利用ResNet-50进行犬种鉴定

作者:如缕清风
本文为博主原创,未经允许,请勿转载:https://www.cnblogs.com/warren2123/p/15033224.html
一、前言
本文基于残差网络模型,通过对ResNet-50模型进行微调,对不同狗狗品种数据集进行鉴定。
Dog Breed Identification数据集包含20579张不同size的彩色图片,共分为120类犬种。其中训练集包含10222张图片,测试集包含10357张图片。犬种数据集样本图如下所示。

二、基于Fine Tuning构建ResNet-50模型
随着模型深度的提升,出现网络出现退化问题,因此残差网络应运而生。通过微调已经构建好的模型,能够在相似的数据集运用,不再需要重新训练模型。本文模型构建分为四个部分:数据读取及预处理、构建ResNet-50模型以及模型微调、定义模型超参数以及评估方法、参数优化。
1、数据读取及预处理
本文采用pandas对数据进行预处理,以及通过GPU对运算进行提速。
import os, torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pandas as pd
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, models, transforms
from PIL import Image
from sklearn.model_selection import StratifiedShuffleSplit
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
通过pandas读取csv文件,显示前5条数据,发现原数据只存在两列数据,id对应图片名,breed对应犬种名称,总共有120种。
data_root = 'data' all_labels_df = pd.read_csv(os.path.join(data_root, 'labels.csv')) all_labels_df.head()
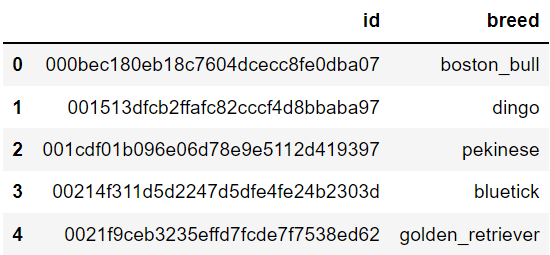
根据犬种名称,将其转化为id的形式进行一一对应,并在数据集中增加新列,表示犬种类别的id标签。
breeds = all_labels_df.breed.unique() breed2idx = dict((breed, idx) for idx, breed in enumerate(breeds)) idx2breed = dict((idx, breed) for idx, breed in enumerate(breeds)) all_labels_df['label_idx'] = all_labels_df['breed'].map(breed2idx)
将训练集分割出10%当作验证集,得到训练集和验证集两个数据集。
dataset_names = ['train', 'valid'] stratified_split = StratifiedShuffleSplit(n_splits=1, test_size=0.1, random_state=0) train_split_idx, val_split_idx = next(iter(stratified_split.split(all_labels_df.id, all_labels_df.breed))) train_df = all_labels_df.iloc[train_split_idx].reset_index() val_df = all_labels_df.iloc[val_split_idx].reset_index()
由于当前处理后的数据不能作为PyTorch的输入,所以需要自定义一个数据的读取。通过DogDataset类实现如下:
class DogDataset(Dataset):
def __init__(self, labels_df, img_path, transform=None):
self.labels_df = labels_df
self.img_path = img_path
self.transform = transform
def __len__(self):
return self.labels_df.shape[0]
def __getitem__(self, idx):
image_name = os.path.join(self.img_path, self.labels_df.id[idx]) + '.jpg'
img = Image.open(image_name)
label = self.labels_df.label_idx[idx]
if self.transform:
img = self.transform(img)
return img, label
下一步,定义了数据的预处理方法,包括:Resize、Crop、Normalize等三种主要方法,数据增强采用了RandomResizedCrop、RandomHorizontalFlip、RandomRotation。图片读取的方式采用PyTorch的DataLoader。
train_transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(30),
transforms.ToTensor(),
transforms.Normalize(img_mean, img_std)
])
val_transforms = transforms.Compose([
transforms.Resize(img_size),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize(img_mean, img_std)
])
image_transforms = {'train': train_transforms, 'valid': val_transforms}
train_dataset = DogDataset(train_df, os.path.join(data_root, 'train'), transform=image_transforms['train'])
val_dataset = DogDataset(val_df, os.path.join(data_root, 'train'), transform=image_transforms['valid'])
image_dataset = {'train': train_dataset, 'valid': val_dataset}
image_dataloader = {x: DataLoader(image_dataset[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in dataset_names}
dataset_sizes = {x: len(image_dataset[x]) for x in dataset_names}
2、构建ResNet-50模型以及模型微调
残差网络是由一系列残差块组成,网络的一层通常可以看做, 而残差网络的一个残差块可以表示为
,也就是
,在单位映射中,
便是观测值,而
是预测值,所以
便对应着残差,因此叫做残差网络。残差块的示意图如下所示。

ResNet-50模型是将残差块堆叠而成,达到50层的深层神经网络。模型架构图如下所示。
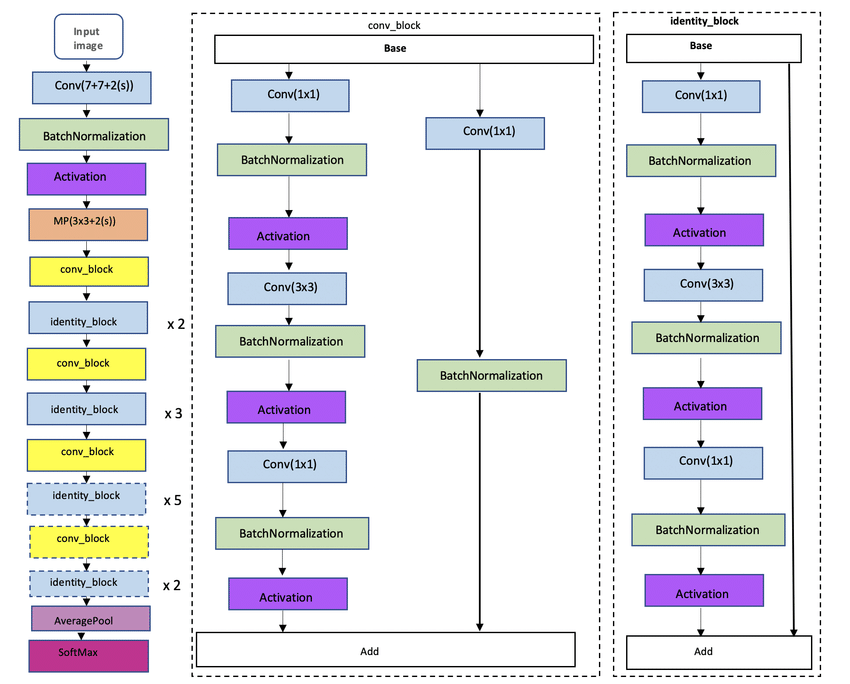
通过torchvision快速实现ResNet-50模型,由于当前模型是通过ImageNet进行训练,而ImageNet有1000个分类,本文的犬种只有120类,所以需要对模型进行重新配置。首先将模型的所有参数进行冻结,再修改模型的输出层。
model_ft = models.resnet50(pretrained=True)
for param in model_ft.parameters():
param.requires_grad = False
num_fc_ftr = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_fc_ftr, len(breeds))
model_ft = model_ft.to(device)
3、定义模型超参数以及评估方法
模型的输入图片大小、图片预处理的MEAN、STD通过以下定义,损失函数采用交叉熵误差计算,优化函数采用Adam。
IMG_SIZE = 224
IMG_MEAN = [0.485, 0.456, 0.406]
IMG_STD = [0.229, 0.224, 0.225]
LR = 0.001
EPOCHES = 20
BATCHSIZE = 256
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam([{'params': model_ft.fc.parameters()}], lr=LR)
4、参数优化
以下是通过定义的训练次数进行模型的参数优化过程,每一次训练输出模型的训练误差、测试误差、准确率。
for epoch in range(1, EPOCHES):
model.train()
for batch_idx, data in enumerate(train_loader):
x, y = data
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_hat = model(x)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
print('Train Epoch: {}\t Loss: {:.6f}'.format(epoch, loss.item()))
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for i, data in enumerate(test_loader):
x, y = data
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_hat = model(x)
test_loss += criterion(y_hat, y).item()
pred = y_hat.max(1, keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(val_dataset), 100. * correct / len(val_dataset)))
训练输出如下所示:
Train Epoch: 1 Loss: 2.652317 Test set: Average loss: 0.0080, Accuracy: 679/1023 (66%) Train Epoch: 2 Loss: 1.943187 Test set: Average loss: 0.0048, Accuracy: 765/1023 (75%) Train Epoch: 3 Loss: 1.791019 Test set: Average loss: 0.0038, Accuracy: 787/1023 (77%) Train Epoch: 4 Loss: 1.551752 Test set: Average loss: 0.0033, Accuracy: 815/1023 (80%) Train Epoch: 5 Loss: 1.534580 Test set: Average loss: 0.0030, Accuracy: 808/1023 (79%) Train Epoch: 6 Loss: 1.454419 Test set: Average loss: 0.0029, Accuracy: 803/1023 (78%) Train Epoch: 7 Loss: 1.365119 Test set: Average loss: 0.0027, Accuracy: 828/1023 (81%) Train Epoch: 8 Loss: 1.234558 Test set: Average loss: 0.0027, Accuracy: 812/1023 (79%) Train Epoch: 9 Loss: 1.290068 Test set: Average loss: 0.0026, Accuracy: 836/1023 (82%) Train Epoch: 10 Loss: 1.474308 Test set: Average loss: 0.0026, Accuracy: 826/1023 (81%) Train Epoch: 11 Loss: 1.262610 Test set: Average loss: 0.0026, Accuracy: 840/1023 (82%) Train Epoch: 12 Loss: 1.240969 Test set: Average loss: 0.0026, Accuracy: 815/1023 (80%) Train Epoch: 13 Loss: 1.098669 Test set: Average loss: 0.0025, Accuracy: 825/1023 (81%) Train Epoch: 14 Loss: 1.006308 Test set: Average loss: 0.0026, Accuracy: 822/1023 (80%) Train Epoch: 15 Loss: 1.144400 Test set: Average loss: 0.0025, Accuracy: 819/1023 (80%) Train Epoch: 16 Loss: 1.033793 Test set: Average loss: 0.0025, Accuracy: 829/1023 (81%) Train Epoch: 17 Loss: 1.105277 Test set: Average loss: 0.0024, Accuracy: 839/1023 (82%) Train Epoch: 18 Loss: 1.132692 Test set: Average loss: 0.0024, Accuracy: 833/1023 (81%) Train Epoch: 19 Loss: 1.225546 Test set: Average loss: 0.0025, Accuracy: 830/1023 (81%)
三、总结
本文通过微调ResNet-50模型,对犬种图片数据进行鉴定,分类效果达到81%~82%左右,可以进一步调整超参数、更换更深的残差网络实现更高的分类效果。通过细分预测结果,得出准确率在50%及以下的犬类品种有12中,其中miniature_poodle、appenzeller、siberian_husky在30%以下。
Accuracy of siberian_husky : 20 % Accuracy of appenzeller : 25 % Accuracy of miniature_poodle : 25 % Accuracy of toy_poodle : 37 % Accuracy of walker_hound : 42 % Accuracy of collie : 44 % Accuracy of english_foxhound : 44 % Accuracy of bouvier_des_flandres : 44 % Accuracy of bloodhound : 50 % Accuracy of irish_wolfhound : 50 % Accuracy of staffordshire_bullterrier : 50 % Accuracy of rottweiler : 50 %

 浙公网安备 33010602011771号
浙公网安备 33010602011771号