知识蒸馏(Knowledge Distilling)
1.参考资料,
一个很好的KD的资料list https://github.com/dkozlov/awesome-knowledge-distillation
一个中文的相关资料https://www.zhihu.com/question/333196499/answer/738197683
一些找到的跟KD相关的资料
https://github.com/lhyfst/knowledge-distillation-papers
https://xmfbit.github.io/2018/06/07/knowledge-distilling/
https://www.zhihu.com/question/50519680
https://github.com/dkozlov/awesome-knowledge-distillation
与seq2seq最相关的论文 Sequence-Level Knowledge Distillation
https://arxiv.org/pdf/1606.07947.pdf
一、Hinton的dark knowledge
1.思想
为了获得更好的效果对模型做ensemble,但是在预测的过程中,太多模型的ensemble会导致每一个参数本质上包含了很少的知识,在预测过程中需要更少的运算量和内存消耗。目标是用训练数据训练ensemble的效果好的模型,再利用一个更小的模型来获得emsemble模型中的 映射空间
2.做法
对于emsemble来说,可以使用多个模型的几何平均也可以使用代数平均,对于输出来说有一个soft target。
对于最终使用的小模型来说,如果只从soft target学习也可以学习的很快很好,因为这样做学习的是大模型的空间,一个不是onehot的label蕴含了更多的关联约束信息,但是利用hard target(one hot 的label)和soft target 一起使用会有更好的效果。
如何添加hard targets呢?(??)
如何让ensemble高效?
对多分类任务,使被集成的模型分别专注于不同的类别(翻译模型可否组合不同的模型,专注于不同的指标,BLEU,METEOR或者在不同的惩罚因子条件下达到最优)
从专家系统中获得更易混淆的类的信息.
3.效果
在做kd的过程中,如果使用soft target,对于多分类问题,即便训练数据中不包含其中某一类的数据,也能对这一类进行预测,
二、对bert做QA的模型进行知识蒸馏(Model Compression with Multi-Task Knowledge Distillation forWeb-scale Question Answering System)
多任务实际上是一个任务,但是使用了多个训练出来的模型(和ensemble类似),在利用soft target 的过程中 使用了 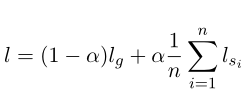 ,其中lg是hard target, ls是多个soft target,效果会更好。
,其中lg是hard target, ls是多个soft target,效果会更好。
模型是使用正常的embedding 加上 transformer 来构建, 训练过程中的小tips:
1.初始化模型参数要按照预训练的模型参数(google的bert来进行初始化再训练,)差距很大

2. 层数和soft target 与hard target 之间的权重系数影响。
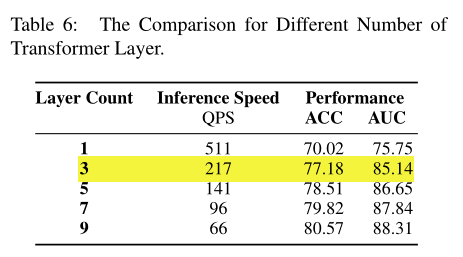

3. 训练过程中使用大量未标记数据利用teacher来获得数据,先利用teacher获得的soft target 对模型进行训练,再对训练好的模型使用hiton的方式进行训练,
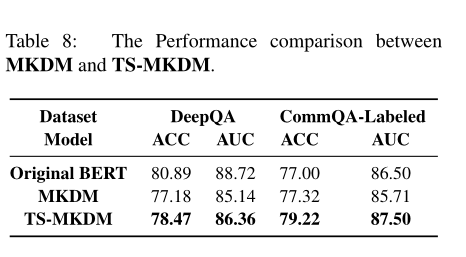
感觉这篇论文没有特别实质的推进,但实验确实很详细,各种情况都进行了对比,是北邮学生在微软实习的工作,符合特点实验繁重复杂,效果良好。其中使用了原始的模型,所以初始化利用原始模型数据产生的提高和类似于ensemble的多任务值得借鉴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号