
Hudi 文件格式分析
Hudi 文件格式分析
请关注微信公众号:阿呆-bot
主题说明
Hudi 支持多种文件格式来存储数据,不同的格式有不同的特点和适用场景。理解文件格式的选择和使用,有助于优化存储和查询性能。
Hudi 主要使用两种文件格式:
- Parquet:用于基础文件(BaseFile),列式存储,查询性能好
- Avro:用于增量日志(LogFile),行式存储,写入性能好
另外还支持 ORC 作为基础文件的替代选择,以及 HFile 用于元数据表。
细化内容
Parquet 格式 - 基础文件
Parquet 是列式存储格式,特别适合分析型查询。Hudi 使用 Parquet 作为基础文件的默认格式。
Parquet 的特点:
- 列式存储:相同列的数据存储在一起,压缩率高
- 谓词下推:可以直接在文件层面过滤数据,减少IO
- 投影下推:只读取需要的列,减少数据传输
- 压缩效率高:列式存储天然适合压缩
在 Hudi 中的使用:
- 基础文件(BaseFile)默认使用 Parquet
- 文件名格式:
{fileId}_{commitTime}.parquet - 支持 Schema 演化,可以添加新列
Avro 格式 - 增量日志
Avro 是行式存储格式,特别适合增量写入。Hudi 使用 Avro 作为增量日志的格式。
Avro 的特点:
- 行式存储:一条记录的所有字段存储在一起
- Schema 驱动:Schema 和数据分离,支持 Schema 演化
- 紧凑的二进制格式:比 JSON 等文本格式更省空间
- 写入性能好:追加写入效率高
在 Hudi 中的使用:
- 增量日志(LogFile)使用 Avro
- 日志文件包含多个数据块(Data Block)
- 每个数据块可以包含多条记录
ORC 格式 - 替代选择
ORC(Optimized Row Columnar)是另一种列式存储格式,可以作为 Parquet 的替代。
ORC 的特点:
- 列式存储:类似 Parquet
- 支持 ACID 事务:原生支持更新和删除
- 压缩率高:使用多种压缩算法
- Hive 集成好:Hive 原生支持 ORC
在 Hudi 中的使用:
- 可以作为基础文件的格式选择
- 通过配置
hoodie.table.base.file.format=ORC启用
HFile 格式 - 元数据表
HFile 是 HBase 的文件格式,Hudi 用它来存储元数据表。
HFile 的特点:
- 键值存储:适合存储键值对数据
- 排序存储:键按顺序存储,查找效率高
- 支持 Bloom Filter:快速判断键是否存在
在 Hudi 中的使用:
- 元数据表使用 HFile 格式
- 存储文件列表、列统计等元数据信息
关键技术
文件格式的选择策略
Hudi 根据表类型选择文件格式:
Copy-on-Write 表:
- 基础文件:Parquet(默认)或 ORC
- 没有日志文件,每次更新都重写基础文件
Merge-on-Read 表:
- 基础文件:Parquet(默认)或 ORC
- 日志文件:Avro 格式
- 查询时需要合并基础文件和日志文件
文件格式的读写器
Hudi 通过 HoodieIOFactory 来获取不同格式的读写器:
- ParquetFileFormatUtils:Parquet 格式的读写工具
- AvroFileFormatUtils:Avro 格式的读写工具
- ORCFileFormatUtils:ORC 格式的读写工具
这些工具类封装了格式特定的读写逻辑。
Schema 演化支持
Hudi 支持 Schema 演化,可以在不重写数据的情况下添加新列:
- Parquet:支持添加新列,向后兼容
- Avro:支持 Schema 演化,通过 Schema Registry 管理
- ORC:支持添加新列
Schema 演化时,旧数据的新列会使用默认值。
压缩和编码
不同格式使用不同的压缩和编码策略:
- Parquet:支持 Snappy、Gzip、LZO 等压缩算法
- Avro:支持 Deflate、Snappy 等压缩算法
- ORC:支持 Zlib、Snappy、LZO 等压缩算法
压缩算法的选择影响压缩率和压缩速度。
关键对象说明
类关系图
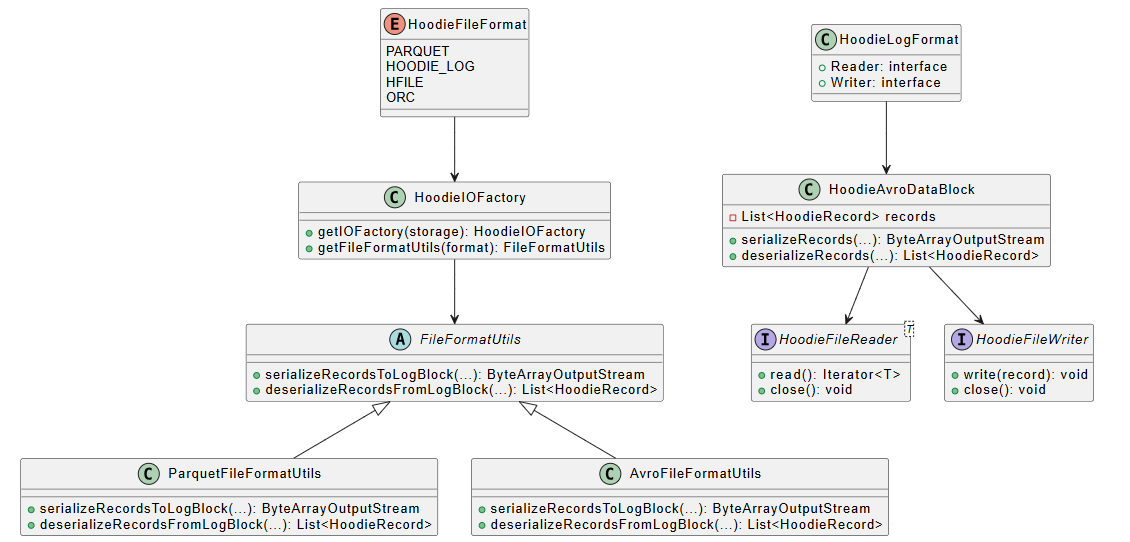
关键类说明
- HoodieFileFormat:文件格式枚举,定义了支持的格式类型。
- HoodieIOFactory:IO 工厂类,根据存储和格式获取对应的工具类。
- FileFormatUtils:文件格式工具抽象类,定义了序列化和反序列化的接口。
- ParquetFileFormatUtils:Parquet 格式工具类,处理 Parquet 文件的读写。
- AvroFileFormatUtils:Avro 格式工具类,处理 Avro 文件的读写。
- HoodieLogFormat:日志文件格式接口,定义了日志文件的读写接口。
- HoodieAvroDataBlock:Avro 数据块,日志文件中的数据块实现。
关键操作时序图
下面是一个文件读取操作的时序图,展示了如何读取 Parquet 基础文件和 Avro 日志文件:

代码示例
读取 Parquet 文件
// 获取 IO 工厂
HoodieIOFactory ioFactory = HoodieIOFactory.getIOFactory(storage);
// 获取 Parquet 格式工具
FileFormatUtils parquetUtils = ioFactory.getFileFormatUtils(HoodieFileFormat.PARQUET);
// 读取基础文件
HoodieBaseFile baseFile = fileSlice.getBaseFile().get();
List<HoodieRecord> records = parquetUtils.deserializeRecordsFromLogBlock(
storage,
baseFile.getPath(),
schema
);
写入 Avro 日志文件
// 获取 Avro 格式工具
FileFormatUtils avroUtils = ioFactory.getFileFormatUtils(HoodieFileFormat.HOODIE_LOG);
// 序列化记录到日志块
ByteArrayOutputStream outputStream = avroUtils.serializeRecordsToLogBlock(
storage,
records,
schema,
keyFieldName,
paramsMap
);
// 写入日志文件
HoodieLogFileWriter writer = HoodieLogFormat.newWriterBuilder()
.withStorage(storage)
.withLogFile(logFile)
.build();
writer.appendBlock(outputStream.toByteArray());
配置文件格式
// 配置基础文件格式为 ORC
HoodieWriteConfig config = HoodieWriteConfig.newBuilder()
.withPath(basePath)
.withBaseFileFormat(HoodieFileFormat.ORC)
.build();
总结
Hudi 支持多种文件格式,每种格式都有其适用场景。核心要点:
- Parquet 是基础文件的默认格式,列式存储,查询性能好
- Avro 是日志文件的格式,行式存储,写入性能好
- ORC 可以作为 Parquet 的替代,在某些场景下性能更好
- HFile 用于元数据表,键值存储,查找效率高
- 文件格式选择 影响存储效率和查询性能
- Schema 演化 支持在不重写数据的情况下添加新列
理解文件格式有助于优化 Hudi 表的存储和查询性能,选择合适的格式可以显著提升系统效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号