Spring AI 代码分析(五)--RAG 分析
Spring AI RAG 分析
请关注微信公众号:阿呆-bot
1. 工程结构概览
spring-ai-rag 是 Spring AI 的检索增强生成(Retrieval Augmented Generation)框架,它提供了完整的 RAG 能力,让 AI 模型能够访问外部知识库。
spring-ai-rag/
├── advisor/
│ └── RetrievalAugmentationAdvisor.java # RAG Advisor
│
├── retrieval/ # 检索层
│ └── search/
│ ├── DocumentRetriever.java # 文档检索接口
│ └── VectorStoreDocumentRetriever.java # 向量存储检索实现
│
├── preretrieval/ # 检索前处理
│ └── query/
│ ├── transformation/ # 查询转换
│ │ ├── QueryTransformer.java
│ │ ├── RewriteQueryTransformer.java
│ │ └── CompressionQueryTransformer.java
│ └── expansion/ # 查询扩展
│ └── QueryExpander.java
│
├── postretrieval/ # 检索后处理
│ └── DocumentPostProcessor.java
│
└── generation/ # 生成层
└── augmentation/
└── ContextualQueryAugmenter.java # 上下文查询增强
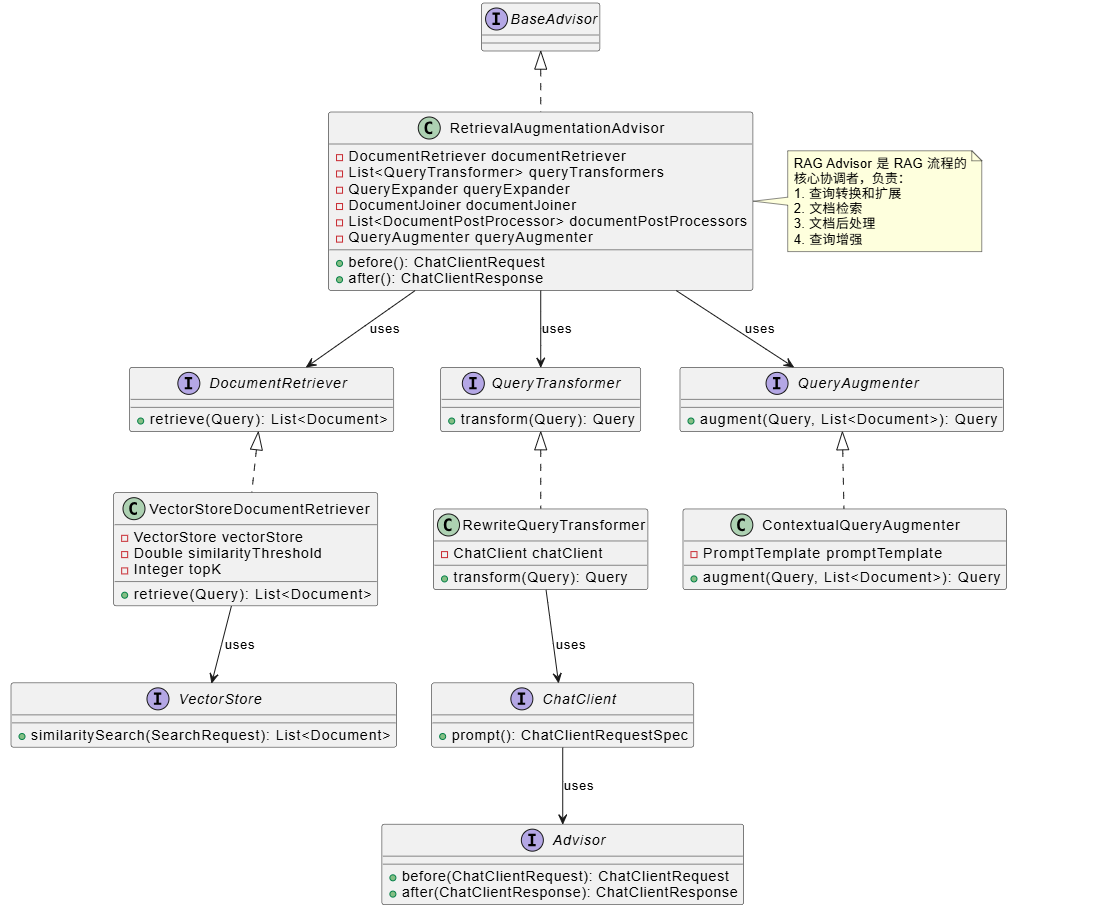
2. 技术体系与模块关系
RAG 框架通过 Advisor 机制集成到 ChatClient,实现了完整的检索增强生成流程:
3. 关键场景示例代码
3.1 基础 RAG 使用
最简单的 RAG 使用方式:
@Autowired
private ChatModel chatModel;
@Autowired
private VectorStore vectorStore;
public void basicRAG() {
// 创建向量存储检索器
VectorStoreDocumentRetriever retriever =
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(5)
.similarityThreshold(0.7)
.build();
// 创建 RAG Advisor
RetrievalAugmentationAdvisor ragAdvisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever)
.build();
// 使用 ChatClient
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(ragAdvisor)
.build();
String response = chatClient.prompt()
.user("查询文档中的信息")
.call()
.content();
}
3.2 带查询重写的 RAG
查询重写可以优化检索效果:
public void ragWithQueryRewrite() {
// 创建查询重写器
RewriteQueryTransformer queryTransformer =
RewriteQueryTransformer.builder()
.chatClient(ChatClient.builder(chatModel))
.targetSearchSystem("vector store")
.build();
// 创建 RAG Advisor
RetrievalAugmentationAdvisor ragAdvisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever)
.queryTransformers(queryTransformer)
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(ragAdvisor)
.build();
}
3.3 多查询扩展
查询扩展可以从一个查询生成多个相关查询:
public void ragWithQueryExpansion() {
// 创建查询扩展器
QueryExpander queryExpander = new MultiQueryExpander(
ChatClient.builder(chatModel)
);
RetrievalAugmentationAdvisor ragAdvisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever)
.queryExpander(queryExpander)
.build();
}
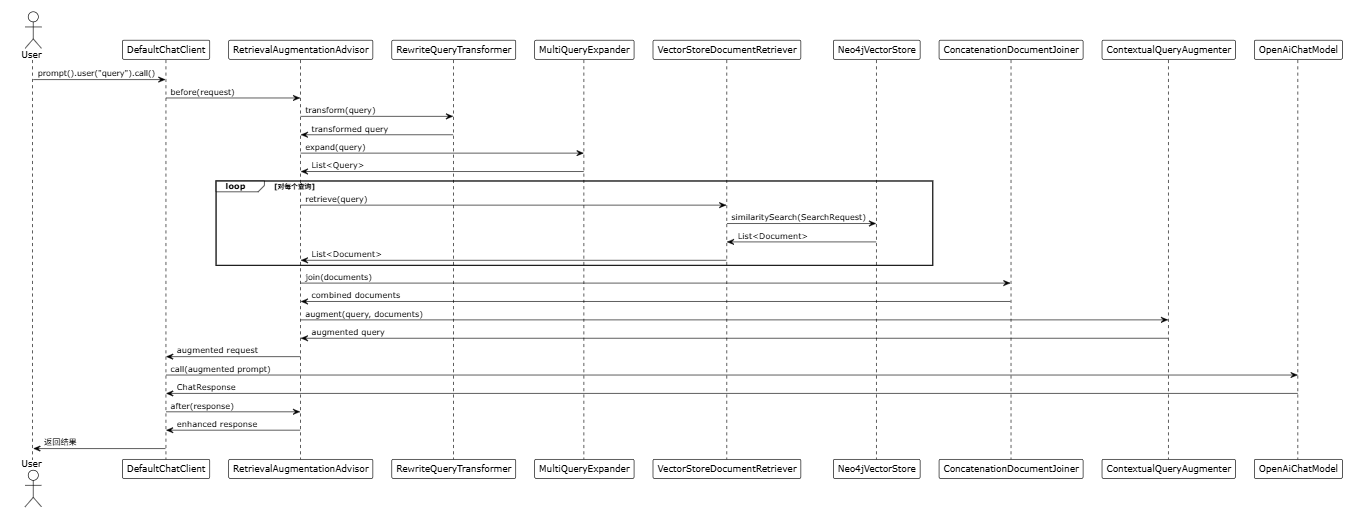
4. 核心时序图
4.1 RAG 完整流程
5. 入口类与关键类关系

6. 关键实现逻辑分析
6.1 RetrievalAugmentationAdvisor 核心逻辑
RetrievalAugmentationAdvisor 是 RAG 流程的核心协调者:
public class RetrievalAugmentationAdvisor implements BaseAdvisor {
@Override
public ChatClientRequest before(ChatClientRequest request, AdvisorChain chain) {
// 1. 构建原始查询
Query originalQuery = Query.builder()
.text(request.prompt().getUserMessage().getText())
.history(request.prompt().getInstructions())
.context(request.context())
.build();
// 2. 查询转换
Query transformedQuery = originalQuery;
for (QueryTransformer transformer : queryTransformers) {
transformedQuery = transformer.transform(transformedQuery);
}
// 3. 查询扩展
List<Query> expandedQueries = queryExpander != null
? queryExpander.expand(transformedQuery)
: List.of(transformedQuery);
// 4. 并行检索文档
Map<Query, List<List<Document>>> documentsForQuery =
expandedQueries.parallelStream()
.map(query -> getDocumentsForQuery(query))
.collect(...);
// 5. 合并文档
List<Document> documents = documentJoiner.join(documentsForQuery);
// 6. 文档后处理
for (DocumentPostProcessor processor : documentPostProcessors) {
documents = processor.process(originalQuery, documents);
}
// 7. 查询增强
Query augmentedQuery = queryAugmenter.augment(originalQuery, documents);
// 8. 更新 Prompt
return request.mutate()
.prompt(augmentedQuery.toPrompt())
.context(context)
.build();
}
}
6.2 向量存储检索实现
VectorStoreDocumentRetriever 负责从向量存储中检索文档:
public class VectorStoreDocumentRetriever implements DocumentRetriever {
@Override
public List<Document> retrieve(Query query) {
// 1. 计算请求的过滤表达式
Filter.Expression filterExpression = computeRequestFilterExpression(query);
// 2. 构建搜索请求
SearchRequest searchRequest = SearchRequest.builder()
.query(query.text())
.filterExpression(filterExpression)
.similarityThreshold(this.similarityThreshold)
.topK(this.topK)
.build();
// 3. 执行相似度搜索
return vectorStore.similaritySearch(searchRequest);
}
}
6.3 查询重写实现
RewriteQueryTransformer 使用 LLM 重写查询以优化检索:
public class RewriteQueryTransformer implements QueryTransformer {
@Override
public Query transform(Query query) {
// 使用 LLM 重写查询
String rewrittenQueryText = chatClient.prompt()
.user(promptTemplate.getTemplate())
.param("target", targetSearchSystem)
.param("query", query.text())
.call()
.content();
return query.mutate()
.text(rewrittenQueryText)
.build();
}
}
6.4 查询增强实现
ContextualQueryAugmenter 将检索到的文档注入到用户查询中:
public class ContextualQueryAugmenter implements QueryAugmenter {
@Override
public Query augment(Query query, List<Document> documents) {
// 1. 格式化文档内容
String documentContext = formatDocuments(documents);
// 2. 使用模板增强查询
String augmentedText = promptTemplate.render(Map.of(
"query", query.text(),
"context", documentContext
));
return query.mutate()
.text(augmentedText)
.build();
}
}
7. 如何集成 Vector Store
RAG 框架通过 DocumentRetriever 接口抽象了向量存储的集成:
7.1 抽象机制
DocumentRetriever 接口提供了统一的文档检索抽象:
public interface DocumentRetriever extends Function<Query, List<Document>> {
List<Document> retrieve(Query query);
}
这种设计让 RAG 框架不直接依赖 VectorStore,而是通过 DocumentRetriever 抽象。这意味着:
- 可以支持多种数据源:向量存储、知识图谱、数据库等
- 易于扩展:可以实现自定义的
DocumentRetriever - 解耦:RAG 框架和向量存储完全解耦
7.2 VectorStoreDocumentRetriever 实现
VectorStoreDocumentRetriever 是向量存储的默认实现:
public class VectorStoreDocumentRetriever implements DocumentRetriever {
private final VectorStore vectorStore;
@Override
public List<Document> retrieve(Query query) {
SearchRequest request = SearchRequest.builder()
.query(query.text())
.topK(this.topK)
.similarityThreshold(this.similarityThreshold)
.filterExpression(computeFilterExpression(query))
.build();
return vectorStore.similaritySearch(request);
}
}
7.3 自定义 DocumentRetriever
可以轻松实现自定义的 DocumentRetriever:
public class CustomDocumentRetriever implements DocumentRetriever {
@Override
public List<Document> retrieve(Query query) {
// 自定义检索逻辑
// 可以从数据库、知识图谱、API 等检索
return customRetrieve(query);
}
}
8. 外部依赖
spring-ai-rag 的依赖:
- spring-ai-client-chat:ChatClient 和 Advisor 机制
- spring-ai-vector-store:向量存储抽象
- spring-ai-commons:Document 等基础类型
- Spring Framework:IoC 和核心功能
- Reactor Core:响应式处理(用于并行检索)
9. 工程总结
Spring AI RAG 框架的设计有几个亮点:
模块化设计。RAG 流程被拆成了多个独立的组件:查询转换、查询扩展、文档检索、文档后处理、查询增强。每个组件都能独立配置和替换,想用哪个用哪个。
抽象和解耦。通过 DocumentRetriever 接口,RAG 框架和向量存储完全解耦。这样就能支持多种数据源,想换就换,扩展起来也方便。
Advisor 机制集成。RAG 通过 Advisor 机制集成到 ChatClient,用起来特别简单,只需要加一个 Advisor 就行。
可扩展性。每个环节都支持自定义实现,比如自己写个查询转换器、文档后处理器什么的。这样 RAG 框架就能适应各种业务场景。
并行处理。查询扩展后生成的多个查询可以并行检索,性能更好。
总的来说,Spring AI RAG 框架是一个设计得不错、功能完整的 RAG 实现。它提供了完整的 RAG 能力,同时保持了高度的灵活性和可扩展性。开发者可以轻松构建基于 RAG 的 AI 应用,也能根据具体需求进行深度定制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号