
1、与hadoop job区别
a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it)
2、有两种结点(物理层面)
Master和Worker 通过Zookeeper通信
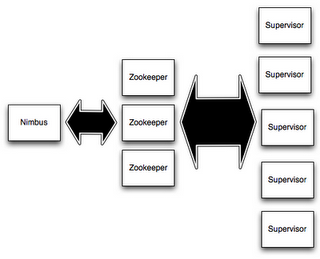
Master上跑一个Nimbus进程,负责代码在集群的发布、任务分配、失败监控等
Worker上跑一个Supervisor进程,负责接收任务,启动和停止工作进程
这是物理层面的结点,一台机器作为Master上面跑一个Nimbus,通过Zookeeper集群与Worker集群交互,每台Worker上跑一个Supervisor
3、Topologies(逻辑层面)
Streams流 spout流入数据,留到bolt处理数据流出
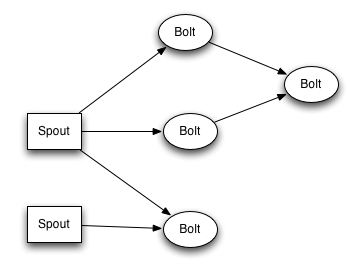
逻辑层面的拓扑结构,spout流入数据,后面的bolt拓扑结构处理业务,拓扑结构可以任意扩展,spout与bolt可以一对多,也可以多对一
bolt可以分布在不同的机器上,在同一台机器上的bolt是多进程的。
A topology will run indefinitely until you kill it.
4、Data model
Storm uses tuples as its data model. A tuple is a named list of values, and a field in a tuple can be an object of any type.
Tuples是拓扑结构中传递的数据结构,它是个list,list里可以是任何类型或对象
5、Stream groupings
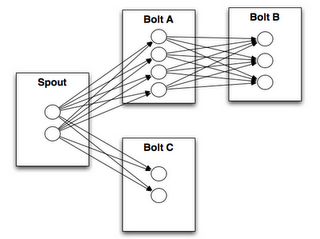
The simplest kind of grouping is called a "shuffle grouping" which sends the tuple to a random task
shuffle grouping将tuple随机的发送给下一层bolt
fields grouping将一个字段相同内容的数据流到下一层同一个task处理
that the same field always go to the same task 某个字段一样的数据会流到同一个task处理,比如统计句子中每个词出现的次数,定义一个word字段,那么同一个词的数据会流到同一个task处理。
collector要提交数据,数据的格式必须在declasreOutputFields里定义,比如下图,要发两个对象数据,
output里必须定义两个fields

 浙公网安备 33010602011771号
浙公网安备 33010602011771号