
Transformer的应用
Transformer
写在前面
本学期学习了NLP的课程,本小菜鸡结合做的课设(基于Transformer的英文文档摘要系统的设计与实现),来写一下有关于Transformer的相关内容吧,有问题之处还请各位大佬批评指正
系统的背景
抽象文本摘要是自然语言处理中最具挑战性的任务之一,涉及理解长段落、信息压缩和语言生成。训练机器学习模型以执行此操作的主要范例是序列到序列(seq2seq) 学习,其中神经网络学习将输入序列映射到输出序列。虽然这些 seq2seq 模型最初是使用递归神经网络开发的,但 Transformer编码器-解码器模型最近受到青睐,因为它们可以更有效地对摘要中遇到的长序列中存在的依赖项进行建模。
结合自监督预训练的 Transformer 模型(例如,BERT、GPT-4、 RoBERTa、XLNet、ALBERT、T5、ELECTRA) 已被证明是产生通用语言学习的强大框架,在对广泛的语言任务进行微调时可实现最先进的性能。然而,长文本摘要长度长,内容广,压缩程度高,并且通常是特殊领域文章(如arxiv论文),一直以来是一个难以处理的问题。
开发环境与工具
模型
云服务器
处理器:8 * Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
内存容量:60GB
显卡:NVIDIA GeForce RTX 3080ti
显卡内存:12GB
---------------我是分割线-----------------
操作系统:Windows 10
工具软件:PyCharm 2022.3.3(Professional Edition)、JupyterLab
开发语言:python 3.10
工具包:TensorFlow-gpu 2.13.0 + pandas +numpy + time + re + pickle
系统
处理器:Gen Intel Core i5-11400H @ 2.70Ghz
内存容量:8GB
外存容量:512GB
显卡:NVIDIA GeForce RTX 3050 Laptop GPU
显卡内存:8GB
---------------我是分割线-----------------
操作系统:Windows 10
工具软件:PyCharm 2022.3.3(Professional Edition)
开发语言:python/HTML/CSS/JavaScript
网络框架:Django
浏览器:Microsoft Edge
工具包:Django 3.2.1 + tensorflow 2.15.0 + pandas + numpy + re + pickle
Transformer语言模型的原理介绍
主要是参考了著名的《Attention is all you need》
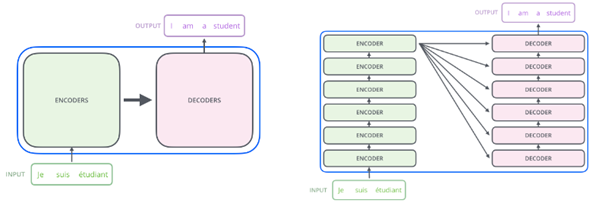
Transformer整体结构
如下图所示,Transformer由encoder和decoder两个部分组成,encoder和decoder都包含6个block。
Transformer的工作流程大概如下:
第一步:获取输入句子的每一个单词的表示向量X,X由单词的embedding(从原始数据提取的feature)和单词位置的embedding相加得到。
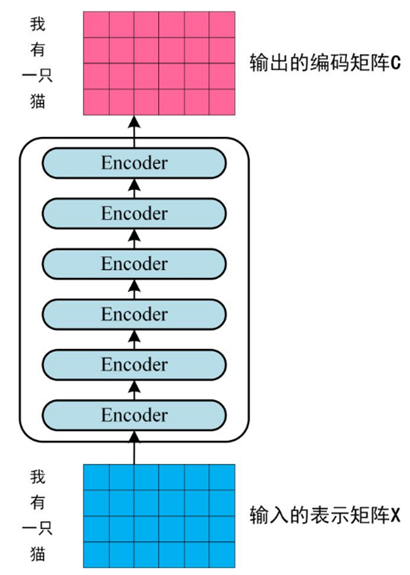
第二步:将得到的单词表示向量矩阵,传入encoder中,经过6个encoder block可以得到句子所有单词的编码信息矩阵C。单词向量矩阵用\(X_{n \times d}\)表示,n是句子中单词的个数,d表示向量的维度(论文[1]中d=512)。每一个encoder block输出的矩阵维度与输入完全一致。如下图所示:
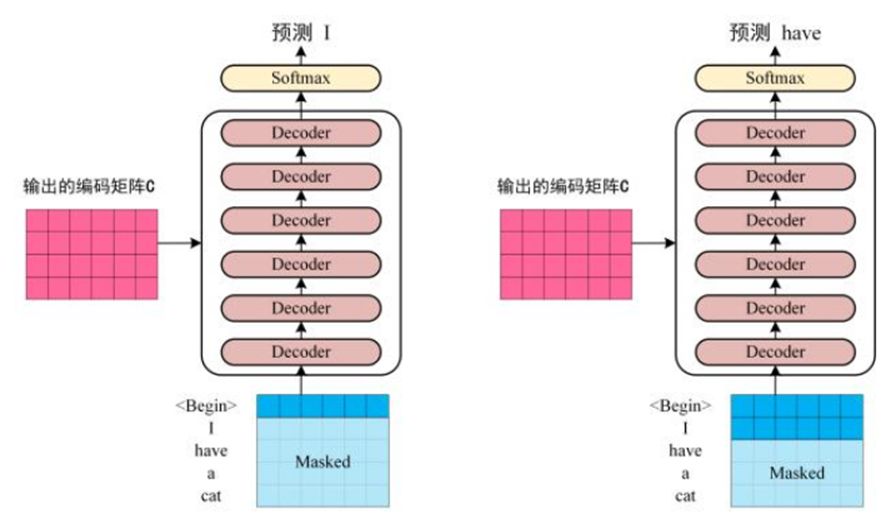
第三步:将encoder输出的编码信息矩阵C传递到decoder中,decoder依次会根据当前翻译过的单词1~i翻译下一个单词i+1,如下图3-3所示。在使用过程中,翻译到单词i+1时需要通过*Mask*操作遮盖住i+1之后的单词。
Transfomer的输入
Transformer中单词的输入表示x由单词embedding和位置embedding相加得到,由下图所示
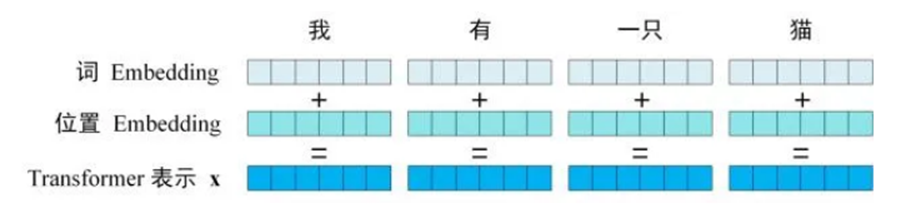
单词embedding
单词的embedding有很多方式可以获取,如word2vec、Glove等算法,也可以在Transformer中训练得到。
位置embdding
Transformer中除了单词的Embedding,还需要使用位置Embedding表示单词出现在句子中的位置。因为Transformer不采用RNN的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。所以Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
位置Embedding用PE表示,PE的维度与单词Embedding是一样的。PE可以通过训练得到,也可以使用某种公式计算得到。在Transformer中采用了后者,计算公式如下:
其中,pos表示单词在句子中的位置,d表示 PE的维度 (与词Embedding一样),2i表示偶数的维度,2i+1表示奇数维度(即 \(2i \leq d,2i+1 \leq d\))。使用这种公式计算PE有以下的好处:[2]
使PE能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有20个单词,突然来了一个长度为21的句子,则使用公式计算的方法可以计算出第21位的Embedding。
可以让模型容易地计算出相对位置,对于固定长度的间距k,PE(pos+k)可以用PE(pos)计算得到。因为\(\sin{(A+B)}=\sin{A}\cos{B}+\cos{A}\sin{B},\cos{(A+B)}=\cos{A}\cos{B}-\sin{A}\sin{B}\)。
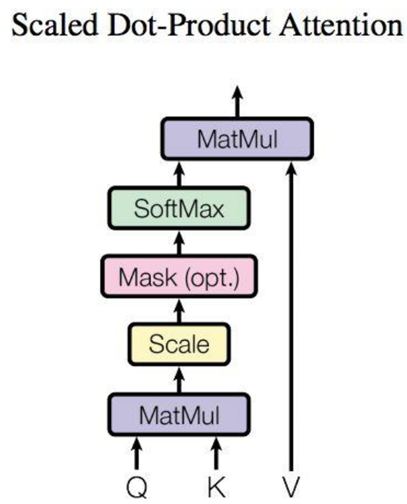
自注意力机制
如下图所示结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
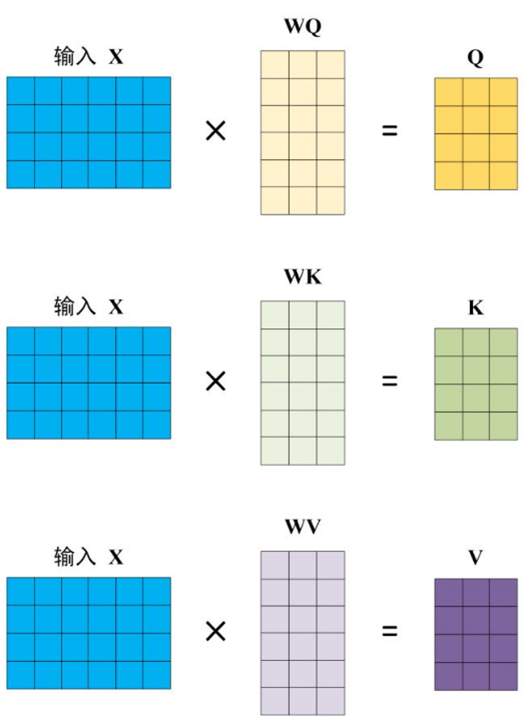
Q、K、V的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。如下图所示:
Self-Attention的输出
得到矩阵Q,K,V之后,就可以计算出Self-Attention的输出了,计算公式如下:
其中\(d_k\)是\(Q、K\)矩阵的列数,即向量维度
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以\(d_k\)的平方根。Q乘K的转置后,得到的矩阵行列数都为n,n为句子单词数,这个矩阵可以表示单词之间的attention强度。得到之\(QK^T\)后,使用Softmax计算每一个单词对于其他单词的attention系数,公式中的Softmax是对矩阵的每一行进行Softmax,即每一行的和都变为1。得到Softmax矩阵之后可以和V相乘,得到最终的输出Z。
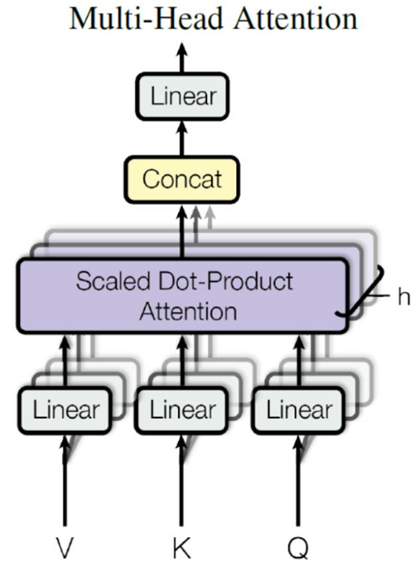
Multi-Head Attention
在上一步,我们已经知道怎么通过Self-Attention计算得到输出矩阵Z,而Multi-Head Attention是由多个Self-Attention组合形成的,下图是论文中Multi-Head Attention的结构图。可以看到Multi-Head Attention输出的矩阵Z与其输入的矩阵X的维度是一样的。
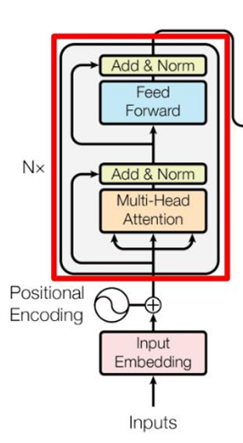
encoder结构
如下图所示,红色部分是Transformer的encoder block结构,可以看到是由Multi-Head Attention、Add & Norm、Feed Forward、Add & Norm组成的
Add&Norm
Add & Norm层由Add和Norm两部分组成,其计算公式如下:
其中X表示Multi-Head Attention或者Feed Forward的输入,MultiHeadAttention(X)和FeedForward(X)表示输出(输出与输入X维度是一样的,所以可以相加)。
Add指X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在ResNet中经常用到。

Norm指Layer Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样,可以加快收敛速度。[3][4]
Feed Forward
Feed Forward曾是一个两层的全连接层,第一层的激活函数为ReLU,第二层不用激活函数,对应公式如下:
X是输入,Feed Forward最终得到的输出矩阵的维度与X一致。
组成Encoder
通过上面描述的Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个Encoder block,Encoder block接收输入矩阵\(X_{(n\times d)}\),并输出一个矩阵\(O_{(n \times d)}\),通过多个 Encoder block 叠加就可以组成Encoder。
第一个Encoder block的输入为句子单词的表示向量矩阵,后续Encoder block的输入是前一个Encoder block的输出,最后一个Encoder block输出的矩阵就是编码信息矩阵C,这一矩阵后续会用到Decoder中。
decoder结构
Transformer的decoder block结构,与encoder block类似,存在如下区别:
包含两个Multi-Head Attention层。
第一个Multi-Head Attention层采用了Masked操作。
第二个Multi-Head Attention层的K, V矩阵使用Encoder的编码信息矩阵C进行计算,而Q使用上一个Decoder block的输出计算。
最后有一个Softmax层计算下一个翻译单词的概率。
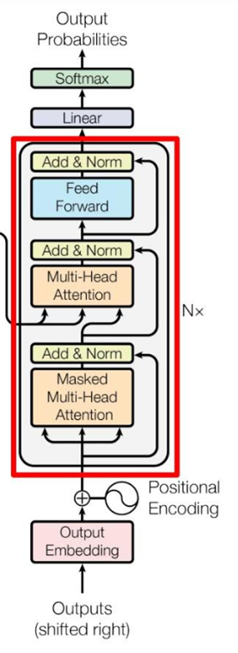
第一个Multi-Head Attention
Decoder block的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第i个单词,才可以翻译第i+1个单词。通过Masked操作可以防止第i个单词知道i+1个单词之后的信息。
第二个Multi-Head Attention
Decoder block第二个Multi-Head Attention变化不大,主要的区别在于其中Self-Attention的K, V矩阵不是使用上一个Decoder block的输出计算的,而是使用Encoder的编码信息矩阵C计算的。
根据Encoder的输出C计算得到K, V,根据上一个Decoder block的输出Z计算Q(如果是第一个Decoder block则使用输入矩阵X进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在Decoder的时候,每一位单词都可以利用到Encoder所有单词的信息(这些信息无需Mask)。
系统概要设计
总体架构设计
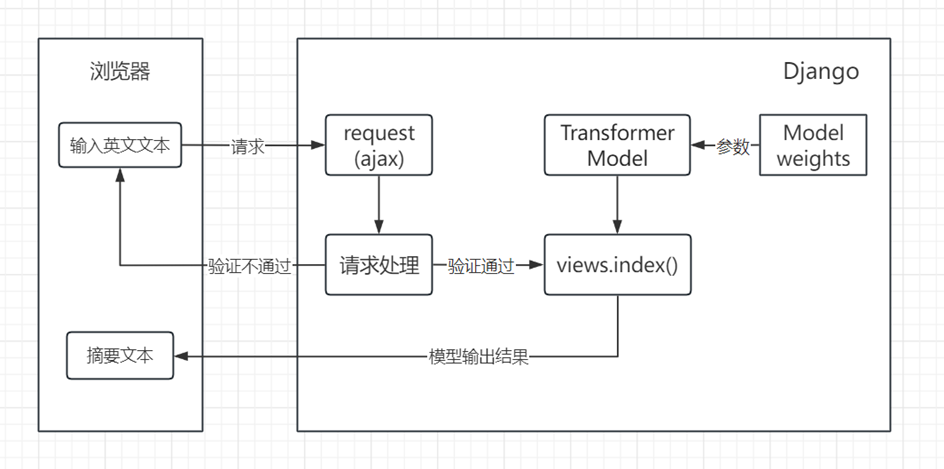
本英文文档摘要系统的设计与实现依托Web框架Django完成,用户需要在前端浏览器页面输入或上传英文文档以获取摘要语句。系统的页面请求通过Ajax方式向后台发送,验证通过后由视图函数index()初步获取请求携带的文件或文本数据。index()通过调用导入的Transformer语言模型对文本进行总结,模型使用的是训练过程中最新的参数权重。处理结束后将由index()返回Json格式的字段解析后在页面显示。系统的工作流程示意图如下
训练数据
模型训练使用的数据集主要来自Kaggle平台,为Inshorts News Data,Inshorts是一项新闻服务,提供来自网络的新闻摘要。该数据集包含新闻项目的标题、摘要及其来源。数据集以excel文件形式存储,训练时我们只使用其中的摘要部分和对应的标题,共计有55104条数据,部分内容如下:
| Headline | Short | |
|---|---|---|
| 0 | 4 ex-bank officials booked for cheating bank o... | The CBI on Saturday booked four former officia... |
| 1 | Supreme Court to go paperless in 6 months: CJI | Chief Justice JS Khehar has said the Supreme C... |
| 2 | At least 3 killed, 30 injured in blast in Sylh... | At least three people were killed, including a... |
| 3 | Why has Reliance been barred from trading in f... | Mukesh Ambani-led Reliance Industries (RIL) wa... |
| 4 | Was stopped from entering my own studio at Tim... | TV news anchor Arnab Goswami has said he was t... |
其中,第三十个数据样本展示输出结果如下,前面的部分为Short中的摘要文献内容,最后的一句话为Headline中的摘要文本对应的标题:
('According to the Guinness World Records, the most generations alive in a single family have been seven. The difference between the oldest and the youngest person in the family was about 109 years, when Augusta Bunge's great-great-great-great grandson was born on January 21, 1989. The family belonged to the United States of America.',
'The most generations alive in a single family have been 7')
自动评估指标
在模型训练的过程中,对模型的评估主要依托于损失函数提供的损失值,另外考虑通过ROUGH指标对模型进行评估。ROUGE指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分。ROUGE指标与BLEU指标非常类似,均可用来衡量生成结果和标准结果的匹配程度,不同的是ROUGE基于召回率,BLEU更看重准确率。ROUGE主要有四种评估方法,分别是Rough-N、Rough-L、Rough-W、Rough-S。
Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率。Rouge-L的计算利用了最长公共子序列,注意区分最长公共子串是连续的,而子序列不一定连续,但是二者都是有词的顺序的。Rouge-W就是所做的工作就是给连续的匹配给到更多的权重,让连续匹配的比非连续匹配的有更高的分数。对于Rouge-S,其中S表示:Skip-Bigram Co-Occurrence Statistics,这其实是Rouge-N的一种扩展表示,而N-gram是连续的,Skip-bigram是允许跳过中间的某些词,同时结合了Rouge-L的计算方式。
系统详细设计
代码部分就不在这里赘述了,后续会补充一个链接,提供访问
2024/1/24补充 https://github.com/WanYongyi/111
实验及演示
实验结果
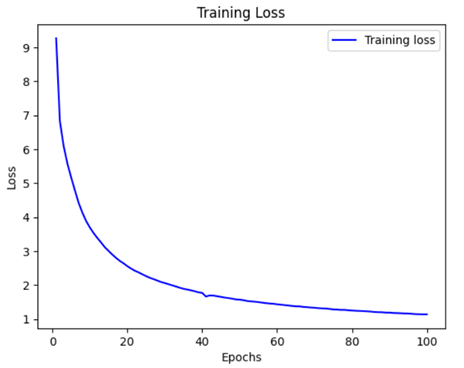
模型训练过程中加入了共计861个批次每个批次损失值和准确率的记录并取均值,通过间断的40+20+20+20共100轮的训练得到损失值和准确率的变化分别如下图6.1和图6.2所示,可以观察到前40~50轮训练损失下降较快,从近10降低至近1.5,而准确率的值从0上升至近0.10,而50轮训练后损失值和准确率的变化速度明显变慢。据统计,后50轮损失从1.5683下降至1.1354,准确率从0.0989上升至0.1103,虽然两个观测指标的数据仍为明显收敛,但可以推理出后续训练的价值不大,因此决定以100轮训练的模型权重作为本系统的语言模型。
模型训练损失率如图:
系统演示
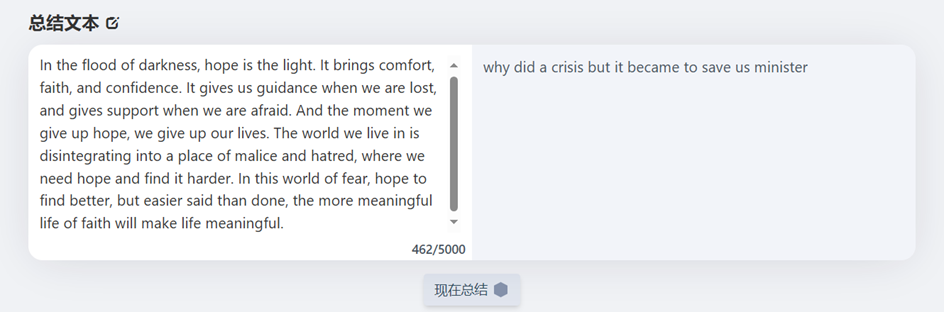
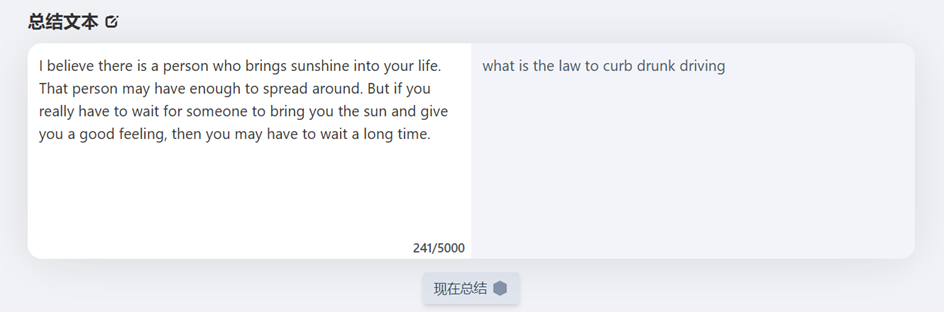
本系统基本采样前后端分离架构进行设计,前端界面美观精简的提供了用户所需的英文文档摘要总结功能,并对系统使用的模型做出了基本的介绍。系统界面如下图所示。文本交互版块位于页面正中央,左侧白底部分为原始文本输入处,右侧深色部分为摘要总结输出处。输入栏会动态的统计当前输入的字符数量,且在未进行输入前总结按钮不会显示。当文本字符数量超过5100个时点击按钮会进行相应的提示。
写在最后
基于Transformer的英文文本摘要系统是一个能够自动生成输入文档摘要的系统。它使用了Transformer模型来处理输入文本,并利用注意力机制和多层自注意力网络来捕捉文本间的关联信息,以生成准确而流畅的摘要。该系统还包括了自定义的学习率调度器、损失函数和训练步骤,以及评估和摘要生成函数。我们设计了一个简单的前端,允许用户输入一段文本,系统会自动生成文本摘要展现在前端供用户参考。我们已经使用TensorFlow API,解决了深度学习中一个相当困难的用例并取得了较好的效果。
在系统开发过程中,我们遇到了如下一些挑战:
第一,数据质量。获取高质量的训练数据对于训练Transformer模型至关重要。我们找了很久数据集,最终得到拼凑了一份超过55000行的数据集。数据集是一份关于新闻的介绍,其中有标题、简要介绍、来源、时间等属性。遗憾是时间太短,来不及仔细甄别、清理、标记其中含有劣质内容的行,无法保证其质量达到预期标准。
第二,超参数调整和模型训练时间。Transformer模型有许多超参数需要调整,如层数、隐藏单元数、注意力头数等,调整这些参数获得最佳性能是一种挑战。此外Transformer模型较为复杂,训练需要大量的计算资源和时间,我们在自己的笔记本电脑上运行的时候,部分超参数设置仅为在前文展示部分的十分之一,训练轮数也仅仅设置了一轮,但训练时长达4000秒以上。最终我们选择了租用GPU训练,超参数设置如上文所示,训练轮数也达到了40轮,这样一轮的训练时间也仅为90秒左右,损失率也大大降低,得到了较为满意的训练成果。
第三,阅读文献。在阅读论文Attention is All You Need时,我们查阅了大量的资料,发现这篇文章的地位十分的重要,因此免不了仔细深入了解,当然这篇文章本身是用于机器翻译的,与我们所做的英文文档摘要还是有一些区别,在如何使用相关模型进行我们课设的使用时,难免还需要寻找其他的资料,于是得到了这样一篇文章[6],这篇文章非常符合我们的需求,对我们的成功有至关重要的作用。在此,我想向作者表示感谢。
通过课程设计,我也学习到了很多。
第一,文本处理。在处理文本数据时,数据清洗和预处理是至关重要的。这包括处理缺失数据、去除噪声、标记化、词干提取和停用词处理等步骤,以确保数据的质量和一致性。
第二,Transformer的构建。我了解了Transformer模型的核心组件,包括自注意力机制、位置编码、前馈神经网络等。我意识到Transformer模型具有并行计算、捕获长距离依赖等优势,适用于处理NLP任务。通过实践,我了解到超参数对模型性能有显著影响,我们需要也必须通过大量调整来获取合适的超参数。
别老说没灵感,艺术家如此,科研也如此,灵感来源于你的积累,积累从哪里来,论文。动手查,动手做,多查资料,百度、论文、github……
此外,团队应该有团队的样子,在团队中,我们可以用更少的时间得到更多的收获,真正地实现1+1>2的效果。
课设的得分是96,排名第一,在此感谢我的两位队友阿伟和阿杰,还有指导老师张老师。穿越逆境,直抵繁星!希望我们能够在自然语言的海洋里游得更远!
参考文献
[1] Ashish Vaswani, Noam Shazeer. Attention Is All You Need [J]. Eprint Arxiv,2017.
[2] NLP与人工智能, Transformer模型详解 [OL], 2021-04-10.
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition [J]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
[4] Ba J L, Kiros J R, Hinton G E. Layer normalization [J/OL]. https://aexiv.org/pdf/1607.06450.pdf, 2016.
[5] 吕秀才. Transformer(一)--论文翻译:Attention Is All You Need 中文版. https://blog.csdn.net/nocml/article/details/103082600. 2023.
[6] Rohan Jagtap. Abstractive Text Summarization Using Transformers. [OL]. 2020.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号