LiteFlow 框架全景解析:从入门到精通的技术内幕
LiteFlow 框架全景解析:从入门到精通的技术内幕
请关注公众号【碳硅化合物AI】
摘要
LiteFlow 作为一款轻量级的编排式规则引擎,在解决复杂业务逻辑解耦方面独树一帜。本文将从架构设计、核心实现、扩展机制、框架集成以及市场定位等多个维度,全面剖析 LiteFlow 的技术内幕。通过深入源码分析、关键类关系梳理、执行流程时序图以及核心技术点解读,帮助开发者深入理解 LiteFlow 的设计哲学和实现精髓。
一、LiteFlow 的设计哲学:组件化与编排化的完美结合
1.1 核心定位
LiteFlow 的诞生,源于一个很现实的问题:当你的业务代码里充斥着各种 if-else 和臃肿的 Service 调用时,改一个逻辑可能要动好几个文件,牵一发而动全身。LiteFlow 的出现就是为了解决这个问题。
它的核心思想非常简单,就两点:
- 组件化:把业务逻辑切碎,每个组件只负责一件事。
- 编排化:用规则文件来决定执行顺序,而不是硬编码在代码里。
这种设计带来的好处是显而易见的:业务逻辑变更时,你只需要修改规则文件,甚至不用重启应用(热刷新),就能让新逻辑生效。这在快速迭代的业务场景下,简直是福音。
1.2 核心概念速览
在深入源码之前,咱们得先对齐一下 LiteFlow 的几个核心概念:
- Node(节点):流程中最小的执行单元,通常对应一个 Java 类。
- Component(组件):Node 的具体实现,继承自
NodeComponent。 - Chain(流程链):一串 Node 的组合,通过 EL 表达式定义执行顺序。
- EL(表达式语言):LiteFlow 独创的语法,比如
THEN(a, b, c)表示串行,WHEN(a, b, c)表示并行。 - Slot(槽/上下文):流程执行的数据容器,所有组件共享这个数据空间。
二、核心架构:四大金刚撑起整个框架
2.1 整体架构图
LiteFlow 的核心架构可以用四个核心类来概括:FlowExecutor、FlowBus、NodeComponent 和 DataBus。它们各司其职,共同构建了一个高效、灵活的流程执行引擎。

2.2 FlowExecutor:流程执行的指挥官
FlowExecutor 是 LiteFlow 对外暴露的主要入口,所有的流程执行都从这里开始。它承担了两个核心职责:
职责一:初始化框架
在 Spring Boot 启动时,FlowExecutor 的 init() 方法会被调用,主要做了这几件事:
public void init(boolean isStart) {
// 1. 初始化组件(Spring 环境下会扫描并注册组件)
ContextCmpInitHolder.loadContextCmpInit().initCmp();
// 2. 解析规则文件
FlowParser parser = FlowParserProvider.lookup(ruleSource);
parser.parseMain(rulePathList);
// 3. 初始化 DataBus(分配数据槽位)
DataBus.init();
// 4. 启动文件监听(如果开启)
if (liteflowConfig.getEnableMonitorFile()) {
MonitorFile.getInstance().create();
}
}
职责二:执行流程
当业务代码调用 flowExecutor.execute2Resp("chain1", param) 时,FlowExecutor 会:
- 从
DataBus申请一个 Slot(数据槽),用于存储本次执行的上下文数据。 - 从
FlowBus获取名为chain1的流程链。 - 调用
Chain.execute(slotIndex)开始执行流程。 - 执行完成后,释放 Slot,归还给
DataBus。
这里有个巧妙的设计:Slot Index。LiteFlow 并不直接在各组件间传递庞大的 Context 对象,而是传递一个轻量级的 Integer 下标。组件需要数据时,拿这个下标去 DataBus 换取真正的 Slot。这种设计大大降低了参数传递的开销。
2.3 FlowBus:元数据的交通枢纽
FlowBus 是一个静态类,充当了 LiteFlow 的"内存数据库"。它维护了三个核心 Map:
chainMap:存储所有解析好的流程链。nodeMap:存储所有的节点组件。fallbackNodeMap:存储降级组件(用于异常处理)。
public class FlowBus {
private static final Map<String, Chain> chainMap;
private static final Map<String, Node> nodeMap;
private static final Map<String, Node> fallbackNodeMap;
public static Chain getChain(String id) {
return chainMap.get(id);
}
public static void addChain(Chain chain) {
chainMap.put(chain.getChainId(), chain);
}
}
LiteFlow 的热刷新功能,本质上就是重新解析规则,然后更新 FlowBus 里的这些 Map。由于使用了线程安全的 ConcurrentHashMap 或 CopyOnWriteHashMap,热刷新过程中不会影响正在执行的流程。
2.4 NodeComponent:业务逻辑的载体
NodeComponent 是所有业务组件的基类。你自己写的组件(比如 ACmp)都继承自它。它定义了组件的完整生命周期:
isAccess():是否允许执行(可用于简单的准入判断)。beforeProcess():前置处理钩子。process():核心业务逻辑(必须实现)。onSuccess():成功回调。onError():失败回调。afterProcess():后置处理钩子。
在 NodeComponent 中,有个 self 属性很有意思:
private NodeComponent self;
这是为了解决 Spring AOP 代理问题。如果组件被代理了,this 指向的是原始对象,而 self 指向代理对象,确保切面能生效。
2.5 DataBus:高性能的数据管理中心
LiteFlow 的高性能很大程度上归功于 DataBus 的设计。它解决了一个核心问题:高并发下的数据隔离与复用。
复用池机制
DataBus 内部维护了一个 Slot 池(默认 1024 个):
- 结构:
ConcurrentHashMap<Integer, Slot>存数据,ConcurrentLinkedQueue<Integer>存空闲下标。 - 申请:
QUEUE.poll()拿一个下标,拿不到就扩容(1.75倍)。 - 释放:
QUEUE.add(index)归还下标。
这种池化设计避免了频繁创建和销毁 Context 对象,极大降低了 GC 压力。在高并发场景下,这种设计带来的性能提升是显著的。
Slot(槽)
Slot 是真正的上下文容器。它里面存放了:
requestData:初始请求参数。contextBeanList:用户定义的上下文 Bean(如 Spring 的 Bean 或普通的 Pojo)。dataMap:内部传递数据的 Map。
所有组件都可以通过 getSlot() 方法获取到当前执行的 Slot,从而实现数据共享。
三、执行流程:从调用到完成的完整链路
3.1 完整执行时序图
让我们通过一张时序图,看看一个完整的流程执行是如何进行的:
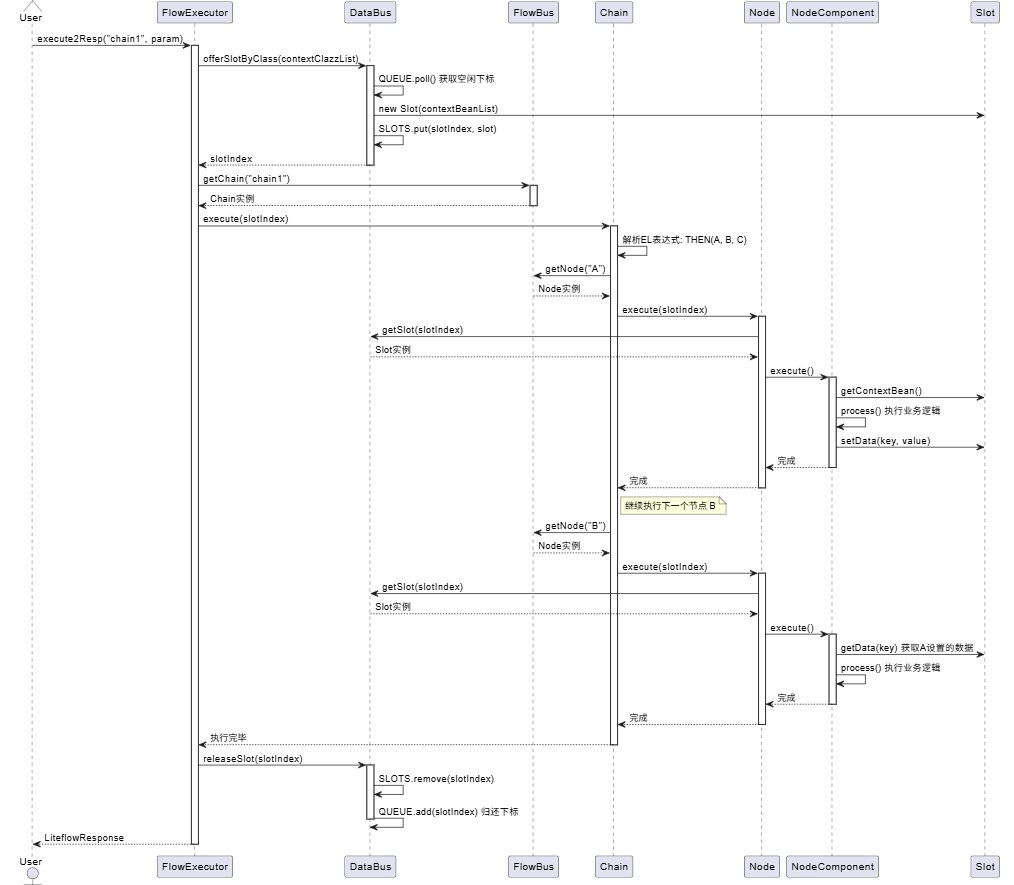
3.2 关键流程解析
第一步:申请 Slot
当 FlowExecutor 收到执行请求时,首先会从 DataBus 申请一个 Slot。这个过程是线程安全的,多个并发请求会拿到不同的 Slot 下标,从而实现了数据隔离。
第二步:查找 Chain
FlowExecutor 从 FlowBus 中查找对应的 Chain。如果找不到,会抛出 ChainNotFoundException。
第三步:执行 Chain
Chain 会根据 EL 表达式(比如 THEN(A, B, C))解析出需要执行的节点顺序,然后依次调用每个 Node 的 execute() 方法。
第四步:执行 Node
每个 Node 在执行时,会:
- 从
DataBus获取对应的Slot(通过 slotIndex)。 - 调用
NodeComponent的execute()方法。 NodeComponent执行process()方法,执行业务逻辑。- 业务逻辑可以通过
Slot存取数据。
第五步:释放 Slot
执行完成后,FlowExecutor 会将 Slot 归还给 DataBus,供后续请求复用。
四、插件扩展机制:SPI 驱动的无限可能
4.1 微内核 + 插件架构
LiteFlow 采用了典型的微内核 + 插件架构。liteflow-core 负责核心流程调度,而具体的规则解析(Parser)和脚本执行(Script Executor)则通过 SPI(Service Provider Interface)机制开放给插件实现。
这种设计的好处显而易见:
- 轻量:核心包不臃肿,用户按需引入插件依赖。
- 灵活:想支持新语言?写个插件就行,不用改核心代码。
4.2 脚本插件机制
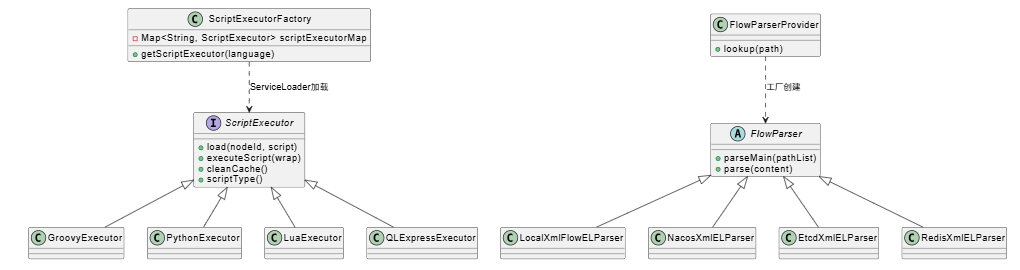
LiteFlow 支持在流程中直接嵌入脚本代码,这使得业务逻辑极其灵活。这一能力的背后是 ScriptExecutor 接口。
核心接口
所有的脚本执行器都必须实现 ScriptExecutor 抽象类:
public abstract class ScriptExecutor {
// 加载并编译脚本
public abstract void load(String nodeId, String script);
// 执行脚本
public abstract Object executeScript(ScriptExecuteWrap wrap) throws Exception;
// 清理缓存
public abstract void cleanCache();
// 返回支持的脚本类型
public abstract ScriptTypeEnum scriptType();
}
插件加载
LiteFlow 使用 Java 原生的 ServiceLoader 来发现插件:
public class ScriptExecutorFactory {
public ScriptExecutor getScriptExecutor(String language) {
ServiceLoader<ScriptExecutor> loader = ServiceLoader.load(ScriptExecutor.class);
for (ScriptExecutor executor : loader) {
if (scriptType.equals(executor.scriptType())) {
return executor;
}
}
}
}
以 Groovy 插件为例,它的 META-INF/services/com.yomahub.liteflow.script.ScriptExecutor 文件内容为:
com.yomahub.liteflow.script.groovy.GroovyExecutor
这样,当你在规则里定义 <node id="s1" type="script" language="groovy">...</node> 时,工厂类就能自动找到 GroovyExecutor 来执行这段代码。
4.3 规则源插件机制
LiteFlow 默认支持本地 XML/JSON/YAML 文件。但企业级开发中,规则通常存储在配置中心(如 Nacos, Apollo)或数据库中。
对于扩展插件(如 Nacos),通常会提供一个特定的 Parser 实现,例如 NacosXmlELParser。这个 Parser 会:
- 拉取配置:使用 Nacos SDK 监听并拉取配置内容。
- 解析配置:调用父类的
parse(content)方法将内容转化为 Chain 和 Node。 - 监听变更:注册监听器,当配置更新时,触发
FlowBus.reloadChain进行热刷新。
4.4 插件架构类图
五、Spring Boot 集成:无缝融合的艺术
5.1 自动装配机制
LiteFlow 对 Spring Boot 的支持可谓是"开箱即用"。一切的起点都在 liteflow-spring-boot-starter 包中。核心配置类是 LiteflowMainAutoConfiguration:
@Configuration
@AutoConfigureAfter({ LiteflowPropertyAutoConfiguration.class })
@ConditionalOnBean(LiteflowConfig.class)
@ConditionalOnProperty(prefix = "liteflow", name = "enable", havingValue = "true")
public class LiteflowMainAutoConfiguration {
@Bean
public FlowExecutor flowExecutor(LiteflowConfig liteflowConfig) {
FlowExecutor flowExecutor = new FlowExecutor();
flowExecutor.setLiteflowConfig(liteflowConfig);
return flowExecutor;
}
@Bean
public ComponentScanner componentScanner(LiteflowConfig liteflowConfig) {
return new ComponentScanner(liteflowConfig);
}
@Bean
public LiteflowExecutorInit liteflowExecutorInit(FlowExecutor flowExecutor) {
return new LiteflowExecutorInit(flowExecutor);
}
}
这里有三个关键 Bean,它们共同完成了 LiteFlow 的自动装配。
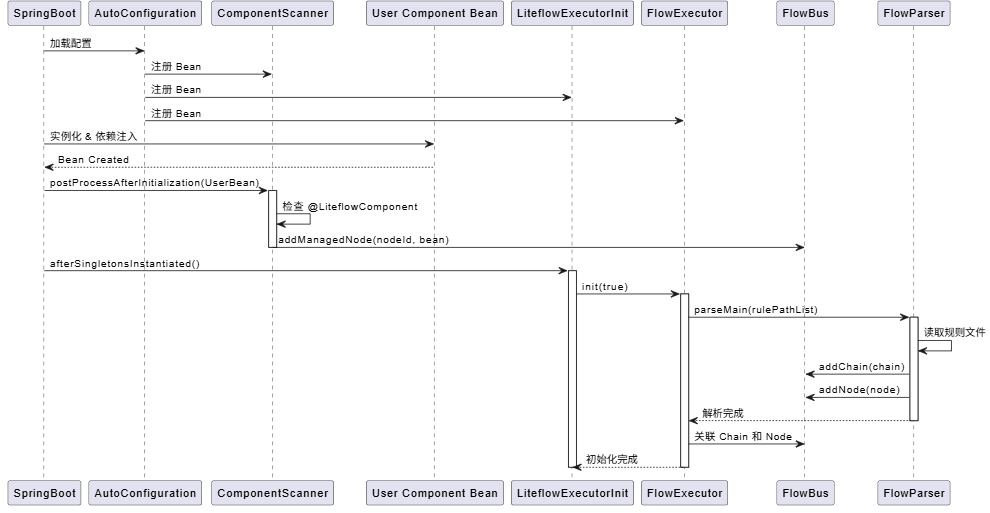
5.2 组件扫描:ComponentScanner
你在 Spring Bean 上加了 @LiteflowComponent,LiteFlow 是怎么知道的?全靠 ComponentScanner。
它实现了 Spring 的 BeanPostProcessor 接口:
public class ComponentScanner implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
Class clazz = LiteFlowProxyUtil.getUserClass(bean.getClass());
// 判断是否是 LiteFlow 组件
if (是LiteFlow组件) {
// 注册到 FlowBus
FlowBus.addManagedNode(nodeId, bean);
}
return bean;
}
}
当 Spring 容器初始化完一个 Bean 后,ComponentScanner 会介入检查。如果这个 Bean 是 LiteFlow 的组件,它就会提取 nodeId、name 等信息,并将其注册到 LiteFlow 的元数据中心 FlowBus 里。
这也解释了为什么 LiteFlow 的组件可以无缝使用 Spring 的 @Autowired 等特性——因为它们本身就是 Spring 容器管理的 Bean。
5.3 启动初始化:LiteflowExecutorInit
规则文件什么时候解析?流程链什么时候构建?答案是在 Spring 容器启动完成之后。
LiteflowExecutorInit 实现了 SmartInitializingSingleton 接口:
public class LiteflowExecutorInit implements SmartInitializingSingleton {
@Override
public void afterSingletonsInstantiated() {
flowExecutor.init(true);
}
}
afterSingletonsInstantiated 方法会在所有单例 Bean 都创建完成之后被调用。这是一个绝佳的时机:
- 依赖就绪:此时所有的组件 Bean 都已经扫描并创建好了。
- 避免死锁:避免在 Bean 创建过程中触发复杂的解析逻辑。
调用 flowExecutor.init(true) 后,LiteFlow 开始解析规则文件,构建 Chain,并将其与之前扫描到的 Node 关联起来,最终完成启动。
5.4 Spring Boot 集成时序图
六、关键技术点深度剖析
6.1 Slot Index 设计:轻量级上下文传递
LiteFlow 的一个核心设计亮点是 Slot Index 机制。它并不直接在各组件间传递庞大的 Context 对象,而是传递一个轻量级的 Integer 下标。
为什么这样设计?
- 性能优势:传递一个
Integer比传递一个包含多个 Bean 的 Context 对象要轻量得多。 - 线程安全:每个请求都有独立的 Slot Index,天然实现了数据隔离。
- 内存复用:通过
DataBus的池化机制,Slot 对象可以被复用,降低 GC 压力。
实现细节
// FlowExecutor 中
Integer slotIndex = DataBus.offerSlotByClass(contextClazzList);
Slot slot = DataBus.getSlot(slotIndex);
// NodeComponent 中
public Slot getSlot() {
return DataBus.getSlot(this.getSlotIndex());
}
6.2 热刷新机制:零停机更新规则
LiteFlow 的热刷新功能是其一大亮点。它允许在不重启应用的情况下,动态更新规则文件。
实现原理
- 文件监听:如果配置了
enable-monitor-file=true,LiteFlow 会启动文件监听器(基于 Java NIO 的 WatchService)。 - 配置中心监听:如果使用 Nacos、Etcd 等配置中心,会注册配置变更监听器。
- 原子更新:当检测到变更时,会重新解析规则,然后原子性地更新
FlowBus中的chainMap和nodeMap。
并发安全
由于使用了线程安全的 Map(ConcurrentHashMap 或 CopyOnWriteHashMap),热刷新过程中不会影响正在执行的流程。正在执行的流程使用的是旧的 Chain 引用,新请求会使用新的 Chain 引用。
6.3 并行执行:WHEN 关键字的多线程实现
LiteFlow 的 WHEN 关键字支持并行执行多个节点,这是如何实现的?
实现原理
// Chain 中解析 WHEN 表达式
if (是WHEN表达式) {
List<CompletableFuture<Object>> futures = new ArrayList<>();
for (Node node : nodes) {
CompletableFuture<Object> future = CompletableFuture.supplyAsync(
() -> node.execute(slotIndex),
ExecutorHelper.loadInstance().buildWhenExecutor()
);
futures.add(future);
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).get();
}
LiteFlow 使用了 CompletableFuture 来实现并行执行,每个节点在独立的线程中执行,最后等待所有节点完成。
6.4 声明式组件:让任意类秒变组件
LiteFlow 2.11.0 引入了声明式组件的概念,允许你不需要继承 NodeComponent,只需要在方法上加注解,就能让一个普通的类变成 LiteFlow 组件。
实现原理
LiteFlow 使用了动态代理(ByteBuddy)来生成代理类:
// 原始类
public class UserService {
@LiteflowMethod(LiteFlowMethodEnum.PROCESS)
public void process() {
// 业务逻辑
}
}
// LiteFlow 会生成代理类
public class UserService$Proxy extends NodeComponent {
private UserService target;
@Override
public void process() {
target.process();
}
}
这样,你就可以在不修改原有代码的情况下,让任意类变成 LiteFlow 组件。
七、市场定位:在规则引擎领域的独特价值
7.1 与竞品对比
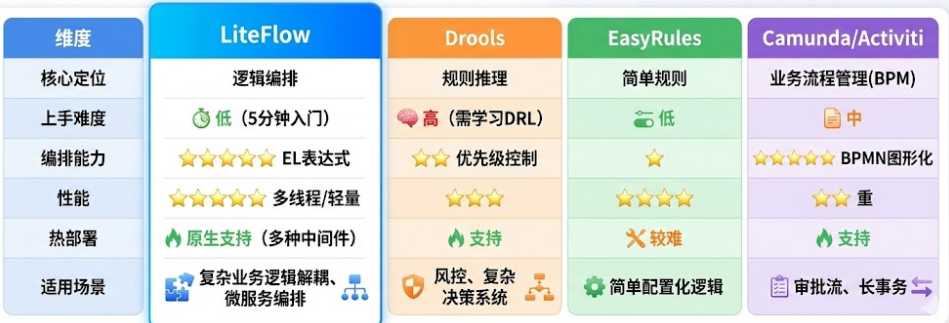
LiteFlow 在规则引擎领域处于一个独特的位置。让我们看看它与其他主流方案的对比:
| 维度 | LiteFlow | Drools | EasyRules | Camunda/Activiti |
|---|---|---|---|---|
| 核心定位 | 逻辑编排 | 规则推理 | 简单规则 | 业务流程管理(BPM) |
| 上手难度 | 低 (5分钟入门) | 高 (需学习DRL) | 低 | 中 |
| 编排能力 | ⭐⭐⭐⭐⭐ (EL表达式) | ⭐⭐ (优先级控制) | ⭐ | ⭐⭐⭐⭐⭐ (BPMN图形化) |
| 性能 | ⭐⭐⭐⭐⭐ (多线程/轻量) | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ (重) |
| 热部署 | 原生支持 (多种中间件) | 支持 | 较难 | 支持 |
| 适用场景 | 复杂业务逻辑解耦、微服务编排 | 风控、复杂决策系统 | 简单配置化逻辑 | 审批流、长事务 |
7.2 适用场景
选 LiteFlow 还是选其他的?
- 如果你需要做人工审批流,选 Camunda/Activiti。
- 如果你的业务是纯粹的复杂数学/逻辑推理(比如保险费率计算、复杂的风控打分),且规则之间关系错综复杂,选 Drools。
- 如果你只是有几个简单的 if-else 想配置化,EasyRules 够用了。
- 但是,如果你面临的是复杂的业务流程开发(比如电商下单、价格计算、支付路由),代码里充斥着大量的 Service 调用和硬编码的顺序逻辑,且需要频繁变动,那么 LiteFlow 是不二之选。
LiteFlow 填补了"简单规则"和"重型工作流"之间的空白,用轻量级的组件编排解决了最常见的业务解耦痛点。
八、总结:LiteFlow 的技术价值与未来展望
8.1 核心价值总结
通过深入分析 LiteFlow 的源码和架构,我们可以总结出它的几个核心价值:
- 解耦能力:通过组件化和规则化,实现了业务逻辑与执行顺序的解耦,让代码更易维护。
- 高性能:通过 Slot 池化、轻量级上下文传递、多线程并行执行等设计,保证了框架的高性能。
- 高扩展性:通过 SPI 插件机制,支持多种脚本语言和配置中心,满足不同场景的需求。
- 易用性:与 Spring Boot 深度集成,开箱即用,学习成本低。
- 热刷新:支持多种数据源的热刷新,实现零停机更新规则。
8.2 设计亮点回顾
- Slot Index 机制:轻量级上下文传递,性能优异。
- FlowBus 元数据管理:线程安全的元数据存储,支持热刷新。
- DataBus 池化设计:高效的 Slot 复用机制,降低 GC 压力。
- SPI 插件架构:微内核设计,无限扩展可能。
- Spring Boot 深度集成:利用 BeanPostProcessor 和 SmartInitializingSingleton,实现无缝集成。
8.3 技术启示
LiteFlow 的成功,给我们带来了几个技术启示:
- 简单即美:核心设计要简单,扩展通过插件实现。
- 性能优先:在高并发场景下,每一个细节都要考虑性能。
- 用户体验:框架要易用,集成要无缝,学习成本要低。
- 持续演进:通过热刷新等机制,支持业务的快速迭代。
8.4 未来展望
LiteFlow 作为一个持续迭代的开源项目,未来可能会在以下方面继续演进:
- 更多脚本语言支持:随着新脚本语言的兴起,LiteFlow 可能会支持更多语言。
- 可视化编排:可能会提供图形化的规则编排界面,降低使用门槛。
- 分布式支持:可能会支持跨服务的流程编排,实现真正的微服务编排。
- 监控与可观测性:可能会提供更完善的监控和链路追踪能力。
结语
LiteFlow 作为一款轻量级的编排式规则引擎,在解决复杂业务逻辑解耦方面展现出了独特的价值。通过组件化、编排化、插件化等设计,它既保证了框架的轻量和性能,又提供了强大的扩展能力。无论是对于个人开发者还是企业团队,LiteFlow 都是一个值得深入学习和使用的优秀框架。
希望通过本文的深入分析,能够帮助开发者更好地理解 LiteFlow 的设计哲学和实现精髓,在实际项目中发挥出它的最大价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号