终止程序,守护所有线程
from threading import Thread
import time
def func1():
while True:
time.sleep(1)
print("我是函数func1")
def func2():
print("我是func2 start ... ")
time.sleep(3)
print("我是func2 end ... ")
def func3():
print("我是func3 start ... ")
time.sleep(6)
print("我是func3 end ... ")
if __name__ == "__main__":
t = Thread(target=func1)
t2 = Thread(target=func2)
t3 = Thread(target=func3)
# 设置守护线程 (启动前设置)
t.setDaemon(True)
t.start()
t2.start()
t3.start()
print("主线程执行结束.... ")
# 在所有线程运行后 结束
线程中的安全问题
[!IMPORTANT]
线程资源不隔离
from threading import Thread , Lock
import time
n = 0
def func1(lock):
global n
with lock:
for i in range(1000000):
n += 1
def func2(lock):
global n
# with语法可以简化上锁+解锁的操作,自动完成
with lock:
for i in range(1000000):
n -= 1
if __name__ == "__main__":
lst = []
lock = Lock()
start = time.time()
for i in range(10):
t1 = Thread(target=func1 ,args=(lock,) )
t1.start()
t2 = Thread(target=func2 ,args=(lock,) )
t2.start()
lst.append(t1)
lst.append(t2)
for i in lst:
i.join()
end = time.time()
print("主线程执行结束... 当前n结果为{} ,用时{}".format(n , end-start))
Lock
from threading import Lock
Semphore
"""
创建线程是异步的,
上锁的过程会导致程序变成同步;
"""
from threading import Thread,Semaphore
import time , random
def func(i,sem):
time.sleep(random.uniform(0.1,0.7))
# with语法自动实现上锁 + 解锁
with sem:
print("我在电影院拉屎 .... 我是{}号".format(i))
if __name__ == "__main__":
sem = Semaphore(5)
for i in range(30):
Thread(target=func,args=(i,sem)).start()
print(1)
死锁问题
语法上的死锁
"""语法上的死锁: 是连续上锁不解锁"""
lock = Lock()
lock.acquire()
# lock.acquire() error
print("代码执行中 ... 1")
lock.release()
lock.release()
逻辑上的死锁
from threading import Thread , Lock
# 可能会产生一个人抢到筷子 一个人抢到面条
noodles_lock = Lock()
kuaizi_lock = Lock()
def eat1(name):
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
def eat2(name):
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
# kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
尽量用一把锁解决问题
# 尽量使用一把锁解决问题,(少用锁嵌套,容易逻辑死锁)
from threading import Thread , Lock
lock = Lock()
def eat1(name):
lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
print("{}吃完了,满意的放下了筷子".format(name))
print("{}吃完了,满意的放下了面条".format(name))
lock.release()
def eat2(name):
lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
print("{}吃完了,满意的放下了筷子".format(name))
print("{}吃完了,满意的放下了筷子".format(name))
lock.release()
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
Rlock
基础语法
"""
递归锁的提出专门用来解决死锁现象
用于快速解决线上项目死锁问题
即使连续上锁,使用递归锁后也形同虚设,因为递归锁的作用在于解锁;
"""
# 基本语法
rlock = RLock()
rlock.acquire()
rlock.acquire()
rlock.acquire()
rlock.acquire()
print("代码执行中 ... 3")
rlock.release()
rlock.release()
rlock.release()
rlock.release()
解决逻辑上的死锁
from threading import Thread , RLock
noodles_lock = kuaizi_lock = RLock()
def eat1(name):
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
def eat2(name):
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
noodles_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
事件
基础语法
e = Event()
print(e.is_set())
e.set()
print(e.is_set())
e.wait()
e.clear()
# 最多阻塞三秒,放行
e.wait(3)
print("代码执行中 ... ")
模拟访问数据
from threading import Thread, Event
import time, random
def check(e):
print("目前正在检测您的账号和密码 .... ")
# 模拟延迟的场景
time.sleep(random.randrange(1, 7)) # 1 ~ 6
# 把成员属性值从False -> True
e.set()
def connect(e):
sign = False
for i in range(1, 4):
# 最多阻塞1秒
e.wait(1)
if e.is_set():
print("数据库连接成功 ... ")
sign = True
break
else:
print("尝试连接数据库第{}次失败了...".format(i))
# 三次都不成功,报错
if sign == False:
# 主动抛出异常 超时错误
raise TimeoutError
e = Event()
t1 = Thread(target=check, args=(e,))
t2 = Thread(target=connect, args=(e,))
t1.start()
t2.start()
线程队列
queue
基本语法
"""先进先出,后进先出"""
"""
put 存放 超出队列长度阻塞
get 获取 超出队列长度阻塞
put_nowait 存放,超出队列长度报错
get_nowait 获取,超出队列长度报错
"""
q = Queue()
q.put(100)
q.put(200)
print(q.get())
print(q.get())
# print(q.get()) 阻塞
# print(q.get_nowait())
# print(q.get_nowait()) 报错
Queue(3) => 指定队列长度, 元素个数只能是3个;
q2 = Queue(3)
q2.put(1000)
q2.put(2000)
# q2.put(3000)
# q2.put(4000) 阻塞
LifoQueue
"""先进后出,后进先出(栈的特点)"""
from queue import LifoQueue
lq = LifoQueue()
lq.put(110)
lq.put(120)
lq.put(119)
print(lq.get())
print(lq.get())
print(lq.get())
PriorityQueue
"""按照优先级顺序进行排序存放(默认从小到大)"""
from queue import PriorityQueue
pq = PriorityQueue()
# 1.对数字进行排序
pq.put(100)
pq.put(19)
pq.put(-90)
pq.put(88)
print(pq.get())
print(pq.get())
print(pq.get())
print(pq.get())
# 2.对字母进行排序 (按照ascii编码)
pq.put("wangwen")
pq.put("sunjian")
pq.put('wangwei')
pq.put("王文")
pq.put("孙坚")
pq.put('王维')
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
# 3.对容器进行排序
pq.put( (22,"wangwen") )
pq.put( (67,"wangyuhan") )
pq.put( (3,"anxiaodong") )
pq.put( (3,"liuyubo") )
print(pq.get())
print(pq.get())
print(pq.get())
print(pq.get())
"""在一个优先级队列中,要放同一类型的数据,不能混合使用"""
# 4.注意点
pq.put(100)
pq.put("nihao")
pq.put( (1,2,3) )
进程池和线程池
进程池
基本语法
[!IMPORTANT]
obj,result 获取返回值有阻塞的效果 所以需要后处理 不放在循环中
默认如果一个进程短时间内可以完成更多的任务,进程池就不会使用更多的进程来辅助完成 , 可以节省系统资源的损耗
os.cpu_count() 返回逻辑处理器的个数
from concurrent.futures import ProcessPoolExecutor
def func(i):
time.sleep(random.uniform(0.1,0.8))
print(" 任务执行中 ... start ... 进程号{}".format(os.getpid()) , i )
print(" 任务执行中 ... end ... 进程号{}".format(os.getpid()))
return i
if __name__ == "__main__":
lst = []
# (1) 创建进程池对象
"""默认参数是 系统最大的逻辑核心数 i"""
p = ProcessPoolExecutor()
# (2) 异步提交任务
"""submit(任务,参数1,参数2 ... )"""
for i in range(10):
obj = p.submit( func , i )
# print(obj.result()) 不要写在这,导致程序同步,内部有阻塞
lst.append(obj)
# (3) 获取当前任务的返回值
for i in lst:
print(i.result(),">===获取返回值===?")
# (4) shutdown 等待所有进程池里的进程执行完毕之后,在放行 同 join
p.shutdown()
print("进程池结束 ... ")
线程池
[!IMPORTANT]
同一时间,一个进程下的多个线程只能被一个cpu执行,不能实现线程的并行操作
from concurrent.futures import ThreadPoolExecutor
from threading import currentThread as ct
from threading import current_thread as ct # 查看线程id号
def func(i):
print(" 任务执行中 ... start ... 线程号{}".format( ct().ident ) , i )
time.sleep(1)
print(" 任务执行中 ... end ... 线程号{}".format(os.getpid()))
return ct().ident # 线程号
if __name__ == "__main__":
lst = []
setvar = set()
# (1) 创建线程池对象
t = ThreadPoolExecutor() """默认参数是 系统最大的逻辑核心数 i * 5 = 5i """
# (2) 异步提交任务
"""默认如果一个线程短时间内可以完成更多的任务,线程池就不会使用更多的线程来辅助完成 , 可以节省系统资源的损耗;"""
for i in range(100):
obj = t.submit(func,i)
lst.append(obj)
# (3) 获取当前任务的返回值
for i in lst:
setvar.add(i.result()) # 同步了可以不shutdown 但是最好加
# (4) shutdown 等待所有线程池里的线程执行完毕之后,在放行
t.shutdown()
print("主线程执行结束 ... ")
print(setvar , len(setvar)) # 查询线程启动的数量
线程池与Map
from threading import currentThread as ct # 引用线程号
from collections import Iterator,Iterable
def func(i):
time.sleep(random.uniform(0.1,0.7)) # 即使有延迟最后返回的数据也顺序 因为线程或进程按顺序创建
print("thread ... 线程号{}".format(ct().ident),i)
return "*" * i
if __name__ == "__main__":
t = ThreadPoolExecutor()
it = t.map(func,range(100))
# 返回的数据是迭代器
print(isinstance(it,Iterator))
# 协调子父线程,等待线程池中所有线程执行完毕之后,在放行;
t.shutdown()
# 获取迭代器里面的返回值
for i in it:
print(i)
回调函数
回调函数: 回头调用一下函数获取最后结果
微信支付宝付款成功后, 获取付款金额
微信支付宝退款成功后, 获取退款金额
一般用在获取最后的状态值时,使用回调
通过add_done_callback最后调用一下自定义的回调函数;
基本原理
# 执行对象里的实现逻辑
class Ceshi():
def add_done_callback(self,func):
print("系统执行操作1 ... ")
print("系统执行操作2 ... ")
# 回头调用一下
func(self)
def result(self):
return 112233
def call_back(obj):
print(obj.result())
obj = Ceshi()
obj.add_done_callback(call_back)
进程池回调
进程池的回调函数由主进程执行
from concurrent.futures import ProcessPoolExecutor , ThreadPoolExecutor
import os,time,random
def func1(i):
time.sleep(random.uniform(0.1,0.9))
print(" 进程任务执行中 ... start ... 进程号{}".format(os.getpid()) , i )
print(" 进程任务执行中 ... end ... 进程号{}".format(os.getpid()) )
return i
def call_back1(obj):
print( "<==回调函数的进程号{}==>".format(os.getpid()) )
print(obj.result())
if __name__ == "__main__":
# (1)进程池 结果:(进程池的回调函数由主进程执行)
p = ProcessPoolExecutor()
for i in range(1,11):
obj = p.submit(func1 , i )
# 使用add_done_callback在获取最后返回值的时候,可以异步并行
obj.add_done_callback(call_back1)
# 直接使用result获取返回值的时候,会变成同步程序,速度慢;
# obj.result()
p.shutdown()
print( "主进程执行结束...进程号:" , os.getpid() )
线程池回调
线程池的回调函数由子线程执行
from concurrent.futures import ThreadPoolExecutor
from threading import currentThread as ct
import os,time,random
def func1(i):
time.sleep(random.uniform(0.1,0.9))
print(" 进程任务执行中 ... start ... 进程号{}".format(os.getpid()) , i )
print(" 进程任务执行中 ... end ... 进程号{}".format(os.getpid()) )
return i
def call_back1(obj):
print( "<==回调函数的进程号{}==>".format(os.getpid()) )
print(obj.result())
if __name__ == "__main__":
# (2)线程池 结果:(线程池的回调函数由子线程执行)
t = ThreadPoolExecutor()
for i in range(1,11):
obj = t.submit(func2 , i )
# 使用add_done_callback在获取最后返回值的时候,可以异步并发
obj.add_done_callback(call_back2)
# 直接使用result获取返回值的时候,会变成同步程序,速度慢;
# obj.result()
t.shutdown()
print("主线程执行结束 .... 线程号{}".format(ct().ident))
协程
进程是资源分配的最小单位
线程是程序调度的最下单位
协程是线程实现的具体方式协程实际上是不存在的 是程序员将线程分离化的结果
在进程一定的情况下,开辟多个线程,
在线程一定的情况下,创建多个协程,
以便提高更大的并行并发

协程的特性原理
# 二者之间通过生成器的暂停和恢复来实现协程的特性
def producer():
for i in range(1000):
yield i
def consumer(gen):
for i in range(10):
print( next(gen) )
gen = producer()
consumer(gen)
print("<==========>")
consumer(gen)
print("<==========>")
consumer(gen)
greenlet
from greenlet import greenlet
import time
""" switch 可以切换任务,但是需要手动切换"""
def eat():
print("eat1")
g2.switch()
time.sleep(3)
print("eat2")
def play():
print("play1")
time.sleep(3)
print("play2")
g1.switch()
g1 = greenlet(eat)
g2 = greenlet(play)
g1.switch()
"""
eat1
play1
play2
eat2
"""
升级到gevent版本
import gevent
def eat():
print("eat1")
gevent.sleep(3)
# time.sleep(3)
print("eat2")
def play():
print("play1")
gevent.sleep(3)
# time.sleep(3)
print("play2")
# 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play)
# 如果不加join, 主线程直接结束任务,不会默认等待协程任务.
# 阻塞,必须等待g1任务完成之后在放行
g1.join()
# 阻塞,必须等待g2任务完成之后在放行
g2.join()
print("主线程执行结束 .... ")
monkey补丁
from gevent import monkey;monkey.patch_all()
"""引入猴子补丁,可以实现所有的阻塞全部识别"""
import time
import gevent
def eat():
print("eat1")
time.sleep(3)
print("eat2")
def play():
print("play1")
time.sleep(3)
print("play2")
# 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play)
# 如果不加join, 主线程直接结束任务,不会默认等待协程任务.
# 阻塞,必须等待g1任务完成之后在放行
g1.join()
# 阻塞,必须等待g2任务完成之后在放行
g2.join()
print(" 主线程执行结束 ... ")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号