kubernetes
Scheduler:
- cache:本地数据,主要是node、pod、pdb信息
- queue:需要调度的pod队列
- 默认为FIFO,可选为PriorityQ;PriorityQ包含UnschedulbleQ和ActiveQ(前者会在事件触发时刷到后者,如下图中部分事件);UnschedulbleQ中含有nominatedPods
- predicates存在两阶段:加nominatedPods(资源要求更高)、不加nominatedPods(亲和性要求更高)
- pod informer存在两个:分别对应对已调度的pod、尚未调度的pod;delete事件不一定是apiserver发出的,具体如下图:
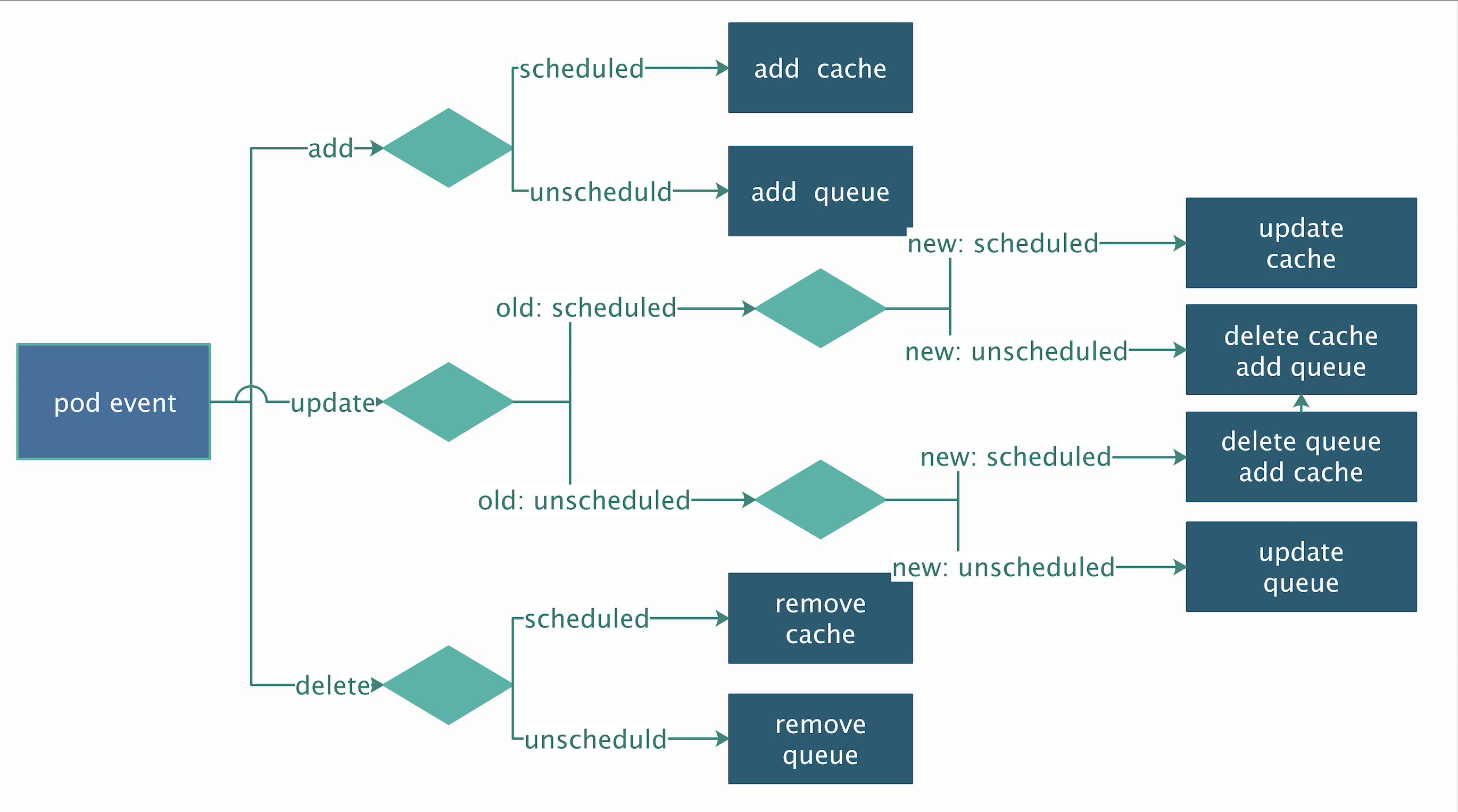
- assume:assumedPods[pod]为true;bind:podStates[pod].bindingFinished为true;新goroutine定期expire那些bind且超过ttl的pod;assume必须保证podStates不存在
- 问题
- sync周期太短:sync产生update事件(有一定延迟) && pod的ttl还没到 -> update queue,再次调度 -> assume时podStates已经存在出错(sync默认为0,关闭)
- 开抢占后太慢:addNominatedPods需要遍历ActiveQ;拆分PriorityQ:UnschedulbleQ、ActiveQ、nominatedPods

 浙公网安备 33010602011771号
浙公网安备 33010602011771号