
OCR 图片文字识别-tesseract
tesseract安装软件下载:
https://digi.bib.uni-mannheim.de/tesseract/
语言包:
https://tesseract-ocr.github.io/tessdoc/Data-Files
开启翻越模式,才能点击链接直接下载。

| chi_sim | Chinese - Simplified | chi_sim.traineddata |
| chi_tra | Chinese - Traditional | chi_tra.traineddata |
Tesseract 提供了三种训练数据:
| 训练数据 | 训练模型 | 识别速度 | 正确率 |
|---|---|---|---|
| tessdata_fast | LSTM | 最快 | 最低 |
| tessdata_best | LSTM | 最慢 | 最高 |
| tessdata | Legacy + LSTM | 中等 | 略低于tesdata -best |
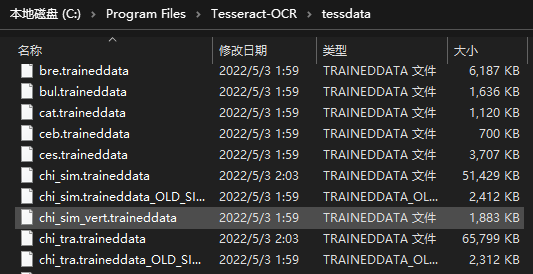
traineddata训练数据安装在testdata下面,比如我是安装在D盘的。
D:\Program Files\Tesseract-OCR\tessdata
把default旧的小文件备份一下,把刚下载的traineddata复制过来。
-------------
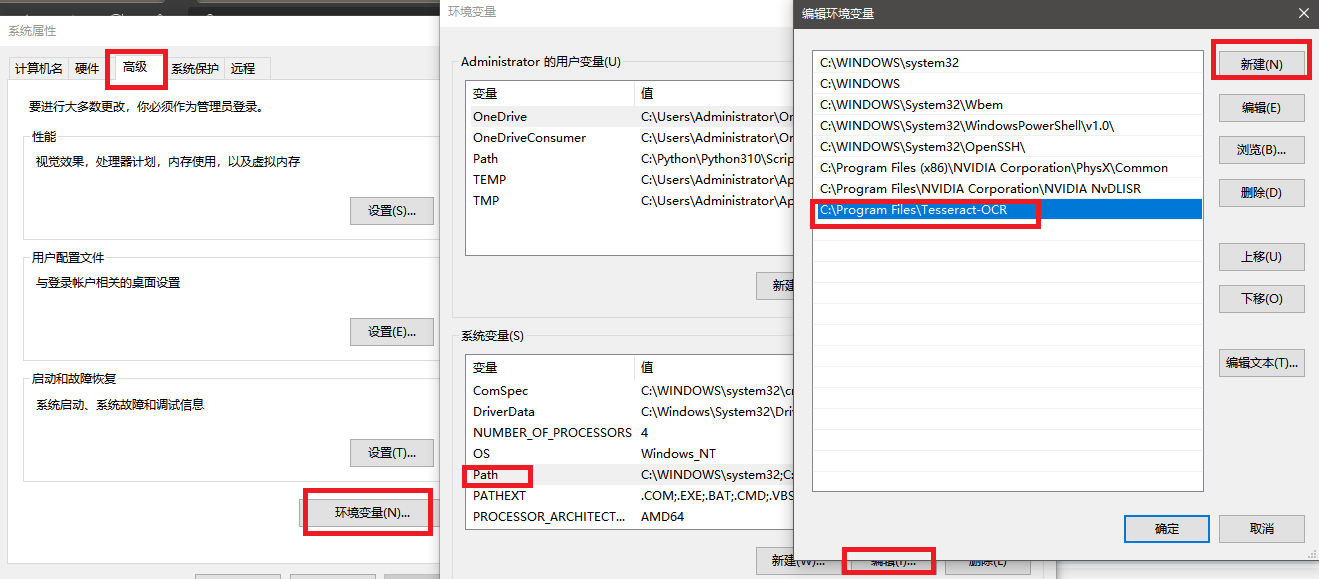
后来电脑重新安装了,安装在了C盘
C:\Program Files\Tesseract-OCR
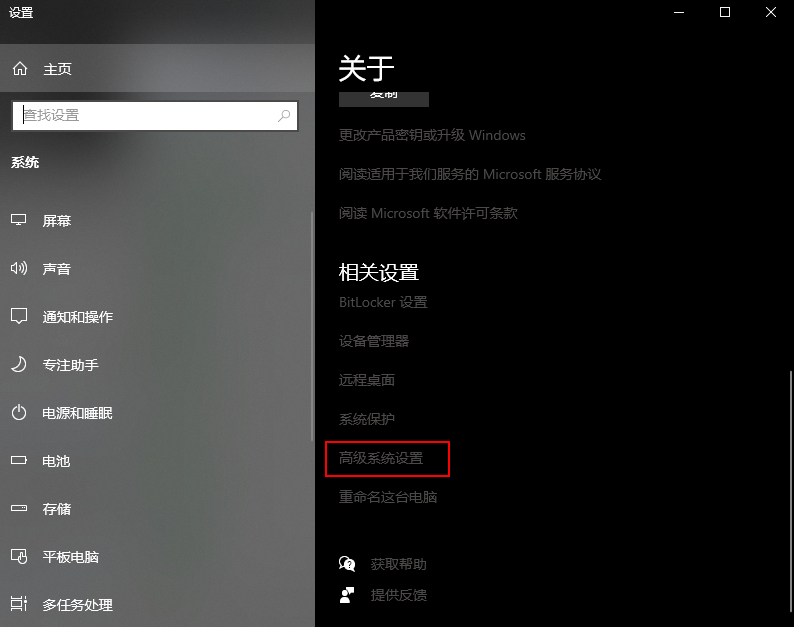
高级系统设置:
ref Python+pytesseract+Tesseract-OCR图片文字识别(只适合新手)_zhangshaohua1603的博客-CSDN博客_python tesseract-ocr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号