19年论文阅读笔记(持续更新)
国内的一些机构目前对于语法纠错有一定的研究,流利说,猿辅导等。
1.Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
这是一篇猿辅导的论文,发在NAACL上。考虑原因是由于语法纠错任务中正确的token是大多数,全部训练数据集中都超过百分之80,主要思路是利用多任务学习机制(增加的任务为复制,其实是做的序列标注),来辅助特征的提取,这个复制的结构以前用在段落总结,主体结构如下图所示。
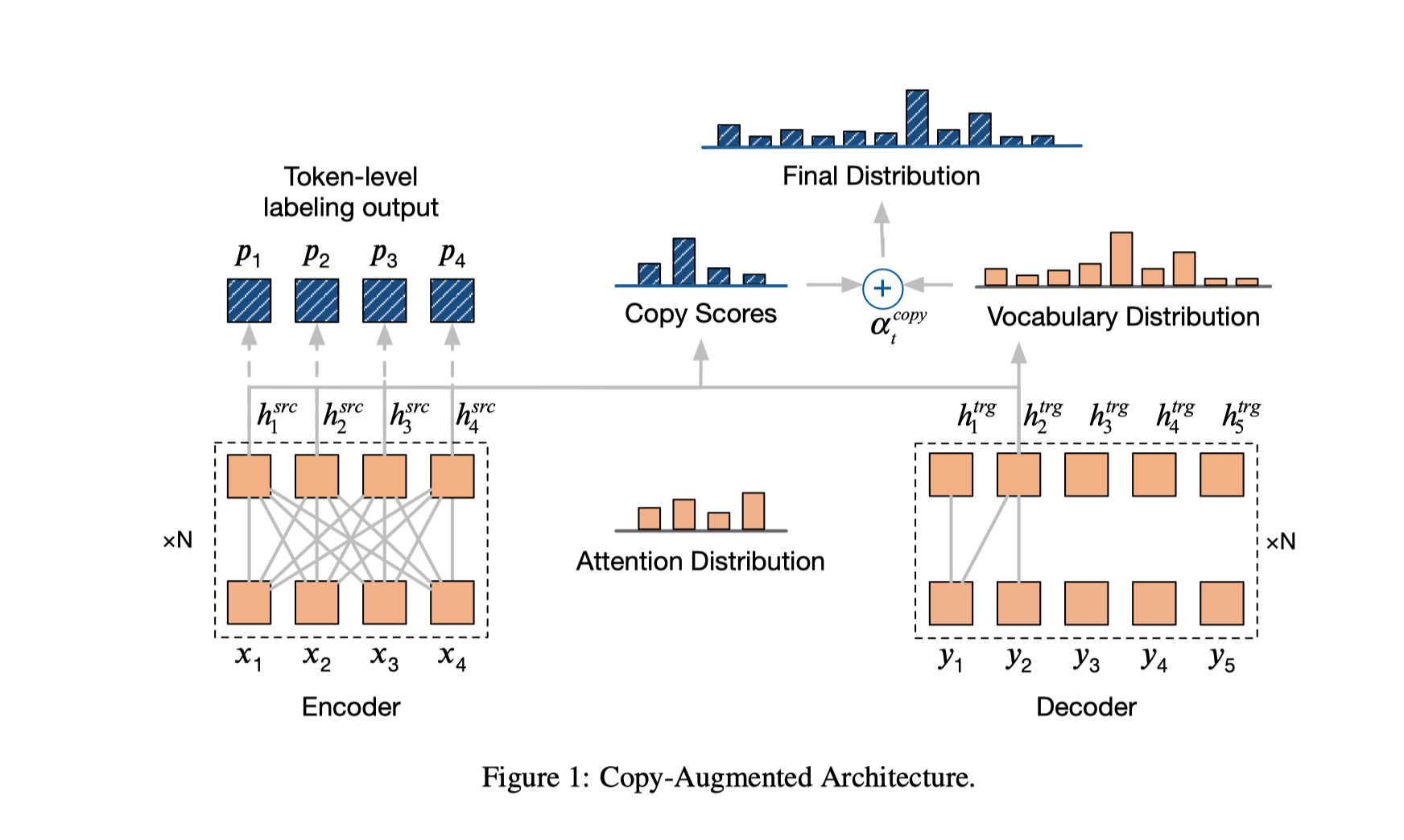
预测过程中对copy score 和generation score做了加权,其中加权系数由训练得到。可以将unk的单词直接复制到输出的结果中,也可以减小一定的字典。
2.A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
一篇写自己比赛的做法的文章,上传至CoRR,比赛是ACL 2019 BEA Shared Task.
3.[NG大佬的论文]Cross-Sentence Grammatical Error Correction(https://github.com/nusnlp/crosentgec)
发在ACL上,句子中的语法错误与上下文相关(时态,冠词等),引入了一个辅助的编码器来获取上下文句子的内容,解码部分也有额外的注意力机制和门限机制,主体结构如下图所示,后续增加拼写纠错后的最高结果为F0.5 57.30
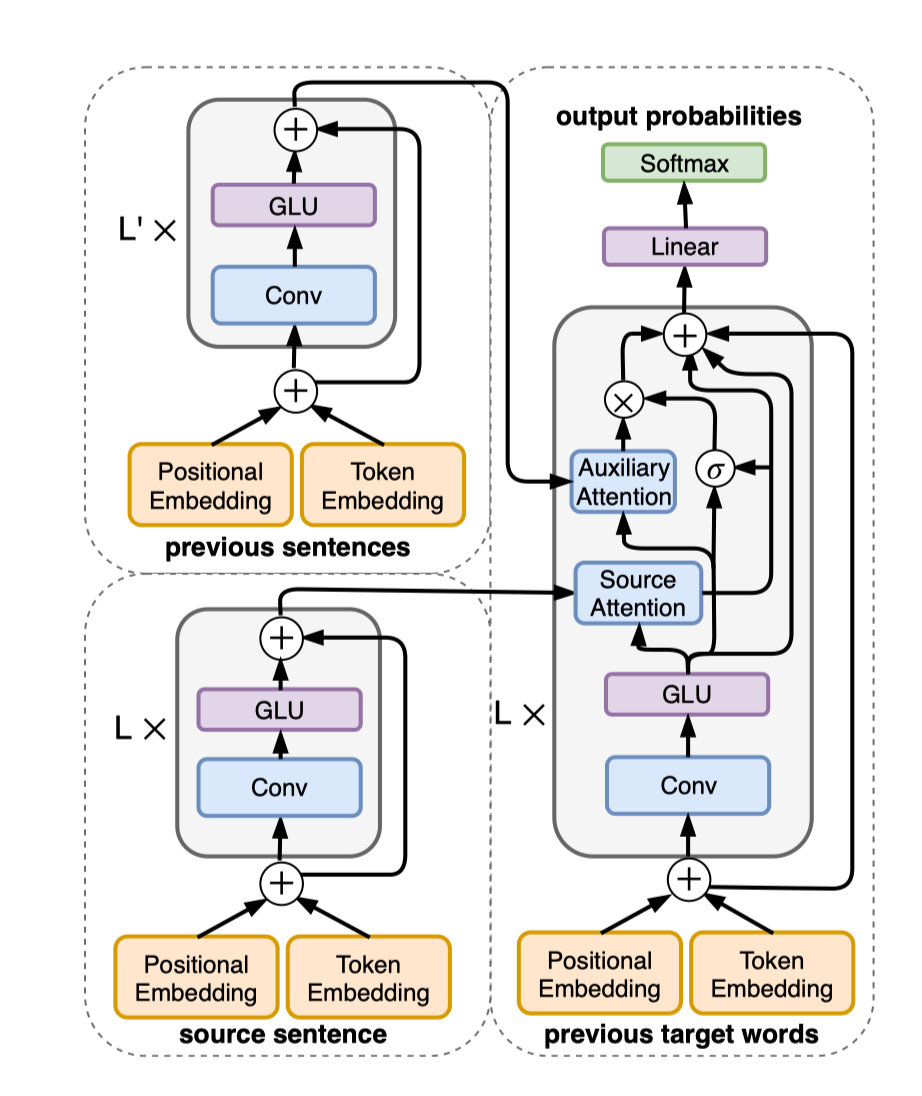
个人看法:借鉴了bert的decoder结构,用卷积代替了transformer,左移将前一个词作为已知信息来处理。(未详细看完计算过程)
4.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号