
Graphormer学习
Grpahormer论文:Do Transformers Really Perform Bad for Graph Representation?
Graphormer官方用的是Fairseq写的,这位大佬用pytorch_geometric重新实现了一下:github:leffff/graphormer-pyg
这篇知乎详细地写了3种编码的思想及代码实现:如何通过代码理解Graphormer(graph+transformer)实现细节
- 前置知识
一般的GNN工作方式如下:
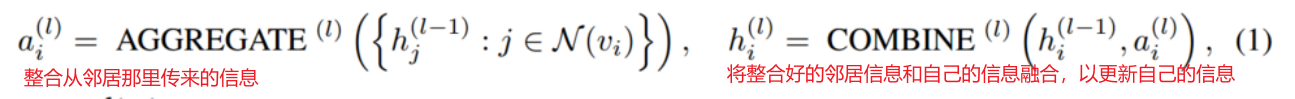
aggregation比如min/max/mean/lstm(graphsage的)
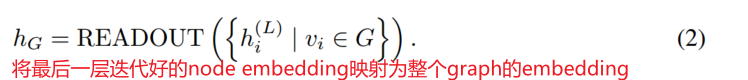
readout比如global_mean_pool/global_max_pool/其他更复杂的池化比如diffpool(还没学)
Transformer中的注意力模块如下:

自注意力的query=key
- Graphormer的架构:
![]()
Graphormer的关键是要讲图的结构信息进行有效的编码,因为在序列信息中存在明确的前后关系,但是在graph data中并没有方向性的概念
所以Transformer中简单的nn.Embedding的语义编码+位置编码对于节点来说失效了,特别是位置编码
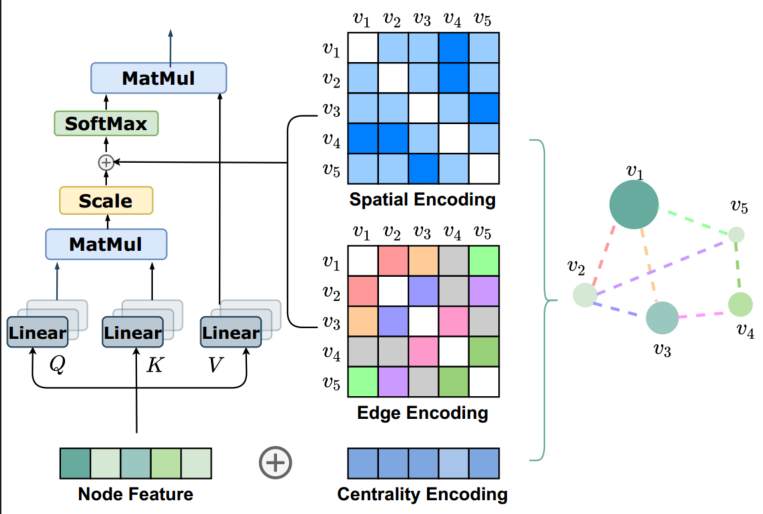
1. Centrality Encoding:(局部信息,感受野只有一阶邻居)
节点的度中心性,表示节点在整个图中的重要性,分别计算入度和出度,然后和node feature相加(add)

所谓度的embedding应该就是类似于用nn.Embedding把一个实数映射为一个d维的向量
如果是无向图的话,入度=出度=deg(vi)
2. Spatial Encoding:(全局信息,感受野是整张图)
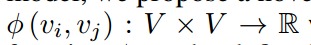
空间编码:定义一个函数,来度量整张图中任意两个节点之间的空间关系,文中用的是任意两个节点之间的无权的最短路径【有人提到空间位置信息可以通过deepwalk得到】
空间编码加在Attention_weight后面作为bias项,然后才过softmax
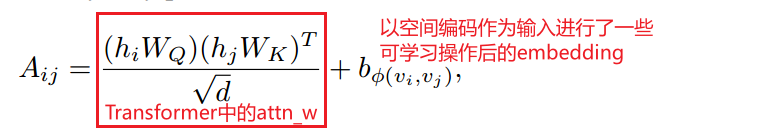
学习空间编码的这个b可以根据需要调整,比如让网络多关注近一点的节点,少关注远一点的节点【具体要怎么设计才能实现目的我也不知道】
3. Edge Encoding
有时候边也有自己的特征,传统的处理方法是在aggregation的过程中,把edge feature也一起整合到node feature里面去(这种方法只是将edge feature传播到其与之相连的node,可能不是利用edge information表示整个图的有效方法)
既然注意力评估的是一对节点(vi, vj)之间的注意力,那么也应该在评估过程中考虑(vi,vj)之间的边eij。为了把edge feature也纳入考虑,对于一对节点(vi, vj),沿着Spatial encoding中的最短路径SPij=(e1, e2, ..., en),计算整条路径经过的边的edge feature与其weight embedding的点积的均值(Rd · Rd → R),也作为bias项加到attn_weight后面
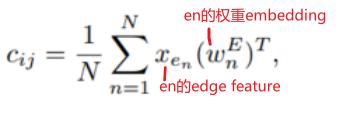
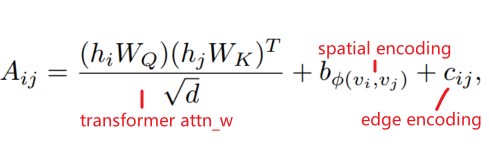
4. Graphormer Layer:
基本基于MultiHeadAttention,但是把Layernorm改在MultiHeadAttention和FeedForwardNetwork之前而不是之后

5. Special Node:
类似于BERT中的[CLS]代表一整个句子的意思,在graph中也添加一个不存在的虚拟节点virtual node,这个node和其他所有real node都相连,和整幅图一起训练,认为这个virtual node的embedding可以表示整个graph的embedding。
virtual node与任何其他node之间的最短路径都为1
为了区分virtual node与其他node之间的virtual edge,以及两个real node之间的real edge,为virtual edge的Spatial encoding设置了一个单独的b
结合源代码一起看
spatial encoding和edge encoding作为attention中的bias项,在源代码中是通过一个叫做BreadcrumbsGraphormer/graphormer/modules
/graphormer_layers.py中的class GraphAttnBias实现的
主要看:通过什么函数实现寻找任意两个节点之间的最短路径及最短路径的长度
原文实在head的level上实现的bias,也就是还要经过一个
Transformer内部实现multi_heads的方法是把feature dim拆分为n_heads*d_k,在每个heads上对这拆分出的d_k维特征进行操作,最后把所有heads的d_k拼回feature_dim
看graphormer的意思,似乎是对于每个head,都要生成一个bias项,那它是怎么合并到但是直接调用nn.MultiheadAttention得到的output已经是把[d_k, n_heads] reshape回 [feature_dim]了,怎么在n_heads的level上把b和c构成的bias加回去呢
具体实现方法:可以定义两种边
一种是直接相连的edge(one-hop-edge):表示方法是邻接矩阵,没有自己的特征
另一种边multi-hop_edge,即任意两个节点之间的最短路径,这种边事全连接的,应该就不需要做成稀疏矩阵的形式?(因为不稀疏了):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号