Oracle性能优化
环境准备
1.在虚拟机linux上面安装好oracle环境。
2.启动Oracle
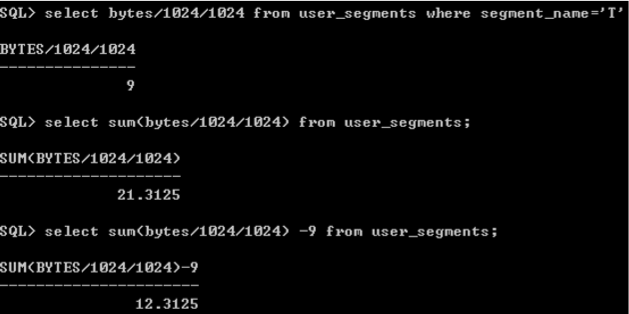
[oracle@WZH ~]$ sqlplus / as sysdba
3.开启一个实例
SQL> startup ORACLE instance started. Total System Global Area 845348864 bytes Fixed Size 1339796 bytes Variable Size 494931564 bytes Database Buffers 343932928 bytes Redo Buffers 5144576 bytes Database mounted. Database opened. SQL> select status from v$instance; STATUS ------------ OPEN
4.开启监听
[oracle@WZH ~]$ lsnrctl status LSNRCTL for Linux: Version 11.2.0.1.0 - Production on 26-FEB-2019 03:05:07 Copyright (c) 1991, 2009, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=WZH)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.1.0 - Production Start Date 26-FEB-2019 02:55:39 Uptime 0 days 0 hr. 9 min. 27 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/WZH/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=WZH)(PORT=1521))) Services Summary... Service "orcl" has 1 instance(s). Instance "orcl", status READY, has 1 handler(s) for this service... The command completed successfully [oracle@WZH ~]$
5.运程链接PL/SQL连接Oracle
导致性能问题的可能原因
1.表没有正确的索引 --错误的执行计划
2.表没有及时的分析 --错误的执行计划
3.热块 --数据块的争用
4.锁的阻塞 --业务设计的缺陷
5.sql解析消耗大量cpu --变量绑定
6.低效的sql --sql自身的问题
......
性能问题的定位
SQL层
如果能定位到SQL,就不要从会话层面分析(工具:执行计划/10053/10046...)
会话层
如果能定位到会话,就不要从系统层面分析(v$SESSION,V$SESSTAT,V$SESSION_WAIT,V$SQL,V$LOCK...)。
系统层
如果无法定位任何性能问题,从系统层面分析(AWR(STATSPACK),OS TOOLS(TOP,IOSTAT...))。
根据业务逻辑优化示例
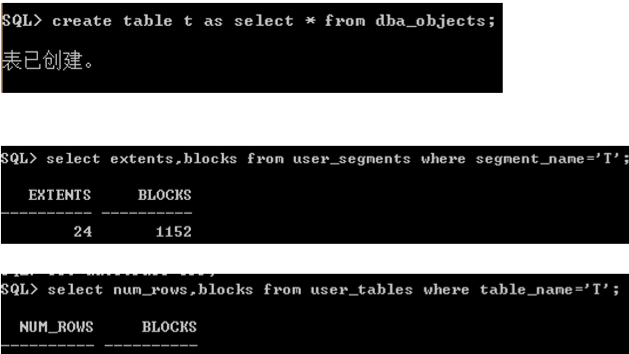
1.创建一张测试表,得到一个累加的结果

2.使用sql实现
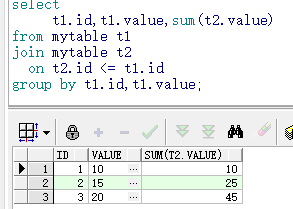
3.查看执行计划
SQL> explain plan for
2 select
3 t1.id,t1.value,sum(t2.value)
4 from mytable t1
5 join mytable t2
6 on t2.id <= t1.id
7 group by t1.id,t1.value;
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1972915077
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 80 | 9 (34)| 00:00:01 |
| 1 | HASH GROUP BY | | 1 | 80 | 9 (34)| 00:00:01 |
| 2 | MERGE JOIN | | 1 | 80 | 8 (25)| 00:00:01 |
| 3 | SORT JOIN | | 3 | 120 | 4 (25)| 00:00:01 |
| 4 | TABLE ACCESS FULL| MYTABLE | 3 | 120 | 3 (0)| 00:00:01 |
|* 5 | SORT JOIN | | 3 | 120 | 4 (25)| 00:00:01 |
| 6 | TABLE ACCESS FULL| MYTABLE | 3 | 120 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access(INTERNAL_FUNCTION("T2"."ID")<=INTERNAL_FUNCTION("T1"."ID")
)
filter(INTERNAL_FUNCTION("T2"."ID")<=INTERNAL_FUNCTION("T1"."ID")
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
)
Note
-----
- dynamic sampling used for this statement (level=2)
25 rows selected
SQL>
4.可以根据业务逻辑改写为用分析函数。
SQL> explain plan for 2 select 3 id,value,sum(value) over(order by id) 4 from mytable; Explained SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 3253109826 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 3 | 120 | 4 (25)| 00:00:01 | | 1 | WINDOW SORT | | 3 | 120 | 4 (25)| 00:00:01 | | 2 | TABLE ACCESS FULL| MYTABLE | 3 | 120 | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------ Note ----- - dynamic sampling used for this statement (level=2) 13 rows selected SQL>
锁(LOCK)
没有并发就没有锁。
示例演示
1.创建一张带主键的表
drop table t purge; create table t(id int primary key);
2.打开两个会话窗口进行测试并设置开头区别
SQL> set sqlprompt "session01>" session01>
在第一个session01提交插入语句后在session02中提交同样的语句
-- session01 session01>insert into t values(1); 1 row created. session01> -- session02 鼠标是一只停留不动 SQL> set sqlprompt "session02>" session02>insert into t values(1);
当在session01中提交后由于主键的原因报错
session01>commit; Commit complete. session01> -- session02中立即报错 insert into t values(1) * ERROR at line 1: ORA-00001: unique constraint (TEST.SYS_C003783) violated
3.上面的锁就是一个会话阻塞另外一个会话。
Oracle中锁的分类
1.Enqueues -- 队列类型的锁,通常和业务有关。
2.Latches -- 系统资源方面的锁,比如内存结构,SQL解析。
锁的原则
1.只有被修改时,行才会被锁定
2.当一条语句修改了一条记录,只有这条记录上被锁定,在Oracle数据库中不存在锁升级。
3.当某行被修改时,它将阻塞别人对它的修改。
4.当一个事务修改一行时,将在这个行上加上行锁(TX),用于阻止其它事务对相同行的修改。
5.读永远不会阻止写。
6.读不会阻塞写,唯一的例外,就是select ... for update。
7.写永远不会阻塞读。
8.当一行被修改后,Oracle通过回滚段提供给数据的一致性读。
TM锁和TX锁
1.TM表锁,发生在insert update delete 以及select for update操作时,目的是保证操作正常进行,并阻止其它对表执行DDL操作。
2.TX锁 事务锁(行锁)对于正在修改的数据,阻止其它会话进行修改。
3.示例
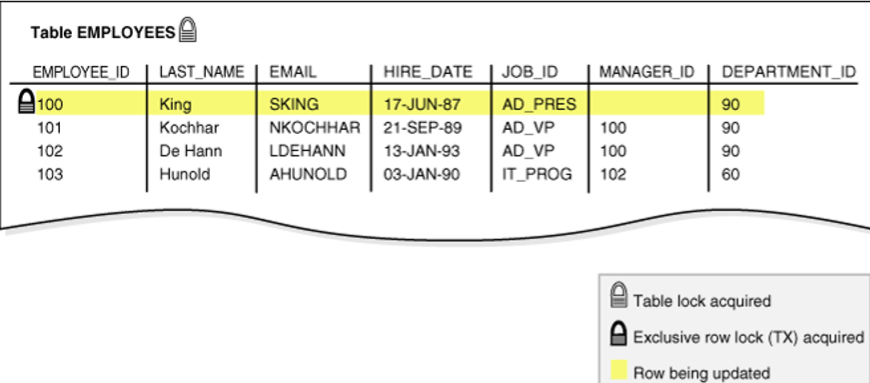
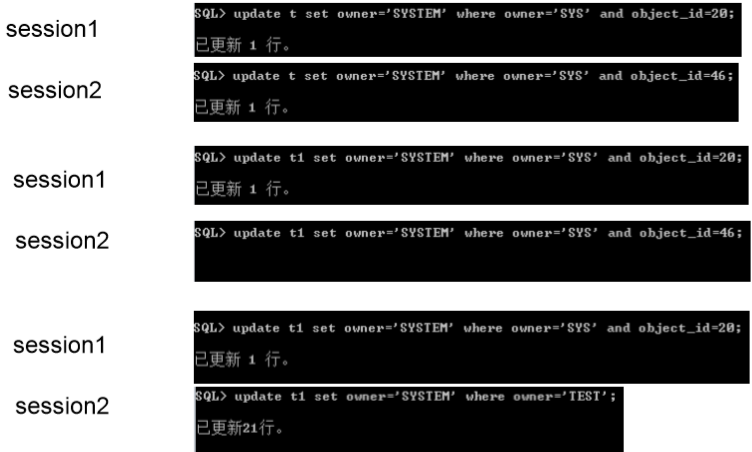
update的阻塞
1.会话1中修改一条记录不提交
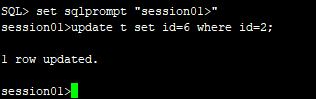
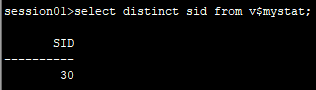
2.会话2中修改相同行的记录


3.会话3查看
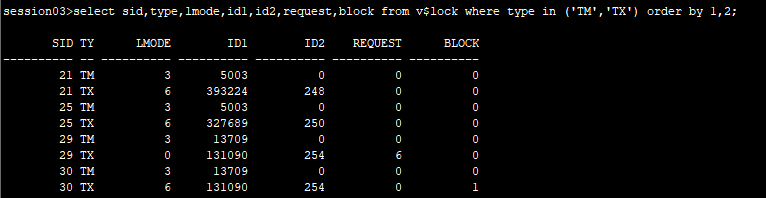

ps:select ... for update的阻塞,在表上加上了表锁和事务锁。
死锁
相互持有对方资源等待对方的释放。
1.会话1中修改一条记录
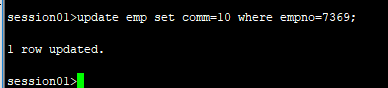
2.会话2中修改一条记录后并修改会话1中修改未提交的记录,此时出现等待。

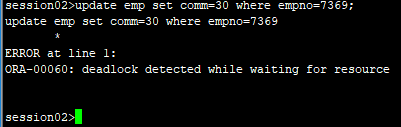
3.在会话1中修改会话2中修改未提交的记录。

4.此时会话2中会报死锁错误
TM锁的几种模式

手工锁定
lock table dept in share mode; -- 其它会话等待 update emp set sal = sal * 1.1 where deptno in ( select deptno from dept where loc = 'loc' ); update budget set totsal = totsal * 1.1 where deptno in ( select deptno from dept where loc = 'loc' ); commit; -- 释放锁
RI锁
当对具有主外键关系的表做DML操作时,锁定不单单发生在操作表上,相应的引用表 上也可能加上相应的锁定。
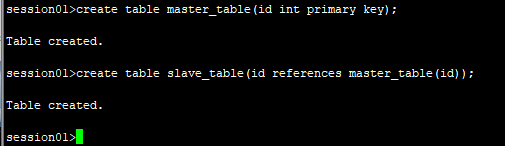
1.创建主从表
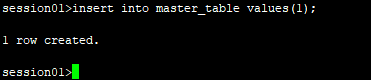
2.在主表中插入数据
3.在从表上会加上TM锁

latch
latch目的
1.保证资源的串行访问
--保护SGA的资源访问
--保护内存的分配
2.保证执行的串行化
--保护关键资源的串行执行
--保存内存结构损坏
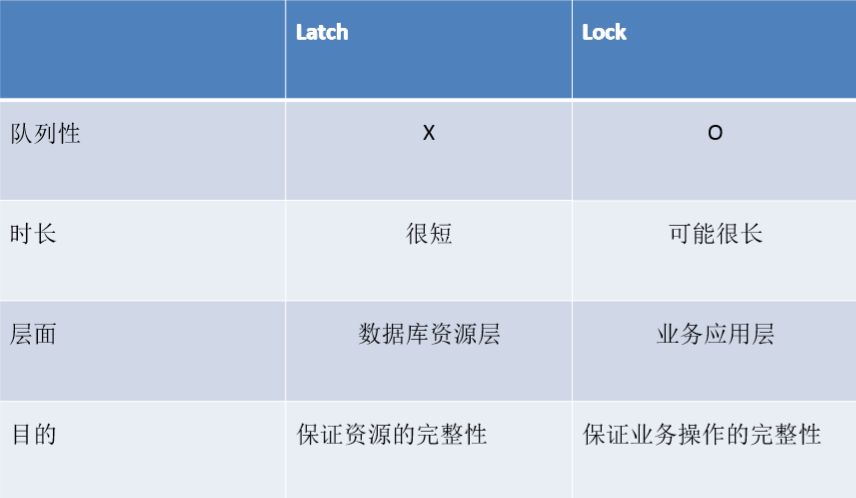
latch VS enqueue
Latch在SGA中
1.共享池(sql解析,sql重用)。
2.数据缓冲池(数据访问,数据写入磁盘,数据写入内存/修改数据块/数据段扩展)。
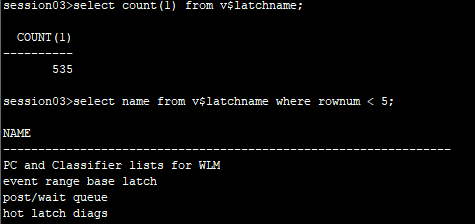
Oracle中Latch
Latch的机制
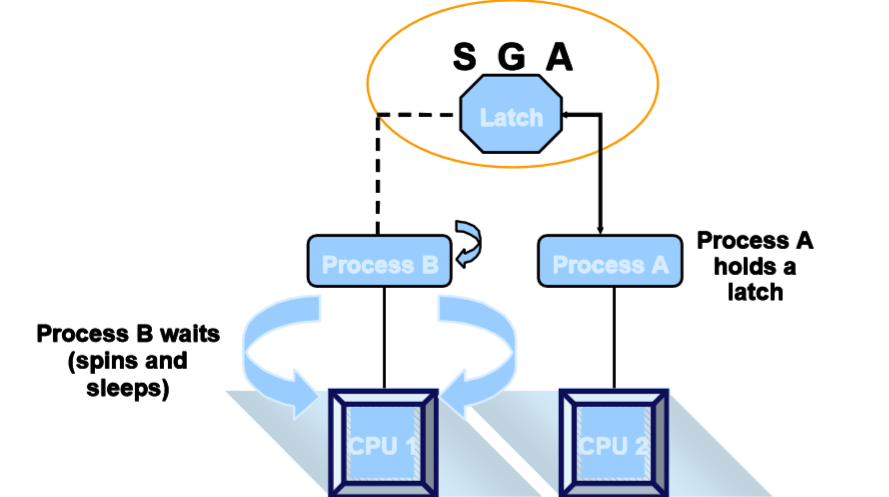
Latch的获取
1.wait方式:如果无法获取请求的Latch
-- spin 当无法获取latch时,会继续使用CPU,达到一个间隔后,再次申请直到达到最大次数。
-- sleep 等待一段时间,达到一个间隔后,再次尝试申请,达到最大重试次数。
2.No wait方式:如果无法获取请求的latch
-- 不会发生sleep或者spin
-- 转而去获取其它可用的Latch
Shared pool里latch争用-绑定变量
declare
l_cnt number;
begin
for i in 1..10000 loop
execute immediate 'select count(*) from t where x ='||i into l_cnt;
end loop;
end;
/
declare
l_cnt number;
begin
for i in 1..10000 loop
select count(*) into l_cnt from t where x = i;
end loop;
end;
比较绑定变量和没有绑定变量的区别。
Buffer cache的机制

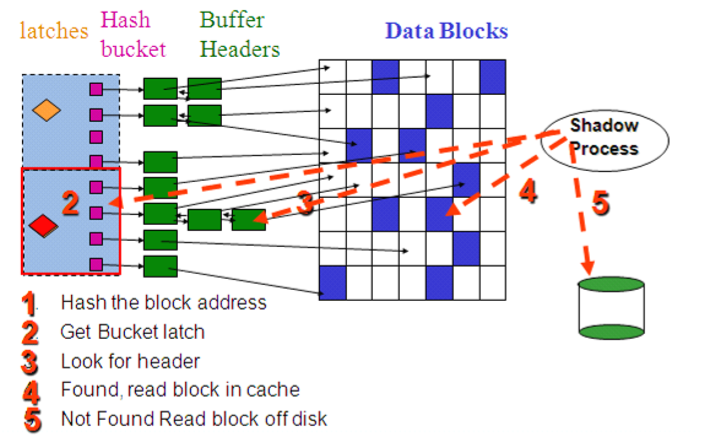
Latch相关的视图
V$LATCH
select name,gets,misses,sleeps,immediate_gets,immediate_misses from v$latch where name like 'cache%';
� NAME:latch名称
� GETS:以Willing to wait请求模式latch的请求成功数
� MISSES:初次尝试请求不成功次数
� SLEEPS:成功获取前sleeping次数
� IMMEDIATE_GETS:以Immediate模式latch请求数
� IMMEDIATE_MISSES:以Immediate模式l请求失败数
V$LATCHHOLDER
� 包含了当前latch持有者的信息。
� 通过视图中的PID和SID信息,关联视图v$SESSION,V$SESSION_WAIT,可以定位相 应持有资源的会话信息
V$LATCH_CHILDREN
� 存储子latch信息的视图,在SGA中有些资源使用多个latch保护,比如library cache, 这些多个latch保护同一个资源,成为子latch.
� V$LATCH_CHILDREN和V$LATCH一样
执行计划
SQL语句访问和处理数据的方式
数据的访问
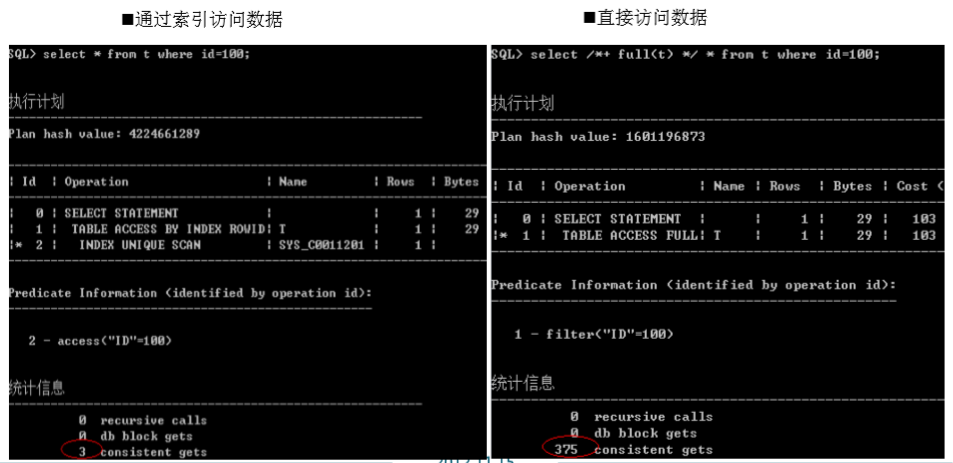
1.直接表的访问
- 并行
- 多数据块
2.通过索引访问
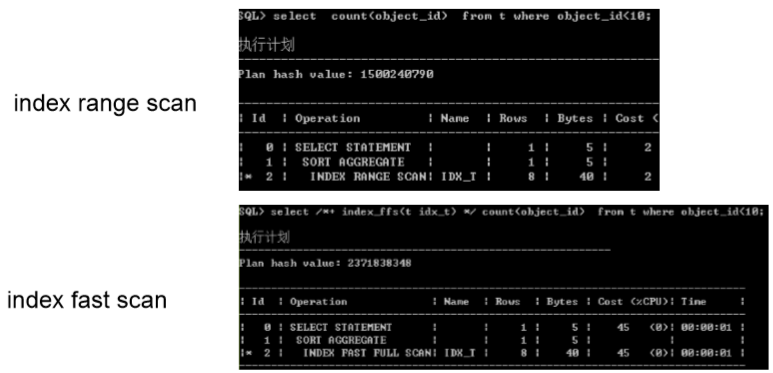
- index unique scan
- index range scan
- index full scan
- index fast full scan
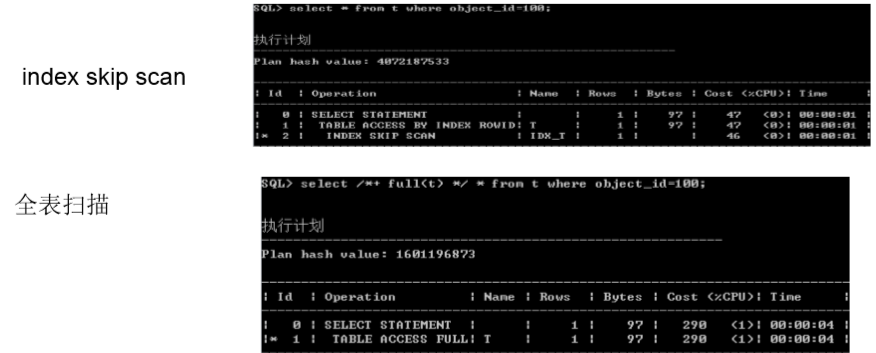
- index skip scan
数据的处理
- order by
- group by
- count
- avg
- sum
......
数据的关联处理
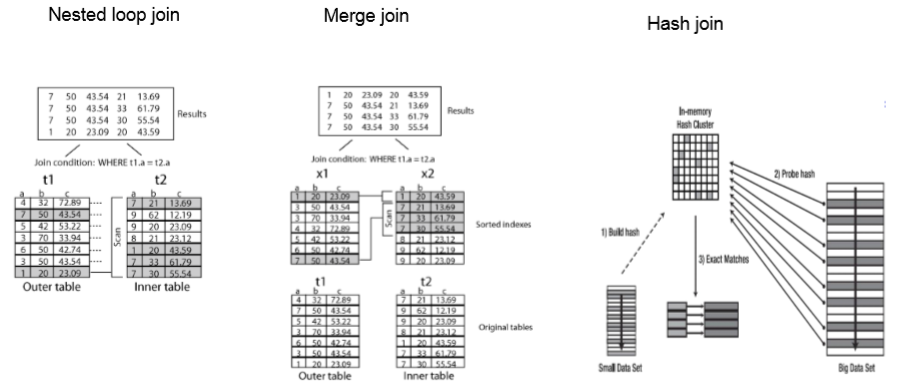
1.Nested loop join 嵌套循环(索引)
2.Merge join 先排序
3.Hash join 哈希算法(通常一个大表和一个小表)
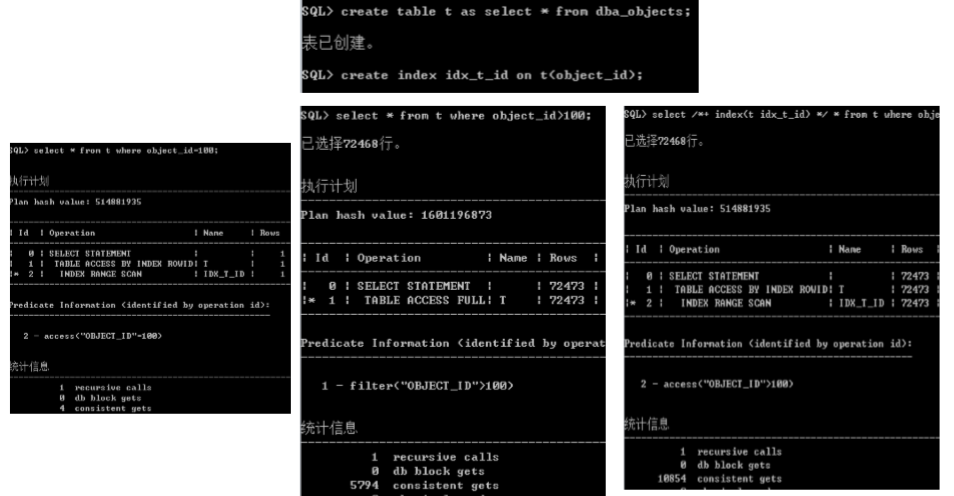
数据访问
1.通过表访问数据
SQL> explain plan for select * from emp; Explained SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 3956160932 -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 13 | 1144 | 3 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL| EMP | 13 | 1144 | 3 (0)| 00:00:01 | -------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement (level=2) 12 rows selected SQL>
2.索引唯一扫描
SQL> explain plan for select * from t where id = 2;
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1107090163
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 1 (0)| 00:00:01
|* 1 | INDEX UNIQUE SCAN| SYS_C003783 | 1 | 13 | 1 (0)| 00:00:01
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID"=2)
13 rows selected
SQL>
3.索引范围扫描
SQL> explain plan for select * from t where id > 5;
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 207962788
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| SYS_C003783 | 1 | 13 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ID">5)
Note
-----
- dynamic sampling used for this statement (level=2)
17 rows selected
SQL>
4.索引快速扫描
SQL> explain plan for select count(*) from t; Explained SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 773134027 ----------------------------------------------------------------------------- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ----------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | INDEX FAST FULL SCAN| SYS_C003783 | 4 | 2 (0)| 00:00:01 | ----------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement (level=2) 13 rows selected SQL>
5.整个索引的扫描
SQL> explain plan for select id from t order by id; Explained SQL> select * from table(dbms_xplan.display); PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 1428161888 -------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 4 | 52 | 2 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | SYS_C003783 | 4 | 52 | 2 (0)| 00:00:01 | -------------------------------------------------------------------------------- Note ----- - dynamic sampling used for this statement (level=2) 12 rows selected SQL>
数据处理
1.Hash join (小表哈希到内存中进行关联)
SQL> explain plan for
2 select t.*,t2.* from t,t2 where t.id = t2.id;
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 106979157
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 260 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 5 | 260 | 7 (15)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T | 5 | 130 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 5 | 130 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T"."ID"="T2"."ID")
Note
-----
- dynamic sampling used for this statement (level=2)
19 rows selected
2.Nested loops(从一张表拿数据一条条去匹配)
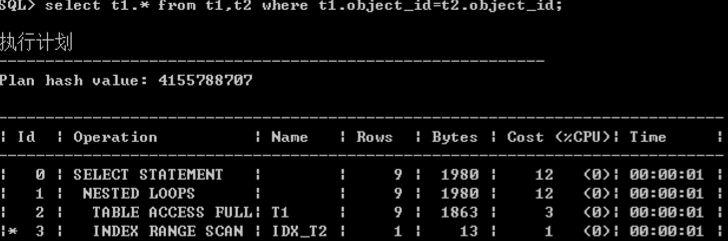
3.Merge join
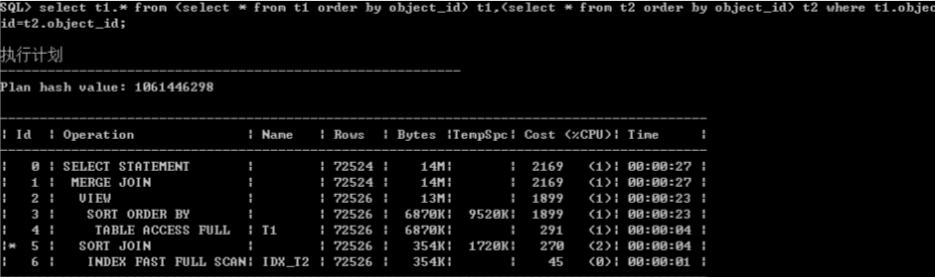
4.并行(PX)
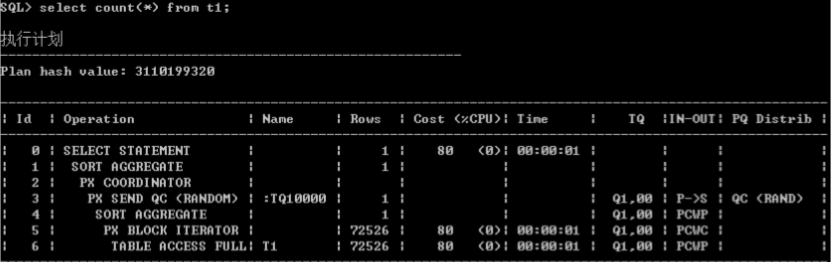
Oracle的优化器
� RBO(8i之前)---Rule based optimizer – 一套死板的规则来控制数据的访问。
� CBO(8i之后)---Cost based optimizer – 依据一套数据模型,计算数据访问和处理的成本,择最优成本为执行方案
CBO工作原理
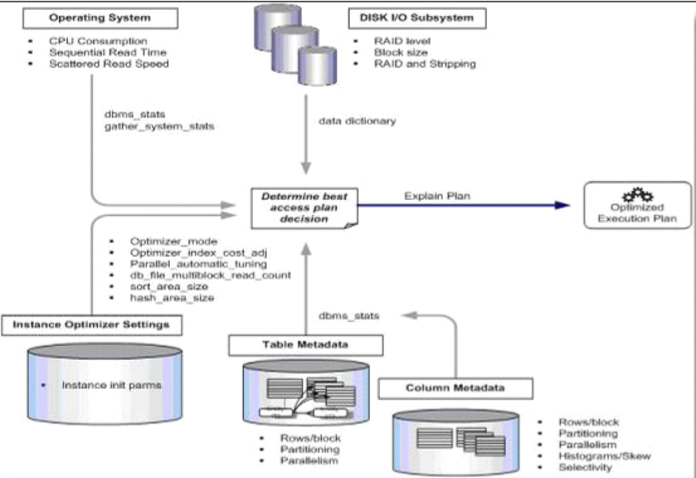
CBO工作模式
� all_rows--- 以结果集的全部处理完毕为目的。
– select id,count(*) from t group by id,order by id.
� first_rows(n)--- 以最快返回n行为目的
– SELECT OBJECT_NAME FROM ( SELECT ROWNUM RN, OBJECT_NAME FROM ( SELECT OBJECT_NAME FROM T ORDER BY OBJECT_NAME ) WHERE ROWNUM <= 20 ) WHERE RN >= 11;
设置方式
1.参数设置
optimizer_mode
2.会话设置
alter session set optimizer_mode=all_rows;
3.SQL设置
select /*+ all_rows */ count(*) from t;
COST--代价
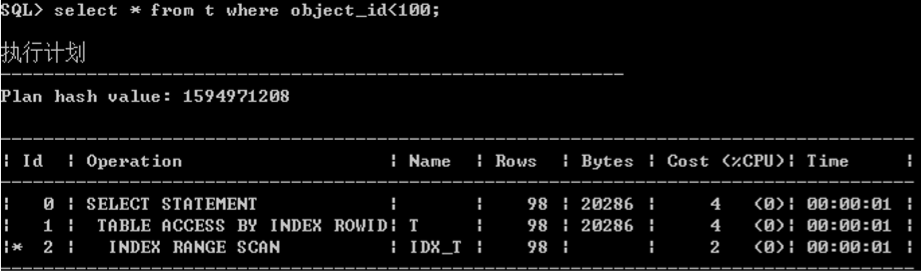
rows为估算出来的数。
重要概念selectivity
表的选择性
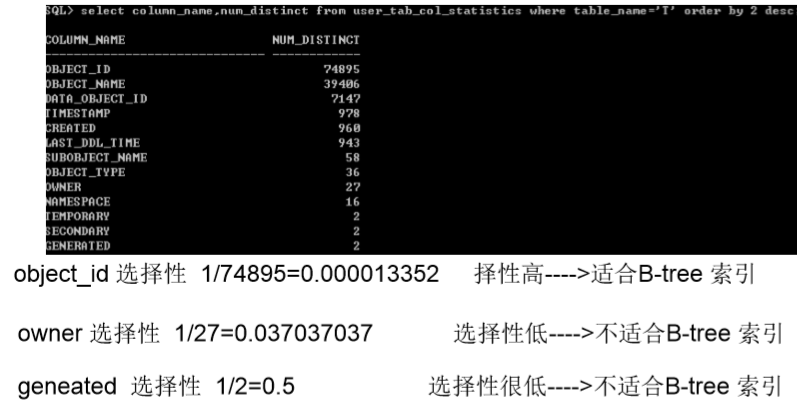
索引的选择性

cardinality
�在执行计划中表示每一步操作返回的记录数。
�CBO通过对这个值的权重计算,决定使用哪一种方式访问数据
cardinality VS selectivity
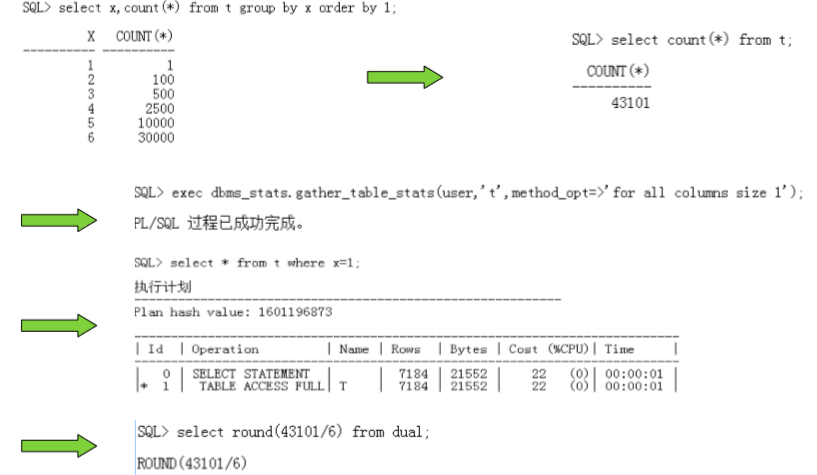
- for all columnus size 1 不做直方图的统计
- 有6个值,就是用1/6*整个数据量(计算cardinality)
clustering factor
- 集群因子,会影响索引的选择
- 影响索引成本的评估和计算,索引扫描数据时数据块出现跳转集群因子加1

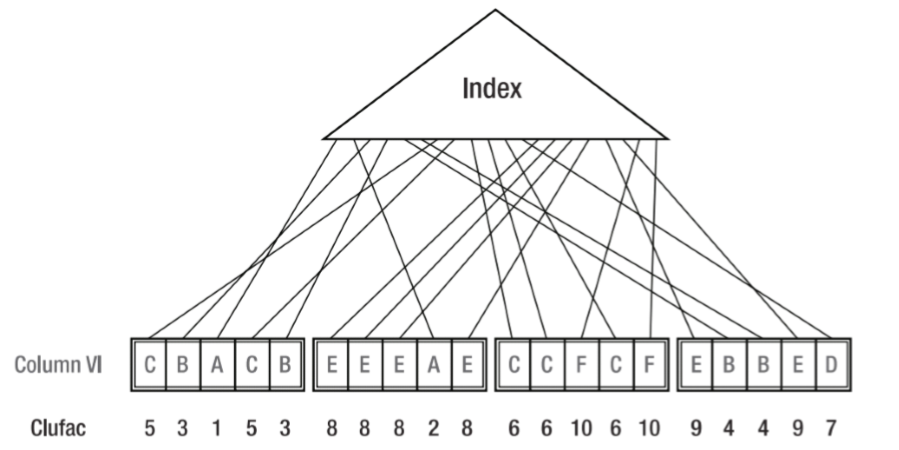
CBO核心-成本计算
� 数据访问的成本的估算
– I/O成本的估算 • 全表扫描(多数据块) • 索引(单数据块,多数据块)
– CPU成本的估算
� 数据处理的成本
– CPU的成本的估算
SQL语句成本估算
基于索引成本估算

直方图
其它因素
� CPU
� multi_blocks 多数据块读
� 并行
� 相关的参数设置
Hints
Hints是用来约束型优化器行为的一种技术
– 优化器模式
• all_rows
• first_rows
– 数据访问路径
• 基于表的数据访问
• 基于索引的数据访问
– 表关联的方式
• NL
• MJ
• HJ
Hints的使用范畴
� 尽量避免在开发中使用
� 辅助DBA用来做性能排查和优化
Oracle Hints

访问路径相关的Hints
/* full */ 全表扫描
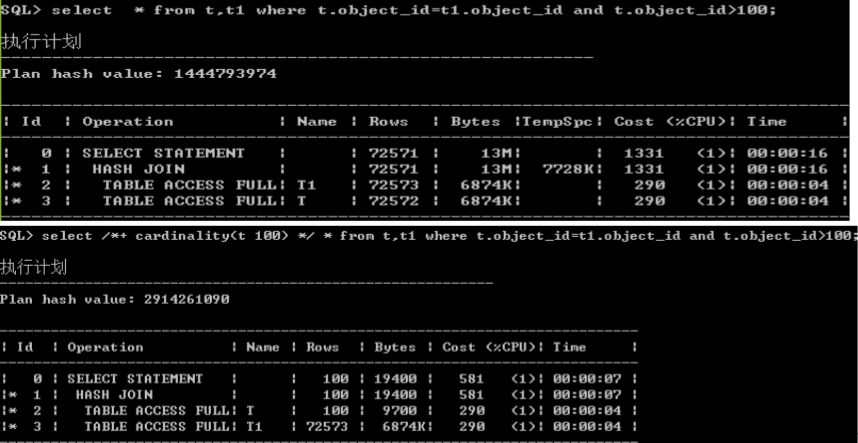
SQL> explain plan for
2 select /* full(t) */ * from t where id < 8;
Explained
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 78 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T | 3 | 78 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"<8)
Note
-----
- dynamic sampling used for this statement (level=2)
17 rows selected
INDEX 和 NO_INDEX
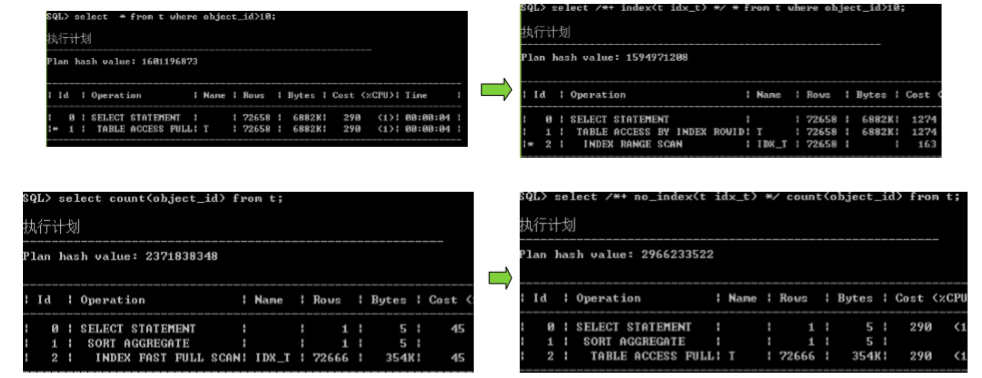
INDEX_FFS
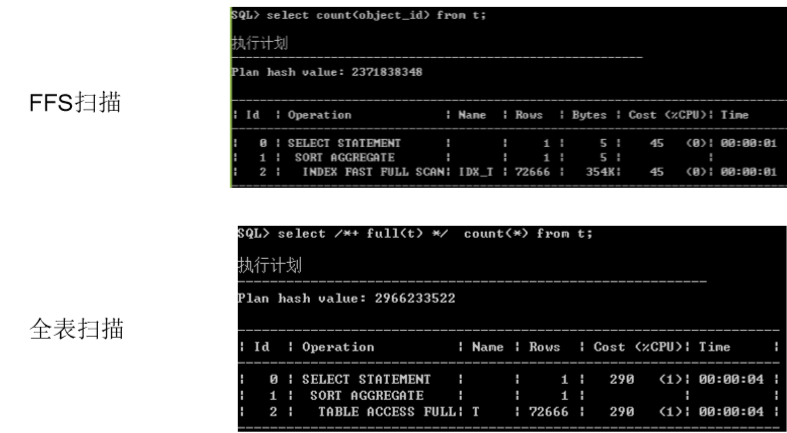
/*+ index_ss */ index skip scan
– 用于替代全表扫描的一种数据访问方法。
– 对于前导重复率高的联合索引,有时候index skip scan的性能要好一些。

表关联的Hints
/*+ use_nl */ Nested Loop Joins

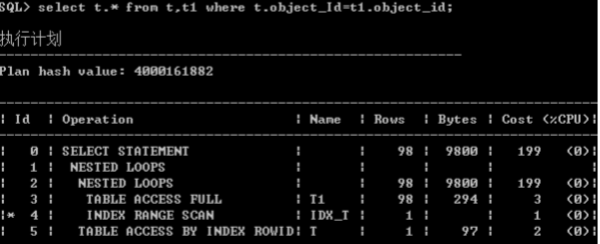
� NL的场景
– 关联中有一个表比较小
– 被关联表的关联字段上有索引
– 索引的键值不应该重复率很高
/*+ use_hash */ hash join
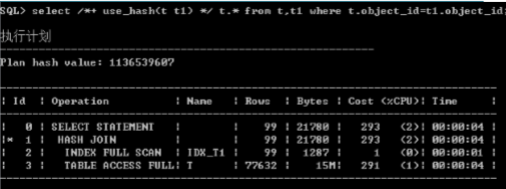
� Hash join 的原理
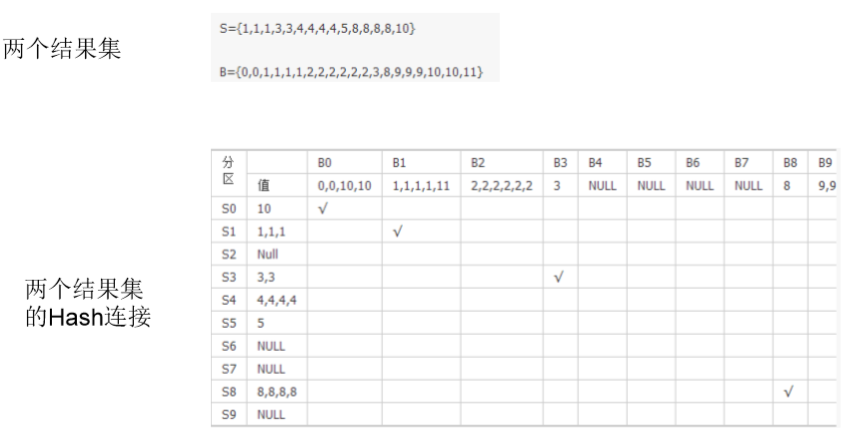
� Hash join的应用场景
– 一个大表,一个小表的关联(小表刷到内存,磁盘,临时表空间)
– 表上没有索引
– 返回结果集比较大

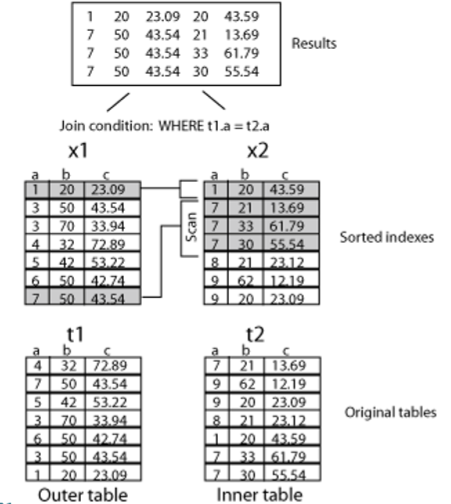
/*+ use_merge */
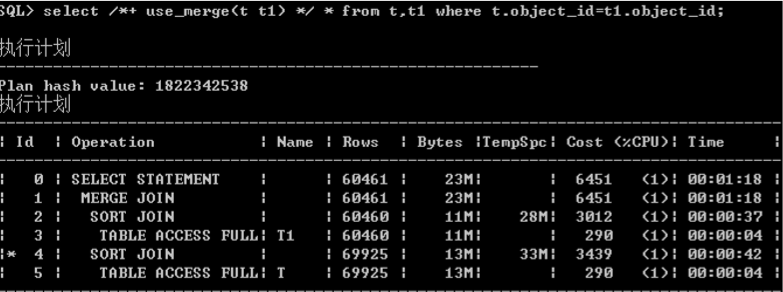
应用场景
�将两个结果集分别排序
�对排序后的结果集进行连接

/*+ leading() */ 规定表连接顺序
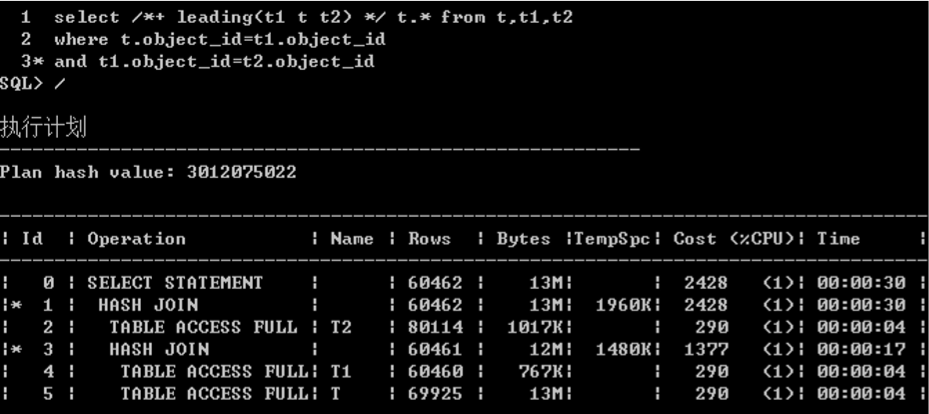
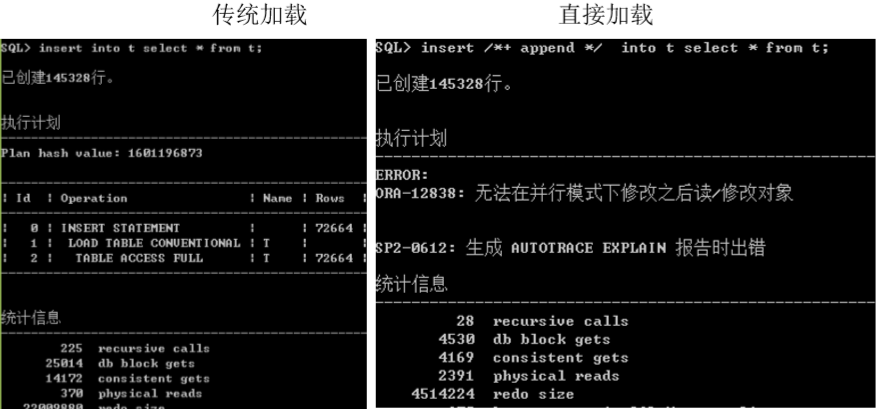
/*+ append */
– 以直接加载的方式插入数据
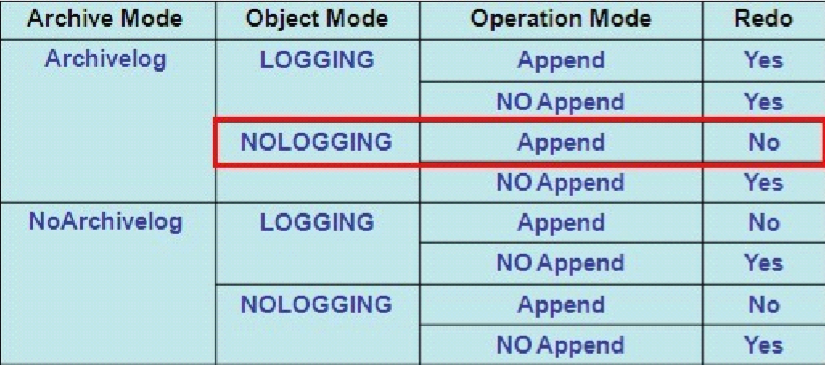
- 传统加载会在高水位以下找空的块插入数据,直接加载跳过高水位加载,将高水位向上移。
- 当数据库是归档表属性为loging,产生redo日志,表属性设置为nologing,不产生redo日志。

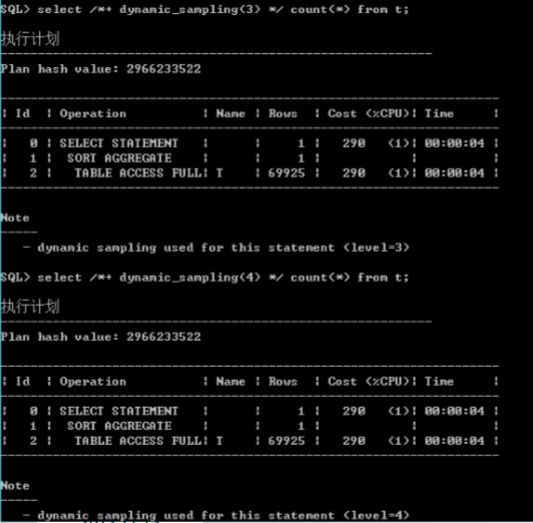
/*+ dynamic sampling */
– 设置动态采样的级别
/*+ parallel */
– 指定并行度
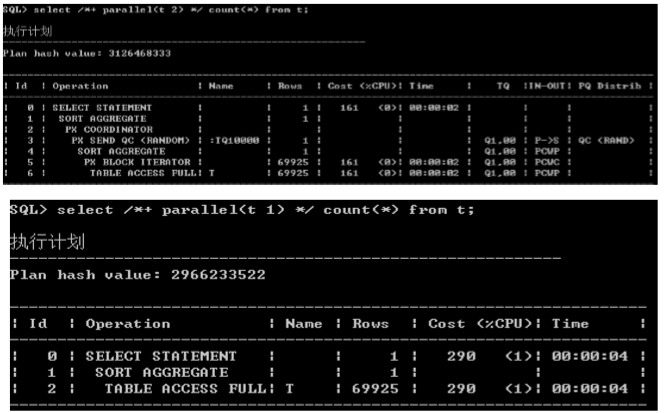
/* driving_site() */
– 决定一个分布式事物中,操作在哪个节点上完成。

� 如果没有hint,远程表(departments)上的数据将被传到本地来做关联。
� 使用hint,本地的数据将传到远程节点上执行,最后将结果返回本地
/*+ cardingality() */
– 模拟一个结果集的cardinality
等待事件
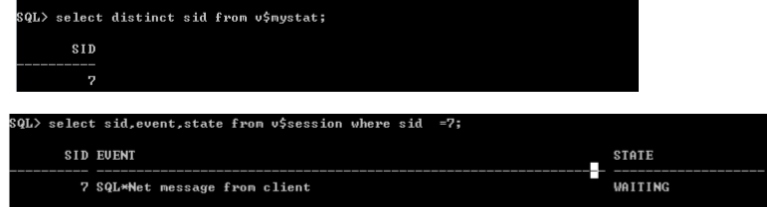
示例简单的等待事件
� SQL*Net message from client
- Oracle的一个通信协议
- 等待客户端发送指令
造成等待情况
� 请求的资源太忙,需要等待资源释放
� 会话处于空闲状态,等待新的任务
� 会话被阻塞,需要等待阻塞解除
关于等待事件
� 数据库处理数据,只要有时间的消耗,就会有等待事件。
� 性能和等待是一个矛盾体。
� 理解出现某种等待事件的原因。
� 结合业务,主观的看待等待事件。
– 制定基线(baseline),发现异常等待事件。
– 接受合理的等待事件
定位方式--SQL级别
� 10046 event

定位方式--会话级别
� 如果某个会话非常慢

定位方式--系统级别
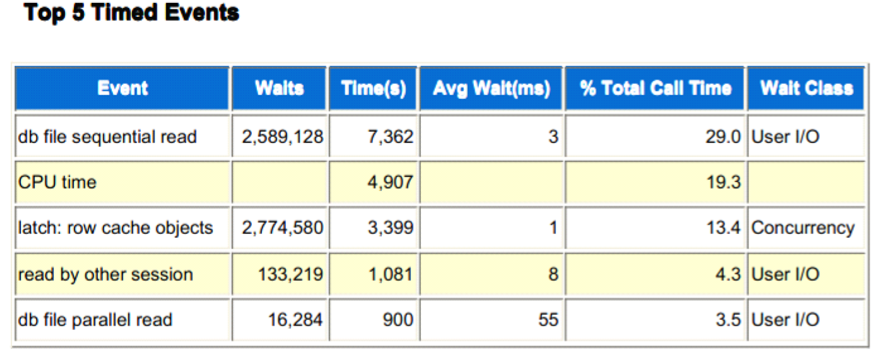
�AWR报告(v$system_event)
等待事件分类
� Classes of Wait Events

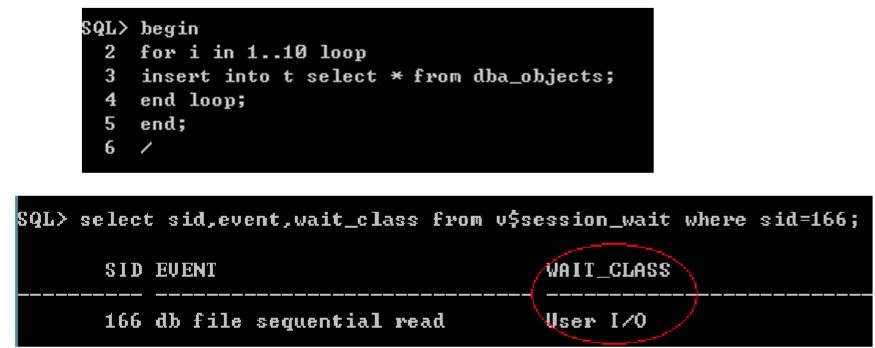
查看等待事件
EVENT(P1+P2+P3)
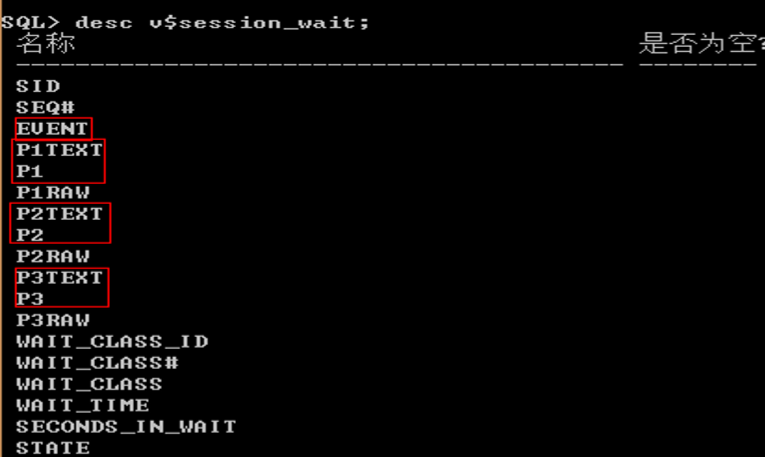
�对于不同的event,p1,p2,p3的含义各不相同

常见等待事件--ilde wait events
� 进程由于无事可做,等待分派任务。
� 空等待意味着空闲.
� 空闲,还意味着其它的事情... ...

常见的等待事件--CPU
� CPU不属于等待事件
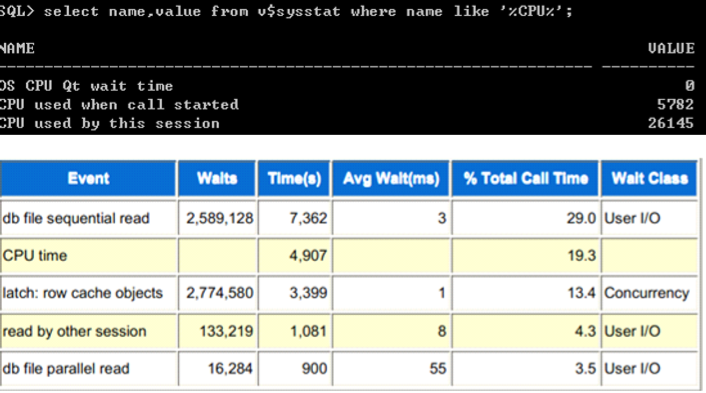
常见的等待事件--db file scattered read
� 当数据块以multiblock read的行式被
读取到SGA中时。
– FTS(full table scan)
– IFFS(index fast full scan)
– db_file_multiblock_read_count
常见的等待事件--DB File Sequential Read
� 当把一个数据块读入SGA时,发生db file sequential等待。
� 单数据块的读,通常指索引的读取,但 不绝对。
– 有些索引读取会发生'db file scattered read' 等待。
– 有时候表的读取会发生db file sequential 等待。
– undo的读取,会使用DB File Sequential.
� 如何解决?
– 无需解决
– SQL语句的效率
– 考虑其它方式的索引 • 符合索引 • 位图索引 • 全文索引
– 全表扫描+并行
– 改善磁盘I/O
常见的等待事件--Direct Path Read
� 数据被直接读取到PGA内存中时,发生的等待。
– 排序数据由于内存不足,被写到磁盘上(temp表空间数据文件) ,然后重新读取时。
– 并行操作的slave进程的数据读取。 – 其它的属于某个会话私有数据的读取操作。
� 参数说明
– P1,读取的文件ID。
– P2,读取开始的数据块ID
– P3,读取的数据块数量。
� 如何解决?
– 无需解决。
– 增大内存排序区(PGA)
– 调整操作的并行度。
– 改善磁盘I/O
常见的等待事件--Direct Path write
� 数据从PGA内存中直接写到磁盘上,发生的等待。
– 排序数据由于内存不足,被写到磁盘上(temp表空间数据文件)
– 并行操作的slave进程向磁盘上写数据。
– 其它的属于某个会话私有数据的读取操作。
� 参数说明
– P1,读取的文件ID。
– P2,读取开始的数据块ID
– P3,读取的数据块数量。
常见的等待事件--Log File Sync
� 用户commit(rollback)时,lgwr需要将log buffer的数据写到log file上面,发生的等 待。
� 参数说明
– P1,写入文件的数据块数
– P2 无
– P3 无
� 解决方式
– 减少commit的频率(错误的频繁提交)。
– 提高I/O性能。
常见的等待事件--buffer busy waits
� 内存中对相同的数据块有多个并发请求时,导致这个等待。
� 参数说明
– P1,读取数据块所在的文件ID
– P2 读取的数据块ID
– P3 等待类型(class id)
� 如何处理?
– 热块
• segment header--ASSM
• data block --ASSM,反向索引。
• undo header-- automatic undo management
• undo block ---增大回滚段
常见的等待事件-- free buffer waits
� server process无法找一个可用的内存空间。
– 系统I/O成为瓶颈(或者性能不够)
– 等待资源 latch争用
– SGA太小
– SGA太大,dbwr无法快速的把脏数据刷到磁盘上
� 参数说明
– P1,读取数据块所在的文件ID
– P2 读取的数据块ID
– P3 无
� 优化I/O
– 提高I/O通道的性能。
– 异步I/O
– 增加多个dbwr 进程。
� 增大SGA
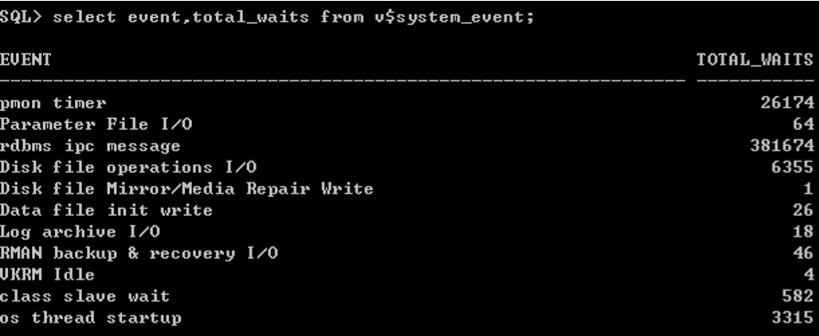
相关的视图
v$session_event

v$system_event
索引
索引的目的
� 提高数据访问的效率
分析:访问根一次I/O 健值I/O rowid I/O
索引类型
�B-tree索引 B树索引 (二叉树)
�Bitmap索引 位图索引
�TEXT index 全文索引
B-tree 索引
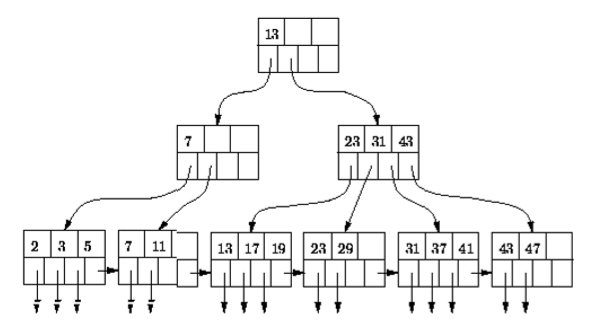
� 高效的场景 – 索引字段有着很高的selectivity或者结果集很小的时候
� 低效的场景 – 索引字段有着很低的selectivity或者结果集很大的时候。
� 基本上适用于所有类型的数据库。
� 没有太明显的缺点。
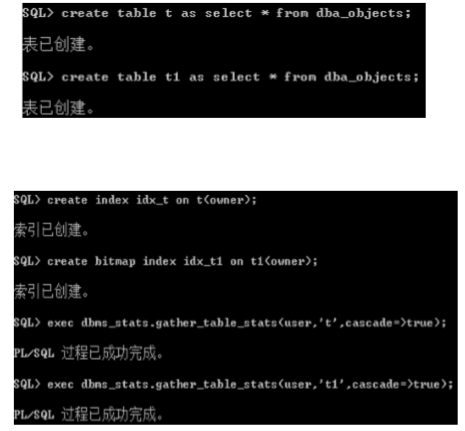
位图(bitmap)索引
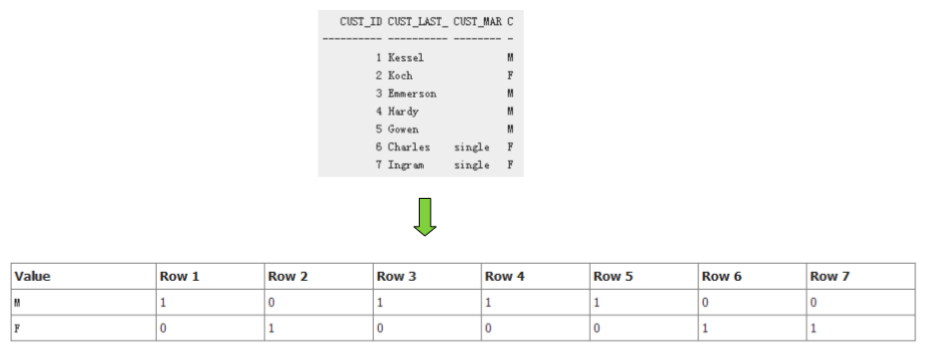
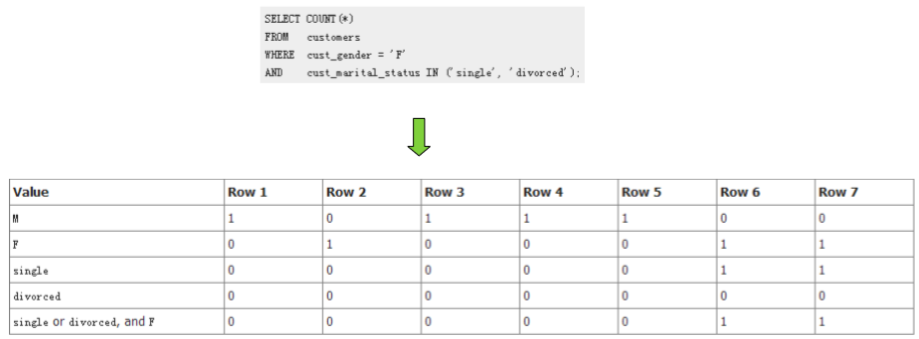
� 使用场景
– OLAP
– 重复率很高的键值
� 不适用的场景
– OLTP
– DML频繁操作。
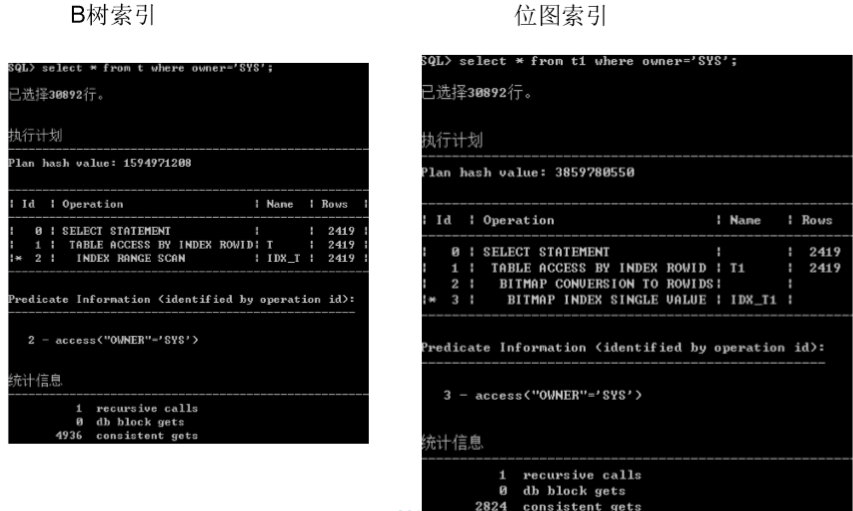
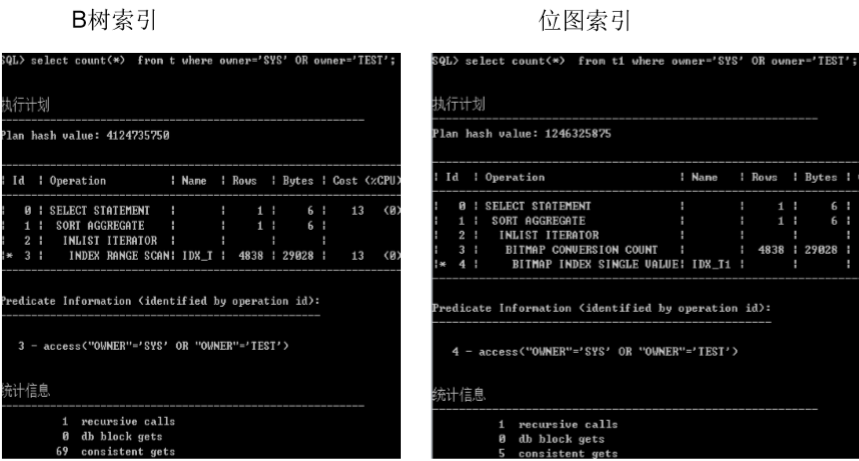
� 位图索引的锁定

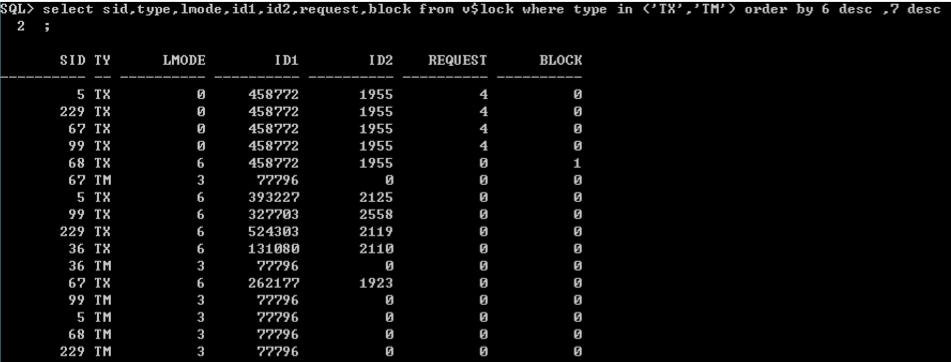
全文索引

全文索引是如何存储数据
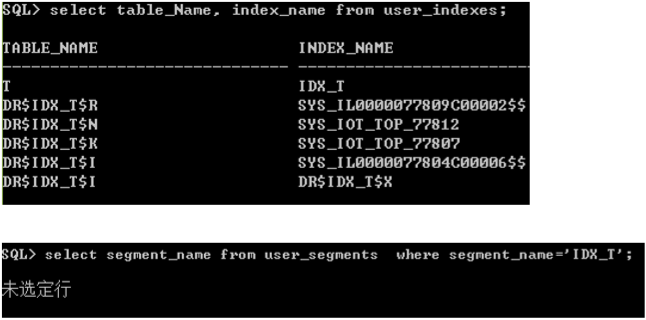
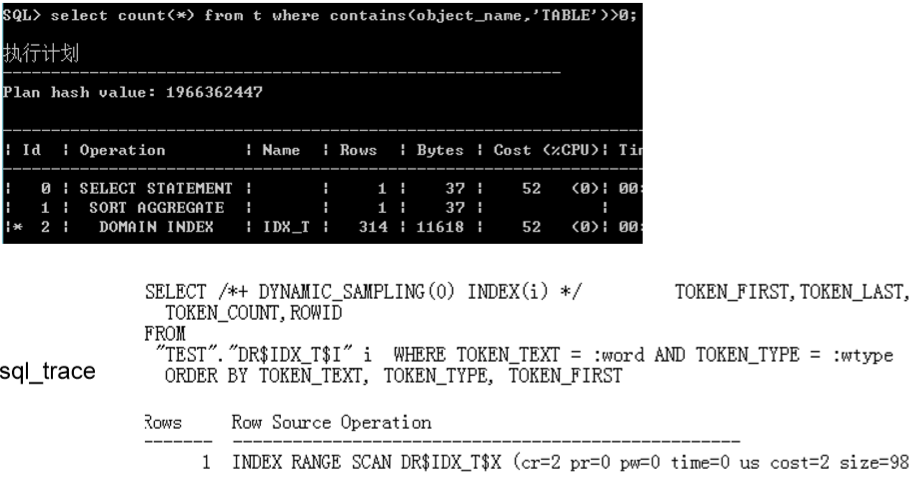
� 使用场景
– b-tree,bitmap无法发挥作用的场景, like '%string%'
� 缺点
– 占用过大的磁盘空间
– 维护成本高
– bug多
分区
� 分区表的几点注意
– 表分区后,分区变成各自的段,而表表成一个逻辑名称。
– 分区裁剪
分区裁剪

分类

组合分区(子分区)

� Oracle11g四种组合
– RANGE-RANGE
– LIST-RANGE
– LIST-HASH
– LIST-LIST
分区索引
� Local index
– 表的DML操作无需rebuild索引
– 可以非常方便的管理数据。

全局索引
� 表的DDL操作会导致索引无效
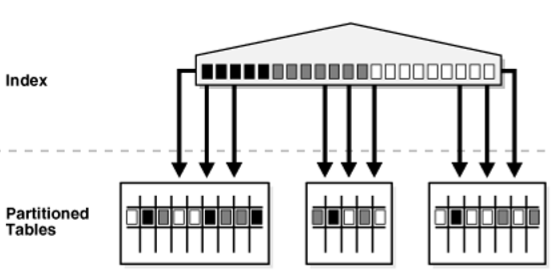
分区索引和全局索引
� 分区索引的目的在于数据的管理而非性能。
� 一个分区表上如果经常有DDL操作,将会导致全局索引无效,需要对索引重建,此时 创建分区索引更加适合。
数据分析
CBO的数据来源
� CBO是一个数学模型
� 需要准确的传入数据
� 通过精确的数据计算出精确的执行计划
没有分析数据时

分析信息不充足时

有足够的分析数据时

CBO的数据来源
� 初始化参数
– 优化参数
– CPU
– 数据块大小
– 多块读的大小 ......
� 数据字典
– user_tables,user_tab_partitions
– user_indexes,user_ind_partitions
– user_tab_col_statistics
DBMS_STATS包和analyze命令
� analyze命令已经过时
– 无法提供灵活的分析选项
– 无法提供并行的分析
– 无法对分析数据进行管理
� DBMS_STATS
– 专门为CBO提供信息来源
– 可以进行数据分析的多种组合
– 可以对分区进行分析
– 可以进行分析数据管理
• 备份,恢复,删除,设置....
自动信息收集
� Oracle11g的一个默认设置
� user_tab_modification跟踪表的修改
� 当分析对象的数据修改超过10%时,Oracle会重新分析。
� 定时任务GATHER_STATS_JOB负责重新定时收集过旧数据的信息。


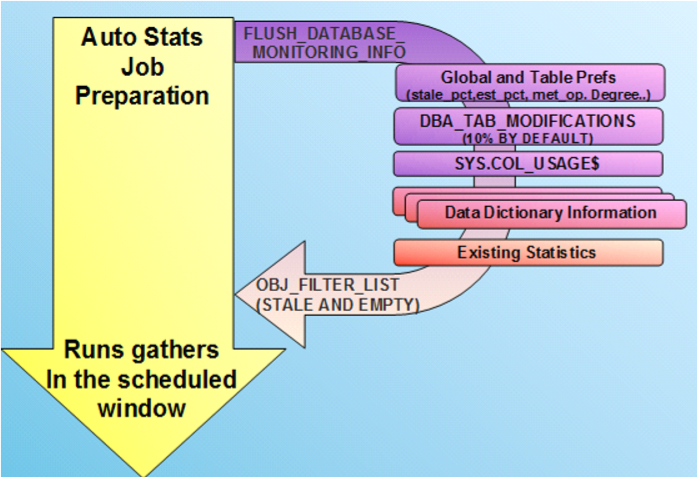
是否要完全依赖自动分析
�当数据执行计划保持不错的时候,可以依赖自动分析。 – 比如,OLTP系统。
�否则,需要手工介入。 – 比如,OLAP系统
�没有一个适合所有系统的数据分析方法
DBMS_STATS包

DBMS_STATS包 -Gathering_optimezer_statistics 收集 -setting_or_getting_statistics 自己设置参数 -deleting_statistics 删除 -transferring_statistics 传输 -locking_or_unlocking_statistics 锁定
表数据的收集
DBMS_STATS.GATHER_TABLE_STATS(
ownname
,tabname
,partname
,estimate_percent 采样
,block_sample 块的采样
,method_opt default 'for all columns size'
,degree 并行
,granularity 粒度
,cascade 索引
,stattab 建表存储统计信息
,statid
,statown
,no_invalidate 验证有效性
)
procedure gather_table_stats
(ownname varchar2, tabname varchar2, partname varchar2 default null,
estimate_percent number default DEFAULT_ESTIMATE_PERCENT,
block_sample boolean default FALSE,
method_opt varchar2 default DEFAULT_METHOD_OPT,
degree number default to_degree_type(get_param('DEGREE')),
granularity varchar2 default DEFAULT_GRANULARITY,
cascade boolean default DEFAULT_CASCADE,
stattab varchar2 default null, statid varchar2 default null,
statown varchar2 default null,
no_invalidate boolean default
to_no_invalidate_type(get_param('NO_INVALIDATE')),
stattype varchar2 default 'DATA',
force boolean default FALSE);
索引数据的收集
DBMS_STATS.GATHER_INDEX_STATS
(ownname varchar2, indname varchar2, partname varchar2 default null,
estimate_percent number default DEFAULT_ESTIMATE_PERCENT,
stattab varchar2 default null, statid varchar2 default null,
statown varchar2 default null,
degree number default to_degree_type(get_param('DEGREE')),
granularity varchar2 default DEFAULT_GRANULARITY,
no_invalidate boolean default
to_no_invalidate_type(get_param('NO_INVALIDATE')),
stattype varchar2 default 'DATA',
force boolean default FALSE);
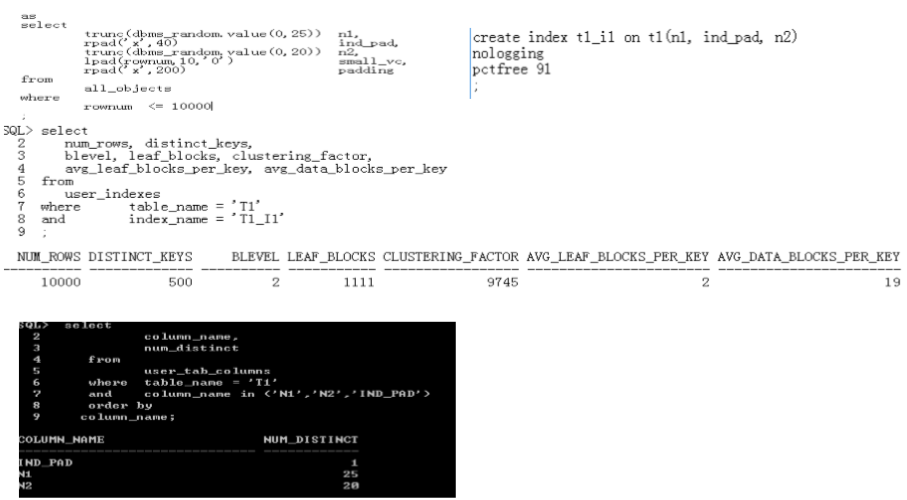
数据分析示例
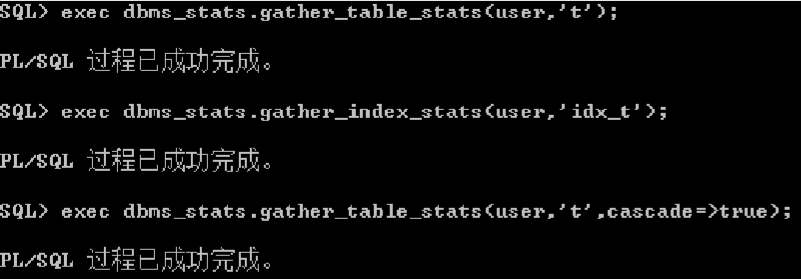
表(索引)分析中几个重要的参数
� estimate_percent estimate_percent estimate_percent estimate_percent
– DBMS_STATS.AUTO_SAMPLE_SIZE
– 手工设置(范围 0.000001,100 0.000001,100 0.000001,100 0.000001,100)
• 超大表
• 大表
• 小表
� granularity 数据分析的力度
– global
– partition
– subpartition
全局分析和分区分析
� 当表上已经有全局统计信息时,单独对分区分析,不会更新全局信息。

当表上没有全局统计信息时,单独对分区分析,会更新全局信息
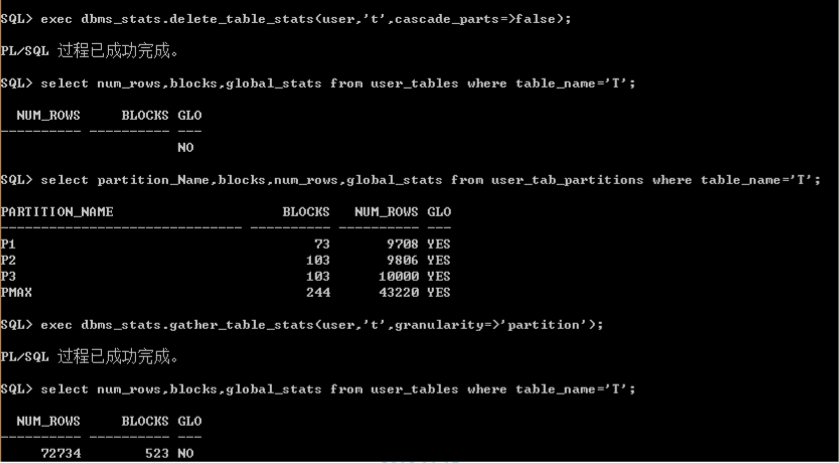
� 增量统计
– Oracle会增量的收集分区信息来更新全局信息

� 结论:如何设置这个参数
– 在一个很大的分区表(OLAP),全局分析代价是非常昂贵的。
– OLAP系统下,除了新加入的数据外,旧的数据基本上是没有变化的,全局分析很浪费资源。
– 对于很大的分区表,将granulariy设置为partition(Oracle10g)或者incremental( Oracle11g)是很有意义的。
– 对于不大的分区表,可以使用默认设置。
gather_table_stats几个重要的参数
� method_opt 分析直方图选项
直方图
� 概念--Oracle对列上的数据分布进行统计分析,对数据倾斜分布时 很有用。
� CBO的数据来源

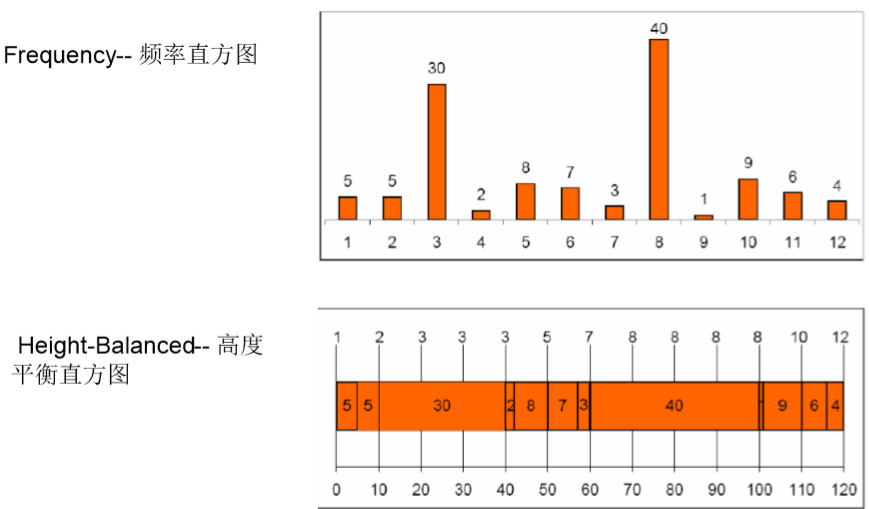
HEIGHT BALANCED
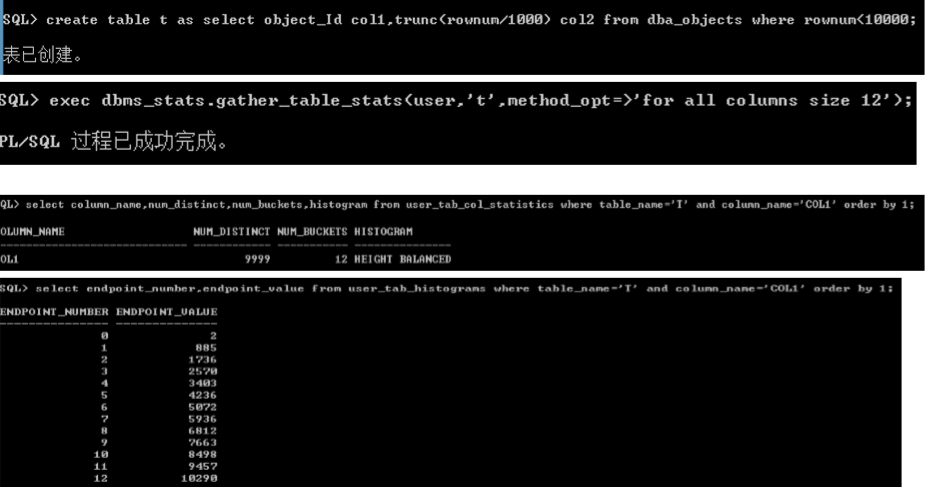
FREQUENCY
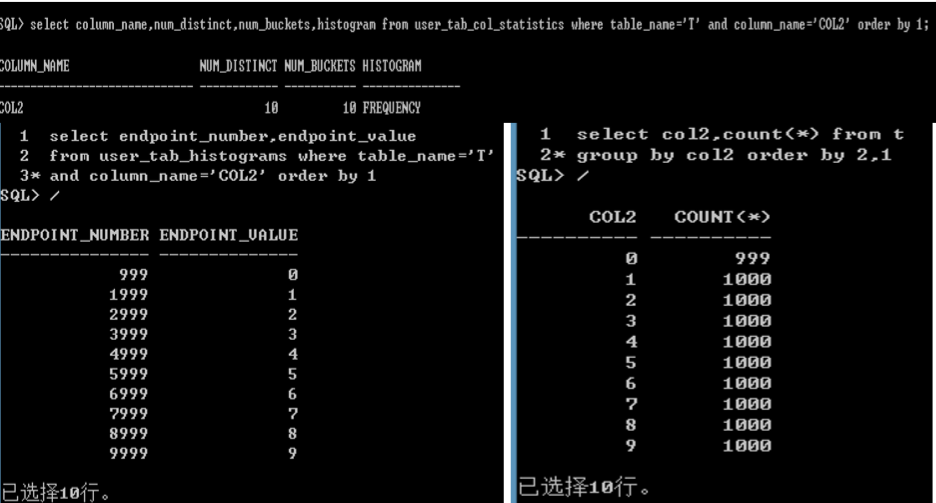
GATHER_TABLE_STATS.METHOD_OPT

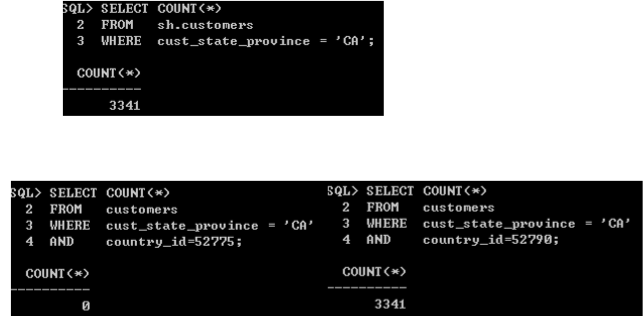
DBMS_STATS--Extended Statistics
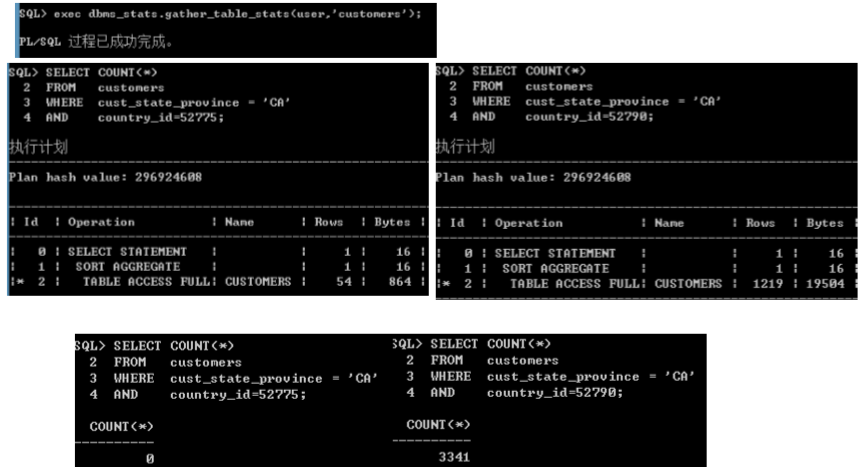
DBMS_STATS--Extended Statistics
DBMS_STATS--Extended Statistics

动态采样
� 当表上没有分析信息时,Oracle会使用动态采样技术。
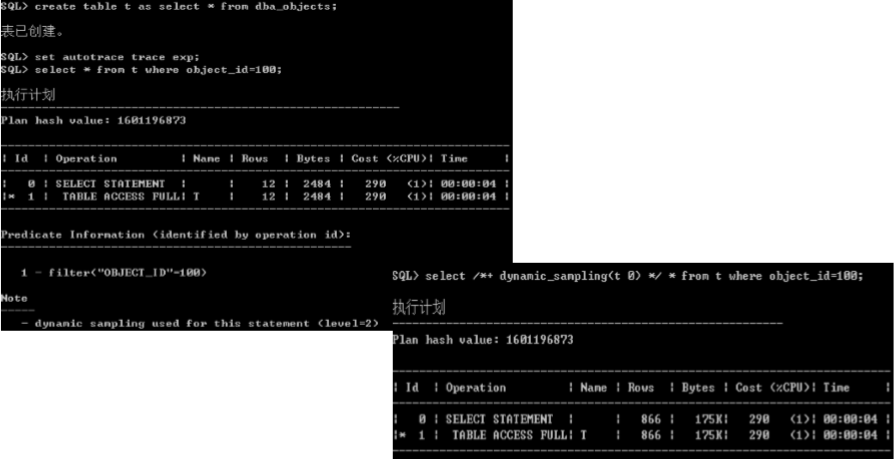
动态采样的级别
� 不同的级别,采样的数据块数量不同
– level1-10,采样数据量逐级递增。
– level10 对所有数据进行采样分析
并行
� 将一件工作分成很多块,分别由不同的进程来执行,最后将结果合并。

并行的应用场景
� OLAP 数据仓库
� 整块的数据读取操作
– FTS
– IFFS
� 并行执行高效的要素:
– 充足的系统资源
– 待处理的数据分布均匀
并行的机制
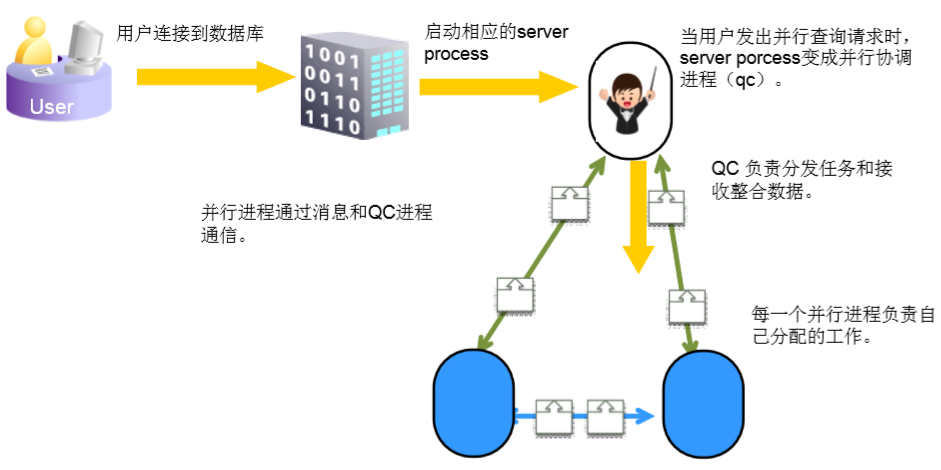


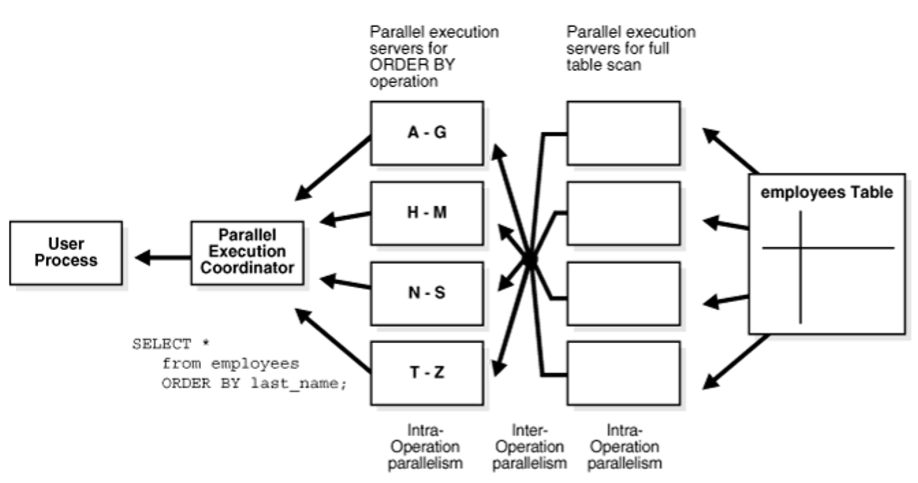
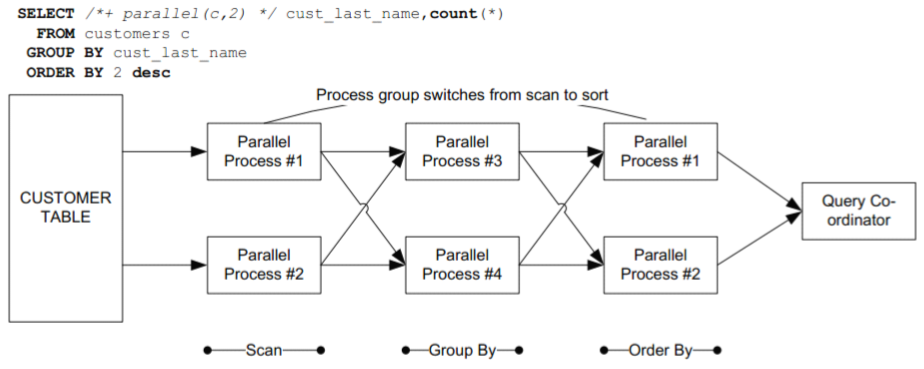

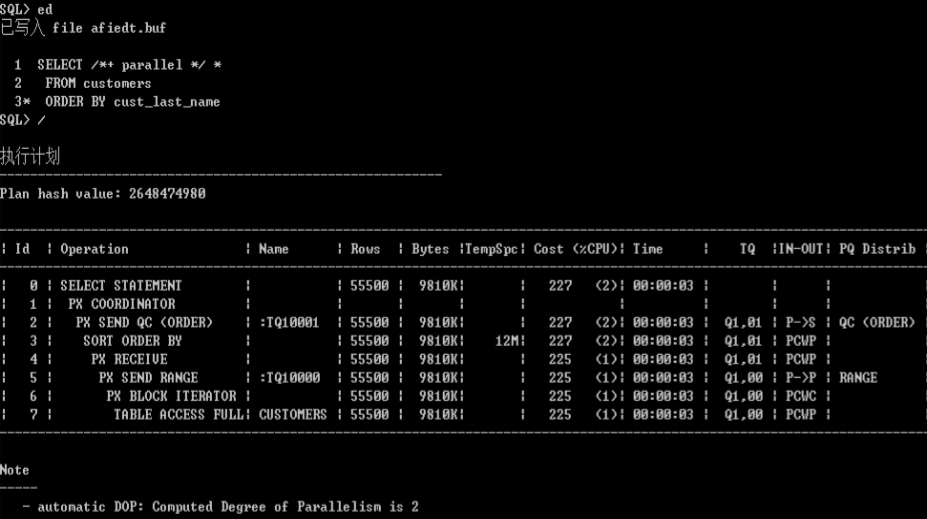
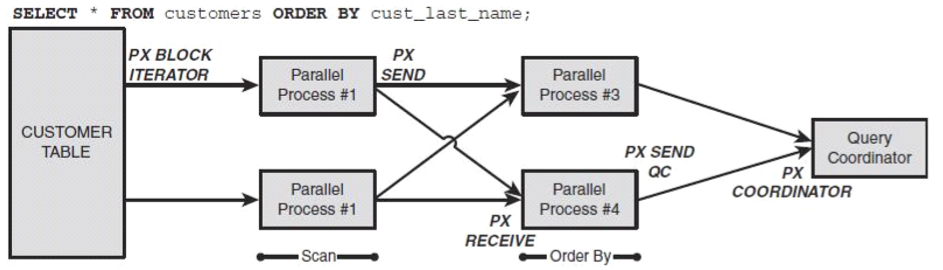
并行的执行计划


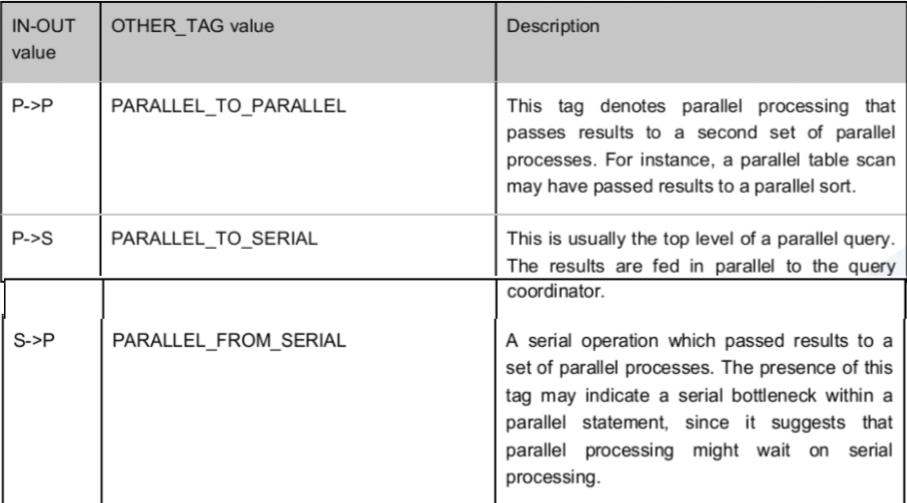
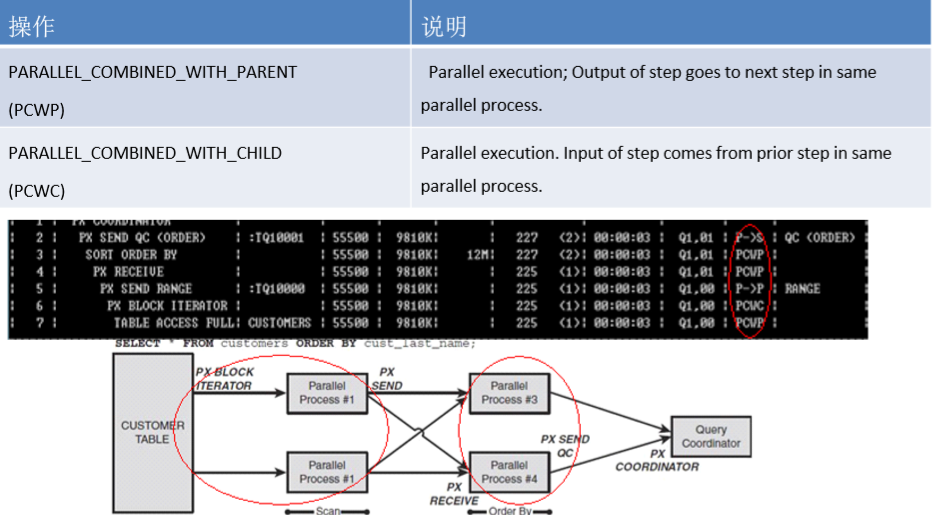
并行与性能
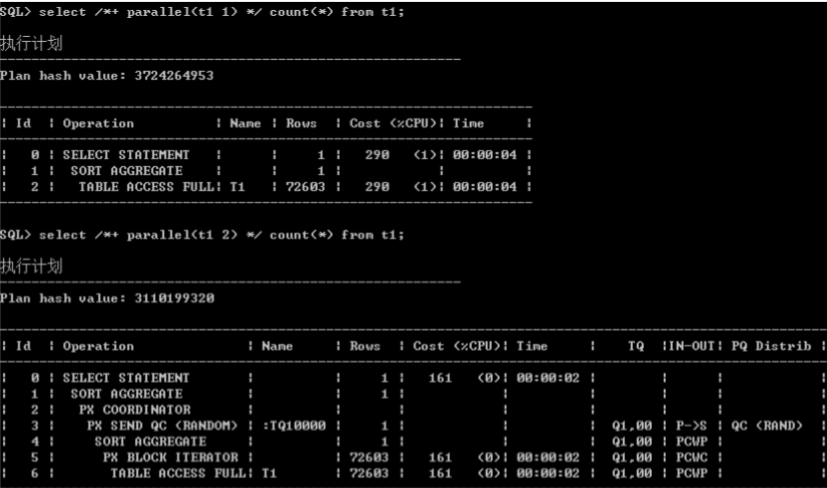
并行度
� 所谓并行度,就是Oracle在进行并行处理时,会启动几个并行进程来同时执行。
� 并行度的设定
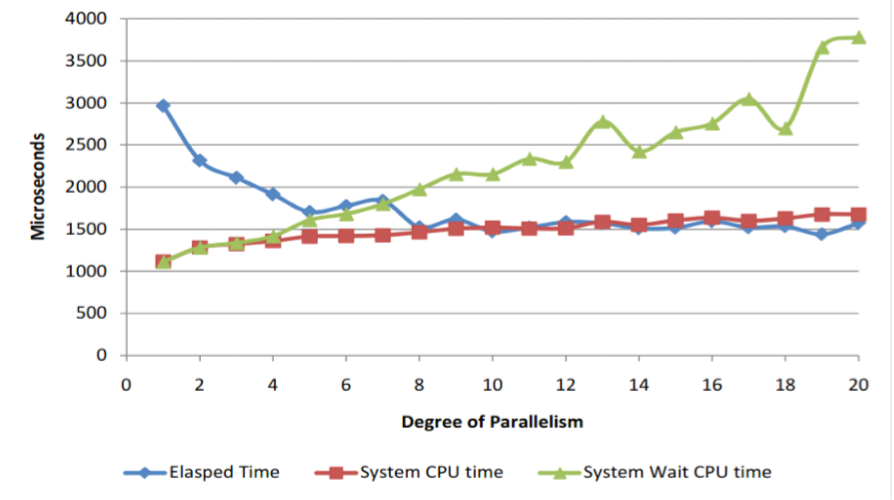
并行度的设置
� 并行执行系统资源关系非常密切
� 系统通常是动态改变的
� 所以,方法是
– 深入了解并行的机制+测试=〉最好的效果
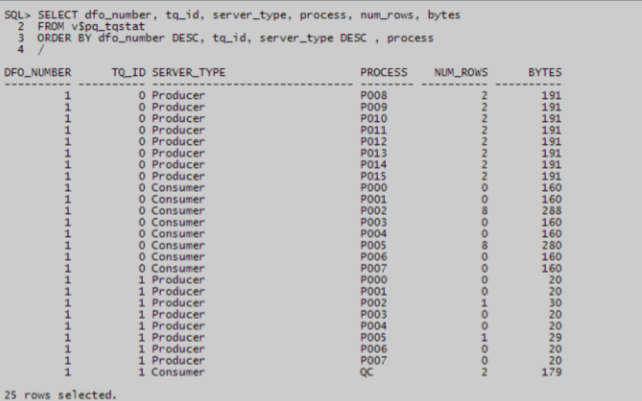
如何获得SQL的并行度
� V$PX_SESSION.degree
� V$PQ_TQSTAT
变量绑定
变量绑定演示

变量绑定的目的
� 减少SQL硬解析的次数。
� 减少系统资源开销。
� 减少latch争用

变量绑定的应用场景
� 适用于OLTP
– 用户并发很高
– 表中有主键
– 操作的数据少
– 执行计划基本相同
– SQL的重复率高
• select * from account where account_id=xxxx;
• update account set money=xxxx where account_id=xxxx;
� 不适用于OLAP
– 执行计划多变
– 用户少
– SQL解析对系统性能影响小
SQL语句的处理
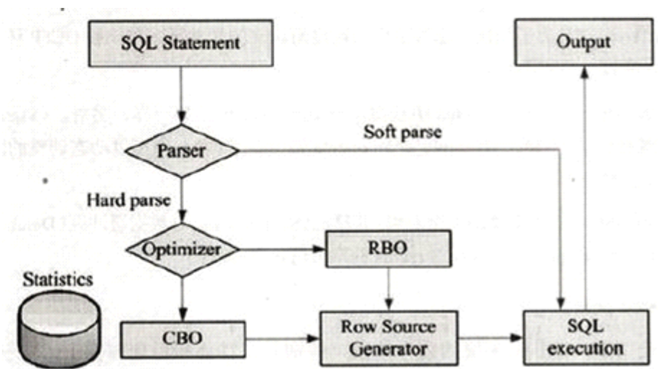
SQL的分析-硬分析(hard parse)
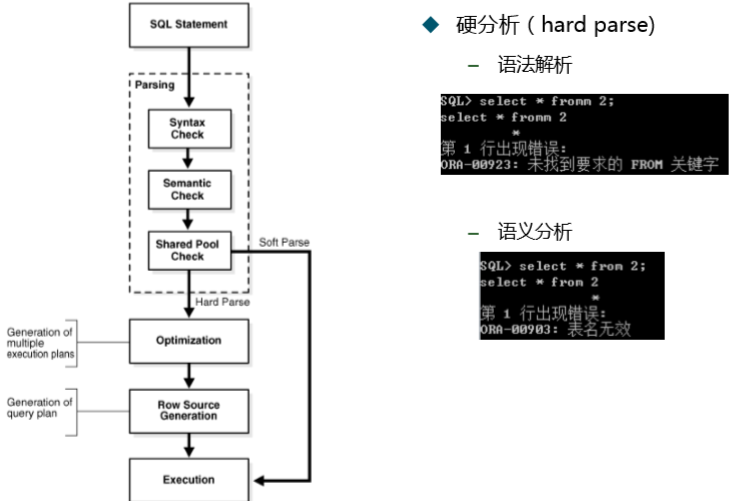
� 当SQL语句第一次执行时,都会被硬分析。

SQL的分析-软分析(soft parse)
� 软分析(soft parse)
– 共享池中搜索执行计划。
– 使用现有执行计划执行SQL
当SQL SQL SQL SQL硬分析之后,后续的相同的SQL SQL SQL SQL都会被软分析,除非SQL SQL SQL SQL被剔除shared_pool. shared_pool. shared_pool.
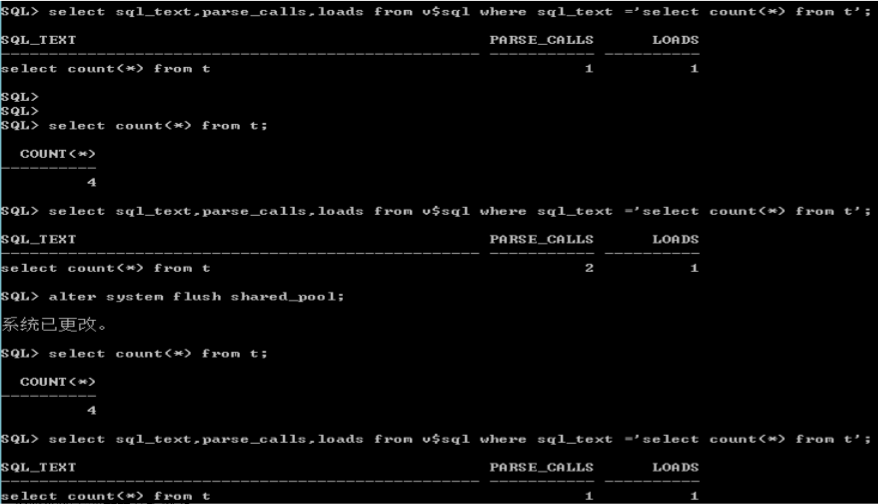
会话对游标的缓存--softer_soft_parse
� session_cached_cursor
– 对于已经关闭的cursor,可以把它的资于保留在pga中,用于后续对curosr的继续调用。
– 如果该参数设置为0,Oracle将会对关闭的游标重新打开。
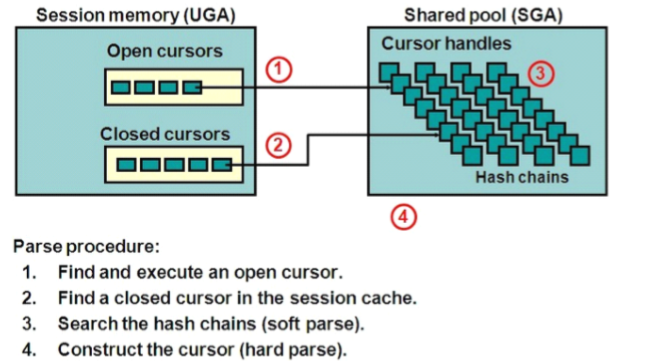
游标
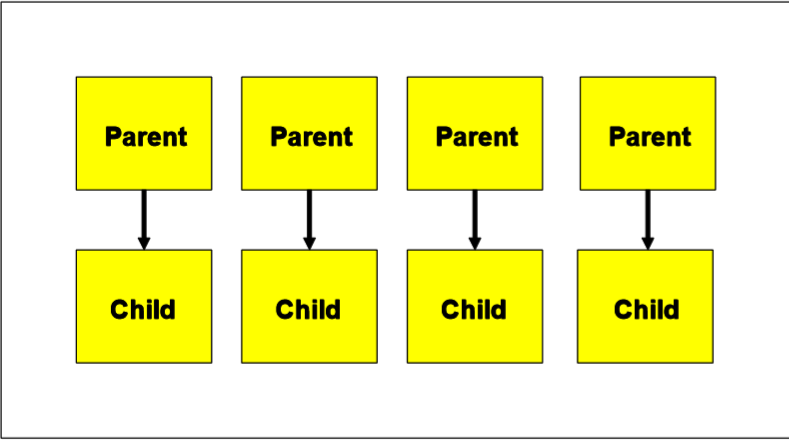
父子游标
� 同样的SQL,因某些其它的差异,会产生另外的cursor
– 父游标 parent cursor ---第一条运行的SQL
– 子游标 child cursor ---后续的SQL
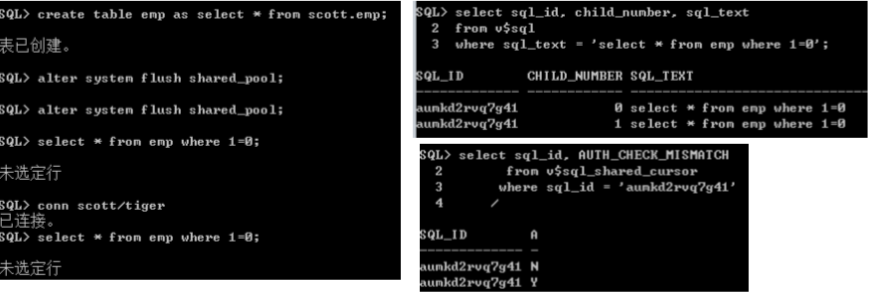
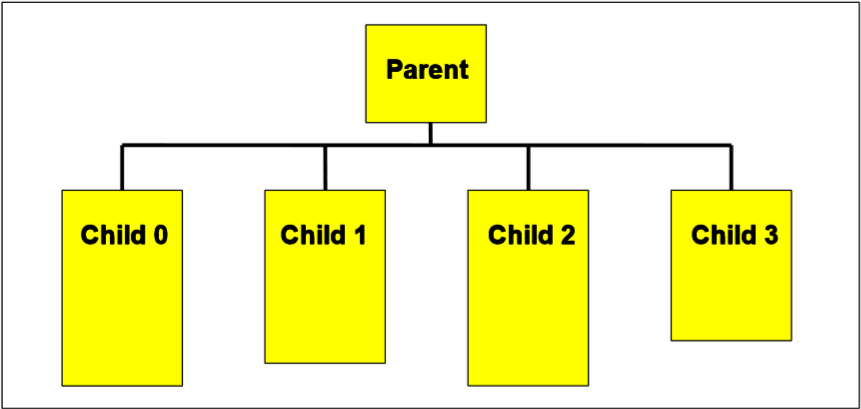
� V$SQL_SHARED_CURSOR---提供游标共享的信息
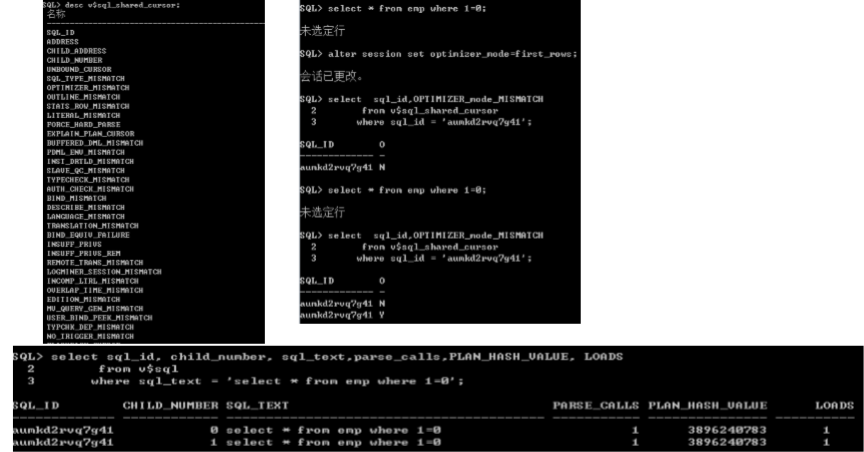
游标共享---cursor_sharing
� cursor_sharing=exact
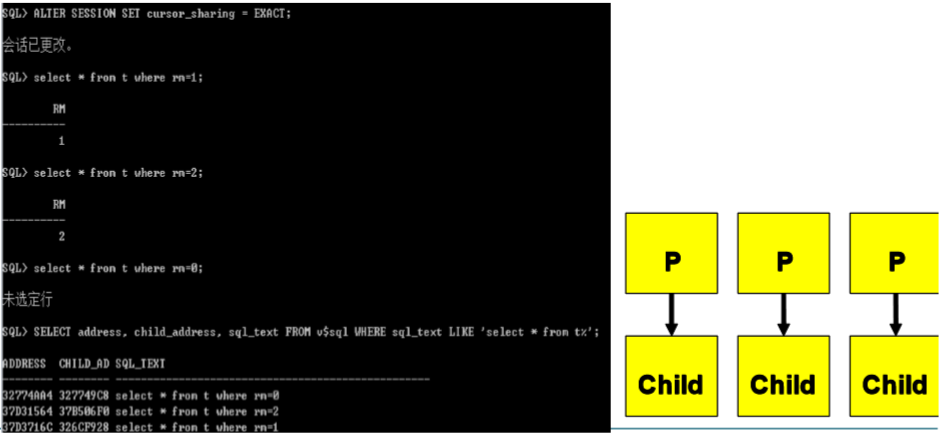
� cursor_sharing=force

� cursor_sharing=similar
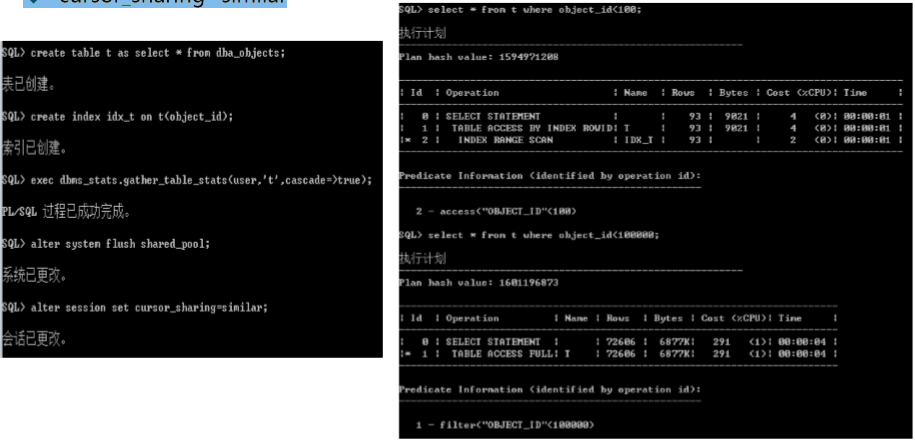
bind peeking
� 从Oracle9i开始,Oracle在第一次解析SQL(hard parse)时,如果SQL上有变量绑定, 会查看这个变量的值,以便于更准确的指定执行计划;但在后续的分析中(soft parse ),将不会理会这个变量的值。
� 适用场景
– 执行计划几乎不改变(oltp)
– 大量的并发
– 大量的除谓词外几乎相同的SQL。
� 不适用场景
– 执行计划会随变量值的变化而改变。
– 少量的SQL(OLAP).

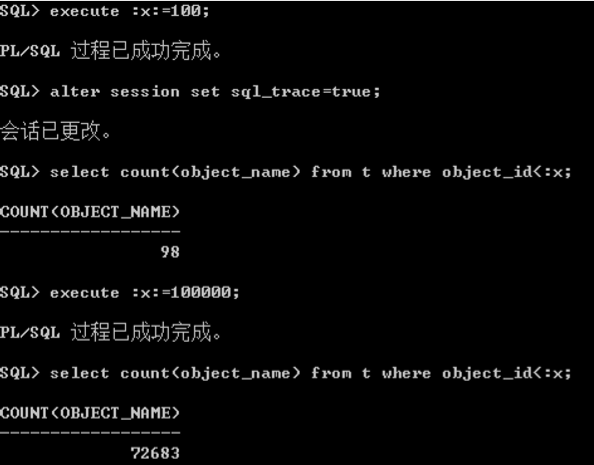
sql_trace & 10046
SQL_TRACE
� 用以描述SQL的执行过程的trace输出。
– SQL是如何操作数据的。
– SQL执行过程中产生了那些等待时间。
– SQL执行中消耗了多少资源。
– SQL的实际执行计划。
– SQL产生的递归语句。
set auto trace v.s. sql_trace(10046)
� SET AUTO TRACE (EXPLAIN PLAN)
– 输出优化器的产生的执行计划(估算值)
� SQL_TRACE
– SQL实际的执行情况
• 消耗的资源
• 产生的等待事件
• 数据的处理过程
� 当需要分析执行计划及CBO行为时,使用
– SET AUTO TRACE (EXPLAIN PLAN)
� 当要看一条SQL的真实运行效果时,使用:
– SQL_TRACE(10046)
产生一个SQL_TRACE
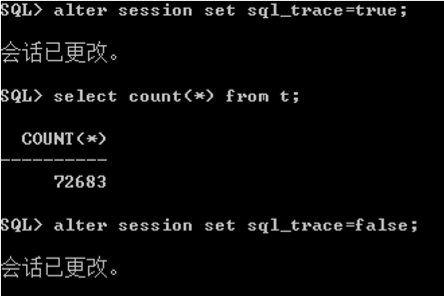
查看SQL_TRACE trace文件

阅读原始的trace文件
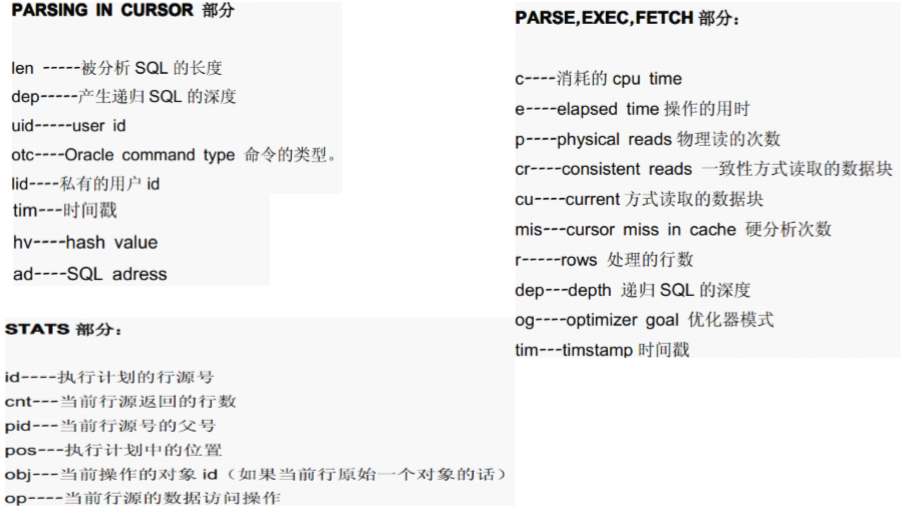
tkprof-格式化trace文件的工具


10046 event
� SQL> alter session set events '10046 trace name context forever,level n';

10053事件
� 了解Oracle执行计划的生成过程。
� 无法获知代价的计算公式。
10053 trace的内容
� 参数区
� SQL区
� 系统信息区 --SYSTEM STATISTICS INFORMATION
� 基本统计信息--BASE STATISTICAL INFORMATION
� 数据访问---ACCESS PATH
� 关联查询----JOIN ORDER
� 代价的最后修正
� 最终执行计划
使用10053场景
当set auotrace或者explain plan显示错误执行计 划,而又找不到原因的时候。
初始化参数和性能视图
性能问题的来源和对应的性能视图
� CPU
– cpu_count
CPU_COUNT
� 显示的是逻辑CPU数量(thread),比如:
– cpu_count=8 可以是8个单核,4个双核或者2个4核。
� 对并行度和代价有影响。
� 内存
– memory_max_target(11g)
memory_max_target
� 允许memory_target调整的上限。
� 设置memory_max_target而忽略memory_target,Oracle设置memory_target=0( 不使用自动内存管理)。
� 设置memory_target的值,忽略memory_max_target,Oracle自动将 memory_max_target设置为memory_target的值。
� 同时设置这两个值,memory_target的上限值为memory_max_target
– sga_target
- 对SGA区的动态调整
– sga_max_size
– pga_aggregate_target
- PGA内存空间总和的动态调整
� I/O
– DB_FILE_MULTIBLOCK_READ_COUNT
- 多数据块的读取
– DB_WRITER_PROCESSES
� 我们可以设置多个DB_WRITER进程,以加快数据从缓冲区先磁盘写入的速度,这在写 操作非常大的数据库上非常有用。
� 需要注意的是,这个参数只用于数据库的写操作,和数据读取没有任何关系,数据块 的读取是用户会话的服务端进程来完成的。
– DISK_ASYNCH_IO
– DBWR_IO_SLAVES
� 网络
– sessions
- 数据库允许产生的session数量
– processes
- 数据库允许产生的process数量。
– open_cursors
- � 指定某个会话能够打开的最大游标数
�优化器:
- optimizer_index_cost_adj
- CBO计算成本时索引的权重修正值。
- optimizer_mode
- optimizer_dynamic_sampling
- 动态采样的级别 0 to 10
- cursor_sharing
性能问题的来源和对应的性能视图
� CPU
– V$SYSSTAT 某个会话消耗cpu值
� 内存
– V$MEMORY_TARGET_ADVICE Oracle自动管理内存的建议器
– V$SGA_TARGET_ADVICE
– GV$SHARED_POOL_ADVICE
� I/O
– V$IOSTAT_FILE 数据文件/临时文件/控制文件/日志文件/归档文件
– V$IOSTAT_FUNCTION
– V$FILESTAT
– V$ROLLSTAT
� 网络
– V$IOSTAT_NETWORK
� 对象
– V$SEGSTAT,V$SEGMENT_STATISTICS,V$SEGSTAT_NAME 各类统计信息
� 等待事件
– V$ACTIVE_SESSION_HISTORY
– V$SESS_TIME_MODEL and V$SYS_TIME_MODEL
– V$SESSION_WAIT 会话当前等待事件的详细信息
– V$SESSION 某会话的当前各种状态
– V$SESSION_EVENT 会话所有等待事件的详细信息
�其它:
- V$SQL
- V$LATCH
- V$ENQUEUE_STAT

 浙公网安备 33010602011771号
浙公网安备 33010602011771号