Pyspider抓取静态页面
近期,我想爬一批新闻资讯的内容。新闻类型的网址很多,我想看看有没有一个网页上能包罗尽可能多的新闻网站呢,于是就发现了下面这个网页
http://news.hao123.com/wangzhi
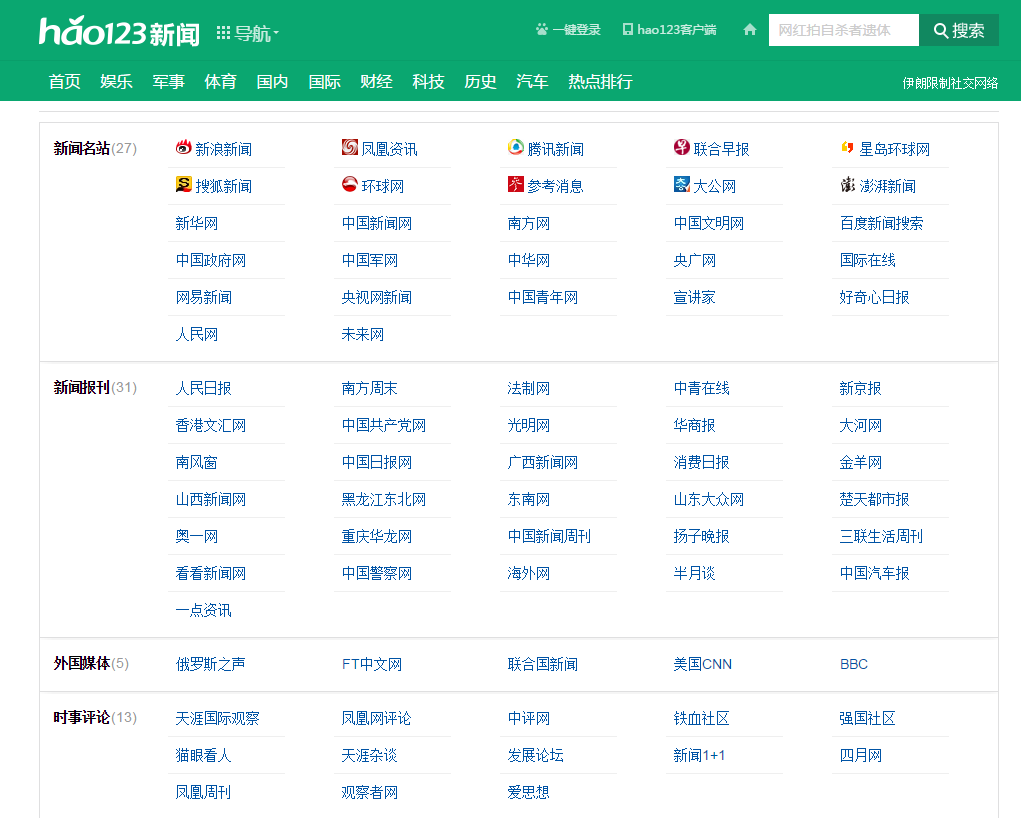
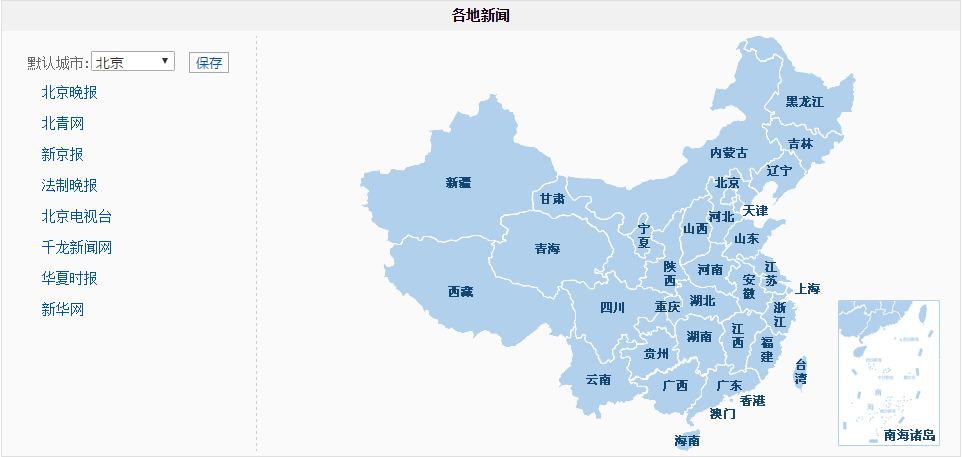
这个页面的下边还有地方新闻的分类
1、爬取目标
按类型分的网址列表
按地方分的网址列表
2、按类型
1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2018-01-02 15:44:54 4 # Project: financeNews 5 6 from pyspider.libs.base_handler import * 7 8 9 class Handler(BaseHandler): 10 crawl_config = { 11 } 12 13 def __init__(self): 14 self.url = 'http://news.hao123.com/wangzhi' 15 16 @every(minutes=24 * 60) 17 def on_start(self): 18 self.crawl(self.url,callback=self.index_page) 19 20 @config(age=10 * 24 * 60 * 60) 21 def index_page(self, response): 22 23 return [{ 24 "group" : x('.content-title').text(), 25 "websites" : [a.text() for a in x('li a').items()] 26 } for x in response.doc('.mod-content').items()]
运行结果

3、按地方
1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2018-01-02 15:44:54 4 # Project: financeNews 5 6 from pyspider.libs.base_handler import * 7 8 9 class Handler(BaseHandler): 10 crawl_config = { 11 } 12 13 def __init__(self): 14 self.url = 'http://news.hao123.com/wangzhi' 15 16 @every(minutes=24 * 60) 17 def on_start(self): 18 self.crawl(self.url,callback=self.index_page) 19 20 @config(age=10 * 24 * 60 * 60) 21 def index_page(self, response): 22 23 return [{ 24 "city" : x.attr('id')[5:], 25 "websites" : [a.text() for a in x('li a').items()] 26 } for x in response.doc('.page').items()]
运行结果

4、知识点小结
4.1 __init__()方法为对象创建完成后的初始化方法,自动执行,可以自定义一些全局属性
4.2 "city" : x.attr('id')[5:]
取属性id的值,并从第6个字符截取

 浙公网安备 33010602011771号
浙公网安备 33010602011771号