2、Pyspider使用入门
1、接上一篇,在webui页面,点击右侧【Create】按钮,创建爬虫任务

2、输入【Project Name】,【Start Urls】为爬取的起始地址,可以先不输入,点击【Create】进入:

3、进入爬取操作的页面
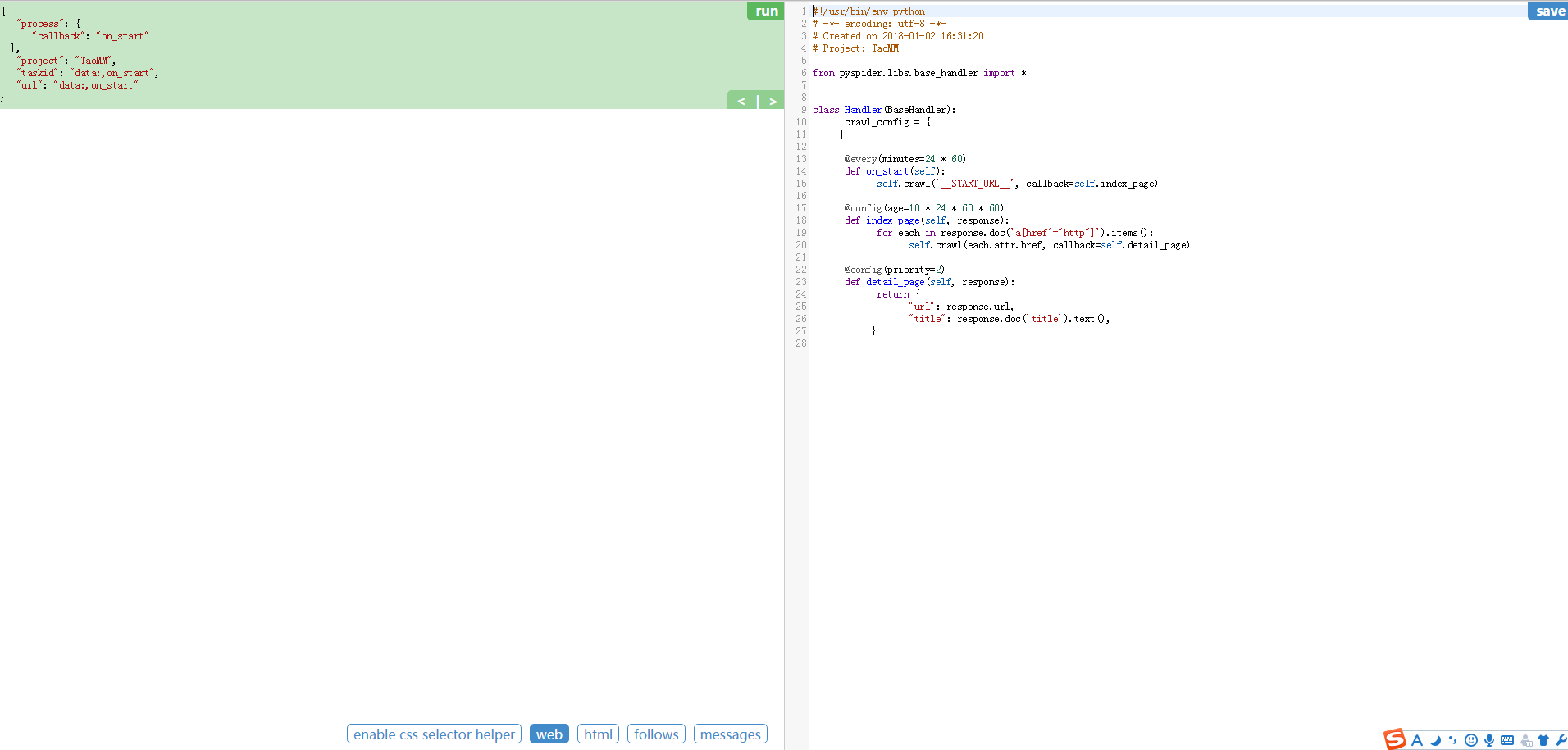
整个页面分为两栏,左边是爬取页面预览区域,右边是代码编写区域。下面对区块进行说明:
左侧绿色区域:这个请求对应的 JSON 变量,在 PySpider 中,其实每个请求都有与之对应的 JSON 变量,包括回调函数,方法名,请求链接,请求数据等等。
绿色区域右上角Run:点击右上角的 run 按钮,就会执行这个请求,可以在左边的白色区域出现请求的结果。
左侧 enable css selector helper: 抓取页面之后,点击此按钮,可以方便地获取页面中某个元素的 CSS 选择器。
左侧 web: 即抓取的页面的实时预览图。
左侧 html: 抓取页面的 HTML 代码。
左侧 follows: 如果当前抓取方法中又新建了爬取请求,那么接下来的请求就会出现在 follows 里。
左侧 messages: 爬取过程中输出的一些信息。
右侧代码区域: 你可以在右侧区域书写代码,并点击右上角的 Save 按钮保存。
右侧 WebDAV Mode: 打开调试模式,左侧最大化,便于观察调试。
4、代码编辑区
1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2015-10-08 12:45:44 4 # Project: test 5 6 from pyspider.libs.base_handler import * 7 8 9 class Handler(BaseHandler): 10 crawl_config = { 11 } 12 13 @every(minutes=24 * 60) 14 def on_start(self): 15 self.crawl('http://scrapy.org/', callback=self.index_page) 16 17 @config(age=10 * 24 * 60 * 60) 18 def index_page(self, response): 19 for each in response.doc('a[href^="http"]').items(): 20 self.crawl(each.attr.href, callback=self.detail_page) 21 22 @config(priority=2) 23 def detail_page(self, response): 24 return { 25 "url": response.url, 26 "title": response.doc('title').text(), 27 }
代码简单分析:
def on_start(self) 方法是入口代码。当在web控制台点击run按钮时会执行此方法。
self.crawl(url, callback=self.index_page)这个方法是调用API生成一个新的爬取任务,这个任务被添加到待抓取队列。
def index_page(self, response) 这个方法获取一个Response对象。 response.doc是pyquery对象的一个扩展方法。pyquery是一个类似于jQuery的对象选择器。
def detail_page(self, response)返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。你也可以重写on_result(self,result)方法来指定保存位置。
更多知识:
@every(minutes=24*60, seconds=0) 这个设置是告诉scheduler(调度器)on_start方法每天执行一次。
@config(age=10 * 24 * 60 * 60) 这个设置告诉scheduler(调度器)这个request(请求)过期时间是10天,10天内再遇到这个请求直接忽略。这个参数也可以在self.crawl(url, age=10*24*60*60) 和 crawl_config中设置。
@config(priority=2) 这个是优先级设置。数字越大越先执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号